はじめに
複数のコンテナを使ってエンジニアにリモートデスクトップ環境を提供している場合、各コンテナの状況を可視化する方法を確認した。具体的には、各コンテナでChromiumの並列ビルドを実行し、各コンテナのCPU使用率やRAM使用量がどのように変動するかを、ダッシュボードを通じてリアルタイムで簡単にモニタリングした。この可視化により、リソースの負荷状況を把握し、必要に応じて対策を講じることができる。
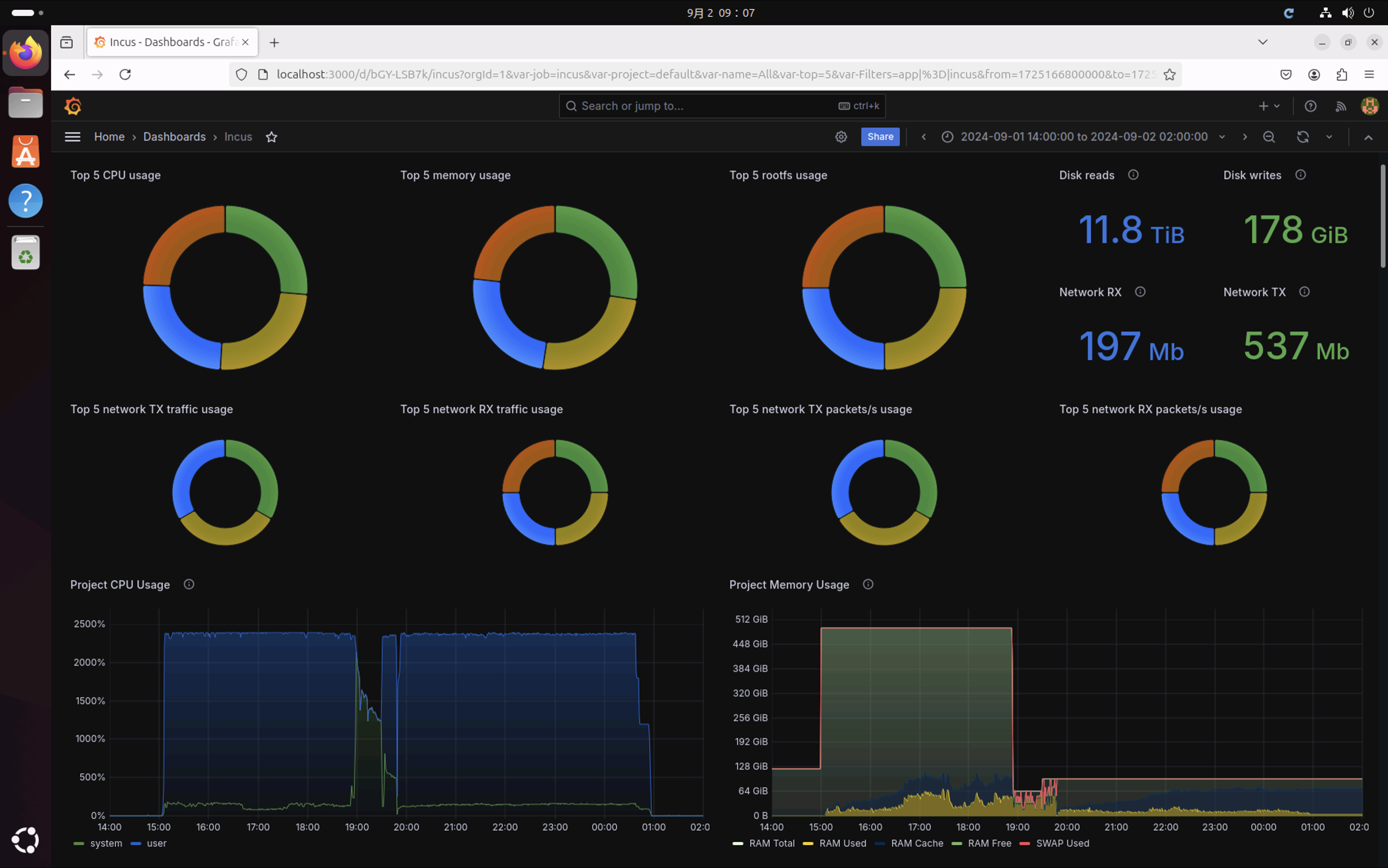
下図はChromiumをビルド中のIncusの状況を示すある時点でのダッシュボードのスクリーンショットである。このようなダッシュボードでコンテナの状況を確認するための環境を構築する。
まとめ
Chromiumのビルド中にフォーカスしてコンテナのメトリックスをダッシュボード表示することで下記の事実を確認できた。
- 15:00過ぎにビルドを開始し日を跨いで1:00頃にビルドが終了した
- 多少の誤差はあるがCPUとRAMの割り当ては均衡に行われている
- ディスク読み込みが約12TiB、書き込みが178GiBとChromiumのビルドの負荷を再確認した
- メモリリミットを設定した19:00頃(16GiBx4)と19:30頃(24GiBx4)のタイミングでRAM上限が変更されている
-
-j6を設定した20:00頃のタイミングでプロセス数が削減されている -
-j6を設定した20:00頃のタイミングでメモリ使用量が削減されている - ネットワークはコンテナ
nobleのネットワークが途中で切れていたため3分割されている

前提
前回の記事で作成したインスタンス(noble)が動作している前提で進める。
ネットワーク環境
今回の記事のネットワーク環境を示す。記事の初期段階ではクライアントPC、ホストPC、コンテナ(noble)が動作している。途中でコンテナnoble2、noble3、noble4を追加する。

Incusのメトリクスを監視する
公式ドキュメントを参考に進める
次の3つの作業を行う
- Prometheusをセットアップする
- Lokiをセットアップする
- Grafanaダッシュボードをセットアップする
Prometheus
Prometheusは、オープンソースの監視システムおよび時系列データベースで、主にメトリクスデータ(CPU使用率、メモリ使用量など)を収集し、アラートを生成するために使用される。多くのインフラやサービスのパフォーマンスを監視するために広く使われており、効率的なメトリクス収集とクエリ処理が特徴のツール。
Loki
Lokiは、Prometheusのログバージョンとも言えるオープンソースのログ集約システムだ。メトリクスと同様にログデータを収集し、必要な情報をラベル(タグ)に基づいて素早く検索できる。Lokiは、フルテキストインデックスを行わず、メタデータのみをインデックス化することで、運用コストを抑えつつ効率的なログ管理を実現している。
Grafana
Grafanaは、PrometheusやLokiなどからデータを取得し、それらをダッシュボード上に可視化するオープンソースのツールだ。豊富なプラグインやカスタマイズオプションを提供し、ユーザーがリアルタイムでシステムの状態を監視したり、過去のデータを分析したりするための強力なビジュアル化機能を備えている。
これら3つのツールは組み合わせて使われることが多く、システム監視や運用における強力なソリューションを提供する。Prometheusでメトリクスを収集し、Lokiでログを管理し、Grafanaでそれらを一元的に可視化することで、インフラ全体の健全性を効率的に監視する。
Prometheusをセットアップする
Prometheusをインストール
PrometheusパッケージをホストPCにインストールする
sudo apt-get update && \
sudo apt-get upgrade -y && \
sudo apt install prometheus prometheus-node-exporter -y
Incusのメトリックスを読み込み可能に設定
Incusのメトリクスエンドポイントを公開する。
# 完全な API を8443ポートで公開する場合
incus config set core.https_address ":8443"
# メトリクス API エンドポイントのみを8444ポートで公開する場合
# incus config set core.metrics_address ":8444"
# メトリクス用証明書の作成
## 自己署名証明書(X.509形式): metrics.crt
## 秘密鍵 : metrics.key
mkdir -p .cert_metrics
cd .cert_metrics/
openssl req -x509 -newkey ec -pkeyopt ec_paramgen_curve:secp384r1 -sha384 -keyout metrics.key -nodes -out metrics.crt -days 3650 -subj "/CN=metrics.local"
# 証明書を信頼済みクライアントのリストにmetricsというタイプを指定して追加する
incus config trust add-certificate metrics.crt --type=metrics
メトリクス用証明書をPrometheusで利用可能にする。ローカルでPrometheusを動作させる場合は、下記のように作成した証明書とキーをPremetheusがアクセスできる場所にコピーする。
# tls ディレクトリーを作成
sudo mkdir /etc/prometheus/tls/
# 新規に作成された証明書と鍵を tls ディレクトリーにコピー
sudo cp metrics.crt metrics.key /etc/prometheus/tls/
# Incus サーバー証明書を tls ディレクトリーにコピー
sudo cp /var/lib/incus/server.crt /etc/prometheus/tls/
# ファイルを Prometheus からアクセス可能にします
sudo chown -R prometheus:prometheus /etc/prometheus/tls
/etc/prometheus/prometheus.yamlにincusからのメトリックスの収集するjobを追加する.
global:
# デフォルトでどれぐらい頻繁にターゲットからデータ収集するか。Prometheus のデフォルト値は 1m です。
# apt-get でインストールした場合は 15s が設定されていた。
scrape_interval: 15s
scrape_configs:
- job_name: incus
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['127.0.0.1:8443']
tls_config:
ca_file: 'tls/server.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
# openssl x509 -noout -text -in /etc/prometheus/tls/server.crt
# X509v3 Subject Alternative Name:
# DNS:raiko, IP Address:127.0.0.1, IP Address:0:0:0:0:0:0:0:1
# の DNS:raiko の部分で設定
server_name: 'raiko'
修正した設定ファイルを反映
Prometheusを再起動する
systemctl restart prometheus
Premetheusが起動したか確認する
systemctl status prometheus
● prometheus.service - Monitoring system and time series database
Loaded: loaded (/usr/lib/systemd/system/prometheus.service; enabled; preset: enabled)
Active: active (running) since Sun 2024-09-01 11:44:48 JST; 26s ago
Docs: https://prometheus.io/docs/introduction/overview/
man:prometheus(1)
Main PID: 262945 (prometheus)
Tasks: 29 (limit: 154176)
Memory: 35.1M (peak: 35.2M)
CPU: 218ms
CGroup: /system.slice/prometheus.service
└─262945 /usr/bin/prometheus
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.487Z caller=head.go:684 level=info component=tsdb msg="Replaying WAL, this may take a while"
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.503Z caller=head.go:755 level=info component=tsdb msg="WAL segment loaded" segment=0 maxSegment=1
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.505Z caller=head.go:755 level=info component=tsdb msg="WAL segment loaded" segment=1 maxSegment=1
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.505Z caller=head.go:792 level=info component=tsdb msg="WAL replay completed" checkpoint_replay_duration=23.303µs wal_replay_duration=18.0>
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.508Z caller=main.go:1025 level=info fs_type=EXT4_SUPER_MAGIC
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.508Z caller=main.go:1028 level=info msg="TSDB started"
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.508Z caller=main.go:1209 level=info msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.509Z caller=main.go:1246 level=info msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=5>
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.509Z caller=main.go:989 level=info msg="Server is ready to receive web requests."
Sep 01 11:44:48 raiko prometheus[262945]: ts=2024-09-01T02:44:48.509Z caller=manager.go:999 level=info component="rule manager" msg="Starting rule manager..."
Lokiをセットアップする
Lokiのインストール
LokiのパッケージをホストPCにインストールする
sudo apt-get update && \
sudo apt-get install -y loki
Lokiを起動する
lokiの起動を確認する
systemctl status loki
● loki.service - Loki service
Loaded: loaded (/etc/systemd/system/loki.service; enabled; preset: enabled)
Active: active (running) since Sun 2024-09-01 12:21:35 JST; 53s ago
Main PID: 271489 (loki)
Tasks: 28 (limit: 154176)
Memory: 33.8M (peak: 34.4M)
CPU: 527ms
CGroup: /system.slice/loki.service
└─271489 /usr/bin/loki -config.file /etc/loki/config.yml
Sep 01 12:21:35 raiko loki[271489]: level=info ts=2024-09-01T03:21:35.487199326Z caller=module_service.go:82 msg=starting module=query-scheduler
Sep 01 12:21:35 raiko loki[271489]: level=info ts=2024-09-01T03:21:35.487334016Z caller=module_service.go:82 msg=starting module=querier
Sep 01 12:21:35 raiko loki[271489]: level=info ts=2024-09-01T03:21:35.487421594Z caller=module_service.go:82 msg=starting module=query-frontend
Sep 01 12:21:35 raiko loki[271489]: level=info ts=2024-09-01T03:21:35.487700957Z caller=loki.go:508 msg="Loki started" startup_time=140.270097ms
Sep 01 12:21:38 raiko loki[271489]: level=info ts=2024-09-01T03:21:38.488253153Z caller=scheduler.go:653 msg="this scheduler is in the ReplicationSet, will now accept requests."
Sep 01 12:21:38 raiko loki[271489]: level=info ts=2024-09-01T03:21:38.488271509Z caller=worker.go:231 component=querier msg="adding connection" addr=127.0.0.1:9096
Sep 01 12:21:40 raiko loki[271489]: level=info ts=2024-09-01T03:21:40.487723061Z caller=compactor.go:489 msg="this instance has been chosen to run the compactor, starting compactor"
Sep 01 12:21:40 raiko loki[271489]: level=info ts=2024-09-01T03:21:40.48781495Z caller=compactor.go:518 msg="waiting 10m0s for ring to stay stable and previous compactions to finish before starting comp>
Sep 01 12:21:45 raiko loki[271489]: level=info ts=2024-09-01T03:21:45.488769754Z caller=frontend_scheduler_worker.go:106 msg="adding connection to scheduler" addr=127.0.0.1:9096
Sep 01 12:22:05 raiko loki[271489]: level=error ts=2024-09-01T03:22:05.36396331Z caller=recalculate_owned_streams.go:55 msg="failed to get token ranges for ingester" err="zone not set"
IncusからLokiへのログ送信設定
IncusからLokiにログを送信する設定を行う。loki.instanceには/etc/prometheus/prometheus.yamlで設定したjob名(incus)を設定する。
incus config set core.syslog_socket true
incus config set loki.api.url=http://localhost:3100
incus config set loki.instance=incus
incus config show
config:
core.https_address: :8443
core.metrics_address: :8444
core.syslog_socket: "true"
loki.api.url: http://localhost:3100
loki.instance: incus
Grafanaダッシュボードをセットアップする
Grafanaのインストール
GrafanaパッケージををホストPCにインストールする
# 必要なパッケージをインストール:
sudo apt-get install -y apt-transport-https software-properties-common wget
# GPGキーをインポート
sudo mkdir -p /etc/apt/keyrings/
wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
# 安定版リリース用のリポジトリを追加
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
# 利用可能なパッケージリストを更新
sudo apt-get update
# 最新のOSSリリースをインストール:
sudo apt-get install grafana -y
sudo apt-get install grafana-enterprise -y
### インストール時に自動で開始しないため、systemdを使用してGrafanaが自動的に開始されるように設定するには、次のコマンドを実行してください
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable grafana-server
### grafana-serverを開始するには、次のコマンドを実行できます
sudo /bin/systemctl start grafana-server
Grafanaの起動を確認する
systemctl status grafana-server
● grafana-server.service - Grafana instance
Loaded: loaded (/usr/lib/systemd/system/grafana-server.service; enabled; preset: enabled)
Active: active (running) since Sun 2024-09-01 11:52:54 JST; 1min 2s ago
Docs: http://docs.grafana.org
Main PID: 266022 (grafana)
Tasks: 31 (limit: 154176)
Memory: 63.8M (peak: 67.4M)
CPU: 3.082s
CGroup: /system.slice/grafana-server.service
└─266022 /usr/share/grafana/bin/grafana server --config=/etc/grafana/grafana.ini --pidfile=/run/grafana/grafana-server.pid --packaging=deb cfg:default.paths.logs=/var/log/grafana cfg:defaul>
Sep 01 11:53:00 raiko grafana[266022]: logger=provisioning.dashboard t=2024-09-01T11:53:00.933606947+09:00 level=info msg="starting to provision dashboards"
Sep 01 11:53:00 raiko grafana[266022]: logger=provisioning.dashboard t=2024-09-01T11:53:00.933625763+09:00 level=info msg="finished to provision dashboards"
Sep 01 11:53:00 raiko grafana[266022]: logger=ngalert.state.manager t=2024-09-01T11:53:00.933644456+09:00 level=info msg="State cache has been initialized" states=0 duration=42.279059ms
Sep 01 11:53:00 raiko grafana[266022]: logger=ngalert.scheduler t=2024-09-01T11:53:00.933667863+09:00 level=info msg="Starting scheduler" tickInterval=10s maxAttempts=1
Sep 01 11:53:00 raiko grafana[266022]: logger=ticker t=2024-09-01T11:53:00.933698431+09:00 level=info msg=starting first_tick=2024-09-01T11:53:10+09:00
Sep 01 11:53:01 raiko grafana[266022]: logger=grafana-apiserver t=2024-09-01T11:53:01.023203176+09:00 level=info msg="Adding GroupVersion playlist.grafana.app v0alpha1 to ResourceManager"
Sep 01 11:53:01 raiko grafana[266022]: logger=grafana-apiserver t=2024-09-01T11:53:01.023402304+09:00 level=info msg="Adding GroupVersion featuretoggle.grafana.app v0alpha1 to ResourceManager"
Sep 01 11:53:01 raiko grafana[266022]: logger=grafana.update.checker t=2024-09-01T11:53:01.071260456+09:00 level=info msg="Update check succeeded" duration=179.627515ms
Sep 01 11:53:01 raiko grafana[266022]: logger=plugins.update.checker t=2024-09-01T11:53:01.072228464+09:00 level=info msg="Update check succeeded" duration=181.026939ms
Sep 01 11:53:01 raiko grafana[266022]: logger=plugin.angulardetectorsprovider.dynamic t=2024-09-01T11:53:01.164892784+09:00 level=info msg="Patterns update finished" duration=229.109065ms
Grafanaへサインイン
公式ページに従って作業を進める。
ホストPCでウェブブラウザを開き、URLに http://localhost:3000 を入力してサインインページにアクセスする。初回のサインインでは、ユーザー名 admin とパスワード admin を使用する。サインイン後、初回ログイン時にはパスワードの変更が求められるため、新しい admin パスワードを設定する。

Grafanaダッシュボードをセットアップする
GrafanaのGUIが公式ページの説明とは異なりアップデートされていたため、作業に一部変更が必要でした。
Prometheusをデータソースとして設定
Connections-Add new connectionのData sourcesからPrometheusを選択する。

Add new data sourceを選択する
Prometheusがローカルで動いている場合URLフィールドに http://localhost:9090/ を入力する。

下にスクロールして Save & test を選択する
Lokiをデータソースとして設定
Connections-Add new connectionのData sourcesからLokiを選択する。

Add new data sourceを選択する
Lokiをローカルで動かす場合URLフィールド内で http://localhost:3100/ を入力する

下にスクロールして Save & test を選択する
Incus のダッシュボードをインポート
DashboardsでNew-Importを選択します。

Import via grafana.comフィールドにダッシュボード ID19727を入力する。
Incusのドロップダウンメニューから、PrometheusとLokiのデータソースを選択してImportを選択する。


トラブルシューティング
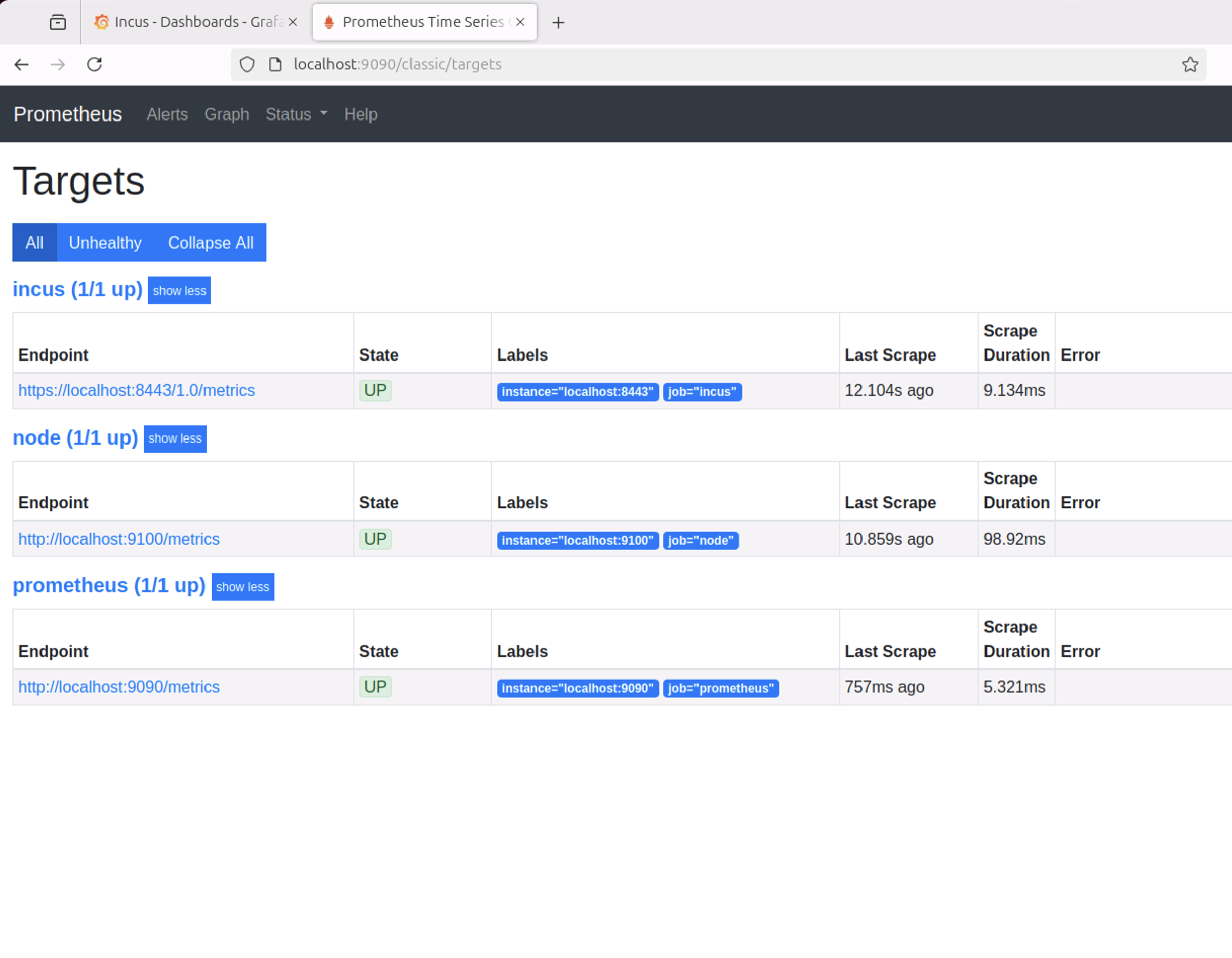
URL: localhost:9090/classic/targets をウェブブラウザで開き、PrometheusがIncusからメトリクスを収集できているかを確認する。この記事では、Incusが完全なAPIをポート8443で公開する設定を前提に書かれているが、メトリクスAPIエンドポイントのみをポート8444で公開する場合には、8443ポートを8444ポートに読み替える必要がある。8443と8444が混在していると、接続に問題が発生するので注意する。
Chromiumのビルド
Chromiumのビルドを複数のエンジニアが並行に行った場合のIncusのメトリクスを確認するために、コンテナnobleでChromiumのビルドを試す。
公式ドキュメント
# Install depot_tools (to ${HOME})
cd ${HOME}
git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git
export PATH="${HOME}/depot_tools:$PATH"
# Get the code
mkdir ~/chromium && cd ~/chromium
fetch --nohooks chromium
cd src
./build/install-build-deps.sh
gclient runhooks
# Setting up the build
gn gen out/Default
# Build
time autoninja -C out/Default chrome
1つのコンテナがフルにCPUを利用した場合には2時間を少し越える程度でビルドが終了した。
ninja: Entering directory `out/Default'
[62551/62551] LINK ./chrome
real 129m31.326s
user 2910m13.007s
sys 184m27.320s
ビルドしたChromiumを起動する。
# Run Chromium
out/Default/chrome
# AppArmor問題が発生する場合
out/Default/chrome --no-sandbox
AppArmorの設定を行っていない場合には--no-sandboxをつけない場合には下記のエラーが発生することもある。
[153764:153764:0901/232556.108054:WARNING:chrome_main_delegate.cc(743)] This is Chrome version 130.0.6689.0 (not a warning)
[153764:153764:0901/232556.137733:FATAL:zygote_host_impl_linux.cc(128)] No usable sandbox! If you are running on Ubuntu 23.10+ or another Linux distro that has disabled unprivileged user namespaces with AppArmor, see https://chromium.googlesource.com/chromium/src/+/main/docs/security/apparmor-userns-restrictions.md. Otherwise see https://chromium.googlesource.com/chromium/src/+/main/docs/linux/suid_sandbox_development.md for more information on developing with the (older) SUID sandbox. If you want to live dangerously and need an immediate workaround, you can try using --no-sandbox.
#0 0x7c4734bca149 base::debug::CollectStackTrace() [../../base/debug/stack_trace_posix.cc:1044:7]
#1 0x7c4734b7dbba base::debug::StackTrace::StackTrace() [../../base/debug/stack_trace.cc:245:20]
#2 0x7c4734b7db25 base::debug::StackTrace::StackTrace() [../../base/debug/stack_trace.cc:240:28]
#3 0x7c47348b9121 logging::LogMessage::Flush() [../../base/logging.cc:739:29]
#4 0x7c47348b9cc5 logging::LogMessageFatal::~LogMessageFatal() [../../base/logging.cc:1078:3]
#5 0x7c472be6525f content::ZygoteHostImpl::Init() [../../content/browser/zygote_host/zygote_host_impl_linux.cc:128:5]
#6 0x7c472cf22c0e content::(anonymous namespace)::InitializeZygoteSandboxForBrowserProcess() [../../content/app/content_main_runner_impl.cc:389:34]
#7 0x7c472cf228a8 content::ContentMainRunnerImpl::Initialize() [../../content/app/content_main_runner_impl.cc:1067:5]
#8 0x7c472cf1fa9b content::RunContentProcess() [../../content/app/content_main.cc:299:38]
#9 0x7c472cf20106 content::ContentMain() [../../content/app/content_main.cc:344:10]
#10 0x58f5de40c027 ChromeMain [../../chrome/app/chrome_main.cc:230:12]
#11 0x58f5de40bd92 main
#12 0x7c46d8c2a1ca (/usr/lib/x86_64-linux-gnu/libc.so.6+0x2a1c9)
#13 0x7c46d8c2a28b __libc_start_main
#14 0x58f5de40bcaa _start
Crash keys:
"num-switches" = "0"
"osarch" = "x86_64"
"pid" = "153764"
"ptype" = "browser"
Trace/breakpoint trap (core dumped)
AppArmorの設定方法は公式ドキュメントを参考にして解決する。
# 環境変数の設定
export CHROMIUM_BUILD_PATH=/@{HOME}/chromium/src/out/**/chrome
# AppArmorプロファイルの作成:
cat | sudo tee /etc/apparmor.d/chrome-dev-builds <<EOF
abi <abi/4.0>,
include <tunables/global>
profile chrome $CHROMIUM_BUILD_PATH flags=(unconfined) {
userns,
# Site-specific additions and overrides. See local/README for details.
include if exists <local/chrome>
}
EOF
#AppArmorプロファイルのリロード
sudo service apparmor reload
# Chromiumを起動
./out/Default/chrome
YouTubeで動画が音声付きで再生することGPUがサポートされていることを確認した。

次のステップでコンテナnobleのコピーを作成し、複数のコンテナで並列ビルドを行うので、予めビルド中に作成されたファイルを削除しておく。
rm -rf ./out
ビルド中に作成されたすべてのファイルは-Cで指定したout/Defaultに出力される。設定を変更してビルドをやり直したい場合にはout/Defaultを削除して、gn gen out/Defaultの部分からやり直す。
複数のコンテナでChromiumを並列ビルドする
ビルド用コンテナを複数起動する
コンテナnobleからnoble2, 3, 4を作成し、合計で4つのコンテナを起動させる。
# Chromeをビルド可能なコンテナを追加で3つ用意する
incus copy noble noble2
incus copy noble noble3
incus copy noble noble4
# 作成したコンテナを起動
incus start noble2
incus start noble3
incus start noble4
# 作成したコンテナの確認
incus list
+--------+---------+----------------------+---------------------------------------------+-----------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+--------+---------+----------------------+---------------------------------------------+-----------+-----------+
| noble | RUNNING | 10.107.73.63 (eth0) | fd42:8159:b94:458:216:3eff:fe41:cb7 (eth0) | CONTAINER | 0 |
+--------+---------+----------------------+---------------------------------------------+-----------+-----------+
| noble2 | RUNNING | 10.107.73.93 (eth0) | fd42:8159:b94:458:216:3eff:fe7d:183a (eth0) | CONTAINER | 0 |
+--------+---------+----------------------+---------------------------------------------+-----------+-----------+
| noble3 | RUNNING | 10.107.73.161 (eth0) | fd42:8159:b94:458:216:3eff:feb8:9753 (eth0) | CONTAINER | 0 |
+--------+---------+----------------------+---------------------------------------------+-----------+-----------+
| noble4 | RUNNING | 10.107.73.163 (eth0) | fd42:8159:b94:458:216:3eff:fe84:e767 (eth0) | CONTAINER | 0 |
+--------+---------+----------------------+---------------------------------------------+-----------+-----------+
各コンテナで並列ビルドする
SSHで各コンテナ(noble2, noble3, noble4)にログインしてChromeのビルドを行う
例) noble2の場合
# noble2にログイン
ssh -J raiko@192.168.1.113 ubuntu@10.107.73.93
# noble2でChromiumをビルド
export PATH="${HOME}/depot_tools:$PATH"
cd ~/chromium/src
gn gen out/Default
time autoninja -C out/Default chrome
4つのコンテナでChromiumのビルドを実行すると、ホストPCのhtopコマンドの画面がclang++コマンドで埋まっている。

コンテナ内で動作しているclang++プロセスがホストPCのhtopで確認できるのは、コンテナがホストPCのカーネル上で動作しているためだ。コンテナは、仮想マシンとは異なり、ホストのカーネルを共有し、プロセスがホストのプロセスリストに表示される。そのためhtopのようなツールを使用すると、ホストPC上で実行されているすべてのプロセス(コンテナ内のプロセスも含む)を確認することができる。これにより、ホストPCのhtopにclang++コマンドが大量に表示されることになる。
ダッシュボードでコンテナのメトリックスを確認する
Grafanaで作成したダッシュボードからは、4つのコンテナがCPUについてはほぼ同率の割合で割り当てられている。

メモリーリミットが未設定であるため、コンテナを4つ起動したタイミングでRAM Totalが実際のRAMサイズの4倍になってしまっている。実際に運用する場合にはlimits.memoryを設定を行うほうが良いだろう。limits.cpuでのCPUリミットについては今回のユースケースでは必要ないかもしれない。

コンテナへのRAM割り当ての上限を動的に変更する
Chromiumのビルドには16GiB以上が推奨されている。
incus config set noble limits.memory=16GiB
limits.memoryは動的に変更が可能なので、Chromiumをビルド中でも下記のようにメモリリミットの設定を行うことができる。各コンテナに16GiBの割り当てに変更すると下図のように合計メモリ(RAM Total)が64GiBに変更される。
incus config set noble limits.memory=16GiB
incus config set noble2 limits.memory=16GiB
incus config set noble3 limits.memory=16GiB
incus config set noble4 limits.memory=16GiB

さらにメモリ上限が16GiBだとビルドに失敗するかもしれないので24GiBに変更する。その場合には下図のように合計メモリ(RAM Total)が96GiBと表示に更新される。
incus config set noble limits.memory=24GiB
incus config set noble2 limits.memory=24GiB
incus config set noble3 limits.memory=24GiB
incus config set noble4 limits.memory=24GiB

コンテナのRAM消費を最適化した場合
現在のclang++が並列実行数は208(1コンテナあたり52)だと確認できる。4つのコンテナが24個あるCPUに対してclang++を2つづつ割り当てようとするため非常に大きな数となっている。これでは非効率だろう。
ps auxw | grep '[c]lang++' | wc -l
208
CPUを食い潰して無駄にメモリを消費しているようなので各コンテナのビルドをCtl-Cで中断して-j6を指定しclang++の並列実行数を制限して再実行する。
time autoninja -C out/Default chrome -j6
clang++の並列実行を(1コンテナあたり12並列、1CPUあたりだと2並列に)制限するため、全体のメモリ消費量が減少し4コンテナ全体で9GiB程度しかRAMを消費しないことが確認できる。

Buildに要した時間
10時間弱で4つのコンテナがほぼ同時間でビルドが終了した。1つのコンテナで動作させた場合(約130分)と比較してビルドに要した時間は約4.5倍である。複数のコンテナを動作させたことによるロスが見られるが、期待通りのパフォーマンスでビルド処理が終了したと言って良いだろう。
real 589m31.259s
user 1700m12.542s
sys 112m14.882s
まとめ
Build中のメトリクスを確認した。 (はじめにの内容と同一)
Chromiumのビルド中にフォーカスしてコンテナのメトリックスをダッシュボード表示することで下記の事実を確認できた。
- 15:00過ぎにビルドを開始し日を跨いで1:00頃にビルドが終了した
- 多少の誤差はあるがCPUとRAMの割り当ては均衡に行われている
- ディスク読み込みが約12TiB、書き込みが178GiBとChromiumのビルドの負荷を再確認した
- メモリリミットを設定した19:00頃(16GiBx4)と19:30頃(24GiBx4)のタイミングでRAM上限が変更されている
-
-j6を設定した20:00頃のタイミングでプロセス数が削減されている -
-j6を設定した20:00頃のタイミングでメモリ使用量が削減されている - ネットワークはコンテナ
nobleのネットワークが途中で切れていたため3分割されている