概要
noisy studentはImagenetでSOTAをたたき出した手法です。
普通データを増やして再学習するときは人間が教師データを作る必要がありますが、noisy studentはとにかくデータを集めて現状のモデルに推論して仮の教師データとして再学習させることで精度を上げられますので、教師データの作成の時間がいらないということになります。厳密には元のラベルのいずれかに該当するデータを集めてこないといけないですが、人が教師をつける必要がないのはありがたいですね。
詳しい説明は以下のサイトを参考にしてみてください。
解説: 画像認識の最新SoTAモデル「Noisy Student」を徹底解説!
論文:Self-training with Noisy Student improves ImageNet classification
やっている1つ1つはそこまで難しいことはやっていないので本記事ではimagenetを使って再現をしてみよう
と思いましたが私のPC能力では学習にとても時間がかかるのでresnet50とcifar10での実験をしてみました。
正直、疑似ラベルをつけるための画像の数が少ないですので精度はあくまで参考値で
手順と実装のやり方の参考として読んでいただけると幸いです。
前提
tensorflow 1.15.0
keras 2.3.1
Python 3.7.6
numpy 1.18.1
core i7
GTX1080ti
noisy studentの手順
noisy studentの手順としては以下の通りになります。
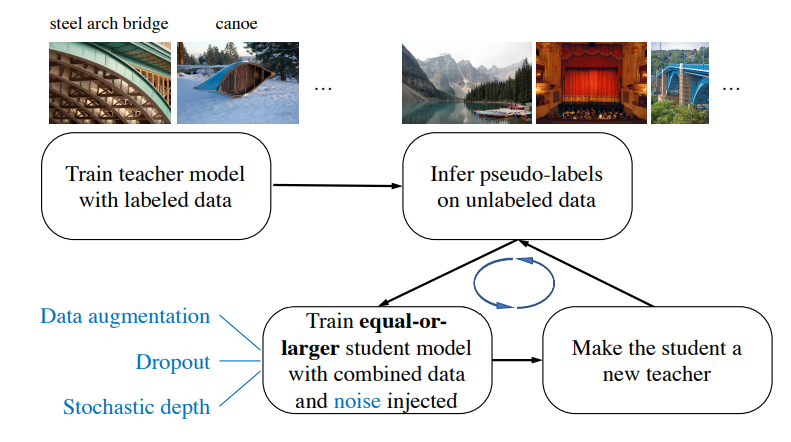
引用:Self-training with Noisy Student improves ImageNet classification
日本語にしてまとめると
- 教師となるモデルをラベル有データのみで学習させる
- 教師モデルでラベルなしデータに疑似ラベルをつける
- 教師モデルと同じか大きい生徒モデルを用意する
- 生徒モデルをラベル有+疑似ラベルデータでノイズを与えて学習させる
ここでノイズとは
- Rand Augmentation→入力画像に対するノイズ
- Dropout→モデルに対するノイズ
- Stochastic depth→モデルに対するノイズ
です。
実装するにあたってそれぞれ簡単に説明しておきます。
Rand Augmentation
たった2行で画像認識モデルの精度向上!?新しいDataAugmentation自動最適化手法「RandAugment」解説!
上記が解説がわかりやすいです。
要約すると、データ拡張の種類をX個準備して
- X個の中からN個取り出す
- MでAugmentationの強さを決める
以上です。簡単ですね。
noisy studentの論文ではN=2, M=27を採用しています。
今回の私の実装ではN=2, M=10としてます。
cifar10は画像サイズ小さいのであまり強くノイズをかけたら良くないかなという理由です。
Dropout
これは有名なので割愛します。
noisy studentの論文では0.5を採用しています。
Stochastic depth
[Survey]Deep Networks with Stochastic Depth
詳しく知りたい方は上記の解説を参考にしてみてください。
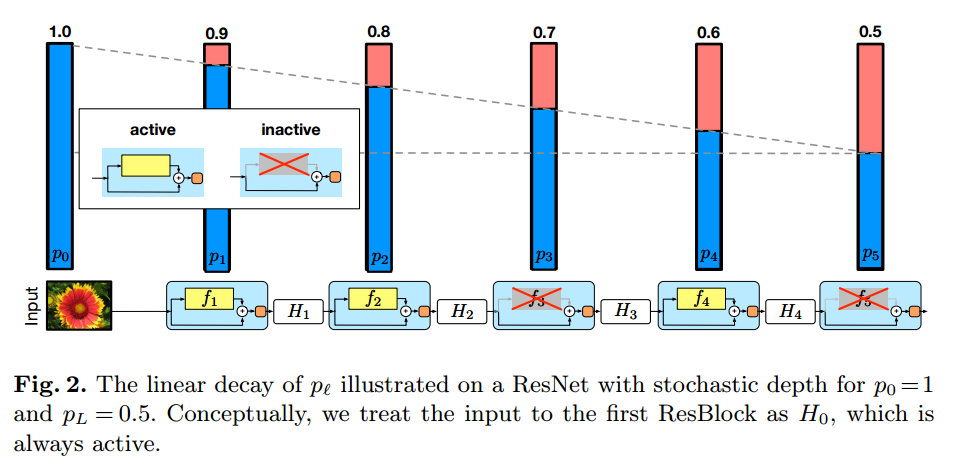
引用:Deep Networks with Stochastic Depth
上記の画像を元に簡単に説明します。
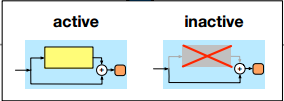
まずは基本としてはresnetの出力を確率的にスキップしている部分だけにするというものです。
そして、その確率を層が深くなるにつれて直線的に高くしていきます。
noisy studentの論文では最後の層を0.8としています。
また、推論時にはその確率を各resnet blockの出力に乗算します。
実装
前段が長かったですが実装していきたいと思います。
ここで、手順をおさらいしておきます。
- 教師となるモデルをラベル有データのみで学習させる
- 教師モデルでラベルなしデータに疑似ラベルをつける
- 教師モデルと同じか大きい生徒モデルを用意する
- 生徒モデルをラベル有+疑似ラベルデータでノイズを与えて学習させる
この順番で順に実装を解説していきます。
1. 教師となるモデルをラベル有データのみで学習させる
これはよく見かけるただの分類問題です。
モデルはefficient netを準備したかったですが、実装の手間を省くためにresnet50で試しました。
注意点は基本の構造はresnet50と同じですが画像サイズが小さくなりすぎないよう
ストライドを2にする数を減らしています。
データセットの準備
from keras.datasets import cifar10
from keras.utils.np_utils import to_categorical
# cifar10のデータセットを準備
(x_train_10,y_train_10),(x_test_10,y_test_10)=cifar10.load_data()
# 教師データをone-hot表現に直す
y_train_10 = to_categorical(y_train_10)
y_test_10 = to_categorical(y_test_10)
resnetのための関数準備
from keras.models import Model
from keras.layers import Input, Activation, Dense, GlobalAveragePooling2D, Conv2D
from keras import optimizers
from keras.layers.normalization import BatchNormalization as BN
from keras.callbacks import Callback, LearningRateScheduler, ModelCheckpoint, EarlyStopping
# 参考URL:https://www.pynote.info/entry/keras-resnet-implementation
def shortcut_en(x, residual):
'''shortcut connection を作成する。
'''
x_shape = K.int_shape(x)
residual_shape = K.int_shape(residual)
if x_shape == residual_shape:
# x と residual の形状が同じ場合、なにもしない。
shortcut = x
else:
# x と residual の形状が異なる場合、線形変換を行い、形状を一致させる。
stride_w = int(round(x_shape[1] / residual_shape[1]))
stride_h = int(round(x_shape[2] / residual_shape[2]))
shortcut = Conv2D(filters=residual_shape[3],
kernel_size=(1, 1),
strides=(stride_w, stride_h),
kernel_initializer='he_normal',
kernel_regularizer=l2(1.e-4))(x)
shortcut = BN()(shortcut)
return Add()([shortcut, residual])
def normal_resblock50(data, filters, strides=1):
x = Conv2D(filters=filters,kernel_size=(1,1),strides=(1,1),padding="same")(data)
x = BN()(x)
x = Activation("relu")(x)
x = Conv2D(filters=filters,kernel_size=(3,3),strides=(1,1),padding="same")(x)
x = BN()(x)
x = Activation("relu")(x)
x = Conv2D(filters=filters*4,kernel_size=(1,1),strides=strides,padding="same")(x)
x = BN()(x)
x = shortcut_en(data, x)
x = Activation("relu")(x)
return x
resnet50実装
inputs = Input(shape = (32,32,3))
x = Conv2D(32,(5,5),padding = "SAME")(inputs)
x = BN()(x)
x = Activation('relu')(x)
x = normal_resblock50(x, 64, 1)
x = normal_resblock50(x, 64, 1)
x = normal_resblock50(x, 64, 1)
x = normal_resblock50(x, 128, 2)
x = normal_resblock50(x, 128, 1)
x = normal_resblock50(x, 128, 1)
x = normal_resblock50(x, 128, 1)
x = normal_resblock50(x, 256, 1)
x = normal_resblock50(x, 256, 1)
x = normal_resblock50(x, 256, 1)
x = normal_resblock50(x, 256, 1)
x = normal_resblock50(x, 256, 1)
x = normal_resblock50(x, 256, 1)
x = normal_resblock50(x, 512, 2)
x = normal_resblock50(x, 512, 1)
x = normal_resblock50(x, 512, 1)
x = GlobalAveragePooling2D()(x)
x = Dense(10)(x)
outputs = Activation("softmax")(x)
teacher_model = Model(inputs, outputs)
teacher_model.summary()
学習準備
batch_size = 64
steps_per_epoch = y_train_10.shape[0] // batch_size
validation_steps = x_test_10.shape[0] // batch_size
log_dir = 'logs/softlabel/teacher/'
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
teacher_model.compile(loss = "categorical_crossentropy",optimizer = "adam", metrics = ["accuracy"])
trainj_gen = ImageDataGenerator(rescale = 1./255.).flow(x_train_10,y_train_10, batch_size)
val_gen = ImageDataGenerator(rescale = 1./255.).flow(x_test_10,y_test_10, batch_size)
学習
history = teacher_model.fit_generator(train_gen,
initial_epoch=0,
epochs=250,
steps_per_epoch = steps_per_epoch,
validation_data = val_gen, validation_steps = validation_steps,
callbacks=[checkpoint])
history = teacher_model.fit_generator(trainj_gen,
initial_epoch=250,
epochs=300,
steps_per_epoch = steps_per_epoch,
validation_data = val_gen, validation_steps = validation_steps,
callbacks=[checkpoint, reduce_lr, early_stopping])
結果確認
# 参考URL:https://qiita.com/yy1003/items/c590d1a26918e4abe512
def my_eval(model,x,t):
#model: 評価したいモデル, x: 予測する画像 shape = (batch,32,32,3) t:one-hot表現のlabel
ev = model.evaluate(x,t)
print("loss:" ,end = " ")
print(ev[0])
print("acc: ", end = "")
print(ev[1])
my_eval(teacher_model,x_test_10/255,y_test_10)
10000/10000 [==============================] - 16s 2ms/step
loss: 0.817680492834933
acc: 0.883899986743927
結果はテストデータで88.39%の精度でした。
2. 教師モデルでラベルなしデータに疑似ラベルをつける
まずは疑似ラベルを付けるための画像を準備します。
少ないですが、ここではimagenetから10クラスそれぞれ約800枚ほど収集しました。
それを32×32にリサイズしたものをデータセットとしました。
詳細の手順としては
- ラベルなし画像をnumpy配列にする
- ラベルなし画像に疑似ラベルをつける
- ある閾値以上の疑似ラベルデータのみを残す
- 各ラベルのデータ数を揃える
となります。
実装を載せますが3と4さえ守れば、決まったやり方はないと思いますので各々やりやすいように実装してみてください。
ラベルなし画像をnumpy配列にする
img_path = r"D:\imagenet\cifar10\resize"
img_list = os.listdir(img_path)
x_train_imgnet = []
for i in img_list:
abs_path = os.path.join(img_path, i)
temp = load_img(abs_path)
temp = img_to_array(temp)
x_train_imgnet.append(temp)
x_train_imgnet = np.array(x_train_imgnet)
ラベルなし画像に疑似ラベルをつける
# バッチサイズの設定
batch_size = 1
# 何ステップfor文を回すか
step = int(x_train_imgnet.shape[0] / batch_size)
print(step)
# 疑似ラベルのための空リスト
y_train_imgnet_dummy = []
for i in range(step):
#バッチサイズ分画像データを取り出す
x_temp = x_train_imgnet[batch_size*i:batch_size*(i+1)]
#正規化
x_temp = x_temp / 255.
#推論
temp = teacher_model.predict(x_temp)
#空リストへ追加
y_train_imgnet_dummy.extend(temp)
# リストをnumpy配列へ
y_train_imgnet_dummy = np.array(y_train_imgnet_dummy)
ある閾値以上の疑似ラベルデータのみを残す
# 閾値決め
threhold = 0.75
y_train_imgnet_dummy_th = y_train_imgnet_dummy[np.max(y_train_imgnet_dummy, axis=1) > threhold]
x_train_imgnet_th = x_train_imgnet[np.max(y_train_imgnet_dummy, axis=1) > threhold]
各ラベルのデータ数を揃える
# onehot vectorから分類のインデックスにする
y_student_all_dummy_label = np.argmax(y_train_imgnet_dummy_th, axis=1)
# 疑似ラベルの各クラスの数をカウント
u, counts = np.unique(y_student_all_dummy_label, return_counts=True)
print(u, counts)
# カウント数の最大値を計算
student_label_max = max(counts)
# numpy配列を各ラベル毎に分ける
y_student_per_label = []
y_student_per_img_path = []
for i in range(10):
temp_l = y_train_imgnet_dummy_th[y_student_all_dummy_label == i]
print(i, ":", temp_l.shape)
y_student_per_label.append(temp_l)
temp_i = x_train_imgnet_th[y_student_all_dummy_label == i]
print(i, ":", temp_i.shape)
y_student_per_img_path.append(temp_i)
# それぞれのラベルで最大のカウント数になるようにデータをコピー
y_student_per_label_add = []
y_student_per_img_add = []
for i in range(10):
num = y_student_per_label[i].shape[0]
temp_l = y_student_per_label[i]
temp_i = y_student_per_img_path[i]
add_num = student_label_max - num
q, mod = divmod(add_num, num)
print(q, mod)
temp_l_tile = np.tile(temp_l, (q+1, 1))
temp_i_tile = np.tile(temp_i, (q+1, 1, 1, 1))
temp_l_add = temp_l[:mod]
temp_i_add = temp_i[:mod]
y_student_per_label_add.append(np.concatenate([temp_l_tile, temp_l_add], axis=0))
y_student_per_img_add.append(np.concatenate([temp_i_tile, temp_i_add], axis=0))
# それぞれラベルのカウント数を確認
print([len(i) for i in y_student_per_label_add])
# ラベルごとのデータを合体させる
student_train_img = np.concatenate(y_student_per_img_add, axis=0)
student_train_label = np.concatenate(y_student_per_label_add, axis=0)
# 元のcifar10のnumpy配列と合体
x_train_student = np.concatenate([x_train_10, student_train_img], axis=0)
y_train_student = np.concatenate([y_train_10, student_train_label], axis=0)
3. 教師モデルと同じか大きい生徒モデルを用意する
ここでは教師モデルと同じサイズのresnet50で行こうと思います。
モデルのノイズとしては
- Dropout→モデルに対するノイズ
- Stochastic depth→モデルに対するノイズ
の2つです。
Stochastic depthの実装はgithubに上がっている下記の実装を参考にしました。
実装URL:https://github.com/transcranial/stochastic-depth/blob/master/stochastic-depth.ipynb
私の実装では
先に各resblockでの確率のリストを作っておいて、モデルの定義の時に1つずつ取り出して使うという実装にしてます。
先に定義しておいて後で使う方がミスがなくていいかなと思ったのでそうしています。
# 各resblockの適用する確率を定義する関数
def get_p_survival(l, L, pl):
pt = 1 - (l / L) * (1 - pl)
return pt
# 確率で1か0を出力
# 学習時:出力×1or0
# 推論時:出力×確率
def stochastic_survival(y, p_survival=1.0):
# binomial random variable
survival = K.random_binomial((1,), p=p_survival)
# during testing phase:
# - scale y (see eq. (6))
# - p_survival effectively becomes 1 for all layers (no layer dropout)
return K.in_test_phase(tf.constant(p_survival, dtype='float32') * y,
survival * y)
def stochastic_resblock(data, filters, strides, depth_num, p_list):
print(p_list[depth_num])
x = Conv2D(filters=filters,kernel_size=(1,1),strides=(1,1),padding="same")(data)
x = BN()(x)
x = Activation("relu")(x)
x = Conv2D(filters=filters,kernel_size=(3,3),strides=(1,1),padding="same")(x)
x = BN()(x)
x = Activation("relu")(x)
x = Conv2D(filters=filters*4,kernel_size=(1,1),strides=strides,padding="same")(x)
x = BN()(x)
x = Lambda(stochastic_survival, arguments={'p_survival': p_list[depth_num]})(x)
x = shortcut_en(data, x)
x = Activation("relu")(x)
#層の数をインクリメント
depth_num += 1
return x, depth_num
L = 16
pl = 0.8
p_list = []
for l in range(L+1):
x = get_p_survival(l,L,pl)
p_list.append(x)
# 0始まりだがinput layerを飛ばすために1で開始
depth_num = 1
inputs = Input(shape = (32,32,3))
x = Conv2D(32,(5,5),padding = "SAME")(inputs)
x = BN()(x)
x = Activation('relu')(x)
# depth_numを関数内でインクリメントしながら次の層で使用
x, depth_num = stochastic_resblock(x, 64, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 64, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 64, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 128, 2, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 128, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 128, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 128, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 512, 2, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 512, 1, depth_num, p_list)
x, depth_num = stochastic_resblock(x, 512, 1, depth_num, p_list)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(10)(x)
outputs = Activation("softmax")(x)
student_model = Model(inputs, outputs)
student_model.summary()
student_model.compile(loss = "categorical_crossentropy",optimizer = "adam", metrics = ["accuracy"])
4. 生徒モデルをラベル有+疑似ラベルデータでノイズを与えて学習させる
データセットは2.で作成済なので、残りはRand Augmentationだけです。
githubに上がっている下記の実装を使わせていただきました。
実装URL:https://github.com/heartInsert/randaugment/blob/master/Rand_Augment.py
githubの実装はデータ形式がPILなのでnumpy配列に変換しながら教師データを出力するデータジェネレーターを自作しました。
Rand Augmentation定義
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageEnhance, ImageOps
import numpy as np
import random
class Rand_Augment():
def __init__(self, Numbers=None, max_Magnitude=None):
self.transforms = ['autocontrast', 'equalize', 'rotate', 'solarize', 'color', 'posterize',
'contrast', 'brightness', 'sharpness', 'shearX', 'shearY', 'translateX', 'translateY']
if Numbers is None:
self.Numbers = len(self.transforms) // 2
else:
self.Numbers = Numbers
if max_Magnitude is None:
self.max_Magnitude = 10
else:
self.max_Magnitude = max_Magnitude
fillcolor = 128
self.ranges = {
# these Magnitude range , you must test it yourself , see what will happen after these operation ,
# it is no need to obey the value in autoaugment.py
"shearX": np.linspace(0, 0.3, 10),
"shearY": np.linspace(0, 0.3, 10),
"translateX": np.linspace(0, 0.2, 10),
"translateY": np.linspace(0, 0.2, 10),
"rotate": np.linspace(0, 360, 10),
"color": np.linspace(0.0, 0.9, 10),
"posterize": np.round(np.linspace(8, 4, 10), 0).astype(np.int),
"solarize": np.linspace(256, 231, 10),
"contrast": np.linspace(0.0, 0.5, 10),
"sharpness": np.linspace(0.0, 0.9, 10),
"brightness": np.linspace(0.0, 0.3, 10),
"autocontrast": [0] * 10,
"equalize": [0] * 10,
"invert": [0] * 10
}
self.func = {
"shearX": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, magnitude * random.choice([-1, 1]), 0, 0, 1, 0),
Image.BICUBIC, fill=fillcolor),
"shearY": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, 0, magnitude * random.choice([-1, 1]), 1, 0),
Image.BICUBIC, fill=fillcolor),
"translateX": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, magnitude * img.size[0] * random.choice([-1, 1]), 0, 1, 0),
fill=fillcolor),
"translateY": lambda img, magnitude: img.transform(
img.size, Image.AFFINE, (1, 0, 0, 0, 1, magnitude * img.size[1] * random.choice([-1, 1])),
fill=fillcolor),
"rotate": lambda img, magnitude: self.rotate_with_fill(img, magnitude),
# "rotate": lambda img, magnitude: img.rotate(magnitude * random.choice([-1, 1])),
"color": lambda img, magnitude: ImageEnhance.Color(img).enhance(1 + magnitude * random.choice([-1, 1])),
"posterize": lambda img, magnitude: ImageOps.posterize(img, magnitude),
"solarize": lambda img, magnitude: ImageOps.solarize(img, magnitude),
"contrast": lambda img, magnitude: ImageEnhance.Contrast(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"sharpness": lambda img, magnitude: ImageEnhance.Sharpness(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"brightness": lambda img, magnitude: ImageEnhance.Brightness(img).enhance(
1 + magnitude * random.choice([-1, 1])),
"autocontrast": lambda img, magnitude: ImageOps.autocontrast(img),
"equalize": lambda img, magnitude: img,
"invert": lambda img, magnitude: ImageOps.invert(img)
}
def rand_augment(self):
"""Generate a set of distortions.
Args:
N: Number of augmentation transformations to apply sequentially. N is len(transforms)/2 will be best
M: Max_Magnitude for all the transformations. should be <= self.max_Magnitude """
M = np.random.randint(0, self.max_Magnitude, self.Numbers)
sampled_ops = np.random.choice(self.transforms, self.Numbers)
return [(op, Magnitude) for (op, Magnitude) in zip(sampled_ops, M)]
def __call__(self, image):
operations = self.rand_augment()
for (op_name, M) in operations:
operation = self.func[op_name]
mag = self.ranges[op_name][M]
image = operation(image, mag)
return image
def rotate_with_fill(self, img, magnitude):
# I don't know why rotate must change to RGBA , it is copy from Autoaugment - pytorch
rot = img.convert("RGBA").rotate(magnitude)
return Image.composite(rot, Image.new("RGBA", rot.size, (128,) * 4), rot).convert(img.mode)
def test_single_operation(self, image, op_name, M=-1):
'''
:param image: image
:param op_name: operation name in self.transforms
:param M: -1 stands for the max Magnitude in there operation
:return:
'''
operation = self.func[op_name]
mag = self.ranges[op_name][M]
image = operation(image, mag)
return image
データジェネレーター定義
img_augment = Rand_Augment(Numbers=2, max_Magnitude=10)
def get_random_data(x_train_i, y_train_i, data_aug):
x = array_to_img(x_train_i)
if data_aug:
seed_image = img_augment(x)
seed_image = img_to_array(seed_image)
else:
seed_image = x_train_i
seed_image = seed_image / 255
return seed_image, y_train_i
def data_generator(x_train, y_train, batch_size, data_aug):
'''data generator for fit_generator'''
n = len(x_train)
i = 0
while True:
image_data = []
label_data = []
for b in range(batch_size):
if i==0:
p = np.random.permutation(len(x_train))
x_train = x_train[p]
y_train = y_train[p]
image, label = get_random_data(x_train[i], y_train[i], data_aug)
image_data.append(image)
label_data.append(label)
i = (i+1) % n
image_data = np.array(image_data)
label_data = np.array(label_data)
yield image_data, label_data
データジェネレーターができたので後は学習するだけです。
学習
log_dir = 'logs/softlabel/student1_2/'
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
batch_size = 64
steps_per_epoch = x_train_student.shape[0] // batch_size
validation_steps = x_test_10.shape[0] // batch_size
# 0~250epochは学習率を変えずに学習
history = student_model.fit_generator(data_generator(x_train_student, y_train_student, batch_size, data_aug = True),
initial_epoch=0,
epochs=250,
steps_per_epoch = steps_per_epoch,
validation_data = data_generator_wrapper(x_test_10, y_test_10, batch_size, data_aug = False),
validation_steps = validation_steps,
callbacks=[checkpoint])
# 250epoch~300epochは学習率を変えつつ学習の打ち止め実施
history = student_model.fit_generator(data_generator(x_train_student, y_train_student, batch_size, data_aug = True),
initial_epoch=250,
epochs=300,
steps_per_epoch = steps_per_epoch,
validation_data = data_generator_wrapper(x_test_10, y_test_10, batch_size, data_aug = False),
validation_steps = validation_steps,
callbacks=[checkpoint, reduce_lr, early_stopping])
結果確認
my_eval(student_model,x_test_10/255,y_test_10)
10000/10000 [==============================] - 19s 2ms/step
loss: 0.24697399706840514
acc: 0.9394000172615051
結果はテストデータで93.94%の精度でした。
当然ですが上がっていますね。
追加実験
やっていて「教師モデルの時点でノイズを有効にした場合とどちらが精度が良いか」という疑問が浮かび上がりましたので確認しました。以下の表に簡単にまとめました。
| 実験 | 教師 モデル |
テストデータloss/accuracy | 生徒 モデル |
テストデータloss/accuracy |
|---|---|---|---|---|
| 1 | ノイズなし | 0.8176/88.39% | ノイズあり | 0.2470/93.94% |
| 2 | ノイズあり | 0.2492/94.14% | ノイズあり | 0.2289/94.28% |
今回のケースだと教師からノイズを与えた方が精度が少し高くなりました。
本当はロバスト性も確認したかったのですが力尽きました。
以上です。
不明点、おかしい点ありましたらコメントよろしくお願いします。