概要
統計局e-stat APIからデータをCSV保存し、それをPandasで整形してプロット
工業統計2017
データ取得までをコピー参照させていただいたサイト
*ここでは上記サイト手法によりすでに全統計表目録データを入手したものとします。
まずは全統計表目録データを取得
# 表のリスト読み込み strとしないと0始まりのデータが0消える。
df = pd.read_csv('data_04/all_stats_list.csv', dtype=str)
# 2017年のデータにする
df = df[df['SURVEY_DATE'].str.startswith('2017')]
カラム項目はどの程度あるのか確認します。
print(df.columns)
'''
Index(['id', 'CYCLE', 'GOV_ORG_val', 'GOV_ORG_code', 'MAIN_CATEGORY_val',
'MAIN_CATEGORY_code', 'OPEN_DATE', 'OVERALL_TOTAL_NUMBER', 'SMALL_AREA',
'STATISTICS_NAME', 'STATISTICS_NAME_SPEC_TABULATION_CATEGORY',
'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY1',
'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY2',
'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY3',
'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY4',
'STATISTICS_NAME_SPEC_TABULATION_SUB_CATEGORY5', 'STAT_NAME_val',
'STAT_NAME_code', 'SUB_CATEGORY_val', 'SUB_CATEGORY_code',
'SURVEY_DATE', 'TITLE', 'TITLE_val', 'TITLE_no',
'TITLE_SPEC_TABLE_CATEGORY', 'TITLE_SPEC_TABLE_NAME',
'TITLE_SPEC_TABLE_SUB_CATEGORY1', 'TITLE_SPEC_TABLE_SUB_CATEGORY2',
'TITLE_SPEC_TABLE_SUB_CATEGORY3', 'UPDATED_DATE'],
dtype='object')
'''
STAT_NAME_valに統計の種類名があるのでユニークな要素を全部出します。
print('STAT_NAME_valユニーク数合計', df['STAT_NAME_val'].nunique())
print(df['STAT_NAME_val'].unique())
'''
STAT_NAME_valユニーク数合計 21
['住民基本台帳人口移動報告' '人口推計' '就業構造基本調査' '科学技術研究調査' '法人企業統計調査' '学校基本調査'
'就労条件総合調査' '農業物価統計調査' '漁業産出額' '農業構造動態調査' '漁業就業動向調査' '作物統計調査' '畜産統計調査'
'食品産業企業設備投資動向調査' '工業統計調査' '商業動態統計調査' '特定サービス産業実態調査' '経済産業省企業活動基本調査'
'経済産業省生産動態統計調査' '製造工業生産能力・稼働率指数' 'ガス事業生産動態統計調査']
'''
面白そうなので工業統計調査をみてみます。
はじめに紹介したサイトの手法により工業統計調査の中の全ての統計表をCSVにし、その中の0003237750[都道府県別、東京特別区・政令指定都市別統計表 (1)従業者4人以上の事業所に関する統計表 1 産業中分類別の事業所数、従業者数、現金給与総額、原材料使用額等、製造品出荷額等及び付加価値額]という統計データの中の各都道府県別の棒グラフをプロットします。
# 数値変換して例外文字は0フィル
df["value"] = pd.to_numeric(df["value"], errors='coerce').fillna(0)
for i in df.columns:
print('-----------------------')
print('カラム', i, 'のユニーク数', df[i].nunique())
print(df[i].unique()[:25])
'''
-----------------------
カラム cat01_code のユニーク数 6
[17000000 18000000 20000000 21000000 22000000 23000000]
-----------------------
カラム 確報(産業編)・集計項目(H25から) のユニーク数 6
['事業所数' '従業者数(人)' '現金給与総額(百万円)' '原材料使用額等(百万円)' '製造品出荷額等(百万円)'
'付加価値額(従業者29人以下は粗付加価値額)(百万円)']
-----------------------
カラム cat02_code のユニーク数 25
[ 0 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
32]
-----------------------
カラム 産業中分類(コード付加) のユニーク数 25
['【00】製造業計' '【09】食料品製造業' '【10】飲料・たばこ・飼料製造業' '【11】繊維工業'
'【12】木材・木製品製造業(家具を除く)' '【13】家具・装備品製造業' '【14】パルプ・紙・紙加工品製造業' '【15】印刷・同関連業'
'【16】化学工業' '【17】石油製品・石炭製品製造業' '【18】プラスチック製品製造業(別掲を除く)' '【19】ゴム製品製造業'
'【20】なめし革・同製品・毛皮製造業' '【21】窯業・土石製品製造業' '【22】鉄鋼業' '【23】非鉄金属製造業'
'【24】金属製品製造業' '【25】はん用機械器具製造業' '【26】生産用機械器具製造業' '【27】業務用機械器具製造業'
'【28】電子部品・デバイス・電子回路製造業' '【29】電気機械器具製造業' '【30】情報通信機械器具製造業'
'【31】輸送用機械器具製造業' '【32】その他の製造業']
-----------------------
カラム area_code のユニーク数 73
[ 12 13 14 15 2000 3000 4000 5000 6000 7000 8000 9000
10000 11000 12000 13000 14000 15000 16000 17000 18000 19000 20000 21000
22000]
-----------------------
カラム 都道府県及び東京特別区・政令指定都市(H29から) のユニーク数 73
['全国計(2012年)' '全国計(2013年)' '全国計(2014年)' '全国計(2015年)' '全国計' '北海道' '青森' '岩手'
'宮城' '秋田' '山形' '福島' '茨城' '栃木' '群馬' '埼玉' '千葉' '東京' '神奈川' '新潟' '富山' '石川'
'福井' '山梨' '長野']
-----------------------
カラム unit のユニーク数 0
[nan]
-----------------------
カラム value のユニーク数 8459
[216262. 208029. 202410. 217601. 191339. 5189. 1386. 2081. 2618.
1800. 2496. 3620. 5154. 4218. 4794. 10975. 4815. 10789.
7697. 5339. 2717. 2861. 2161. 1764. 4994.]
'''
統計表の各カラムに対するユニーク数とユニーク名を取得しています。
CSVを開いてみれば良いものをなぜこんな手間を掛けるかというと、20メガバイトもあり
エクセルはおろかテキストエディタでもハングするからです。
今回は都道府県別に各産業別の統計表を作りたいのですがこのデータの中には全国計(つまり合計値)と各市町村、製造業計(つまり合計値)が含まれているのでドロップします。
# 全国集計と各市町村を落とす(都道府県のみにする)
droplist = ['全国計(2012年)', '全国計(2013年)', '全国計(2014年)', '全国計(2015年)', '全国計', '札幌市', '仙台市', 'さいたま市', '千葉市', '東京特別区', '横浜市', '川崎市', '相模原市', '新潟市', '静岡市', '浜松市', '名古屋市', '京都市', '大阪市','堺市', '神戸市', '岡山市', '広島市', '北九州市', '福岡市', '熊本市']
for i in droplist:
df = df[df['都道府県及び東京特別区・政令指定都市(H29から)'] != i]
# 製造業計のみにする
df = df[(df['産業中分類(コード付加)'] == '【00】製造業計')]
そしてそれをプロットします。
g = sns.barplot(x='都道府県及び東京特別区・政令指定都市(H29から)', y='value', hue='確報(産業編)・集計項目(H25から)', data=df)
g.set_xlabel('都道府県')
g.set_title(
'2017年 地域別 1. 都道府県別、東京特別区・政令指定都市別統計表 (1)従業者4人以上の事業所に関する統計表 1 産業中分類別の事業所数、従業者数、現金給与総額、原材料使用額等、製造品出荷額等及び付加価値額')
plt.xticks(rotation=90)
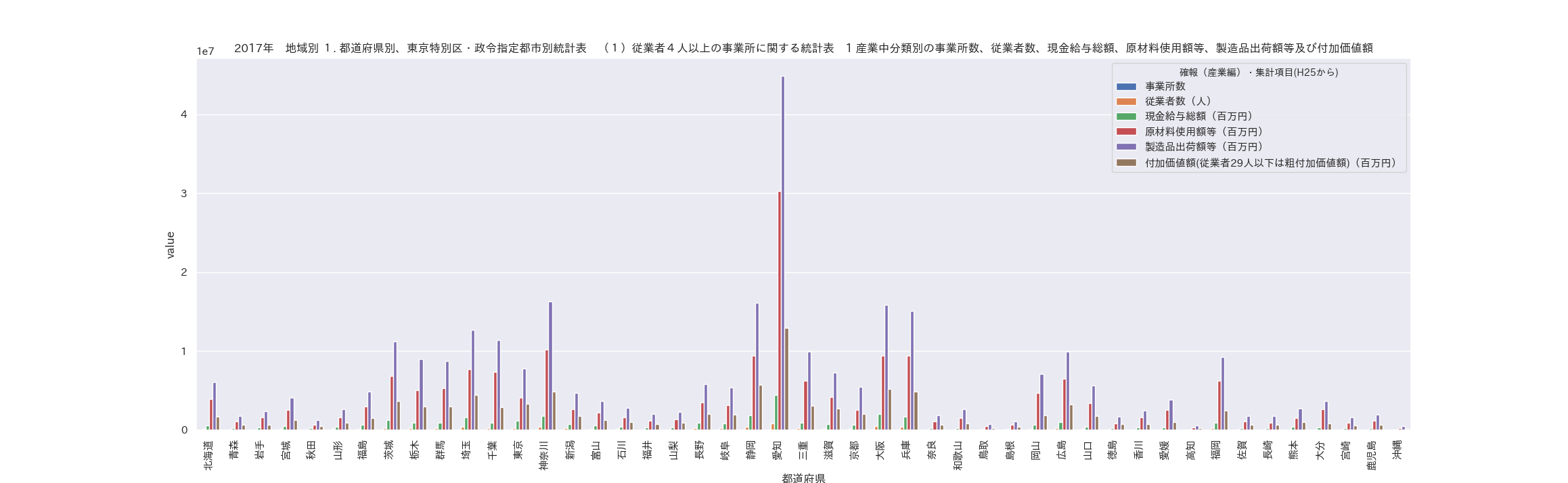
愛知が大きいのは自動車産業がありその影響でしょうか。
確か社会の時間に習ったような気もします。
人口統計2018
続いて今度は各都道府県別人工の入出統計をプロットします。
df = pd.read_csv(file)
# 各カラムのユニーク数とユニークの種類をn個以下なら排出
for i in df.columns:
print('-----------------------')
print('カラム', i, 'のユニーク数', df[i].nunique())
print(df[i].unique()[:10])
print(type(df[i].unique()))
'''
-----------------------
カラム cat01_code のユニーク数 1
[0]
-----------------------
カラム 性別 のユニーク数 1
['総数']
-----------------------
カラム cat02_code のユニーク数 7
[ 0 201 202 203 204 205 206]
-----------------------
カラム 年齢 のユニーク数 7
['総数' '0~4歳' '5~9歳' '10~14歳' '15~19歳' '20~24歳' '25~29歳']
-----------------------
カラム cat03_code のユニーク数 4
[1 2 3 4]
-----------------------
カラム 都市間移動者数・その他 のユニーク数 4
['他市町村からの転入者数' '他市町村への転出者数' '転入超過数' 'その他']
-----------------------
カラム cat04_code のユニーク数 2
[60000 61000]
-----------------------
カラム 国籍 のユニーク数 2
['移動者(外国人含む)' '日本人移動者']
-----------------------
カラム area_code のユニーク数 2386
[ 0 1 2 1000 1001 1002 1100 1101 1102 1103 1104 1105 1106 1107
1108 1109 1110 1202 ]
'''
都道府県以外のいらない項目データが混じっているのでドロップします。
df_pr = df[(df['全国・都道府県・市区町村2018~'].str.endswith(('都', ' 道 ', '府 ', '県')))]
そしてまずは入出者別でプロット
g = sns.barplot(x='全国・都道府県・市区町村2018~', y='value', hue='都市間移動者数・その他',
data=df_pr)
g.set_ylabel('人')
g.set_title('各都道府県移動者数 入出者別')
plt.xticks(rotation=90)
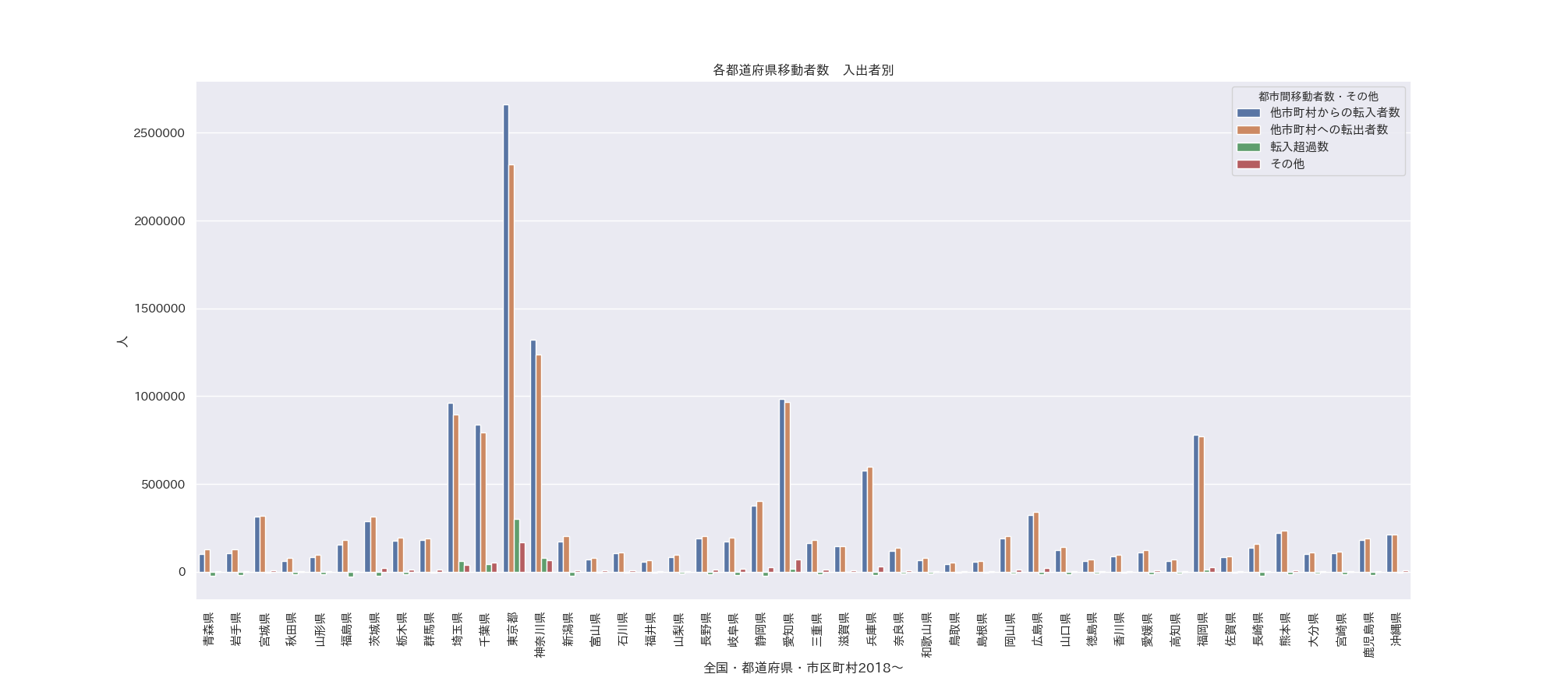
このグラフは統計局のデータと合っている。
見事に東京都とその近辺のみ人口が増えていて、それ以外は減少していることがわかりますね。
東京はいったいどこまで人口が増えていくのでしょうか。
次に国籍別でプロット
g = sns.barplot(x='全国・都道府県・市区町村2018~', y='value', hue='国籍',
data=df_pr)
g.set_ylabel('人')
g.set_title('各都道府県移動者数 国籍別')
plt.xticks(rotation=90)
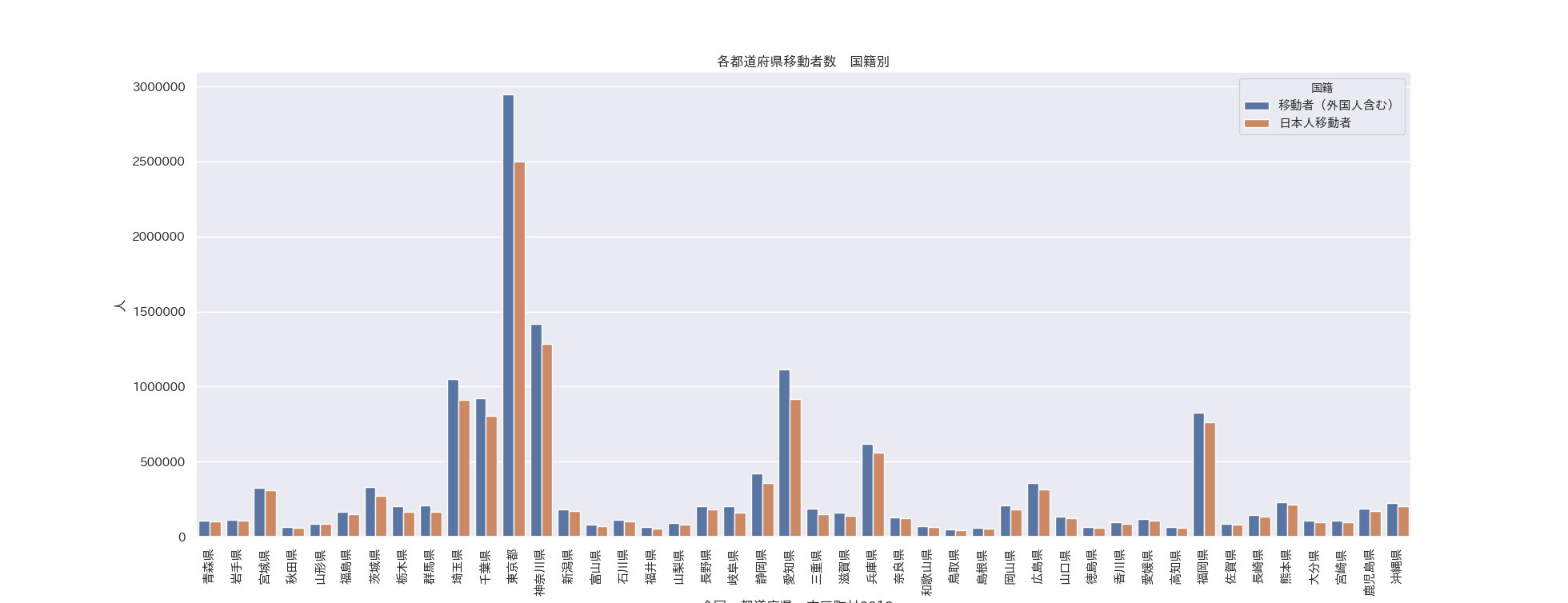
青色は常に日本人と外国人の合算なので、純増は差分を見ることになります。
次に年齢別でプロット
g = sns.barplot(x='全国・都道府県・市区町村2018~', y='value', hue='年齢',
data=df_pr[(df_pr['年齢'] != '総数')])
g.set_ylabel('人')
g.set_title('各都道府県移動者数 年齢別')
plt.xticks(rotation=90)
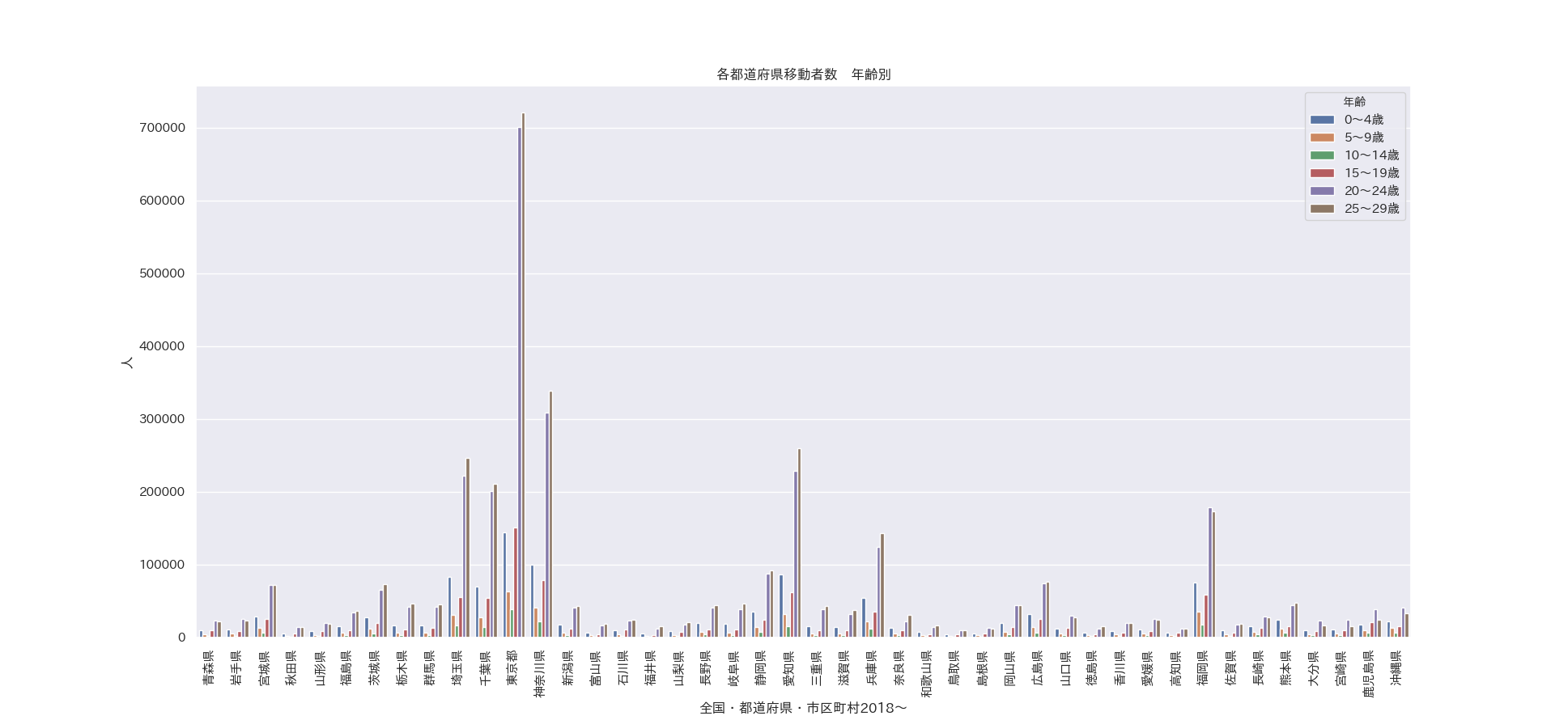
統計局のデータはなぜか5歳区分で29歳までのデータしかありませんでした。
社会人になった20代以降の移動が多いことが見て取れます。
10~14歳よりも5~9歳のほうが移動が多いのはなぜなのでしょうね。
詰まったこと
統計局のデータは単純にカラムで分けられているわけではなく行内でも区分されているので
分類が難しかった。ひとつひとつ見ていくことが必要。