本記事は ZOZO Advent Calendar 2023 シリーズ 7 の 22 日目の記事です。
はじめに
Vertex AI Experiments の一部の機能である Autolog についてご紹介します。
モデルの定義部分を以下のコードのように aiplatform.autolog() で囲うことで、パラメータや評価指標を自動で記録し、GCP コンソールから確認できるという便利機能です。
aiplatform.init(
experiment=experiment_name,
project=project,
location=location,
experiment_tensorboard=experiment_tensorboard,
)
aiplatform.autolog()
# Your model training code goes here
aiplatform.autolog(disable=True)
▼ ログの例
本記事では Autolog をメインで扱いますが、Vertex AI Experiments の基本的な機能について知りたい方は、公式ドキュメントや以下の記事をご参照ください。
実践
Vertex AI Experiments AutoLog がサポートしているライブラリは以下です。(2023/12/21)
- Fastai
- Gluon
- Keras
- LightGBM
- Pytorch Lightning
- Scikit-learn
- Spark
- Statsmodels
- XGBoost
本記事では LightGBM を使用して 5-Fold でモデルを学習しパラメータと評価指標を記録します。
学習データは Kaggle のタイタニックデータセットを使用します。
実行環境は Jupyter Notebook(Python 3.11) を使用します。
▼ ソースコード
from datetime import datetime
import polars as pl
import lightgbm as lgb
from sklearn.model_selection import KFold
from google.cloud import aiplatform
# Set Vertex AI Experiments config
aiplatform.init(
experiment="test-rayuron",
project="project",
location="location",
)
train = pl.read_csv("./titanic/train.csv")
test = pl.read_csv("./titanic/test.csv")
feature_cols = ["Pclass", "Age", "SibSp", "Parch", "Fare"]
target_col = "Survived"
params = {
"objective": "binary",
"boosting_type": "gbdt",
"metric": "binary_error",
"max_depth": 7,
"learning_rate": 0.1,
"num_boost_round": 100,
}
callbacks = [
lgb.early_stopping(10),
lgb.log_evaluation(1),
]
cvs = []
predictions = []
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for fold, (train_index, valid_index) in enumerate(kf.split(train)):
train_fold = train[train_index]
valid_fold = train[valid_index]
train_dataset = lgb.Dataset(train_fold[feature_cols].to_numpy(), label=train_fold[target_col].to_numpy())
valid_dataset = lgb.Dataset(valid_fold[feature_cols].to_numpy(), label=valid_fold[target_col].to_numpy())
# Start Autolog
aiplatform.autolog()
# Start manually log
run_id = datetime.now().strftime("%Y%m%d%H%M%S") + f"-fold-{fold}"
aiplatform.start_run(run=run_id)
model = lgb.train(
params,
train_dataset,
valid_sets=[train_dataset, valid_dataset],
valid_names=["train", "valid"],
callbacks=callbacks,
)
best_binary_error = model.best_score["valid"]["binary_error"]
aiplatform.log_metrics({"best-binary-error": best_binary_error})
accuracy = 1 - best_binary_error
aiplatform.log_metrics({"cv": accuracy})
cvs.append(accuracy)
prediction = model.predict(test[feature_cols].to_numpy())
predictions.append(prediction)
# Finish manually log
aiplatform.end_run()
# Finish AutoLog
aiplatform.autolog(disable=True)
結果の確認
Vertex AI > Experiments のコンソールからログを確認できます。
各 run を選択し COMPARE を押下することで Fold 毎の評価指標が比較可能です。

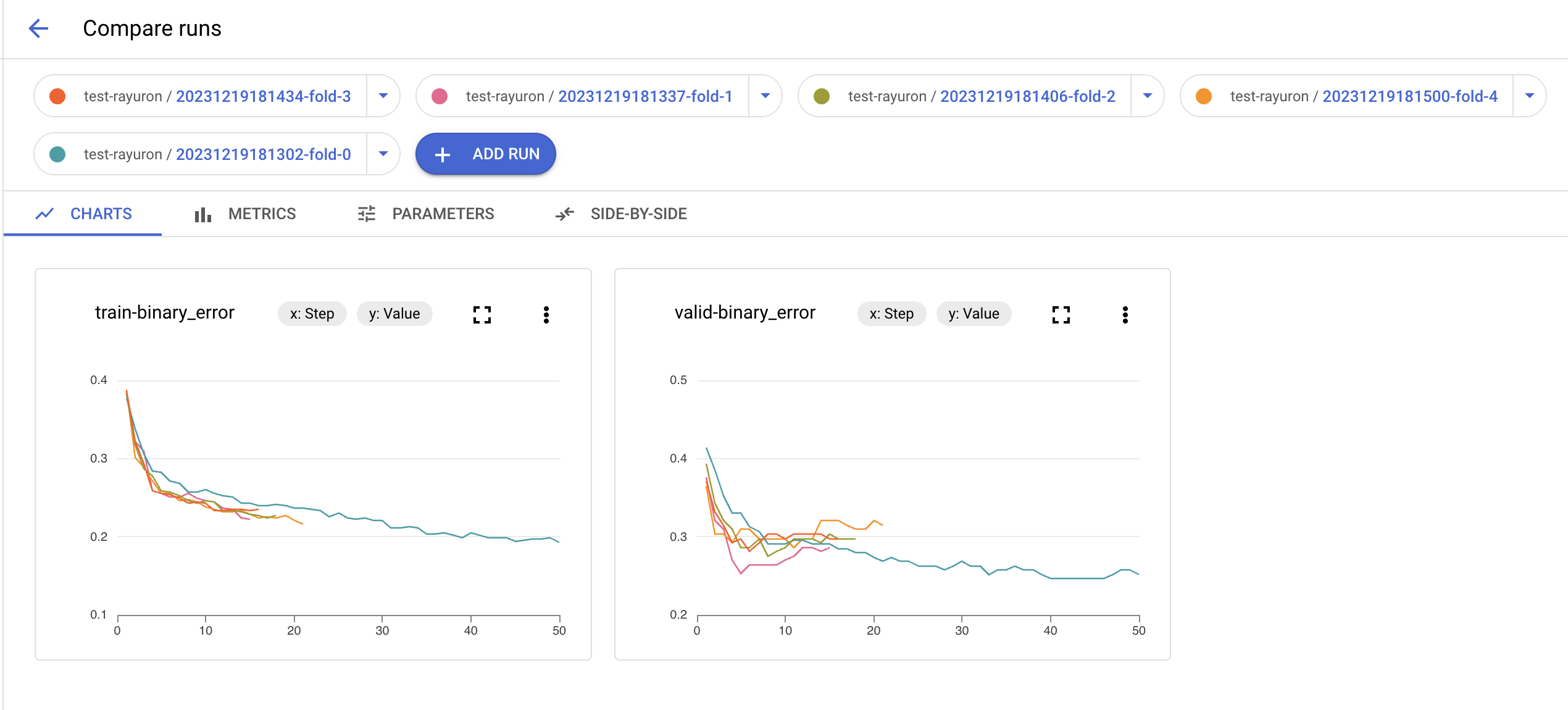
▼ CHARTS タブ
Fold 毎に train loss と validation loss の遷移がグラフで確認できます。
これを使用することで Fold で学習に差が無いかを確認できます。
▼ METRICS タブ
手動でログした best-binary-error, cv に加えて、Autolog 指標の記録も確認できます。

▼ PARAMETERS タブ
学習に使われるハイパーパラメーターが記録されていることを確認できました。
今回は Fold 間でパラメータは同一となっています。

気づき
使用して得た気づきを以下にまとめます。
1. Autolog と手動ログを併用するときは注意
Autolog を手動ログと併用する場合は aiplatform.autolog() の宣言後にaiplatform.start_run(run=run_name) を宣言します。
これによって自動で定義されていた Autolog の run が固定されるので手動ログと併用可能です。
aiplatform.init(
experiment=experiment_name,
project=project,
location=location,
experiment_tensorboard=experiment_tensorboard,
)
aiplatform.autolog()
aiplatform.start_run(run=run_name)
# Your model training code goes here
aiplatform.end_run()
aiplatform.autolog(disable=True)
2. 一度のモデルの学習で Autolog は一度のみ使用可能
学習1回につき Autolog を1回 run する必要があります。
そのため Cross Validation の際は Fold 毎に run を走らせる必要があります。
3. Autolog では最大地点の loss を記録している
Autolog で記録される train loss, validation loss は最大地点を自動記録する挙動でした。
そのため Autolog する指標によっては注意が必要です。
おわりに
本記事では Vertex AI Experiments の一部の機能である Autolog についてご紹介しました。
モデルの実験管理は重要ですが、面倒な時があると思います。
そんな時に、数行コードを追加するだけで上記の課題を解決してくれる頼もしい機能でした。