CloudNativeがここまで進化するとインスタンスの仮想化技術をベースとしたシステムなど使いたくなくなってしまいます。
私は新たにシステムを構築する際、必ずServerless Firstの考え方で設計をしていきます。
その中でAWS Lambda、Amazon DynamoDBを中心にMicroservicesの設計をしていくのですが、
ACIDの部分をどう対処するかが一番悩むところです。
今回はServeice間のTransactionに関する話を自分なりに整理していきたいと思います。
図1
Saga Design Pattern
Sagaは複数のサービスにまたがるトランザクションを実装するためのマイクロサービスアーキテクチャパターンです。
複数のマイクロサービス間でデータ一貫性を実現するもので、Sagaには2つのパターンがあります。
- Choreography-based Saga Transaction
- Orchestration-based Saga Transaction
どちらのパターンにもServerlessで実現可能ですが、今回はOrchestration-based Saga Transactionを中心に話を勧めていきたいとおもいます。
Orchestration-based Saga TransactionではAWS StepfunctionsのState Machineを使います。
サンプルプログラムをGithubに公開しています。ServerlessMicroservicesSagaTransaction
(業務で作成するときにはCleanArchitectureで実装するのですが、今回は手を抜いてますのでご了承ください。)
State Design Pattern vs.State Machine Design Pattern
SagaをDesign Patternに当てはめるとわかりやすいかと思います。
- Choreography-based Saga: State Design Pattern
- Orchestration-based Saga: State Machine Design Pattern
Design Patternの違いは以下になります。
- State Design Pattern: Stateの遷移はマイクロサービスが担当する
- State Machine Design Pattern: Stateの遷移はStateMachineが担当する
State Machineの唯一の責任は、Saga Transactionに参加する各マイクロサービスに何をすべきかを伝えることです。
StateMachineを時前で構築するには結構面倒なのでAWS Stepfunctionsが実現してくれるのにはとても助かります。
ちなみに以前作成したChoreography-based Sagaのシステムでは、AWS LambdaがEvent(AWS SNS)を発行し、
次のState(AWS Lambda)に遷移させていくState Design Patternで実装するものでした。
一番大切なポイント
各State(AWS Lambda)はAtomicにしなければならない。
という点です。
記事とかで紹介されているものに、これができていないものも多く見受けられます。
Atomicにしないということは、State(AWS Lambda)の中に複数の状態をもつことになり、
State Design PatternやState Machine Design Patternにならないということになります。
Sagaの記述に以下のようなものがあります。
「Sagaは、データの一貫性を維持するためのローカルトランザクションのメーセージ駆動シーケンスである。」
つまり、ローカルトランザクションをメッセージでつないで全体的なビジネストランザクションを実現することになります。
ローカルトランザクションをState(AWS Lambda + DynamoDB)で実現し、State Machineでシーケンスを実現するというものです。
AWS Lambda FunctionがAtomicでなく複数のStateを持ってしまうと、途中で失敗した際、Saga Transactionの遷移ができなくなり破綻してしまいます。
私はこのローカルトランザクションを実現する点が一番むずかしいところで、逆にローカルトランザクションができてしまえば後は楽にできると考えています。
ローカルトランザクションの概要は以下のようになります。
- イベントメッセージ消費し
- 重複を検出して破棄し(冪等性)
- 集約を作成または更新し、
- イベントメッセージを送信する
これらをAtomicに処理する必要があります。
集約とはDDDで出てくる集約ですね。DDDの集約をどうつくるか私は結構悩みます。
DDDの中でも集約をAtomicに処理することが求められています。
ローカルトランザクションが難しいという点はこの集約をどう設計するかがポイントになるということです。
State Machineが出来上がるまで
私にはいきなりState Machineを作ることはしません。というか私にはできません。
ローカルトランザクションをどう設計するかをしっかり考えた上で、State Machineを作っていきます。
シーケンス図
私の場合はシーケンス図から入るようにしてます。
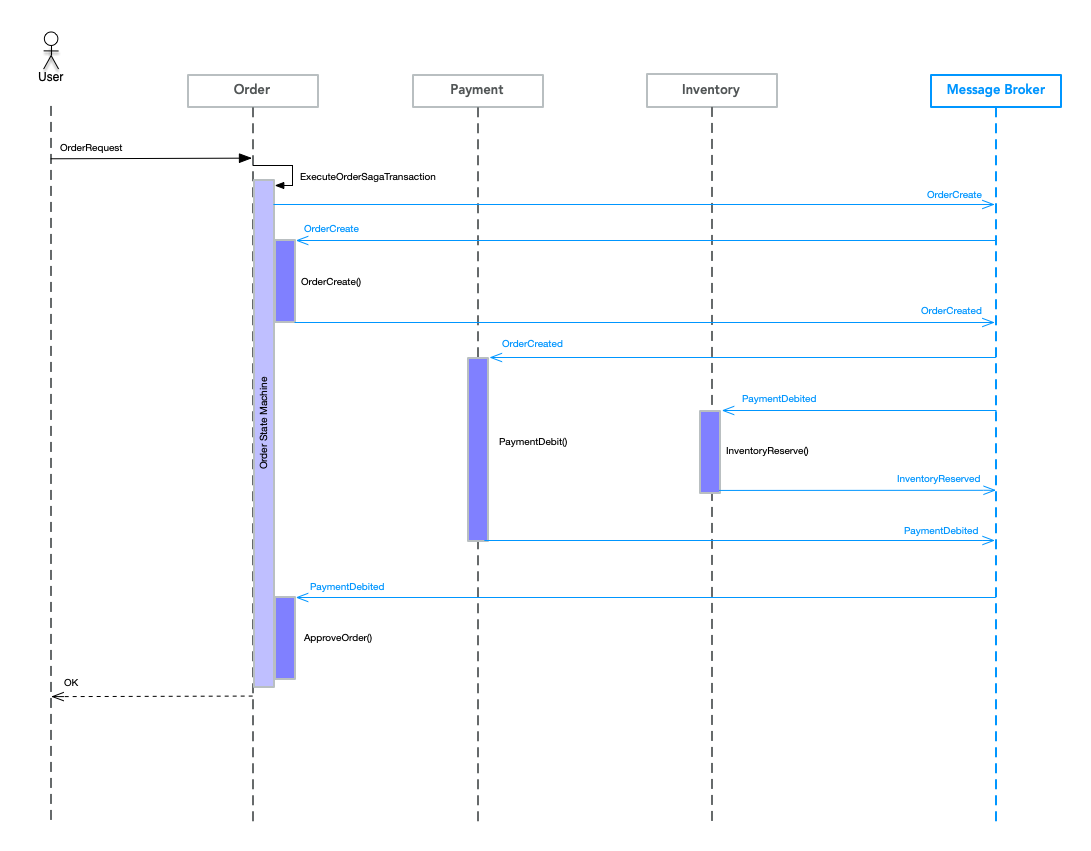
よくあるシーケンス図を以下に示します。
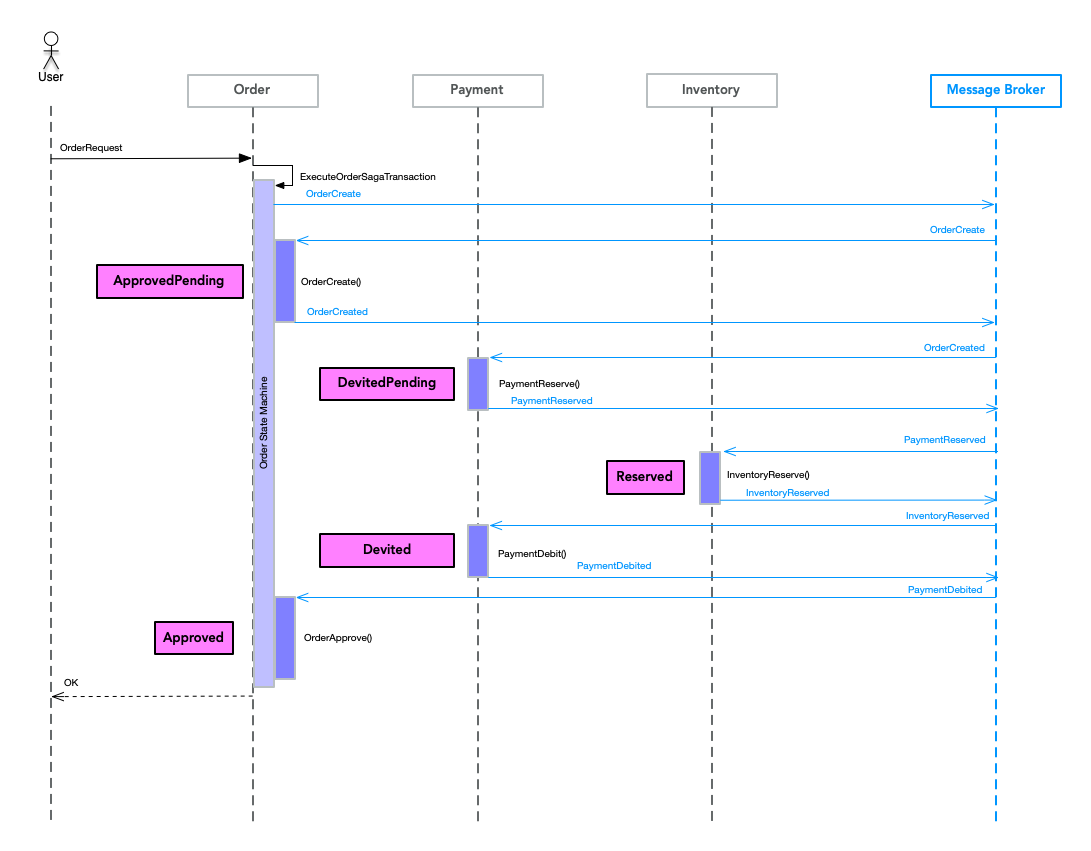
Orderサービスがオーダを受付け、Paymentサービスが支払い処理を行い、Inventoryが在庫を確保するというトランザクションです。
図2
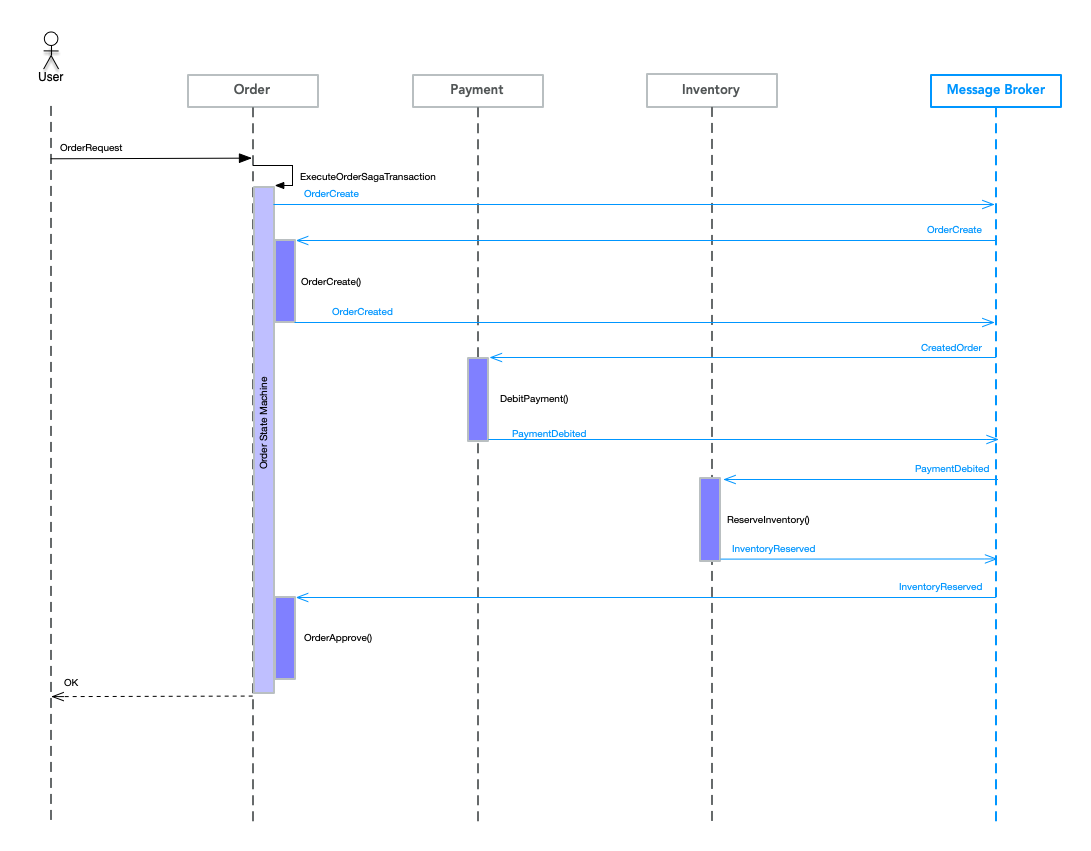
Orderの部分をAWS Lambdaで実装することはできないので、以下のようなシーケンス図をベースに考えます。
Userとのやり取りも同期的でなく非同期になります。
図3
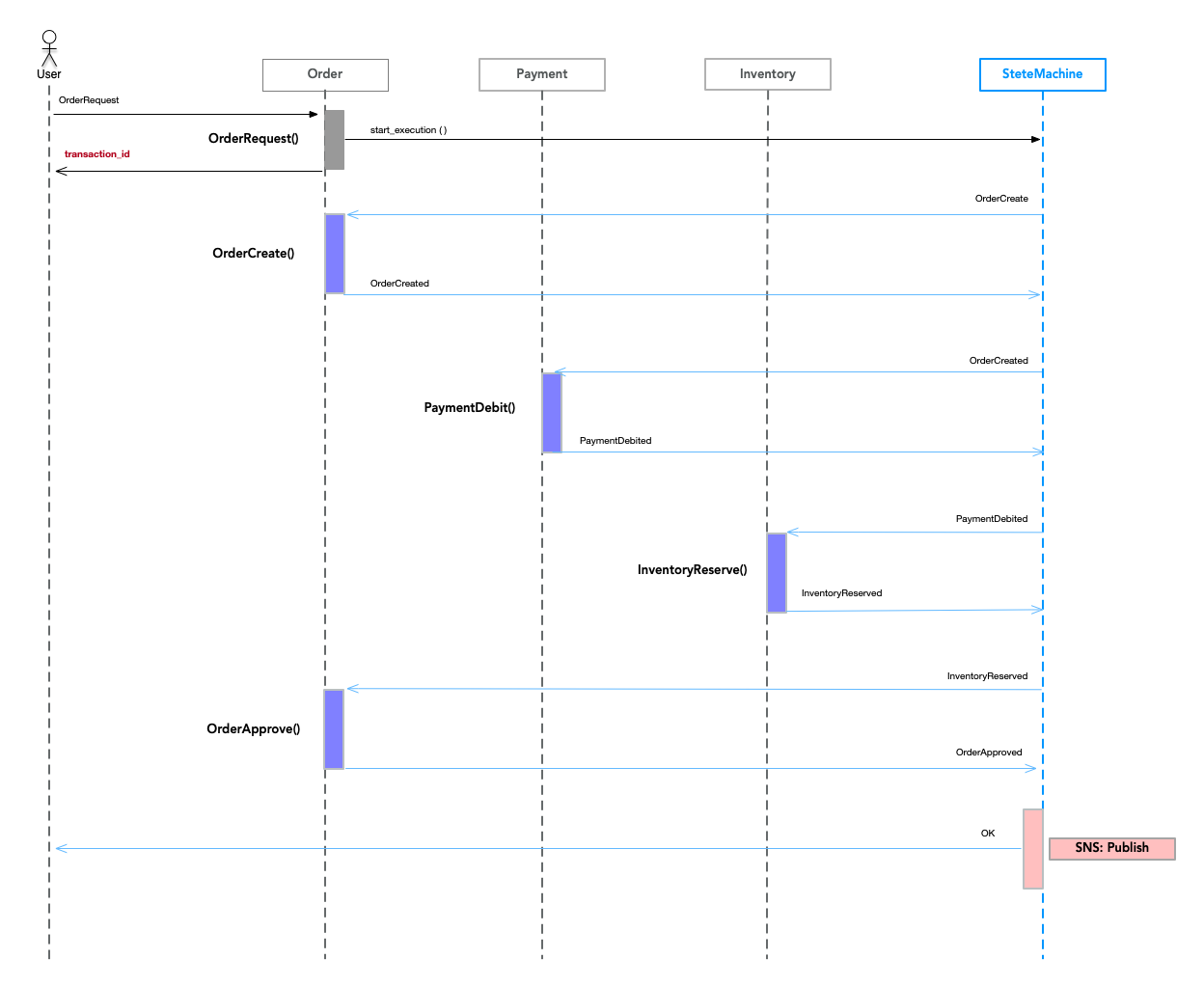
失敗例
話がそれますが、時々以下のようなシーケンス図を見ることがあります。
図4
PaymentとInventoryのStateが入れ子になっているのでAtomicになりません。
私は入れ子のシーケンスにしないようにしています。
もし、どうしても入れ子にしなければならない状況であれば、以下のようにするようにしています。
図5
ローカルトランザクション
図3を元に説明していきます。
OrderRequestで発生するイベントデータのサンプルは以下のようなものを想定しています。
{
"order_id": "40063fe3-56d9-4c51-b91f-71929834ce03",
"order_date": "2019-12-01 12:32:24.927479",
"customer_id": "2d14eb6c-a3c2-3412-8450-239a16f01fea",
"items": [{
"item_id": "0123",
"qty": 1.0,
"description": "item 1",
"unit_price": 12.99
},
{
"item_id": "0234",
"qty": 2.0,
"description": "item 2",
"unit_price": 41.98
},
{
"item_id": "0345",
"qty": 3.0,
"description": "item 3",
"unit_price": 3.50
}
]
}
上記の図では、青い箱がローカルトランザクションになるのですが、
ローカルトランザクションには4つの種類があります。
- 補償可能トランザクション(Compensatable transactions): 補償トランザクションを使用してロールバックできるトランザクション。
処理が失敗したときに更新した処理の取り消しを必要とするトランザクションです。 - 補償トランザクション(Compensating Transaction): 更新を取り消すトランザクション。
- 再試行可能トランザクション(Retriable transactions): 成功することが保証されているトランザクション。
- ピボットトランザクション(Pivot transaction): 補償も再試行もできないトランザクションで、完了するまで実行されます。
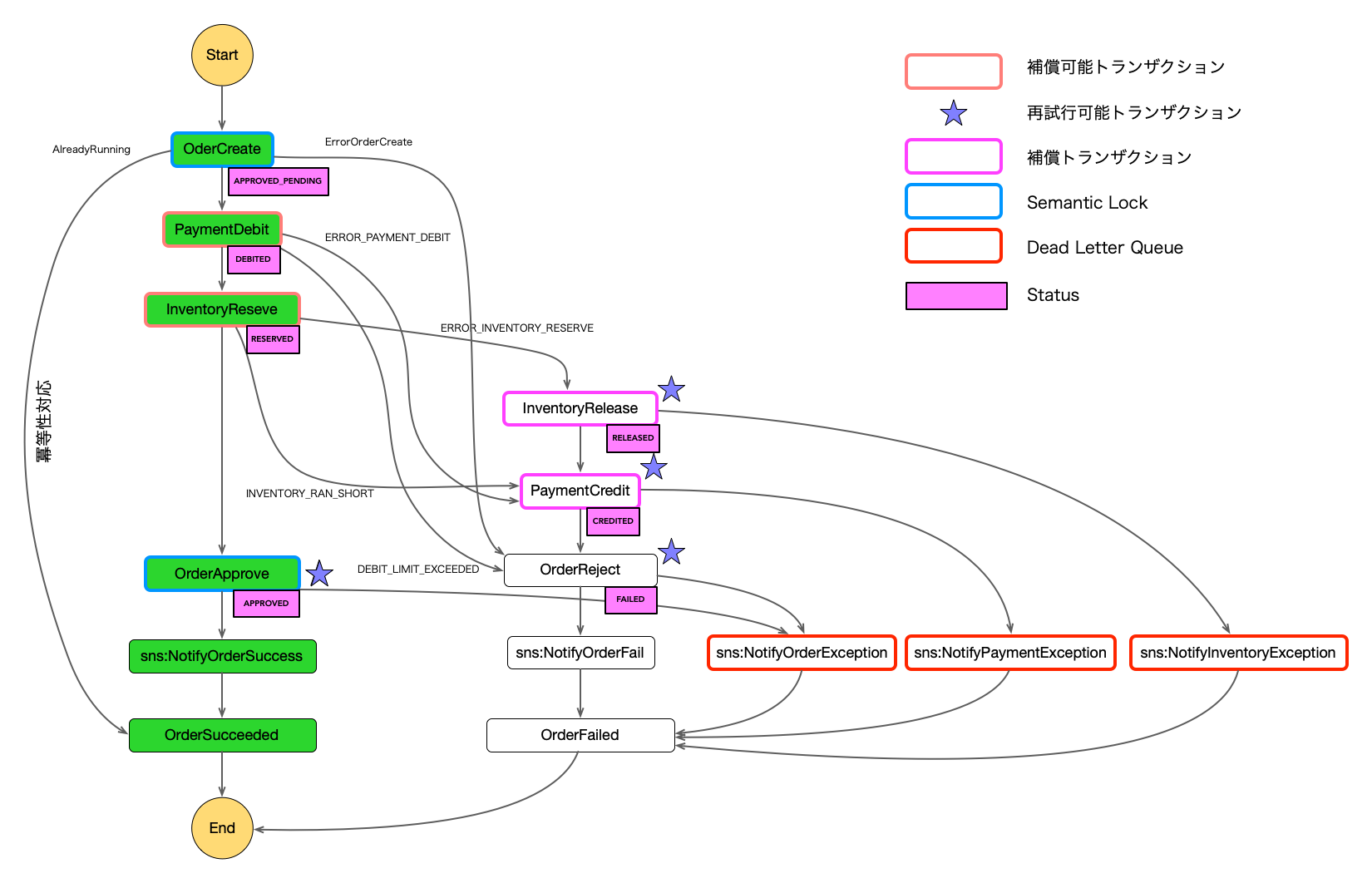
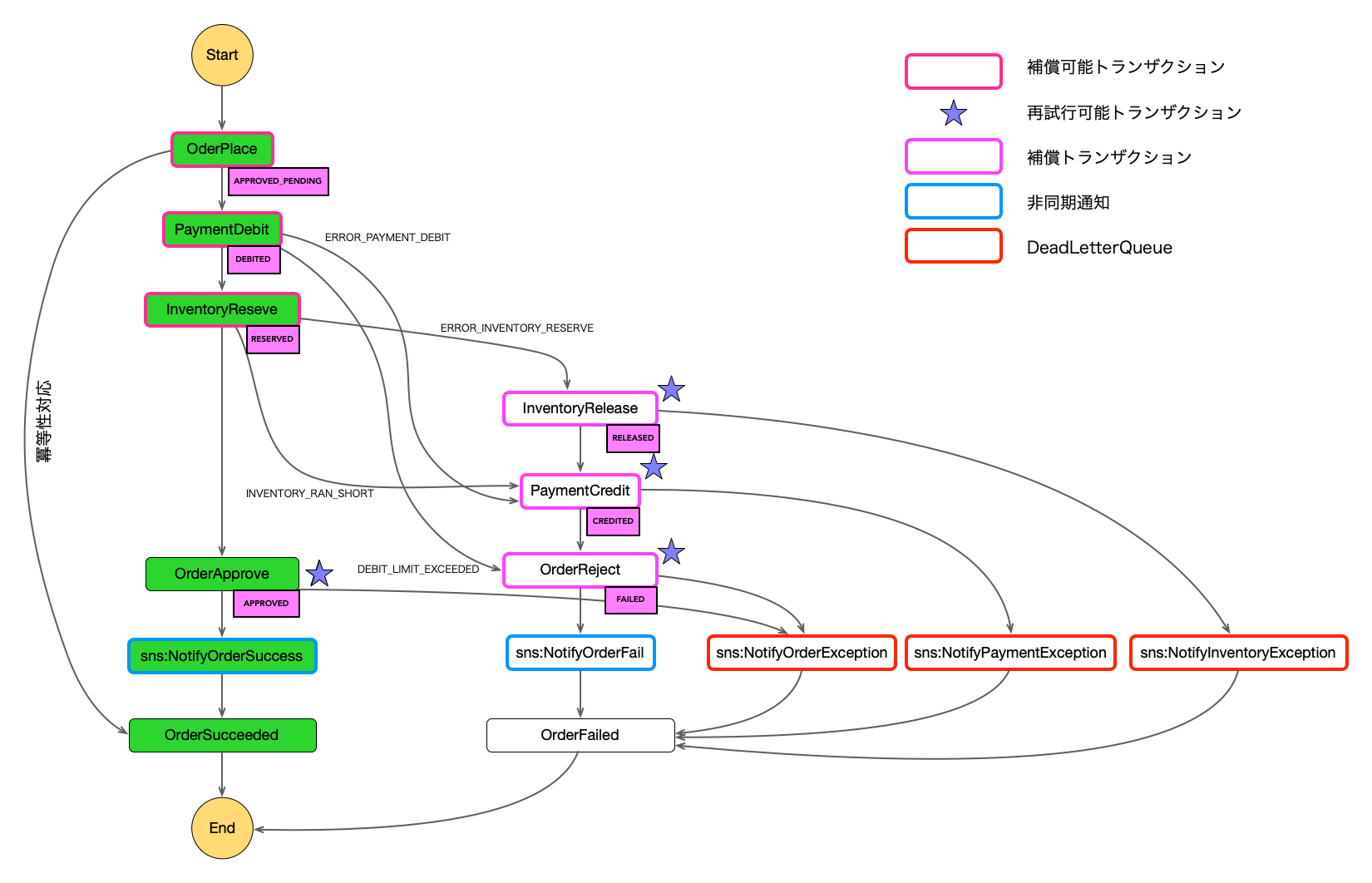
以下の図のように注文した在庫がなかった(RanShort)の例で説明していきます。
図6
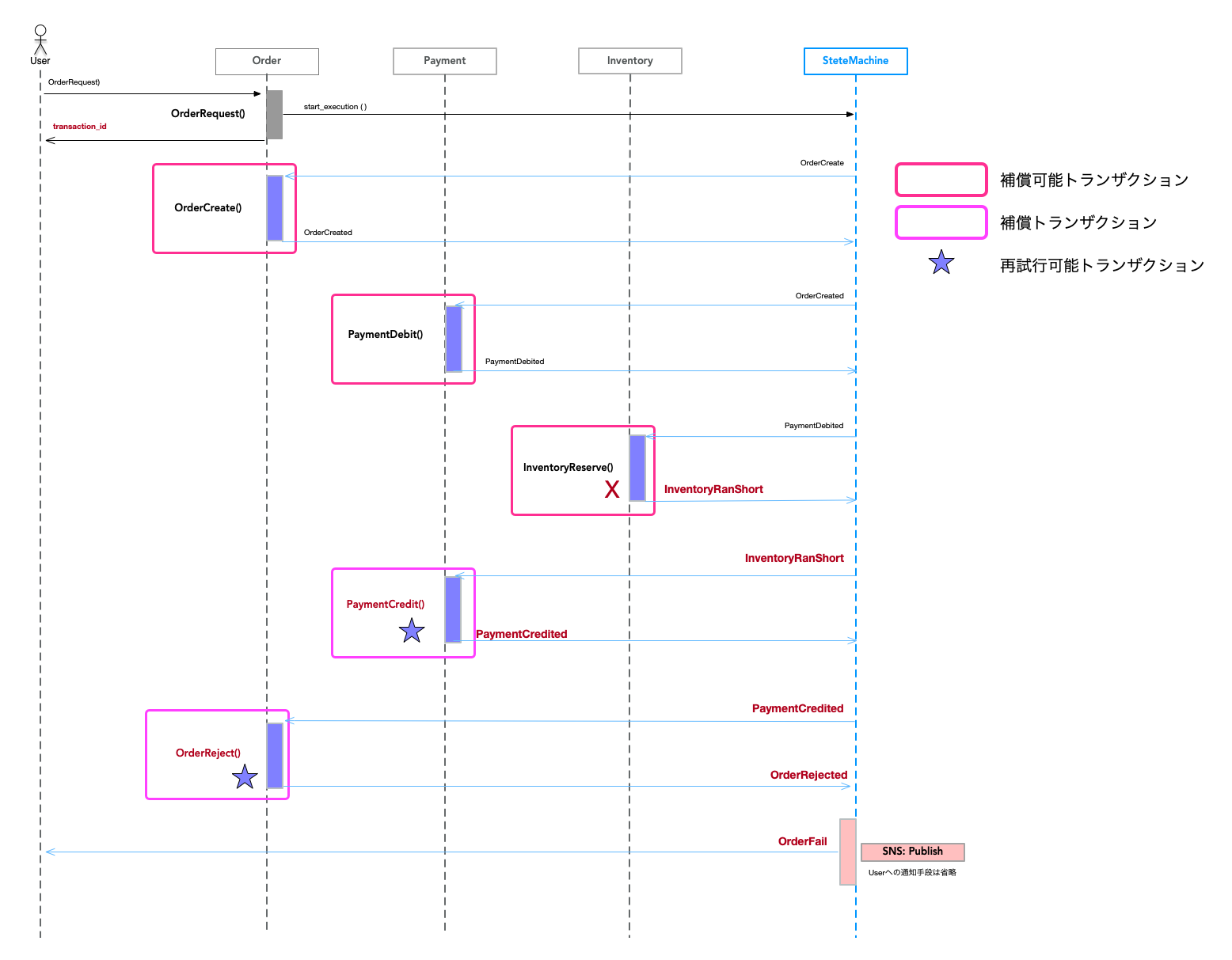
OrderCreate()、PaymentDebit()、InventoryReserve()は補償可能トランザクション。
PaymentCredit()、OrderReject()は補償トランザクション。
PaymentCredit()、OrderReject()は再試行可能トランザクション。
この例では、ReserveInventoryトランザクションで在庫が確保できなかった場合の処理を示していて、
InventoryがInventoryRanShortのイベントを発行しています。
補償トランザクションは、なんとか取り消し処理を成功させなければならないので、
"成功することが保証されているトランザクション"である再試行可能トランザクションにしています。
再試行可能トランザクションに関して
再試行の処理はStateMachineに定義します。
GitHubのコード(state-machine.json)を参照ください。
InventoryReserveには"Retry"はありませんが、InventoryReleaseには"Retry"を入れています。
Sagaトランザクションの中でローカルトランザクションを再試行可能にするかしないかはとても重要なポイントになります。
"InventoryReserve": {
"Comment": "Inventory Reserve",
"Type": "Task",
"Resource": "${InventoryReserveFunction.Arn}",
"Catch": [
{
"ErrorEquals": ["InventoryRanShort"],
"ResultPath": "$.error",
"Next": "PaymentCredit"
},
{
"ErrorEquals": ["ErrorInventoryReserve"],
"ResultPath": "$.error",
"Next": "InventoryRelease"
}
],
"Next": "OrderApprove"
}
"InventoryRelease": {
"Comment": "Inventory Release",
"Type": "Task",
"Resource": "${InventoryReleaseFunction.Arn}",
"Retry": [{
"ErrorEquals": ["States.ALL"],
"IntervalSeconds": 1,
"MaxAttempts": 2,
"BackoffRate": 2.0
}],
"Catch": [{
"ErrorEquals": ["ErrorInventoryRelease", "ErrorPaymentException"],
"ResultPath": "$.fail",
"Next": "sns:NotifyReleaseInventoryException"
}],
"Next": "PaymentCredit"
},
補償トランザクションへの遷移
上記StateMachineのInventoryReserveでは、InventoryRanShortのエラーイベントが発行されると
PaymentCreditに遷移するように定義できます。
StateMachineではInventoryRanShortのようにカスタムエラーを定義します。
AWS Lambda FunctionでInventoryRanShortを定義して、
raiseしてやればStateMachineに遷移先を指示できるというわけです。とても便利ですね。
(services/inventory/reserve/error.py)
(services/inventory/reserve/lambda_function.py)
class InventoryRanShort(Exception):
pass
raise InventoryRanShort(error_message)
ACIDでなくACD
実はサンプルコードではOrderCreate()を補償可能トランザクションにはしていません。
OrderCreate()を補償可能トランザクションにすることは可能なのですが、
Userに一旦Orderの成功を通知したあと、失敗を通知することは問題があるからです。
そのためOrderCreate()をSemantic Lockにしています。
図7
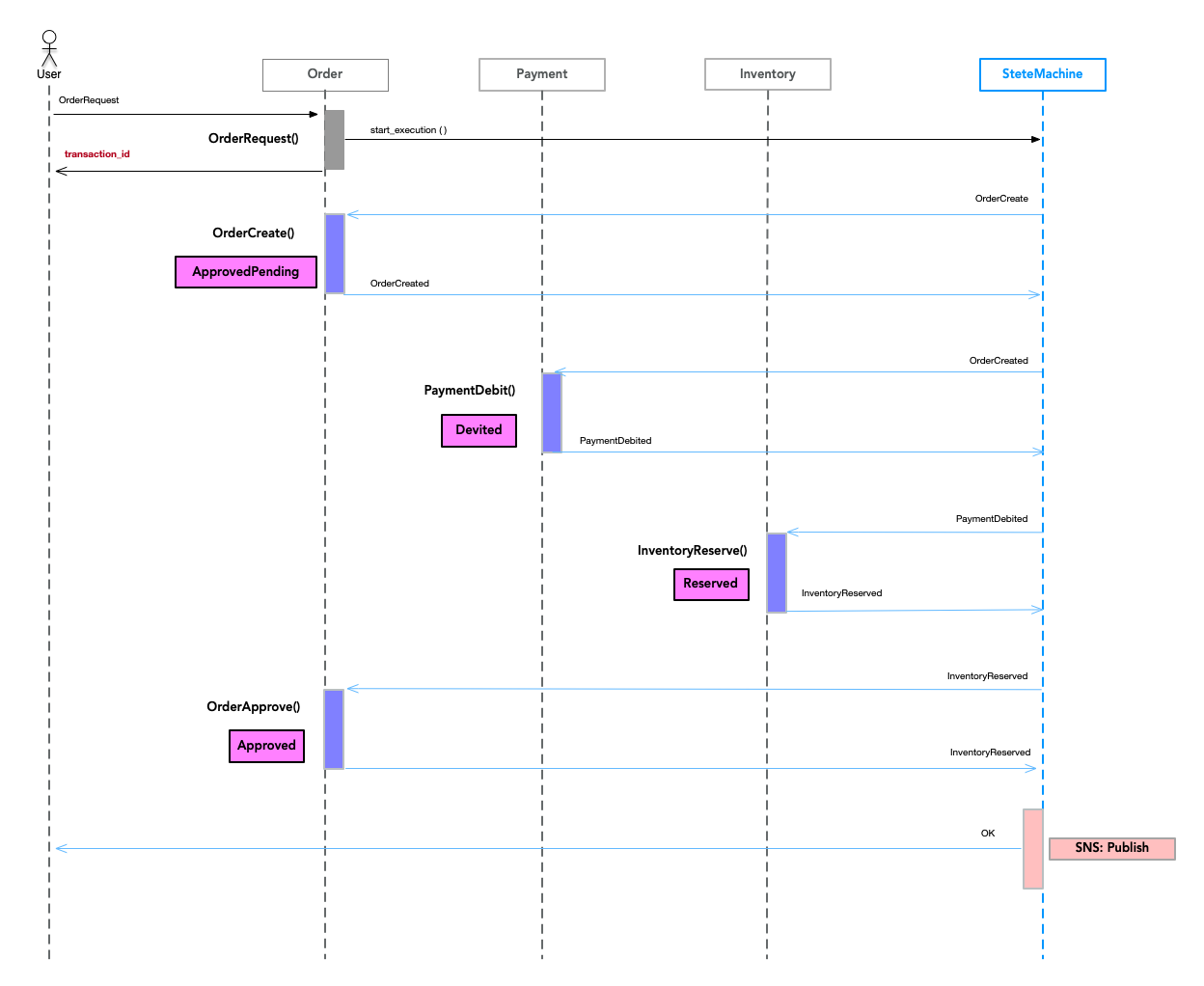
SagaはACIDでなくACDです。つまりIsolationがないということです。
Isolationが無いということはトランザクション途中の状態が見えてしまいDirdy Readsを引き起こします。
その対策としてはSemantic lockやCommutative updatesなどがあります。
Semantic lock
Semantic lockはアプリケーションレベルのロックです。
外部からみたときに、トランザクション途中の状態であることを分かるようにします。
OrderのStatusをAPPROVAL_PENDING、APPROVEDのようにして、
トランザクション処理途中であることがわかるようにしています。
サンプルコードでは、補償トランザクションを発行せず、OrderReject()でOrder集約のステータスを更新しています。
Commutative updates
日本語で"可換な更新"というのでしょうか。
図8
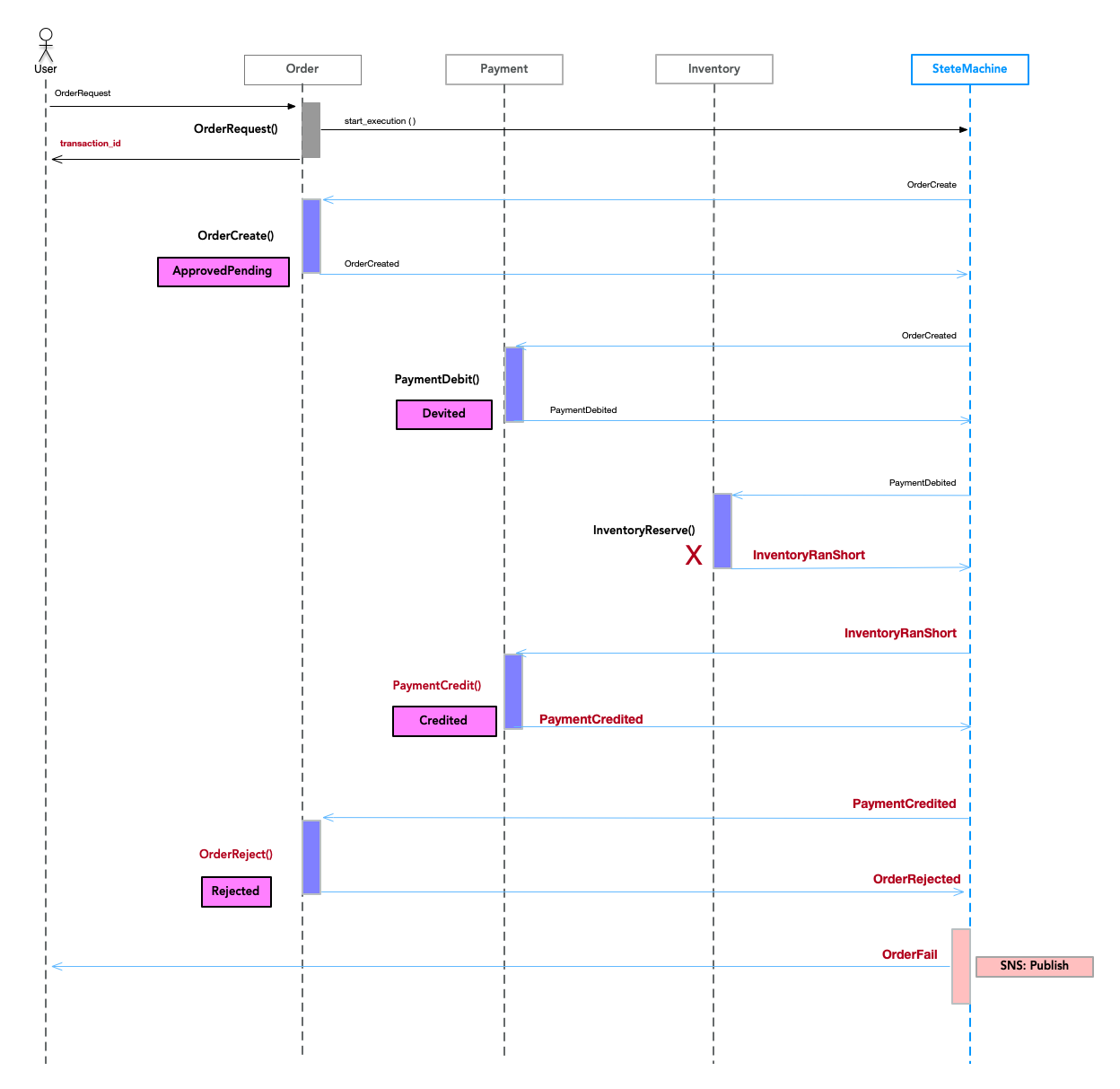
図のPayment状態で"Devited"/"Credited"のように、一旦"Devited"に更新したあと、
補償トランザクションで"Credited"にするように、すぐに取り消しを行うようなケースで
途中の状態が見えても問題にならないケースで行います。
コマンド表
私の場合は上記のようにシーケンス図で設計してから、StateMachineやLambdaの実装に落としていくのですが、
シーケンス図が問題点がわかりやすく一番しっくりしています。以下に全体のコマンド表をまとめています。
|Step|Service|ローカルトランザクション|トランザクション種類|補償トランザクション|state|
|:--|:--|:--|:--|:--|:--|:--|
|1|Order|OrderCreate()|Semantic Lock|- |APPROVED_PENDING|
|2|Payment|PaymentDebit()|補償可能トランザクション|PaymentCredit()|DEBITED/CREDITED|
|3|Inventory|InventoryReserve()|補償可能トランザクション|InventoryRelease()|RESERVED/RELEASED|
|4|Order|OrderApprove()|Semantic Lock|-|APPROVED|
State Machine
これでやっとState Machineを作成します。
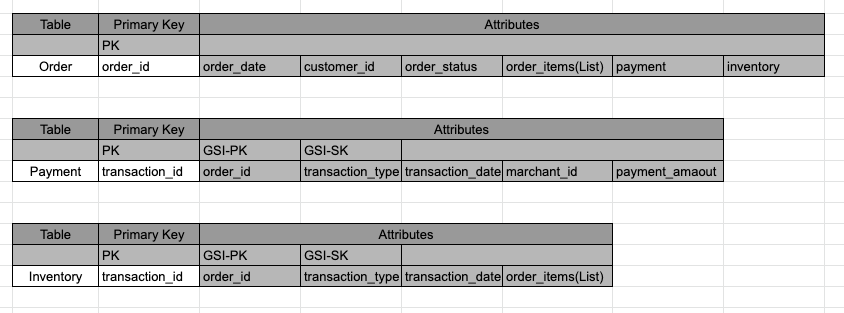
DynamoDB Table
その先には難しいローカルトランザクションに入っていくのですが以下のようなテーブルを作成しています。
PaymentとInventoryはで補償可能トランザクションが必要なので、transaction_idを取得できるようにGSIを作成しています。
Orderでは、Semantic lockなのでGSIを作成していません。
サンプルコードでは私の大好きなPynamoDBを使用してます。
直感的になおかつシンプルに書けるのが気に入ってます。
AWS Lambda Function
AWS Lambda functionでは以下の処理Atomicに実装しています。
- イベントメッセージ消費し
- 重複を検出して破棄し(冪等性)
- 集約を作成または更新
(4. イベントメッセージを送信する)
4はState Machineがやってくれるので、Lambdaはreturnするか、エラーをraiseさせるだけです。
なにかが欠けてる
再試行可能トランザクション: 成功することが保証されているトランザクション
成功が保証されてるって・・・
悩ましいですよね。State Machineに何かしらの障害が発生することを想定しないわけにはいきませんね。
じゃあ、どうするんじゃい?って感じですが、
サンプルではAWS Lambdaと同じようにリトライ処理が失敗した場合にメッセージをDead Letter Queueに突っ込むようにしています。
Dead Letter Queueに突っ込んだ後に、問題の対処をLambda functionで対処できるようにしています。
(対処のコードはサンプルにはありませんが・・・)
考察
Microservicesはサービス毎にDatabaseが分割されるため、Sagaで各サービスのローカルトランザクションを
EventでつないでいくというEventDrivenなシステムです。このようなEventDrivenアーキテクチャーでは、
イベントがつながっていかないと破綻するシステムなので、
AWS Stepfunctionがそこをカバーしてくれるとても大きいと思います。
また、AWS LambdaとDynamoDBの処理をAtomicに作るという部分がやはり難しい点と感じていますが、
DDDでいう集約やEntityを設計することと同じことかなと考えています。
また、AWS StepfunctionsのStateMachineでAWS Lambdaのエラーをキャッチできる
仕組みがとてもいいと思ました。
今までLambdaを失敗させないよう、おおもとでエラーをキャッチして正常終了させる
(エラーハンドリングはアプリケーションレイヤーで対処する)ようなことをしていたのですが、
Lambdaのコーディングもシンプルにできます。
つい先日、AWS Lambda DestinationsがGAされたみたいですが、
これでChoreography-based Saga Transactionも作りやすくなるかなと思っています。
そのうち、Choreography-based Saga Transactionの記事でもかこうかと思います。
コレオグラフィ VS オーケストレーション
複雑な処理の場合、オーケストレーションの方がいいというのが大半の意見なのですが、
StateMachineのJsonを見てもらえればわかるように、これだけの処理でも十分複雑だと思っています。
StateMachinがどんどん肥大化していく状況が結構辛いと思いました。
StepfunctionsがStateMachineのネスト対応ができるようになっているので、
この辺をどう設計していけばいいか考えていきたいと思います。
参考
本記事は以下の書籍を参考にしています。わかりやすく具体的に記載されているのでオススメです。
Microservices Patterns: With examples in Java