概要
Rekognitionを使って画像分析を試したかっただけですが、せっかくなのでDynamoDBとQuickShighを用いて結果を可視化してみました。
記事は2つに分かれており、1つめが分析(DynamoDBへ保存)、2つめが可視化(QuickShightを導入)となっています。
構成図
以下、構成図です。
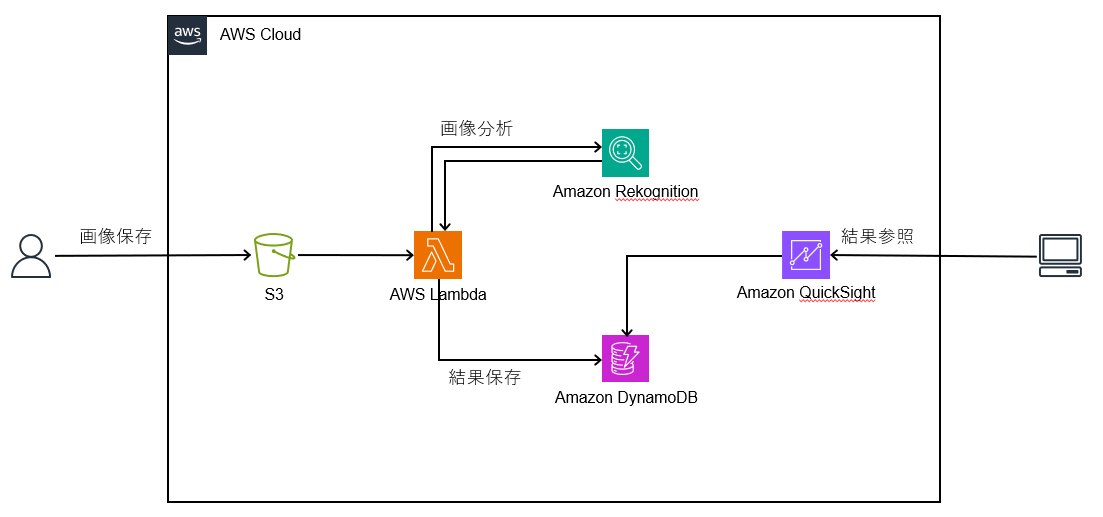
S3に画像が保存されるとLambdaが動作し、Rekognitionにて画像を分析します。
また、分析した結果をDynamoDBへ保存し、QuickShightで可視化します。
手順1(S3構築)
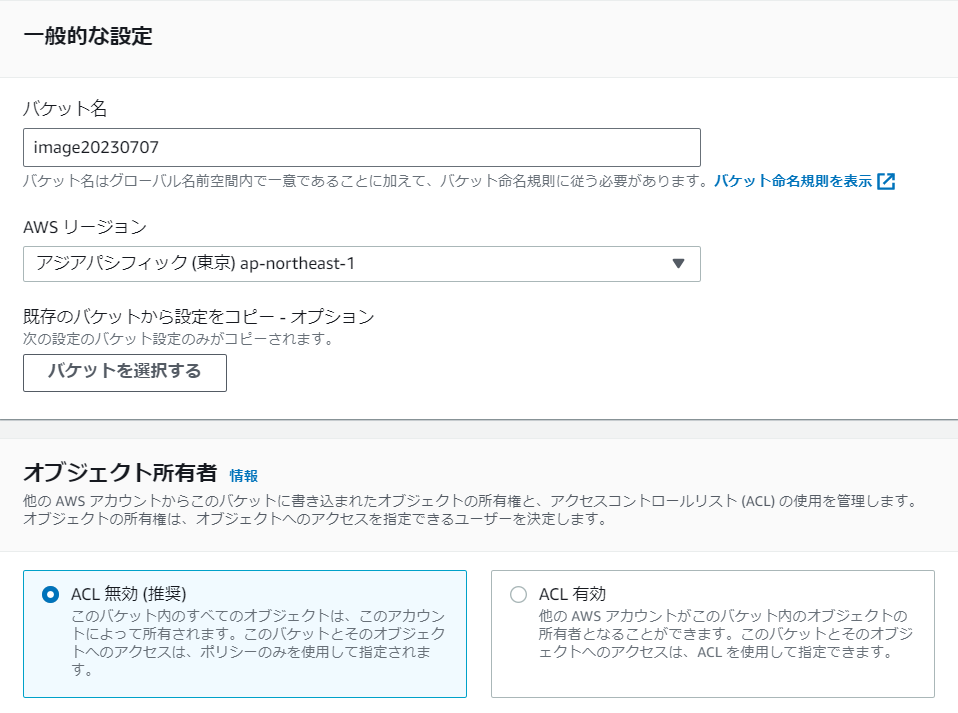
1-1.バケット名を入力し、リージョンは東京、その他はデフォルトのまま設定します。
設定が完了したら、「バケットを作成」を押下します。
手順2(DynamoDB構築)
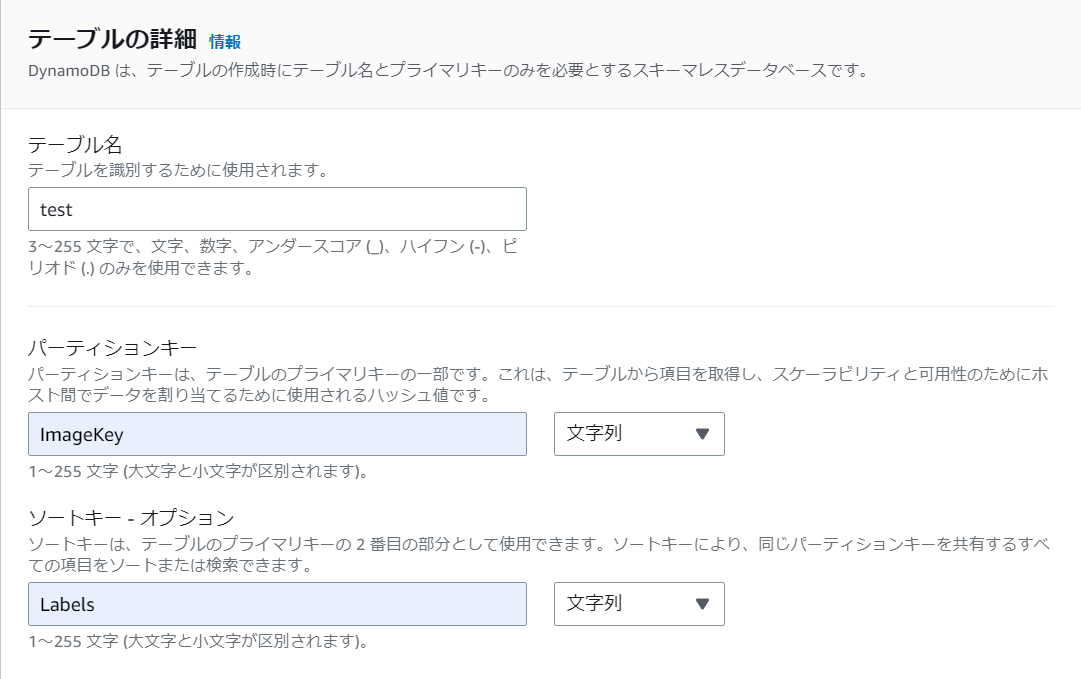
2-1.テーブル名を入力し、パーティションキーへ「ImageKey」、ソートキーへ「Labels」を入力します。
その他はデフォルトのまま設定し、「テーブルの作成」を押下します。
手順3(Lambda構築)
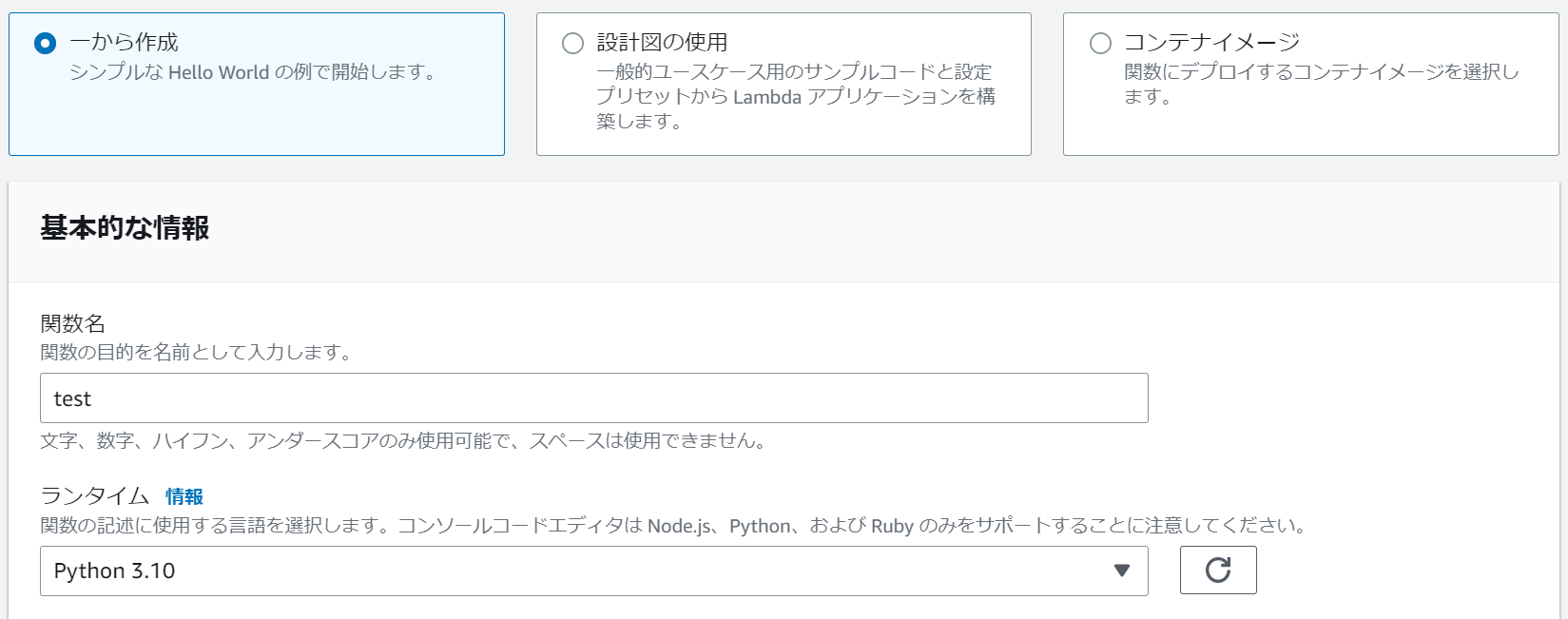
3-1.「一から作成」を選択し、関数名を入力、ランタイムに「Python 3.10」を選択します。
3-2.アーキテクチャに「x86_64」を選択、IAMロールに「既存のロールを使用する(IAMはフル権限つけています)」を選択し、「関数の作成」を押下します。
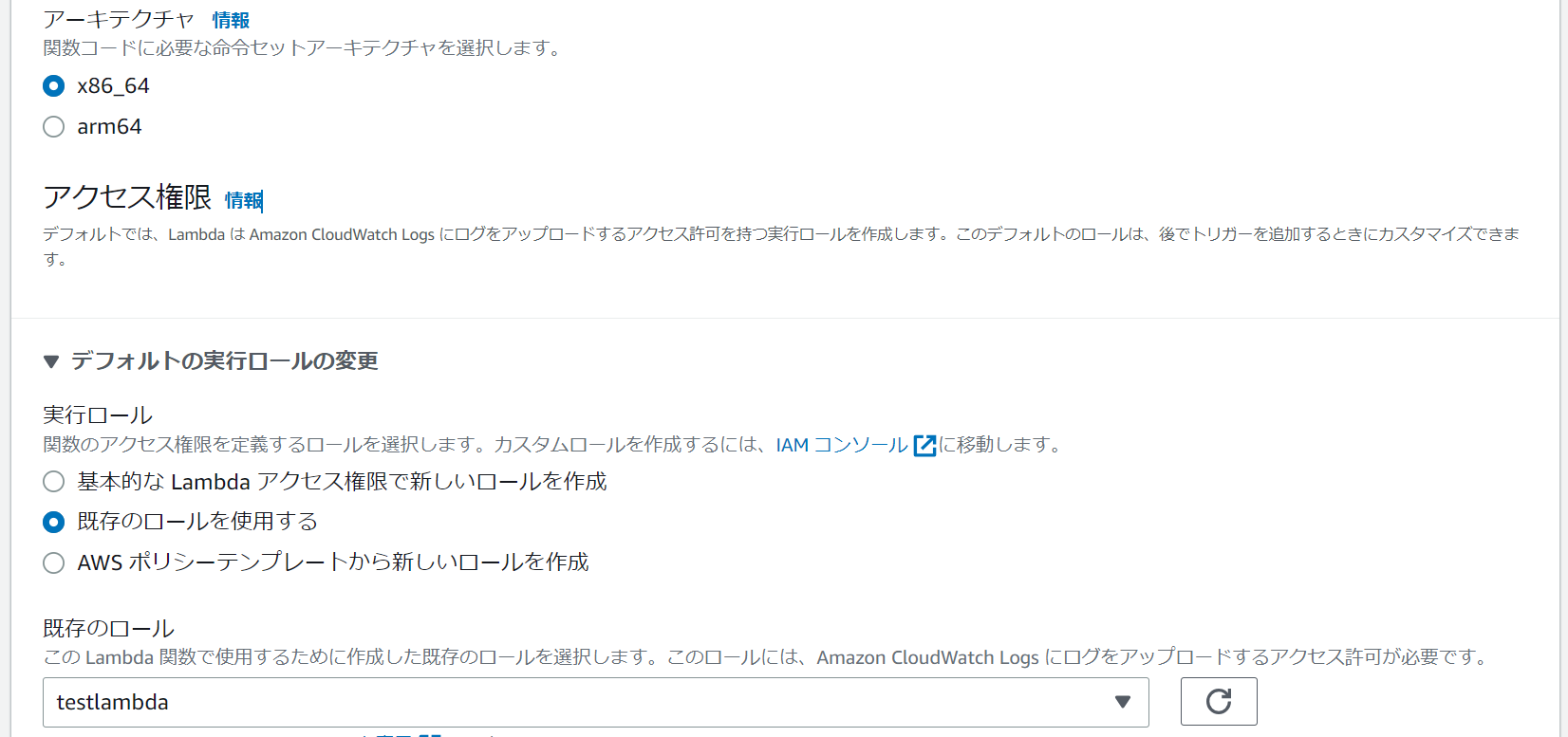
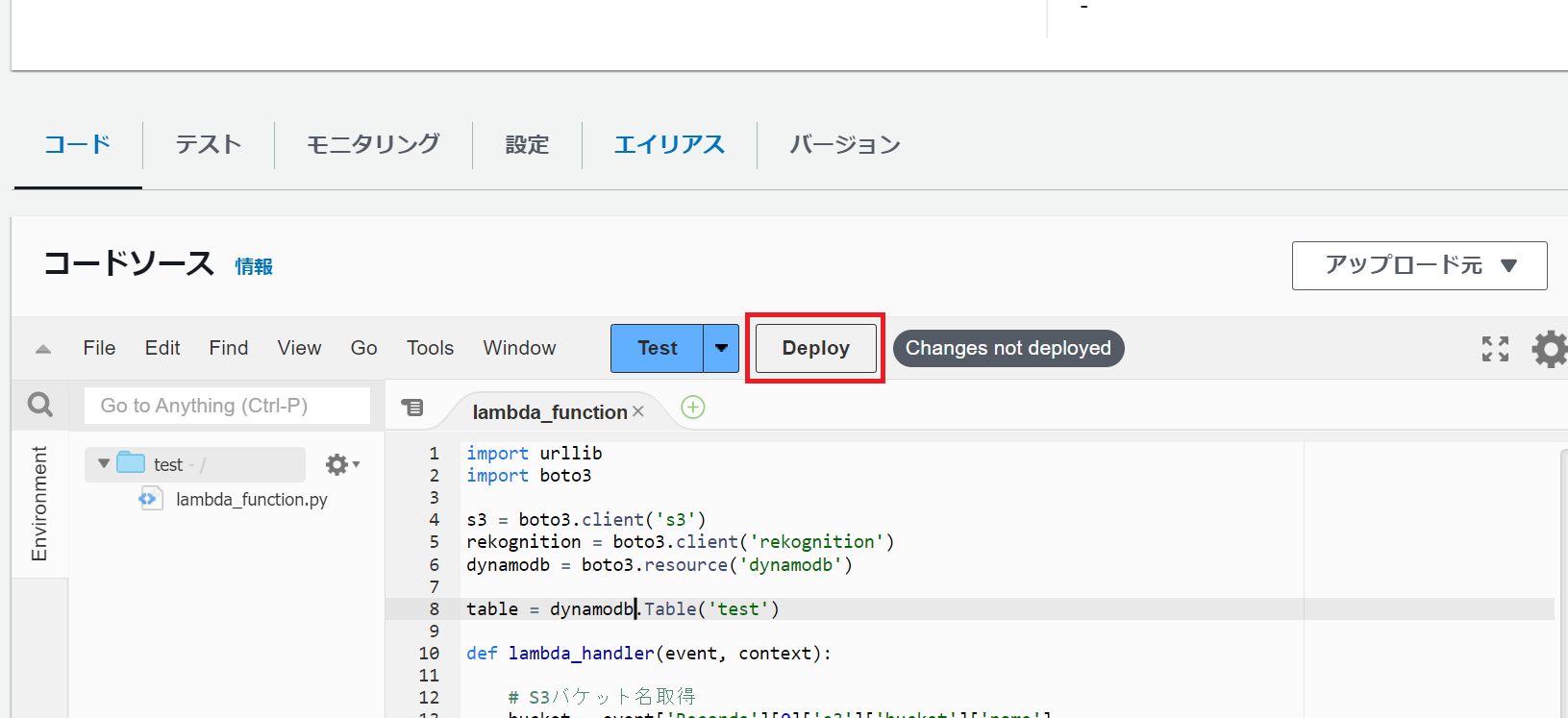
3-3.Pythonコードを記載し、「Deploy」を押下します。
※コードについては以下の「Python」をそのまま使用すれば動作します。
import urllib
import boto3
s3 = boto3.client('s3')
rekognition = boto3.client('rekognition')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('test')
def lambda_handler(event, context):
# S3バケット名取得
bucket = event['Records'][0]['s3']['bucket']['name']
# S3オブジェクト名取得
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
# Rekognitionの実行
detect = rekognition.detect_labels(
Image={
'S3Object': {
'Bucket': bucket,
'Name': key
}
}
)
# ラベルを取得
label = detect['Labels']
label_name = label[1]['Name']
# DynamoDBへ保存
table.put_item(
Item={
'ImageKey': key,
'Labels': label_name,
}
)
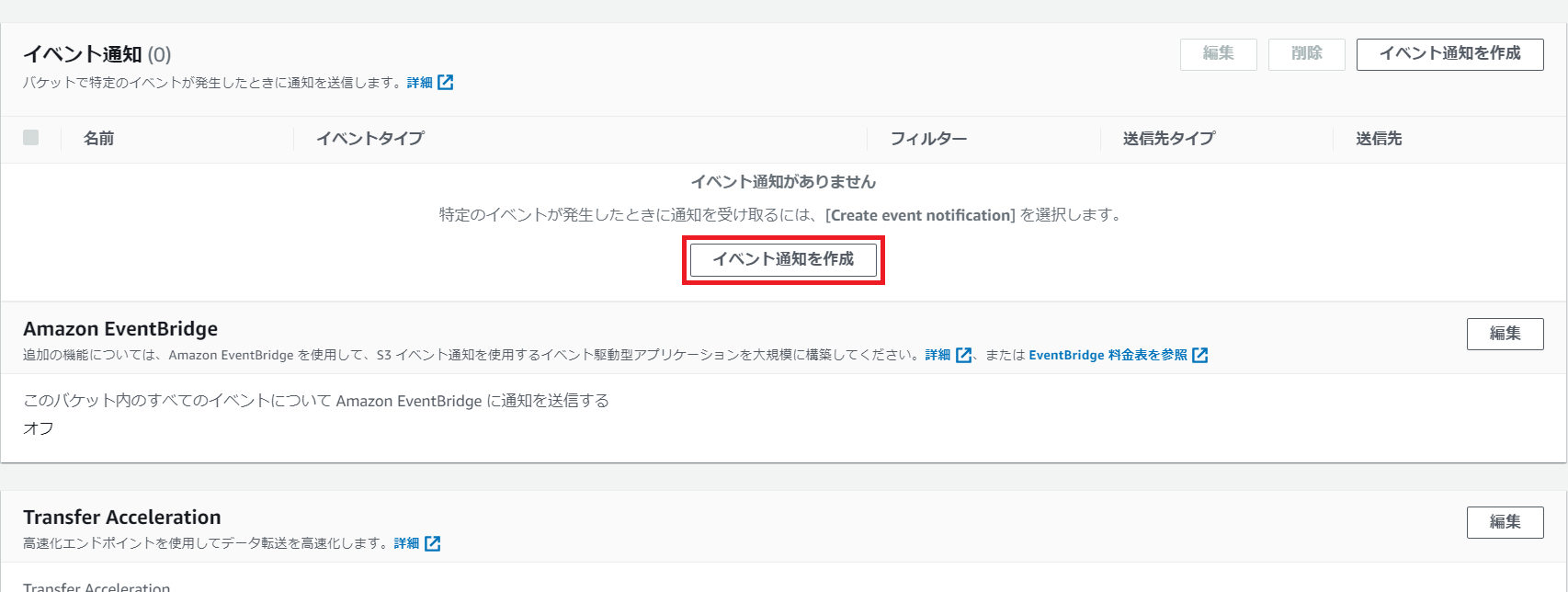
手順4(S3イベント設定)
4-1.「イベント通知を作成」を押下します。
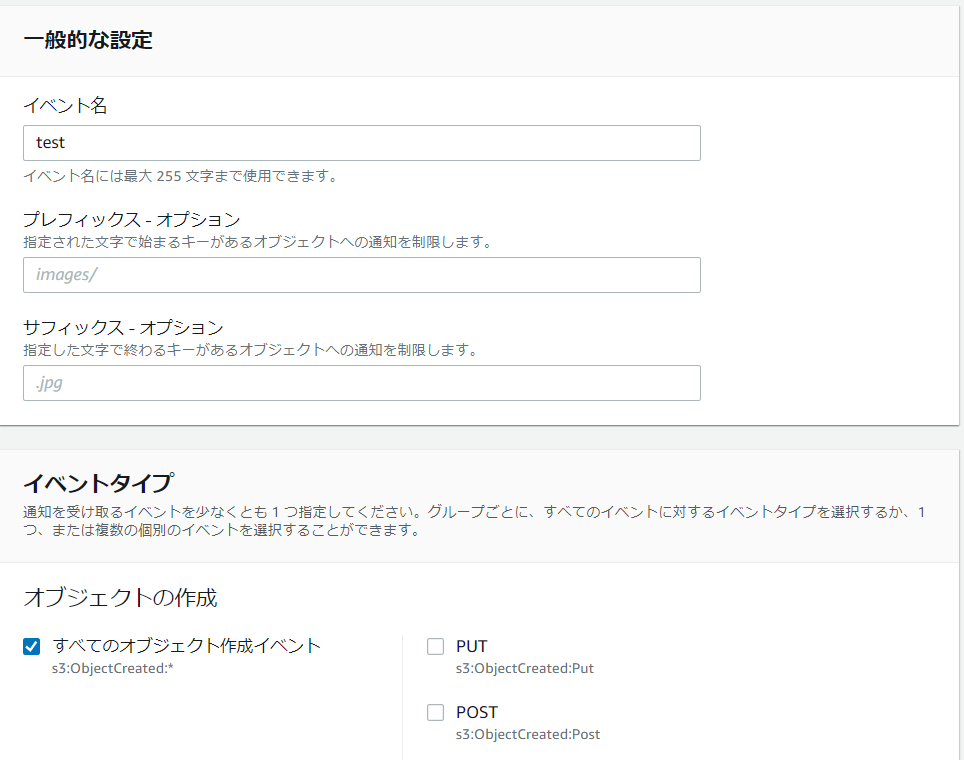
4-2.イベント名を入力し、「すべてのオブジェクト作成イベント」にチェックをいれます。
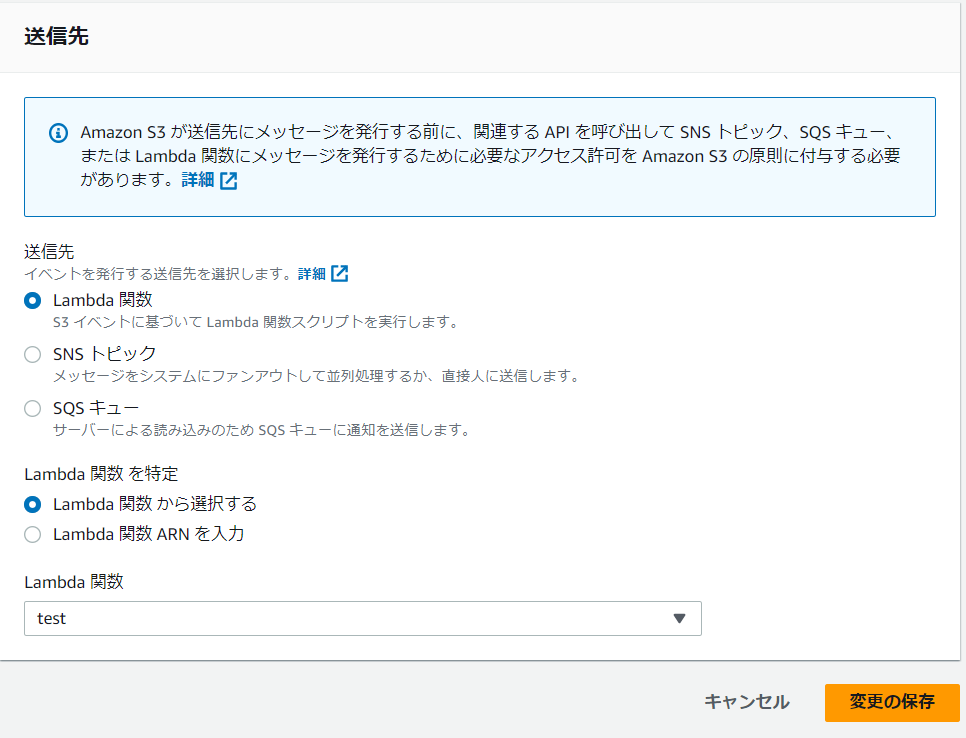
4-3.送信先で「Lambda関数」を選択し、作成した「test」を選択後、「変更の保存」を押下します。
動作確認
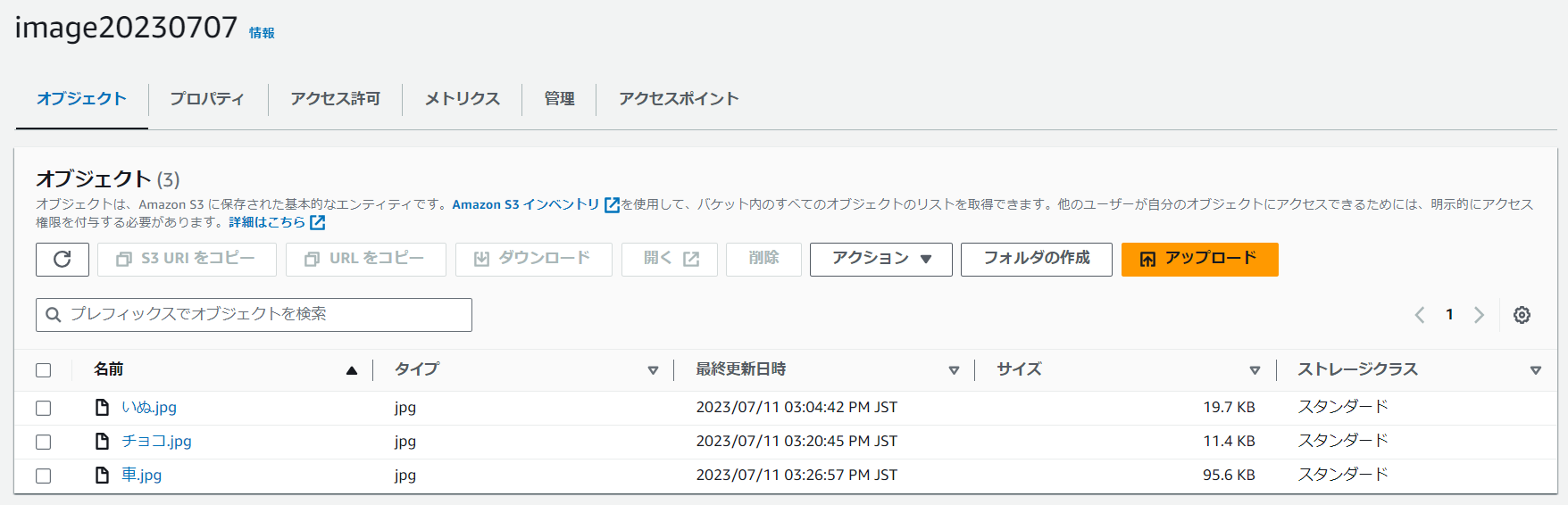
S3へ画像を保存してみます。
今回は、3枚の画像を保存してみました。(犬、チョコレート、車の画像を保存)
※用意したPythonプログラムの仕様上、S3への画像の保存は1枚ずつ実行する必要があります。
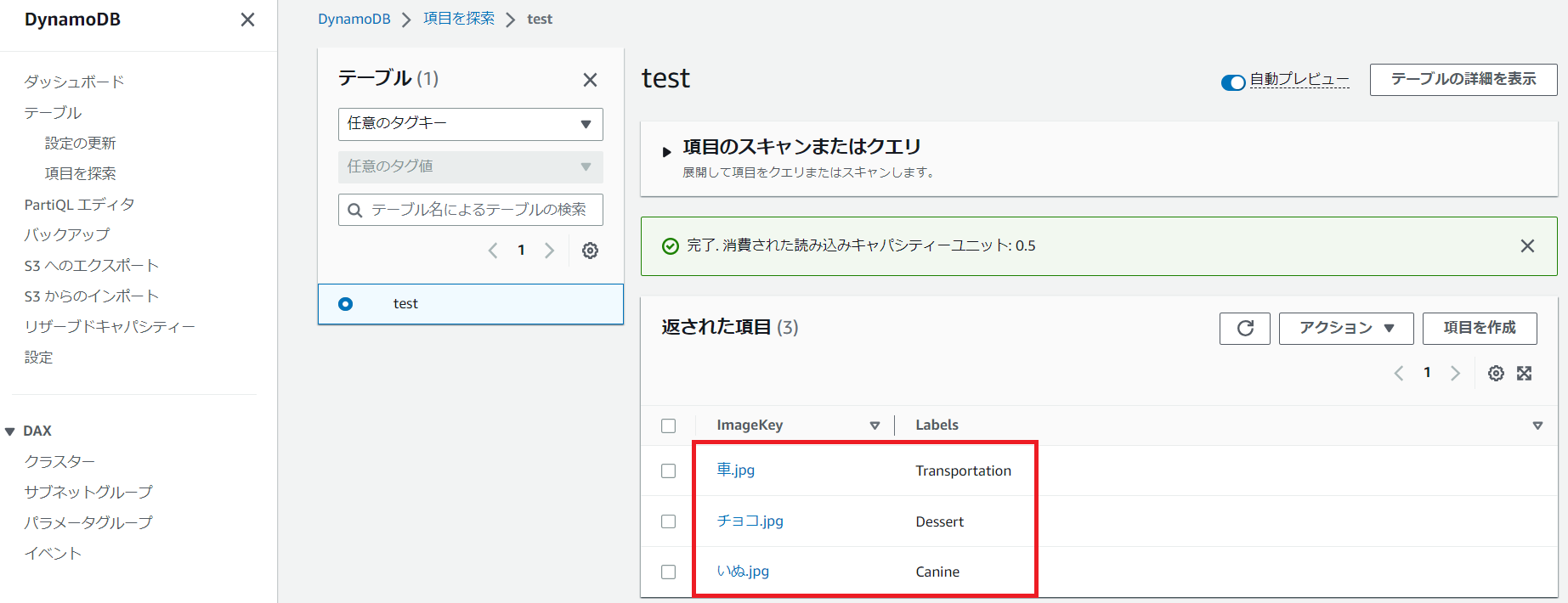
DynamoDBへ分析結果が保存されていることを確認します。
車の画像:Transportation(交通・交通機関)
チョコレートの画像:Dessert(デザート)
犬の画像:Canine(犬科)
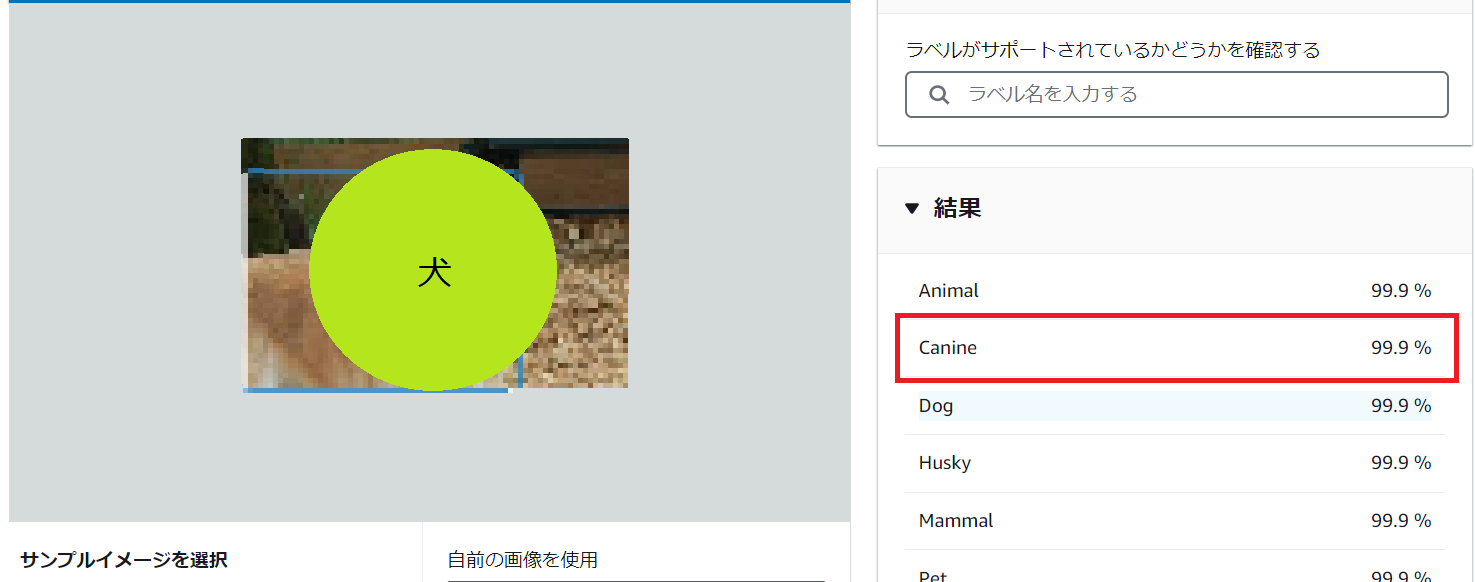
全てニアピンです…。(car、chocolate、dog と分析して欲しかった)
しかしニアピンだったことには理由があります。
Rekognitionは分析結果を信頼度と共に何個も出力します。今回実装しているPythonプログラムでは、信頼度が2番目に高い結果(下記画像参考)を取得しているため、このような結果となりました。
まとめ
今回は、Rekognitionを使って画像分析を行い、結果をDynamoDBへ保存しました。
分析の部分を自分で用意すると、とても多くの時間と苦労が必要ですが、Rekognitionを用いることで簡単に素早く画像分析を実装することができました。
AWSには他にも便利で活気的なサービスがたくさん用意されているので、どんどん試していきたいです。(それにしてもRekognition使いやすい・・・)
次回(2/2)は、DynamoDBに保存された結果を可視化してみたいと思います。