初めに
こんにちは、AIエンジニアを目指しているmitaです!
今回は
ProDistill: Scalable Model Merging with Progressive Layer-wise Distillation
という、大規模モデルを効率的にマージするための新手法に関する研究を要約&考察していきます。
キャッチアップした内容を共有していくので、何かしらの形でお役に立てれば光栄です!
論文要約
- 従来のモデルマージは特定条件下で性能劣化する。学習に必要なデータ量も大きい
- 少ないデータと少ないストレージ使用で高性能なモデルを作成するための手法として層ごとに蒸留してマージするProDistillという手法を提案
- 従来のモデルマージより性能向上。メモリ爆発問題も解決
論文詳細
論文背景
- モデルマージは「タスクベクトル(微調整による差分)」を加重平均して統合するのが基本。
- しかし:
- データなしだと性能が落ちる(理論的にも「必ず劣化する場合がある」と証明)。
- 全層を一気にマージすると計算・メモリコストが膨大。
- そこで「少量データを活用しつつ」「層ごとに段階的に」マージする手法が必要。
論文内容
-
理論的解析
- データなしマージは最悪ケースで大幅劣化することを示す。
- 少量の特化データが性能改善に不可欠。
-
ProDistill の仕組み
- 層ごとにマージ後モデルと教師モデルの 中間表現を一致させるよう λ(マージ係数)を学習。
- 損失関数は「中間表現のL2距離」。
- 学習は 層ごとに順番に進めることで、メモリ効率を改善。
- dual input 設計で特徴の整合性をさらに強化。
-
比較対象
- Task Arithmetic, Fisher Merging, RegMean, AdaMerging, Localize-and-Stitch など既存手法。
結果
-
Vision (ViT-B-32)
- ProDistill は平均 86.04%、既存より +6.14% 改善。
- 特徴表現の可視化でも、クラス分離が鮮明。
-
NLU (RoBERTa, GLUE)
- 平均で +6.61% 改善。ほぼ全タスクで SOTA。
-
LLM (LLaMA2 13B 系)
- WizardMath × Llama-2-Code などのマージでも有効。
- 100億パラメータ級でもスケール可能。
-
効率性分析
- データ効率:1ショットでも性能大幅改善、256ショットで個別モデルに肉薄。
- 計算効率:10エポック程度で収束。
- メモリ効率:層ごと最適化によりメモリ使用量が激減。
モデルマージとは
- 事前学習モデル θ₀ と タスク特化モデル θᵢ の差分を「タスクベクトル τᵢ」と呼ぶ。
- マージはこの差分を加重平均して θ₀ に加える操作。
タスクベクトルとは
- タスクベクトル τᵢ = θᵢ − θ₀
- 「タスク i に合わせてどれだけ事前学習モデルが変化したか」を表すベクトル。
- 辞書の例えでいうと「特化分野の追加ページ」。
個人的感想
論文解釈
モデルマージは特定ドメインに対する高性能を持つモデル同士を結合し、複数ドメインで活躍するモデル作成に貢献している。
しかし各タスクに対するタスクベクトルの差が大きいときや、学習データが少ないときはマージ後のモデル性能が落ちることすらある。
また、モデルマージを実行する際は下記のようにスケーリング係数λとタスクベクトルτの差をかけたうえで総和を取るため、計算コストが膨大になる。
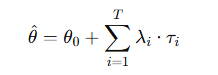
この論文はそれらの課題を解決するための研究だ。
通常モデルマージの際スケーリング係数λは固定して計算をするが、本論文ではλをマージ後モデルの層出力が教師モデルである各タスク特化モデルの層出力に近づくように各層ごとに蒸留を用いて調整することによって、メモリ爆発を抑制したうえで全体の出力の精度を高めた。
考察(感想)
前回読んだDisTaCという手法の蒸留では、マージ前のモデル全体の出力を最適化するように蒸留を行っていました。一方、本論文では、マージ後モデルの出力が各教師モデルの層ごとの出力に近づくよう、層単位で蒸留を実施しています。
……正直、頭がこんがらがってきますね。
間違いがないよう注意しながら記事を書いていますが、自分自身まだ完全に理解しきれているわけではなく、勉強不足を痛感します。特に数式の理解が追いつかない部分もあるため、できる限り「論文の新規性」と「それをどのように実現しているのか」に注目して読み解くよう心がけています。
ただ、生成 AI を活用して読み進めていると、自然言語と数式がふと結びつく瞬間があり、それまでただの記号に見えていた数式が意味を帯びて感じられる瞬間があります。この感覚をもっと味わえるよう、今後も精進していきたいと思います。
本論文も 同一アーキテクチャを前提としたモデルマージ手法でした。当初の目的であった「異なるアーキテクチャを統一する手法」についても調べてみましたが、直接異なるアーキテクチャを結合する方法はまだ見つかりませんでした。その代わりに、「異なるアーキテクチャを一度同一アーキテクチャに変換してからマージする」 という手法が取られていることが分かりました。
次回は、既存の手法の分類や今後の研究方針を整理している論文を読み、どの研究にアーキテクチャ変換の記述があるのか、そして今後どのような研究が必要とされているのかを探っていく予定です。