この記事はマイナビ Advent Calendar 2019 7日目の記事です!
普段、ビッグデータとかAIとかを扱う部署で、主に自然言語処理を専門にやってます。
今回はもくもく時間を使って、社内Slackにチャットボットを解き放って遊んだ話をします。
概要
煽り性能の高いBotがAWS上で稼働しています。
たまに職場の先輩からインジェクション攻撃を受けたりしますが、元気です。
マルチクラウドにせずにシングルクラウドにしたほうが構成がスッキリして良かったと後悔中です。
以下は実際にチャットボットと戯れた画像です。

うーん、親の顔に向かってなんという…。
はじめに
作成しようと思った背景
人間誰しもチャットボット作りたい欲求を抱えたまま生きています。少なくとも私はそうなので、他の人もきっとそうだと思います。
そんな中マイクロソフトの女子高生AI『りんな』の論文が世に発表されました(2016年)。
- 公式ホームページ: https://www.rinna.jp
- 言語処理学会論文: りんな:女子高生人工知能
かわいい
これは作らなければ…(2年経過)
Slackについて
Slackをメインのコミュニケーションツールとして使用しています。Public Channelだけで677ありました。多いのか少ないのかいまいちわかりません ![]()
times文化が根付いているので、本チャットボットの目的は自身のtimesで運用し『みんなを笑顔にする』こととしました。そんな対話Botになればいいなという祈りが込められています。いました。
ちなみに名前は夏に最新リリースをしたから『夏ちゃん』です。バージョンが上がるたびに、その時の季節を名前にしています。
使用したSlack APIはEvents APIです。mentionされたときのみAPIコールされるように権限を絞ることを私は忘れません。
成果物
チャットボット構成図
サクッと作りました。
下記にチャットボットの構成図を記載します。
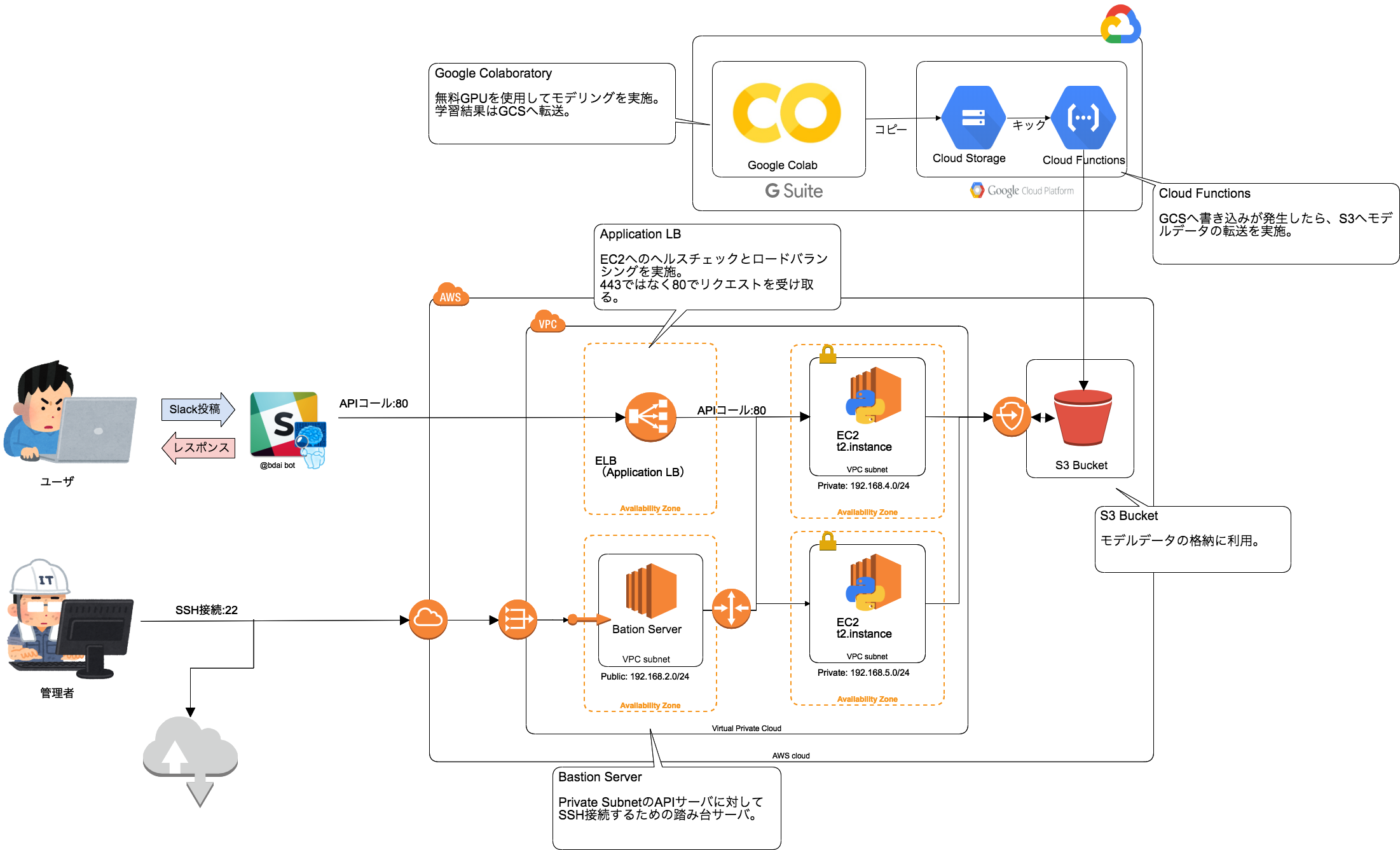
実は結構頑張りました。
はじめは単一EC2にElastic IPをもたせてScreenコマンドでセッションを保存し、Slack連携をしていました。
が、「それじゃAWSを使うメリットないじゃん(ないじゃん)」と神のお告げがあり、たしかにそうだと思い色々と弄っていった経緯があります。
システム構成の課題
自分なりに現構成の問題点を挙げてみます。
- セキュアじゃない
- 「SSL証明書をどうしようかな…」と悩んだ結果、HTTP通信でSlack連携をしちゃいました
- API Gatewayを使用するとamazonドメインではありますが、HTTPS通信が可能です
- その場合、ALBではなくNLBを構築し、VPC Linkでつなげるとよいと思います
- (ALBが使いたい年頃でした)
- マルチクラウドにした理由が不明
- AWS上でインフラをある程度作った後にColaboratoryを使おうと思った結果、連携でGCPを利用することになりました
- その段階でGCPで構築したほうが良かったと今になっては思います
- 技術・環境選定は大事
- (無限に使えるGPUがほしいです)
- どうしてEC2?
- 当時、Dockerについての知識と技術が特になかったためです
- API部分をDockerコンテナ化して、ECSで運用したい
- Terraform管理にしたい(願望)
- 別案件でAWSインフラをTerraform管理にしたので、いずれはチャットボット環境もTerraform管理にしたい
チャットボットのアルゴリズムについて
今回、Seq2Seq+Attention+Sentencepieceで実装しました。具体的な技術群を下記に示します。
※ 学習データについては末尾のリンクを参照ください。
| 項目 | 内容 |
|---|---|
| 学習アルゴリズム | Seq2Seq(4層LSTM)+ Global Attention |
| トークナイザー | Sentencepiece |
| 事前学習 | Word2Vec |
| 最適化手法 | Adam |
| 学習データ | 対話破綻コーパス + 旧名大 + Slack上での会話ログ |
| 使用ライブラリ | Chainer |
事前学習としてSentencepieceによってトークン化された学習コーパスから、Word2Vecを使用して単語ベクトルを学習しています。
学習された単語ベクトルは、EncoderとDecoderのWord Embeddingの初期値として利用しました。
以下、 __init__部分です。
def __init__(self, vocab_size, embed_size, hidden_size, eos, w=None, ignore_label=-1):
super(Seq2Seq, self).__init__()
self.unk = ignore_label
self.eos = eos
with self.init_scope():
# Embedding Layer
self.x_embed = L.EmbedID(vocab_size, embed_size, initialW=w, ignore_label=ignore_label)
self.y_embed = L.EmbedID(vocab_size, embed_size, initialW=w, ignore_label=ignore_label)
# 4-Layer LSTM
self.encoder = L.NStepLSTM(n_layers=4, in_size=embed_size, out_size=hidden_size, dropout=0.1)
self.decoder = L.NStepLSTM(n_layers=4, in_size=embed_size, out_size=hidden_size, dropout=0.1)
# Attention Layer
self.attention = L.Linear(2*hidden_size, hidden_size)
# Output Layer
self.y = L.Linear(hidden_size, vocab_size)
Seq2SeqはEncoder−Decoderを採用した系列変換モデルです。
元の論文では機械翻訳(英仏翻訳タスク)で発表されていましたが、入力文字列を出力文字列に変換するってことは対話でも使えるじゃん!ってことで対話Botでも利用されている認識です。
学習データは以下のような入力文-出力文の組となっています。
入力文: あなたと話すの、本当に楽しいわ。居間に上がって話でもしますか?
出力文: 今日はこれから用事があるのでお暇しますね。
学習されたモデルから得られる回答は一問一答式のようなものとなり、会話の流れなどを一切考慮しないものとなります。会話が続いたように見える場合もありますが、それはたまたま続いたように見えるだけで、モデルとしては一切考慮していません。
以下が__call__部です。
def __call__(self, x, y):
"""
:param x: ミニバッチの入力データ
:param y: 入力データに対応するミニバッチの出力
:return: 誤差と精度
"""
batch_size = len(x)
eos = self.xp.array([self.eos], dtype='int32')
# EOS信号の埋め込み
y_in = [F.concat((eos, tmp), axis=0) for tmp in y]
y_out = [F.concat((tmp, eos), axis=0) for tmp in y]
# Embedding Layer
emb_x = sequence_embed(self.x_embed, x)
emb_y = sequence_embed(self.y_embed, y_in)
# Encoder, Decoderへの入力
h, c, a = self.encoder(None, None, emb_x) # h => hidden, c => cell, a => output(Attention)
_, _, dec_hs = self.decoder(h, c, emb_y) # dec_hs=> output
# batch sizeのdecoder出力をconcat
dec_h = chainer.functions.concat(dec_hs, axis=0)
# Attentionの計算
attention = chainer.functions.concat(a, axis=0)
o = self.global_attention_layer(dec_h, attention)
t = chainer.functions.concat(y_out, axis=0)
loss = F.softmax_cross_entropy(o, t) # 誤差計算
accuracy = F.accuracy(o, t) # 精度計算
return loss, accuracy
推論時はビームサーチを採用しています。ビーム幅は3です。最大単語長は50です。
これらの実装は、以下の@nojimaさんのブログを参考にしました。すごい助かりました。ありがとうございます!
https://nojima.hatenablog.com/entry/2017/10/10/023147
学習はGoogle Colaboratoryを使用しています。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
苦労した点
- ColaboratoryのルールによるJupyter環境の停止
- 90分間の無操作と12時間の連続稼働でColabは停止され、内部データはインターネットの闇に葬られます
- そのためエポックごとにスナップショットを取得しては保存し、また読み込んでを繰り返していました
- (無限に使えるGPUが欲しいです)
- 脱Colaboratory
- Jupyterやスクリプトをgit pushすると学習基盤にデプロイされるようなMLOpsをやってみたいです
API側の実装
Flask + uWSGIで実装しています。Events APIと連携を取る際、Slack側から Challengeが発生します。
https://api.slack.com/events-api#subscriptions
具体的に言うと、以下のようなPOSTがエンドポイントに投げれます。この "challenge" のvalueをそのままreturnすればChallenge成功です。以降、設定したSlack API設定の通りにSlackと連携が可能です。
Challenge失敗だと、SlackからAPIエンドポイントに対してPOSTが発生しないので、注意が必要です。
{
"token": "Slack APIのトークン",
"challenge": "3eZbrw1aBm2rZgRNFdxV2595E9CY3gmdALWMmHkvFXO7tYXAYM8P",
"type": "url_verification"
}
権限設定は『Event Subscriptions』の『Subscribe to bot events』で設定可能です。私はapp_mention をEventとして追加しました。これはBotを導入したチャンネルでメンションされたときに、設定したエンドポイントに投稿データをPOSTするEventです。
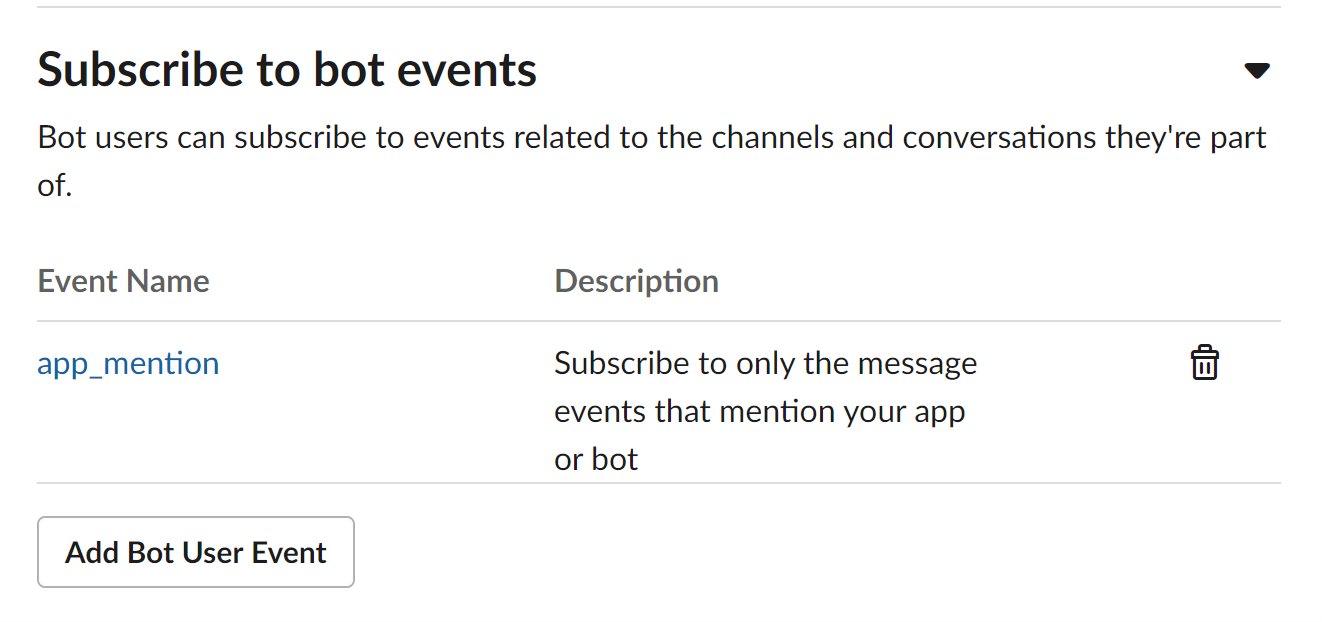
『Subscribe to bot events』の下に『Subscribe to workspace events』がありますが、これはワークスペース全体のEventとして適用される設定となります。大変なことになるので注意です。
APIの課題
API側の課題は以下の通りです。
- Swagger(Connexion)を使用して、もう少しモダンにしたい
- Slackとやり取りをするエンドポイントと推論部分を分離
- エンドポイントと推論部分が蜜月の関係なので、この不健全さを解消したい
- ちゃんとCI/CDをやりたい
- 別案件でBitbucket Pipelinesを使用したので、次のデプロイではCI/CDを回したいです
リリース後の反応
times内で好意的に受け入れてもらえてうれしいかったです。
なんだかんだで、1週間に一度以上はBotとのやり取りが発生してます(私も含め)。
ときには愚痴を聞いたり、時にはインジェクション攻撃を受けたり、時には『強い』言葉を受けたりしています。
チャットボットの裏にいるエンジニアを思うと、チャットボットに対して強く当たれなくなりました。
ごめん、Siri。ごめん、Cortana。ごめん、カイルくん。
作って初めて分かることが多々あると実感した1年間でした。
終わりに

![]()
リンク
- 対話破綻コーパス
- 名大会話コーパス
- Sequence to Sequence Learning with Neural Networks
- Effective Approaches to Attention-based Neural Machine Translation
- SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
- Distributed Representations of Words and Phrases and their Compositionality