初めに
並列処理させないと時間がかかってどうしようもない処理があったため、試して見ました。
-
Kubernetes ClusterではArgoWorkflowというワークフローエンジンが使えるようにしてある -
ArgoWorkflowでは別々のInputファイルを渡したり、並列度を指定できたりするので、いい感じに並列化できた
ということを紹介していきます。
背景
コンテナ化の中で負荷試験を実施することを予定していて、そのために本番 DB のコピーから情報をマスクした DB を用意することを検討していた。
DB のマスク処理自体はバッチ処理として過去に実装されているのでそちらを流用しようとしており、現在この処理はシングルプロセスで順次発行する処理になっているので、本番相当のデータ量だとかなり時間がかかることが分かっている。
どうしたいか?
- テーブル単位で処理を並列に実行したい
- 並列度(同時実行数)を設定したい
手順
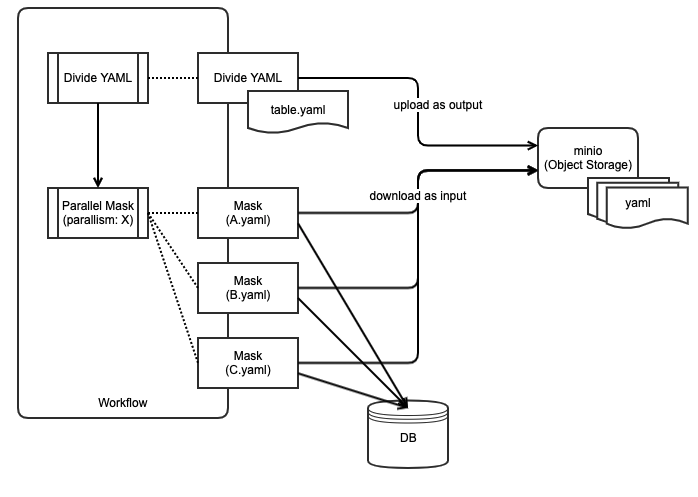
1.初期処理で YAML をテーブル単位で分割
->(これは最初から分割したYAMLをリポジトリを置いておいてもよいが、今回はしていない)
2.分割された YAML をインプットとして、マスク処理を並列で実行
->並列度を指定して、同時に起動されるプロセス数( Pod 数)を固定に
どうなったか
ArgoWorkflow を実現できた!
実行するとこんな感じになります。
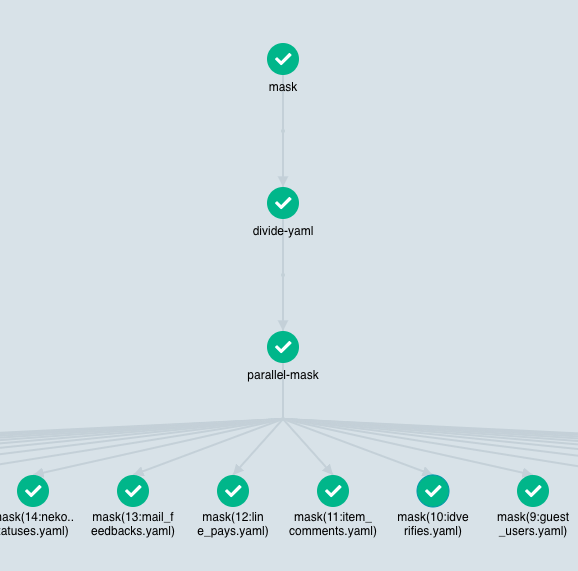
-
mask(XX)という処理( Pod )は設定した同時実行数分起動され、各処理が終わり次第次が始まる -
ArgoWorkflowが設定に合わせてよしなにやってくれる
最後に
こんな感じで並列化させたいなぁというのが、処理自体には特段変更をかけずに ArgoWorkflow の機能を使って実現することが出来ました。
並列化させたい処理がある時、処理Aのアウトプットを処理Bで使いたい時、各処理に依存があるようなワークフローを実行したい時など、ArgoWorkflow を使うと簡単に実現できるので、将来的にいろいろできることは広がるのかなぁと思ってます。