概要
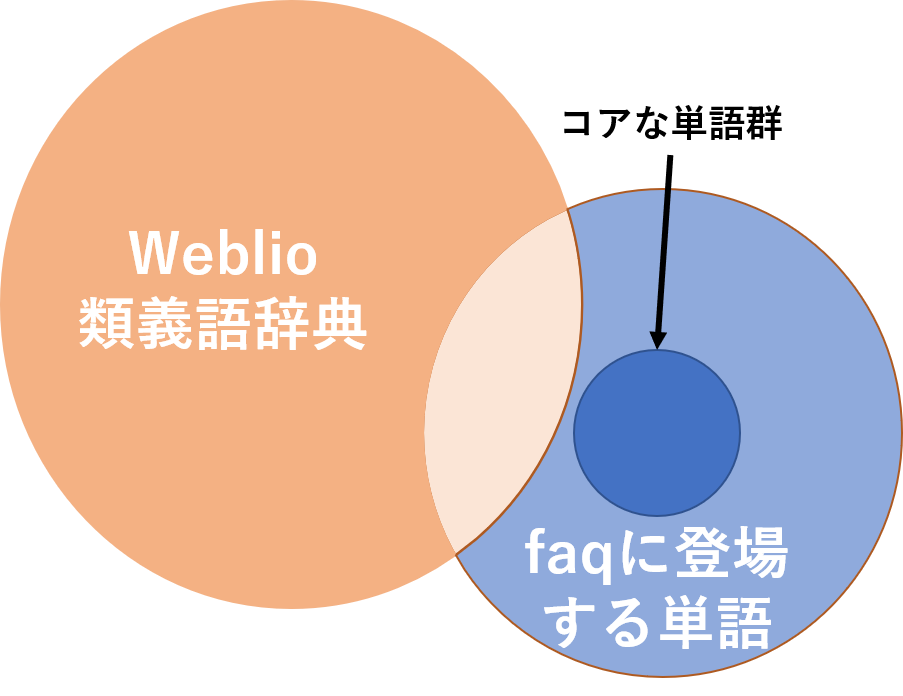
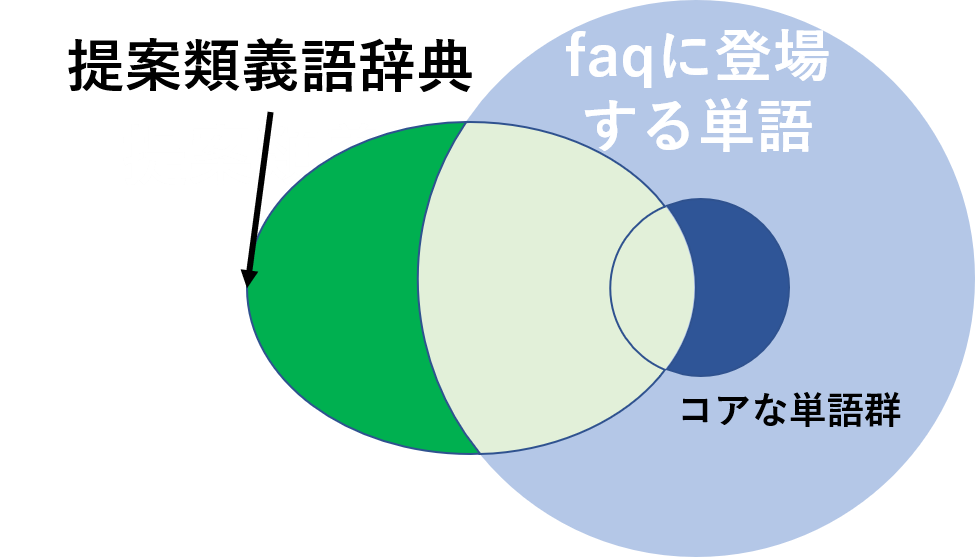
チャットボットの開発をしている株式会社サイシードでインターンをしていて,特定の会社のfaqチャットボットに使う類義語辞典の作成を行っていた.類義語辞典の作成を行う上で,現在使用されているのがweblio提供のオープンな類義語辞典である.しかし,これには使用しづらい単語や特定の会社の固有の単語などが少ないことがあげられる.簡単に表すと下のベン図のようなことになっている.そこで,wikipediaとfasttextを用いることであるトピックに沿った単語を選択し,もう一個下のような図になるようにより少ない単語でよりカバー範囲の高い類義語辞典を作成することが目標である.
実際やったことの概要
- トピックをいくつか準備しwikipediaのページを抜き出す
- 二つのトピックを選び,fasttextでベクトル化し,機械学習で分類できるかを調査
- fasttextがトピックの言葉を区別することができることが確認できれば,fasttextを用いて会社に使われやすい単語はより簡単に選択してくることが可能だと思われる.
- トピック単語セットが現状の類義語辞典に比べてどれくらいのfaq内の単語のカバーが可能かを確認
使用環境
- centos 7.3
- python 3.7
- mecab
- インストール方法
- これは最新版のインストール方法で自分はかなり古いものを使っているため,変えることでよりよくなるかも
- fasttext
- wikipediaデータ
詳細な部分と結果
まず,試したトピックは以下の通り
word_cand = ["車","料理","旅行","システム","Office","Windows","金融","保険","スマートフォン","化粧品","某飲料会社","某化粧品会社"]
wikipediaから特定のトピックを選択するときにページのカテゴリー内にそのトピックの単語が入っていた場合,そのページ内の単語をトピック単語の候補とした.
一つのトピックを1ドキュメントとして,tf-idfを計算し,トピックごとの単語を分別できるかを確認した.
この分別とは例えば車と料理のtf_idfの上位10単語が以下のような感じだとする.
料理 = ['肉', 'スープ', '具', '以子', '鶏肉', '演', 'タマネギ', '牛肉', 'シェフ', '寿司']
旅行 = ['列車', 'ストウ', 'イブン・バットゥータ', '近畿日本ツーリスト', 'ピースボート', 'Airbnb', '貸切', 'レンタカー', 'WILLER', 'ツアー']
料理の中には料理に関係が深そうな単語が,旅行の中には旅行に関係の深そうな単語が存在している.
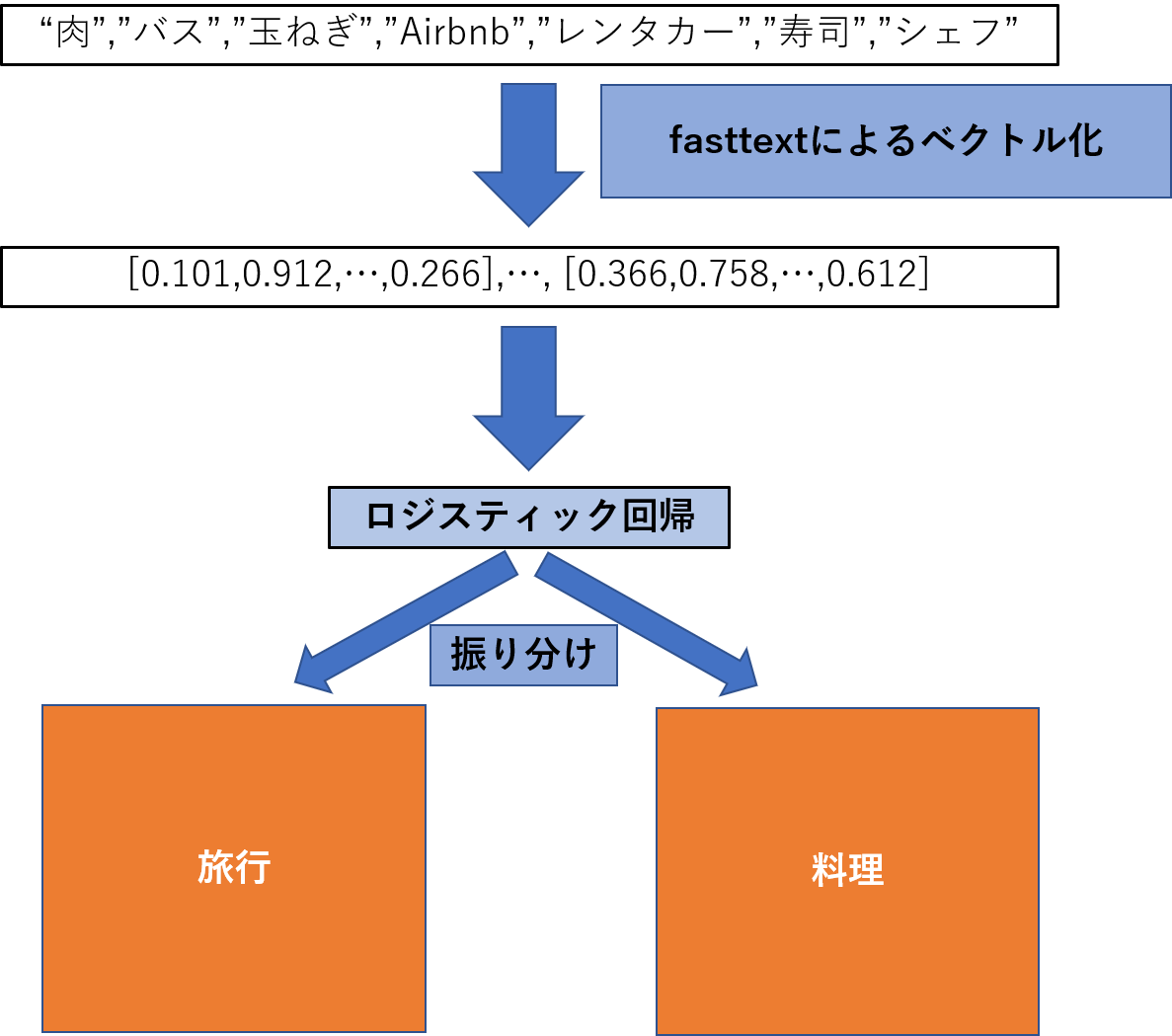
これをfasttextと線形回帰によって以下の図のようなことをしたい.
そして上位n単語を選んで75%をtrain,残りをtestにした時の線形回帰によるaccuracy(どれくらいtestデータが正確にクラスタに分けられたかを)を下のグラフとして結果を示す.
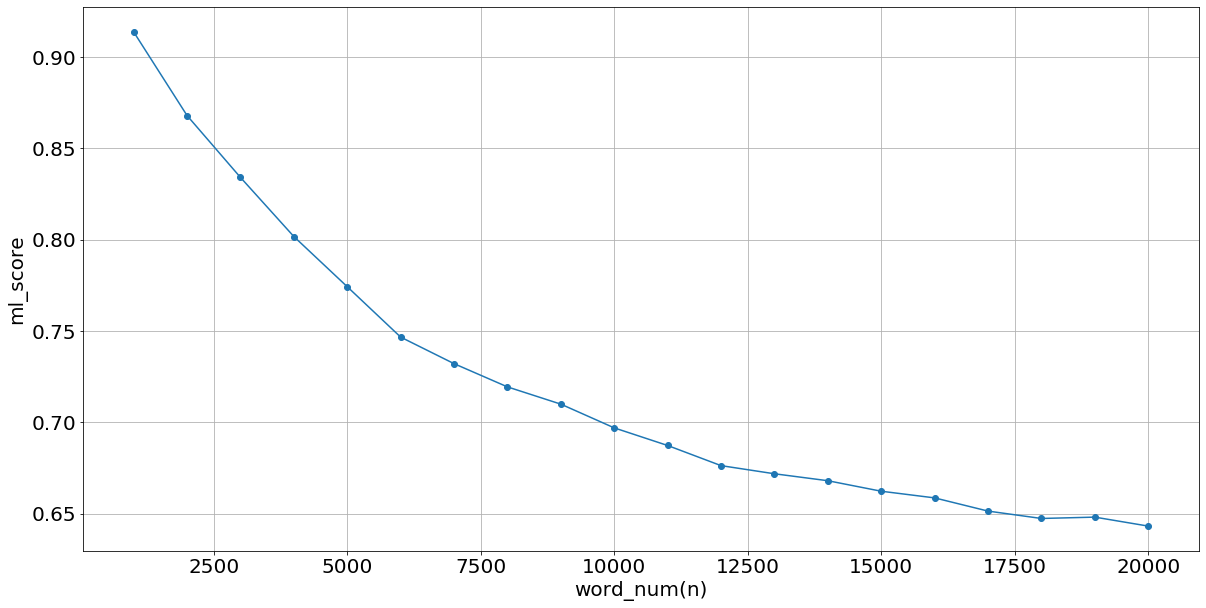
このようにtf_idfの高い場所ではかなりの正答率がある.
tf_idfを使うことによってよりトピックに沿った単語を選べる.
そしてよりトピックに沿った単語を選ぶことができた時ほど,正答率がよくなっている.よってfasttextの空間にはトピックごとのクラスタの様なものが存在し,それらは線形的に分けることができている.
そしてwikiデータの中からtf_idfを使って選択し,fasttext使用して単語数を増やすことでトピックに沿った単語を選ぶことができることが予想できる.
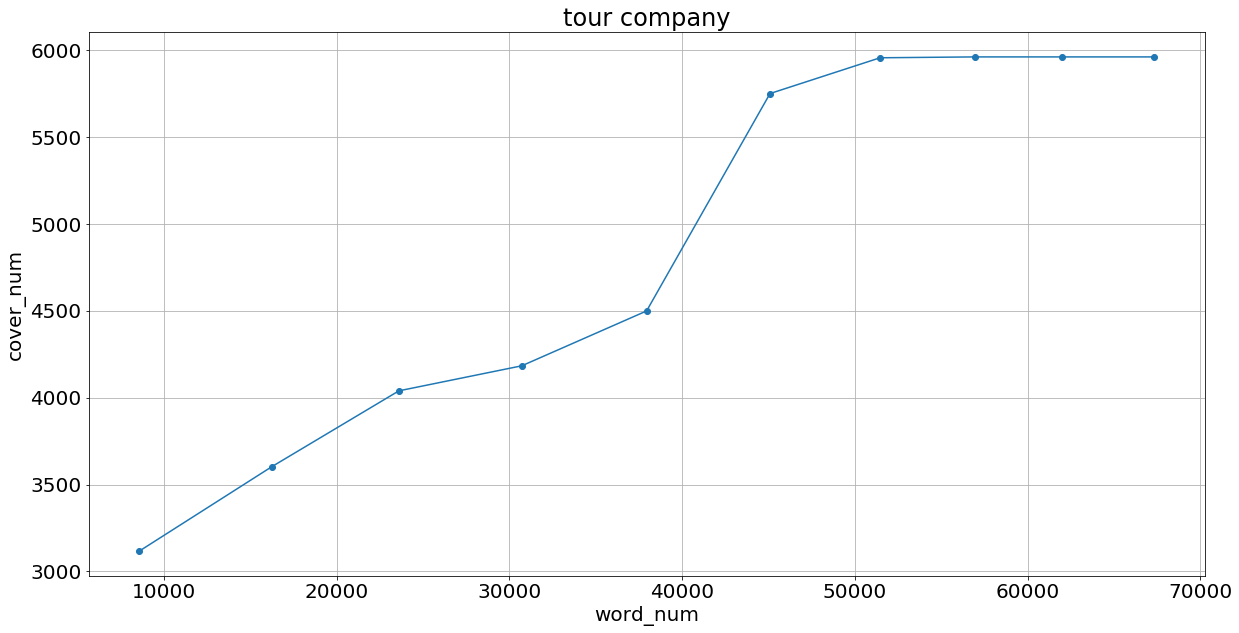
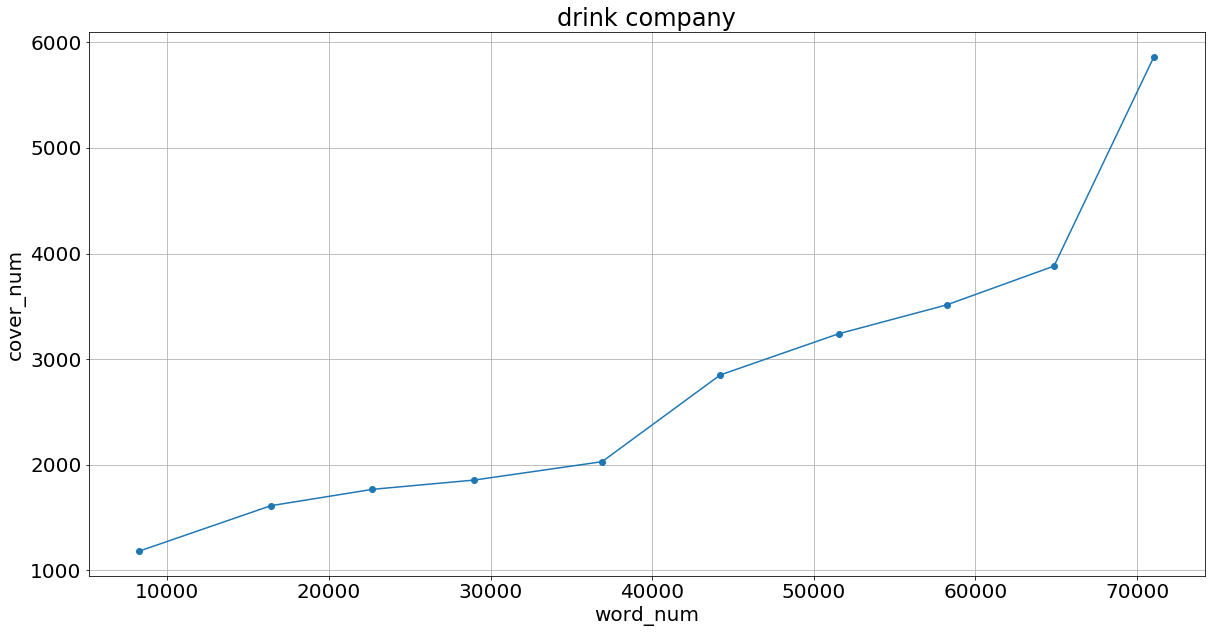
次に,サイシードが持つ某旅行代理店と某飲料会社の実際のfaqの中でどの程度カバー単語数があるのかを確かめた.
カバー単語数とは簡単に言うと上のベン図の重なっている部分である.
しかし,単語ごとに使われているコア単語やあまり使われていない単語がベン図に表しているように存在する.
そこでカバー単語数は単なる単語数ではなく,カバーできた単語の使用数を足し合わせたものである.
某旅行代理店は”旅行”のトピック,某飲料会社には"某飲料会社"のトピックの単語たちを使った.
ここでは上位10000単語まで1000単語づつ選択し,選択した単語をfasttextでの類似度合いが上位5単語かつ類似度が0.4以上であるものを追加することでトピックの言葉をさらに増やす.
ともに某旅行代理店と某飲料会社の結果が以下のようになる.
従来の類義語辞典と比較した場合が以下の表のようになる.
| 言葉の数 | カバー単語数 | 言葉の数/カバー単語数 | |
|---|---|---|---|
| weblio | 144256 | 9040 | 0.062 |
| wiki+fast | 56936 | 5963 | 0.105 |
| 言葉の数 | カバー単語数 | 言葉の数/カバー単語数 | |
|---|---|---|---|
| weblio | 144256 | 5387 | 0.037 |
| wiki+fast | 71042 | 5863 | 0.082 |
この結果からより某旅行会社では少ない単語でそれなりのカバー単語数,某飲料会社では少ない単語でよりよいカバー単語数を示せた.
この違いは某飲料会社では商品名などが存在するため,従来の類義語辞典には載っていないが使われる回数の多い単語が存在するからだと考えられる.
某飲料会社のカバー単語数が最後飛躍的によくなっているのはtf_idfの都合上一般的使われてる言葉が最初には含まれておらず,そこが追加された結果によると考えられる.
まとめ
従来の類義語辞典より効率のよい類義語辞典を作成することができた.ただ,まだ改善点がいくつも存在する.今回は頻出だがどのドキュメントにも使われている単語はtf_idfの性質上選ばれづらい.そのためほかに一般単語集のようなデータを使用することで,さらにカバーできることが想像できる.方法としては,某飲料会社ではなく飲料などあいまいな単語をトピックにし,そこに”某飲料会社”のトピックの単語を上乗せする.すると,一般的な言葉が入りやすくなり改善が見られると想像できる.