J-Quantsを用いた財務スクリーニングの方法(財務データセット構築編)
はじめに
これまで、Pythonによる株式スクリーニング自動化・実践のシリーズ記事を投稿してきました。先日、「J-Quants APIを使った財務データの取得と財務スクリーニング」について、質問があったため、ここではそれについてまとめます。
前回の財務スクリーニングの記事ではyfinanceを用いた方法を紹介しましたが、財務情報は通期では4期分、4半期は1年分のデータのみが取得できるとされるため、過去長期間データを使用するバックテストには、別の取得元が必要です。
yfinanceに関して情報元
J-Quants APIは、日本取引所グループ (JPX) が提供する、個人投資家向けの金融データAPIサービスです。このサービスは、過去の株価データや財務データなどの金融データをAPI経由で取得できます。
筆者は、ライトプラン(¥1,650/月(税込))に加入中で、これを用いると、過去5年分の財務情報が4半期および通期で取得できる他、上場銘柄一覧、株価四本値および決算発表予定日などの、投資分析に必要な様々なデータが入手可能です。
今回の記事の内容
そこで今回は、J-Quants APIを使って東証プライム全銘柄の財務データと株価データを取得し、時系列で統合するパイプラインを紹介します。並列処理やバッチ処理を活用して、大量のデータを効率的に処理し、最終的に機械学習や銘柄財務スクリーニングに使える財務データセットを作成する方法を説明します。
本記事のメイントピック
四半期ごとに「公表済みの情報5年分」を用いて算出された財務指標を含む巨大なデータセットを構築するコードの紹介。
契約方法とライセンスキーの取得の方法は公式HPに詳しく書かれているので、そちらをご参照ください。
J-Quantsの公式HP
注意
筆者は現在コロナウイルス感染症から復帰途中で、いまだに意識とやる気がありません。内容の正確性には注意していますが、いつもよりも大いに生成AIの力に頼っています。内容を鵜呑みにする前に、読者の皆様で、一度冷静にご判断いただくことをお勧めします。また、画面越しに感染のリスクがあるため、画面から十分離れて、一読ください。
これまでの経緯
本記事は、Pythonによる株式スクリーニング自動化・実践の関連記事です。
これまでの背景や検証の流れは、以下の記事をご確認ください。

現在構築中のスクリーニングモデルの全体像と今回やること
- 中期スイングに適したRCIスパンを探索した
- RCIが使える指標かどうか確かめ始めた
- 銘柄情報データベース作り始めたけど地味すぎて飽きた
- スクリーニング結果自動通知bot、結果の可視化とXへの投稿はできるようになった
- 生成AI無料期間にスクリーニング結果自動通知botを作り始めた
- 今回のモデルのスクリーニング速度を100倍向上した方法
- yfinance由来の軽量データセット構築
- 今回のモデルの改善点
- 今回のスクリーニングモデルの精度
- 相場状況を簡易的に数値化する
- 財務スクリーニング
パイプラインの全体フロー
このデータセットは、次の順番で作ります。
- まず準備: API認証して、取得する銘柄リスト(今回はプライム約1600銘柄)を読み込みます。
- 次に集める: 各銘柄の財務データと株価データを取り込み、銘柄ごとに別々のフォルダに保存します。
- つなぐ・計算する: 日付をそろえてデータを結合し、累計の数値から四半期の数値を作り、直近4四半期で合計(または平均)したTTMを出して指標を計算します。
- まとめる: すべての結果をまとめて、最終のCSVとサマリーを出力します。
パイプラインの特徴
| 特徴 | 詳細 | 技術的メリット |
|---|---|---|
| 並列処理 |
concurrent.futures.ThreadPoolExecutor を利用し、APIからのデータ取得処理をマルチスレッドで並列化。多数の銘柄に対するリクエストを同時に実行し、データ収集にかかる時間を短縮。 |
1600銘柄の財務データと株価データ5年分を数分以内で取得可能 |
| バッチ処理 | 全銘柄を指定されたサイズ(デフォルト200)のバッチに分割して処理。一度にメモリにロードするデータ量を制限することで、大規模なデータセットを扱う際のメモリ消費量を抑制し、安定した処理を実現。 | メモリ制御・途中再開が容易 |
| 指標のベクトル演算 | 財務指標(ROE, PER, PBR等)の計算には、Pandasのベクトル演算を利用。ループ処理を避け、データフレーム全体に対して一括で高速に計算を実行。 | ROE, PER, PBR等を高速算出 |
クラス構成と主要メソッドの役割
このパイプラインの全機能は CompleteFinancialAnalysisPipelineExcel クラスに集約されており、各処理は以下のメソッドによって分担されています
| フェーズ | メソッド名 | 役割(機能) | 処理の詳細 |
|---|---|---|---|
| 準備 | __init__ |
初期設定(APIセッション/出力先/バッチサイズなど) | ログ設定、ディレクトリ作成、HTTPセッション初期化 |
get_jquants_token |
APIにログインしてトークンを取得 | refreshToken取得→idToken発行→Authorizationヘッダー設定 | |
get_prime_tickers_from_excel |
対象銘柄リストを作成 | Excel読込→プライム抽出→4桁化→重複除去 | |
| データ収集 | fetch_financial_data_parallel |
財務データを並列取得 | statements API→DataFrame化→IFRS/JP/US分類 |
fetch_prices_data_parallel |
過去5年の株価データを並列取得 | daily_quotes API→DataFrame化→数値型変換 | |
calculate_date_range |
株価取得期間を算出 | 現在日から過去5年の開始・終了日を返す(start_date, end_date) |
|
save_..._data |
取得データを保存 | 銘柄ごとにCSV保存(financial_*.csv, daily_prices.csv)と簡易サマリー | |
| データ処理 | create_ticker_batches |
銘柄をバッチに分割 | 200件ずつのリストに分割 |
process_batch |
1バッチの処理を実行 | 読込→統合→四半期化/TTM/指標→Parquet保存 | |
merge_batch_data |
株価と財務を日付で結合(ポイントインタイム) | 各価格日に対し「開示日≤価格日」の最新行を結合 | |
calculate_batch_metrics |
四半期化とTTM指標を計算 | 累計→四半期差分、4期合計/平均、OPM/ROE/PER/PBR など | |
save_batch_data |
中間データを保存 |
batch_XXX.parquetを書き出し |
|
| 最終統合 | combine_all_batches |
全バッチを連結し最終ファイルを作成 | Parquet読込→連結→最終CSV出力 |
create_final_summary |
まとめの統計を出力 | 基準別・銘柄別に件数と平均指標を集計→CSV |
処理フローの詳細
以下では、パイプラインの主要ステップを取り上げ、各ステップで何をしているのかを簡潔に説明します。
まずは以下の主要ポイントに絞って読むことを推奨します(各ポイントは後続の該当Stepで詳述)。
-
認証と銘柄リスト(Step 1):
.envから認証→トークン発行、プライム銘柄を抽出。 -
取得期間の算出(Step 2):
calculate_date_rangeで過去5年の開始・終了日を決定。 - 株価/財務データの並列取得(Step 2): APIから取得し銘柄別に保存。
-
ポイントインタイム結合(Step 3.2): 株価日tに対し、
DisclosedDate ≤ tの最新財務のみを結合(merge_batch_data)。 -
累計→四半期→TTM(Step 3.3): YTD差分で四半期化(EPSは差分しない)→直近4期を合計/平均(
calculate_batch_metrics)。 - PBR(前年度FYのBPSを使用、Step 3.3): 原則「前年度FYのBPS」で計算。FY行に当期BPSがあるときのみ当期BPSを使用。
-
全バッチの統合と最終出力(Step 4):
output/integrated_data/all_companies_integrated_final.csvと 2種サマリーCSVを出力。
用語(略語)
期間(TTM/YTD/FY/四半期)と主要指標(EPS/BPS/PER/PBR/ROE/OPM/BPR)の用語をまとめます。
用語の詳細(期間・指標)
| 用語 | 日本語 | 定義・意味 | 代表式の例 | 備考 |
|---|---|---|---|---|
| TTM | 過去12カ月 | 直近4四半期の合計/平均で表す期間指標 | 売上・利益=直近4期合計/自己資本=直近4期平均 | 4期のスライド窓を使用 |
| YTD | 年初来累計 | 年度内の累計値(J-Quantsの四半期は多くがこれ) | C(k)=Q1+…+Qk | 四半期化は差分で復元 |
| FY | 通期(年度決算) | 年度末の通期決算 | 多くは4Q相当 | Annual/FY |
| 1Q/2Q/3Q | 四半期 | 第1〜第3四半期 | Qk = CUM(k) − CUM(k−1)(EPSは差分しない) | 期間値はそのまま |
| EPS | 1株当たり利益 | 期間の利益を発行株式数で割った値 | 利益_TTM ÷ 発行株式数 | 本実装では四半期値を合計してTTM化 |
| PER | 株価収益率 | 株価の割高・割安度をEPSで評価 | 株価 ÷ EPS_TTM | EPS_TTMが0/NaNならNaN |
| BPS | 1株当たり純資産 | 純資産を発行株式数で割った値 | 純資産 ÷ 発行株式数 | PBR計算に使用(FY参照) |
| PBR | 株価純資産倍率 | 株価の割高・割安度をBPSで評価 | 株価 ÷ BPS | 四半期は直近FY BPS、FY欠損は直近FY BPSで代替 |
| BPR | Book-to-Price比率 | PBRの逆数(価値/価格) | BPS ÷ 株価 = 1 ÷ PBR | 必要に応じて参考指標として解釈 |
| ROE | 自己資本利益率 | 自己資本に対する利益の割合 | 利益_TTM ÷ 平均自己資本_TTM × 100 | 平均は直近4期平均 |
| OPM | 営業利益率 | 売上高に対する営業利益の割合 | 営業利益_TTM ÷ 売上高_TTM × 100 | 売上・利益はTTM合計 |
簡易アウトライン
- Step 1: 認証と銘柄リスト
- Step 2: 期間算出・データ並列取得
- Step 3: バッチ処理
- 3.1 財務データの読み込みと基準選択
- 3.2 ポイントインタイム結合
- 3.3 財務指標計算(TTM+BPSは前年度FY参照)
- 3.4 中間保存
- Step 4: 全バッチの統合と最終出力
Step 1: 認証と銘柄リストの取得
パイプラインの実行開始後、まずAPIへの認証を行い、処理対象となる銘柄コードのリストを準備します。
1.1 環境変数ファイルの準備
J-Quants.envファイルの作成
プロジェクトのルートディレクトリにJ-Quants.envファイルを作成し、以下の内容を記述します:
# J-Quants.env
JQUANTS_EMAIL=your_email@example.com
JQUANTS_PASSWORD=your_password
J-Quantsに登録した時のメールアドレスとパスワード
ファイルの配置場所
financial_analysis_project/
├── J-Quants.env # ← ここに配置
├── complete_financial_analysis_pipeline_excel.py
├── data_j (1).xlsx
└── output/
1.2 認証プロセスの詳細 (get_jquants_token)
環境変数ファイルから認証情報を読み込み、J-Quants APIからIDトークンを取得します。
認証フロー(トークンの取得と使用)
-
環境変数の読み込み:
load_dotenv('J-Quants.env')で.envファイルから認証情報を取得 - ユーザー認証: メールアドレスとパスワードをJ-Quantsに送信して「リフレッシュトークン」を取得
-
リフレッシュトークン取得: 認証成功時に
refreshTokenを取得(長期間有効) - IDトークン取得: リフレッシュトークンを使って「IDトークン」を取得(短時間有効)
-
ヘッダー設定:
Authorization: Bearer {idToken}として以降のリクエストヘッダに設定
実装コードの流れ(トークン取得の詳細)
# 1. 環境変数読み込み(J-Quants.envファイルから)
load_dotenv(dotenv_path='J-Quants.env')
JQUANTS_MAIL = os.getenv("JQUANTS_EMAIL") # あなたのメールアドレス
JQUANTS_PASS = os.getenv("JQUANTS_PASSWORD") # あなたのパスワード
# 2. ユーザー認証(メールアドレス・パスワードでログイン)
auth_data = {"mailaddress": JQUANTS_MAIL, "password": JQUANTS_PASS}
auth_response = session.post("https://api.jquants.com/v1/token/auth_user", data=json.dumps(auth_data))
refresh_token = auth_response.json()["refreshToken"] # 長期間有効なトークンを取得
# 3. IDトークン取得(リフレッシュトークンを使って短時間有効なトークンを取得)
token_response = session.post("https://api.jquants.com/v1/token/auth_refresh", params={"refreshtoken": refresh_token})
id_token = token_response.json()["idToken"] # 短時間有効なトークンを取得
# 4. ヘッダー設定(このIDトークンを使ってAPIにアクセス)
headers = {"Authorization": f"Bearer {id_token}"}
1.3 銘柄リスト取得 (get_prime_tickers_from_excel)
Excelファイルを読み込み、市場区分が「プライム(内国株式)」の銘柄をフィルタリングし、重複を除いた証券コードのリストを作成します。
エクセルデータ取得元
Step 2: 財務・株価データの並列取得
fetch_financial_data_parallel, fetch_prices_data_parallel, save_..._data
次に、取得した銘柄リストに基づき、必要な生データをAPIから並列で取得し、ローカルに保存します。
-
財務データ取得 (
fetch_financial_data_parallel): 全銘柄の財務諸表データを並列取得します。 -
株価データ取得 (
fetch_prices_data_parallel): 全銘柄の過去5年分の日次株価データを並列取得します。 -
データ保存 (
save_..._data): 取得したデータは、銘柄コード別のディレクトリにfinancial_jp.csvやdaily_prices.csvといったファイル名で保存されます。これにより、再実行時にAPIへの負荷をかけずに処理を再開できます。
*財務データは、会計基準ごとに分類されて保存されます。各銘柄のフォルダには以下のファイルが作成されます:
-
financial_ifrs.csv: IFRS基準の財務データ -
financial_jp.csv: 日本基準の財務データ -
financial_us.csv: 米国基準の財務データ -
financial_other.csv: その他の基準の財務データ -
financial_all.csv: 全基準の財務データ -
financial_summary.csv: 各基準のレコード数などのサマリー情報
各CSVファイルには、TypeOfDocumentフィールドに会計基準と決算期の情報が含まれており、これにより時系列での分析が可能になります。
株価データの期間計算
- 開始日: 現在日付から5年(1,825日)前
- 終了日: 現在日付
-
計算式:
end_date - timedelta(days=5*365)
def calculate_date_range(self):
"""過去5年分の日付範囲を計算"""
end_date = datetime.now().date()
start_date = end_date - timedelta(days=5*365) # 5年分
print(f" 取得期間: {start_date} ~ {end_date}")
return start_date, end_date
Step 3: バッチ単位でのデータの一時統合と財務指標計算
全銘柄を一度に処理するとメモリ負荷が高いため、200銘柄ずつのバッチに分割して、財務指標の計算などの処理を繰り返します。
この章のつながり(概要)
- Step 3.1: 財務データを読み込み、会計基準と決算期で整理(出力: 選別済み財務データ)
- Step 3.2: 価格日tごとに「t以前の最新開示」を結合(出力: df_merged = 価格×最新開示)
- Step 3.3: 累計→四半期→TTMの順に整形し、指標を計算(出力: TTM・指標付きデータ)
- Step 3.4: 中間ファイルとしてParquetへ保存
3.1 財務データの読み込みと基準選択
load_batch_financial_data
1バッチ(200銘柄)分の財務データをローカルファイルからメモリにロードします。この際、会計基準の異なる複数のファイルが存在する場合は、以下の優先順位で1つのファイルを選択します。
優先順位
- IFRS基準(多くの銘柄がこれを採用しているため最優先)
- JP基準(IFRSがない場合)
- US基準(IFRS、JPがない場合)
分類ロジック
TypeOfDocumentフィールドの文字列を基に、以下のように分類・判定します。
| 基準 | 判定条件 | 説明 |
|---|---|---|
| IFRS |
TypeOfDocumentに'IFRS'を含む |
国際財務報告基準 |
| JP |
TypeOfDocumentに'JP'を含む |
日本基準 |
| US |
TypeOfDocumentに'US'を含む |
米国基準 |
| その他 | 上記に該当しない | 基準不明のデータ |
決算期の分類
さらに、TypeOfDocumentフィールドには決算期の情報も含まれており、以下のように分類されます:
| 決算期 | 判定条件 | 説明 |
|---|---|---|
| 通期決算 |
TypeOfDocumentに'FY'または'Annual'を含む |
年度末の通期決算 |
| 四半期決算 |
TypeOfDocumentに'1Q'、'2Q'、'3Q'を含む |
第1四半期、第2四半期、第3四半期の決算 |
| その他 | 上記に該当しない | 中間決算など |
実装例
コードでは以下のように分類・判定を行っています:
# 会計基準の分類
ifrs_data = df[df['TypeOfDocument'].str.contains('IFRS', na=False)]
jp_data = df[df['TypeOfDocument'].str.contains('JP', na=False)]
us_data = df[df['TypeOfDocument'].str.contains('US', na=False)]
# 決算期の分類
df_financial['is_quarterly'] = df_financial['TypeOfDocument'].str.contains('1Q|2Q|3Q', na=False)
df_financial['is_annual'] = df_financial['TypeOfDocument'].str.contains('FY|Annual', na=False)
この分類により、各銘柄の財務データを会計基準と決算期の両方の観点から整理し、時系列での分析に適した形で保存・処理することができます。
ここで整理した財務データは、次の Step 3.2 で価格データと結合します。
3.2 ポイントインタイム・データ統合
merge_batch_data
株価と財務の時系列がズレないように統合します(過去日の株価に未来の開示を混ぜない)。
なお、PER/PBR/BPRなど一部の指標は株価がないと計算できないため、ここでの価格データとの統合・参照が必要になります。
- 銘柄ごとに、日次株価データ(5年分)の各行をループ処理します。
- 各行(特定の日付の株価データ)について、
current_date = price_row['Date']として現在の日付を取得します。 - その銘柄の全財務データの中から、開示日が現在の日付以前 (
df_financial['DisclosedDate'] <= current_date) のものだけを抽出します。 - 抽出された過去の財務データの中から、最後の行 (
.iloc[-1]) を選択します。これがcurrent_date時点で利用可能だった最新の財務情報となります。 - この最新の財務情報と現在の株価情報を結合し、新しい1行のデータを作成します。
# 統合アルゴリズムの概念
for date in stock_dates:
fin_subset = fin_df[fin_df['DisclosedDate'] <= date]
if not fin_subset.empty:
latest_row = fin_subset.iloc[-1] # 時点 t で最も新しい財務
merge(price_row, latest_row)
補足(現在の実装での堅牢化)
- 株価(
df_prices)と財務(df_financial)は結合前に必ず日付で昇順ソートしておきます。 - 同一会計期間に複数のFY開示がある場合は「最新の開示」を採用します(PBRは前年度FYのBPSを用いる方針で安定化)。
- マッチしない価格日は出力しません(無駄なNaN行を量産しない方針)。
ポイントインタイム結合の流れ
ここで得た結合結果(df_merged)は、Step 3.3 の四半期化とTTM指標計算の入力になります。
3.3 財務指標計算(TTMベース+BPSは前年度FY参照)
calculate_batch_metrics
前提と流れ
J-Quantsの四半期値は年初来累計(YTD)。まず累計を四半期の期間値へ戻し、その直近4期を合計/平均して通年相当(TTM)を作ります。
目的
このステップでは、各四半期時点で公表済みの情報だけを用いて指標を計算し、FY(通期決算)を待たずに直近四半期までの情報から通年相当(過去1年)の指標を得ます。
背景と用語の整理(YTD/FY/期間値/TTM)
J-Quantsの多くの四半期項目は年初来累計(YTD)として提供されます。1Q、2Q、3Qは各時点までの累計で、FYは年度末の通期(実質4Q累計)に該当します。四半期の「期間値(period)」は、その四半期だけの増分を指し、一般に Qk = CUM(k) − CUM(k−1)(1QはC1)で復元します。
TTMは「直近4四半期」を合計または平均して、FYを待たずに“過去12カ月”の通年相当を得るための考え方です。
なぜ「一度バラして(期間値にして)から合算」するのか
累計(YTD)のまま合算すると二重計上になるため、まず差分で期間値を復元してから4期分を合計します。これにより毎四半期、FYを待たずに過去12カ月相当の値を更新できます。なお、EPSは四半期の期間値として提供されることが多いため差分は不要で、そのまま4期合計してEPS_TTMを作ります。
やること(累計→四半期化→TTM)
- 四半期化(期間値に復元)
- Q1は累計=期間値
- Q2以降は「当期累計 − 直前期累計」
- EPSは差分しない(期間値としてそのまま)
- TTMの作成
- 売上・利益・EPSは直近4期の合計
- 自己資本など水準系は直近4期の平均
- 指標の算出
- OPM_TTM、ROE_TTM、PER_TTM など
指標ごとの価格依存性(どの列を参照するか)
| 指標 | 株価必要 | 主に使う列 |
|---|---|---|
| PER_TTM | Yes |
close_price, eps_ttm
|
| PBR | Yes |
close_price, bps(BPS=前年度FY。FY行に当期BPSがあれば当期) |
| BPR | Yes |
bps, close_price(= 1 / PBR) |
| OPM_TTM | No |
operating_profit_ttm, net_sales_ttm
|
| ROE_TTM | No |
profit_ttm, avg_equity_ttm
|
| asset_turnover_ttm | No |
net_sales_ttm, total_assets
|
| equity_ratio_ttm | No |
avg_equity_ttm, total_assets
|
累計→四半期化(数値例)
| 期 | 累計 Ck | 四半期 qk(計算) | 値 |
|---|---|---|---|
| Q1 | 10 | q1 = C1 | 10 |
| Q2 | 25 | q2 = C2 − C1 | 15 |
| Q3 | 45 | q3 = C3 − C2 | 20 |
| Q4(FY) | 60 | q4 = C4 − C3 | 15 |
TTMのスライド窓(直近4期)
窓 t : [ q1, q2, q3, q4 ] → TTM_t = q1 + q2 + q3 + q4
次の期 : [ q2, q3, q4, q1' ] → TTM_t+1 = q2 + q3 + q4 + q1'
(古いqが抜け、新しいqが入るだけ)
上のように四半期値 q を得たら、各四半期 k の TTM は直近4期の集計で定義します(売上・利益・EPSは合計、自己資本は平均)。分母が0や欠損のときは結果はNaNとします。
- データ前処理
- 主要列を数値化(
errors='coerce')。0は必要に応じてNaNに変換。 - 銘柄・日付でソートしてから日次リターンを算出します。
- 四半期値の整備
-
net_sales,operating_profit,profitは四半期累計(YTD)から差分化し、Qk = CUM(k) − CUM(k−1)。 -
epsはもともと期間値のため差分化せず、そのまま四半期値として扱います。
- TTMの集計
-
net_sales_ttm,operating_profit_ttm,profit_ttm,eps_ttmは直近4期の合計。 -
avg_equity_ttmは直近4期の平均。
- TTM指標
-
opm_ttm=operating_profit_ttm/net_sales_ttm× 100 -
roe_ttm=profit_ttm/avg_equity_ttm× 100 -
per_ttm=close_price/eps_ttm
-
PBR(BPSは前年度FYを使う)
- 原則「前年度FYのBPS」で計算(四半期、FYに当期BPSがない場合)
- FY行に当期のBPSがある場合のみ、その当期BPSを使う
-
その他の指標(TTM)
-
asset_turnover_ttm=net_sales_ttm/total_assets -
equity_ratio_ttm=avg_equity_ttm/total_assets× 100
- 変化率・クリーニング
-
roe_ttm_changeを四半期ごとに.pct_change()で算出。 -
infをNaNに置換。
計算される主な指標(抜粋)
| 指標 | 概要 |
|---|---|
opm_ttm |
直近4期の営業利益率(TTM) |
roe_ttm |
直近4期の自己資本利益率(TTM) |
per_ttm |
株価 ÷ EPS_TTM |
pbr |
原則「前年度FYのBPS」。FY行に当期BPSがあれば当期BPS |
asset_turnover_ttm |
直近4期売上高 ÷ 総資産 |
equity_ratio_ttm |
直近4期平均自己資本 ÷ 総資産 × 100 |
roe_ttm_change |
roe_ttm の四半期ごとの変化率 |
3.4 中間保存
save_batch_data
指標計算まで完了したバッチデータを、読み書きが高速なParquet形式の中間ファイルとして出力します。
Step 4: 全バッチの統合と最終出力
すべてのバッチ処理が完了した後、最終的な統合ファイルを作成します。
-
最終統合 (
combine_all_batches):output/integrated_data/ディレクトリ内にあるすべての中間Parquetファイルをpandas.concatで縦方向に連結し、全銘柄・全期間を網羅した単一のデータフレームを生成します。 -
最終ファイル出力: この巨大なデータフレームを
all_companies_integrated_final.csvとしてCSV形式で出力します。 -
サマリー作成 (
create_final_summary): 最終データから、会計基準別・銘柄別の統計サマリーを生成します。
入出力ファイルパスのルートツリー
financial_analysis_project/
├── ★ complete_financial_analysis_pipeline_excel.py # 実行ファイル
├── ★ J-Quants.env # 認証情報(必須)
├── ★ data_j (1).xlsx # 銘柄リスト(必須)
│
├── output/
│ ├── financial_data_all_standards/
│ │ ├── 1301/
│ │ ├── 1332/
│ │ ├── 1333/
│ │ └── ... (約1,600銘柄分)
│ │
│ └── integrated_data/
│ ├── batch_001.parquet
│ ├── batch_002.parquet
│ ├── batch_003.parquet
│ ├── final_company_summary.csv
│ ├── final_standard_summary.csv
│ └── ★ all_companies_integrated_final.csv # 最終目標ファイル
出力ファイル構成
| ファイルパス | 説明 |
|---|---|
output/financial_data_all_standards/{銘柄コード}/ |
【生データディレクトリ】 各銘柄の取得データが格納される。 |
.../financial_jp.csv など |
会計基準(JP, IFRS, US)別の財務諸表データ。 |
.../daily_prices.csv |
日次株価データ(過去5年分)。 |
output/integrated_data/ |
【処理・統合データディレクトリ】 処理後のデータが格納される。 |
.../batch_XXX.parquet |
バッチ処理後の中間データ。Parquet形式で保存。 |
.../all_companies_integrated_final.csv |
【目的物】 全銘柄の株価と財務指標が統合されたCSVファイル。 |
.../final_standard_summary.csv |
会計基準ごとの企業数やレコード数などの統計サマリー。 |
.../final_company_summary.csv |
銘柄ごとのデータレコード数や平均指標値などの統計サマリー。 |
目的の統合ファイルの例
最初にFYのデータが取得できるまでは、BPSが空のため、計算できない空欄が生じる。
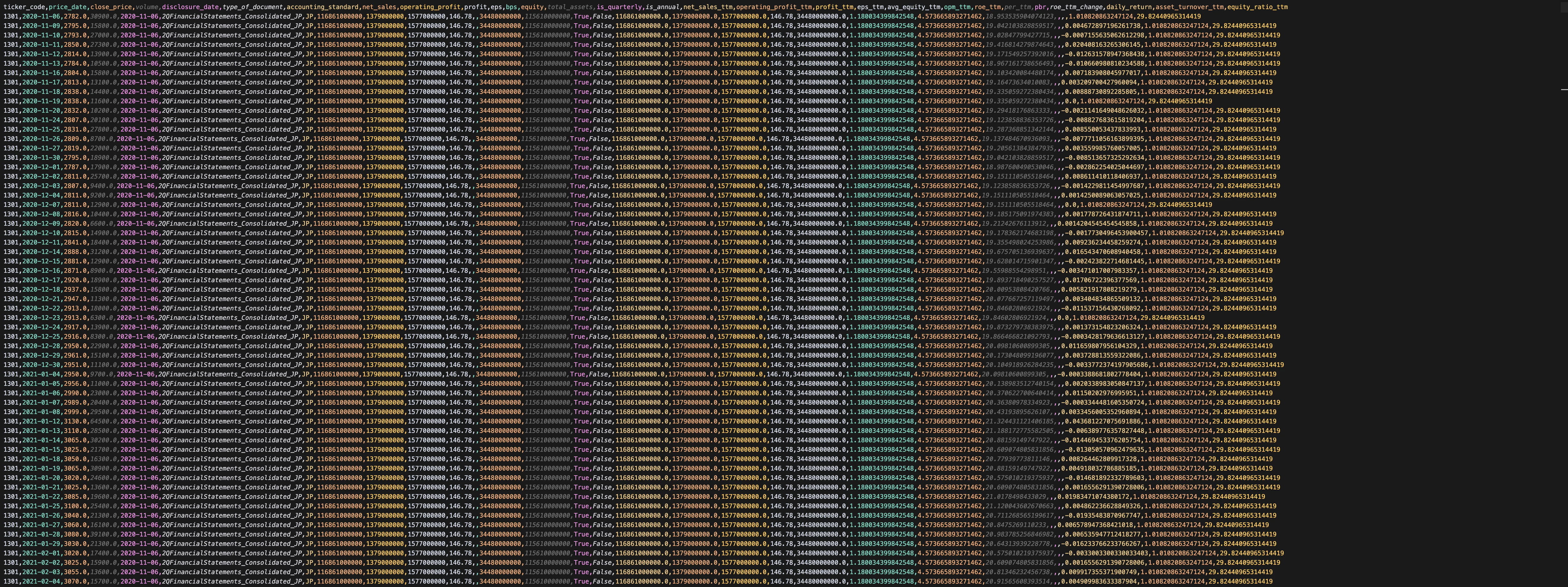
最初のFYデータが取得できた後は、全ての指標が計算されて空欄が埋められる。

実行環境
ハードウェア・OS
- ハードウェア: MacBook Pro 14-inch (Nov 2024)
- プロセッサ: Apple M4 Pro
- メモリ: 24 GB
- OS: macOS Sequoia 15.5
Python環境
- Anaconda: Anaconda3 2024.02-1
- Python: 3.11.7
- conda: 24.11.3
主要ライブラリ
- pandas: 2.3.1
- numpy: 2.2.5
- requests: 2.32.3
- python-dotenv: 1.1.1
- tqdm: 4.67.1
- pyarrow: 20.0.0 (Parquet形式対応)
処理条件
- 対象銘柄数: 約1,600銘柄(東証プライム)
- 取得期間: 過去5年分
- 並列処理: max_workers=10
- バッチサイズ: 200銘柄
実行結果
- 処理時間: 550.14秒(約9分)
- 財務データ: 1635/1639銘柄
- 株価データ: 1635/1639銘柄
- バッチ処理: 9/9バッチ
サンプルコード
import os
import time
import requests
import json
import pandas as pd
import numpy as np
from dotenv import load_dotenv
from tqdm import tqdm
from datetime import datetime, timedelta
import logging
import concurrent.futures
from concurrent.futures import ThreadPoolExecutor, as_completed
# --- 1. 設定 & 認証情報読み込み ---
print("🌀 .envファイルから認証情報を読み込んでいます...")
load_dotenv(dotenv_path='J-Quants.env')
JQUANTS_MAIL = os.getenv("JQUANTS_EMAIL")
JQUANTS_PASS = os.getenv("JQUANTS_PASSWORD")
# ログ設定
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('complete_financial_analysis_pipeline_excel.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class CompleteFinancialAnalysisPipelineExcel:
"""完全な財務分析パイプラインクラス(高速化版・エクセル読み込み対応)"""
def __init__(self, excel_file_path=None):
self.token = None
self.headers = None
self.session = requests.Session()
self.base_dir = "output/financial_data_all_standards"
self.integrated_dir = "output/integrated_data"
self.batch_size = 200 # バッチサイズ
# 絶対パスでエクセルファイルパスを設定
if excel_file_path is None:
# KPCAと同じ絶対パス
self.excel_file_path = "/path/to/data_j.xlsx"
else:
self.excel_file_path = excel_file_path
def get_jquants_token(self):
"""J-QuantsのIDトークンを取得する"""
print("🌀 J-QuantsのIDトークンを取得中...")
try:
# ユーザー認証
auth_data = {"mailaddress": JQUANTS_MAIL, "password": JQUANTS_PASS}
auth_response = self.session.post(
"https://api.jquants.com/v1/token/auth_user",
data=json.dumps(auth_data),
timeout=30
)
auth_response.raise_for_status()
refresh_token = auth_response.json()["refreshToken"]
# IDトークン取得
token_response = self.session.post(
"https://api.jquants.com/v1/token/auth_refresh",
params={"refreshtoken": refresh_token},
timeout=30
)
token_response.raise_for_status()
id_token = token_response.json()["idToken"]
self.token = id_token
self.headers = {"Authorization": f"Bearer {id_token}"}
print("✅ J-QuantsのIDトークン取得完了。")
return True
except Exception as e:
print(f"❌ J-Quantsの認証に失敗しました: {e}")
return False
def get_prime_tickers_from_excel(self):
"""エクセルファイルから東証プライムの銘柄コードを取得(デバッグ用に20銘柄に制限)"""
"""
print("📊 デバッグ用に20銘柄のリストを直接設定中...")
# デバッグ用に20銘柄のリストを直接設定
debug_tickers = [
"1301", "1332", "1333", "1375", "1377", # 住友化学、日本水産、マルハニチロ、昭和電工、フーハイ
"1379", "1414", "1417", "1419", "1429", # ホウスイ、ショーボンド、ミライト・ホールディングス、タマホーム、日本KFCホールディングス
"1433", "1515", "1518", "1605", "1662", # ベステラ、日揮、三井松島産業、国際石油開発帝石、石油資源開発
"1663", "167A", "1719", "1720", "1721" # K&Oエナジーグループ、リバース、安藤・間、住友林業、ミサワホーム
]
print(f"✅ デバッグ用に{len(debug_tickers)}銘柄のリストを設定しました")
return debug_tickers
"""
# 以下はコメントアウト(元のエクセル読み込み処理)
try:
# エクセルファイルの存在確認
if not os.path.exists(self.excel_file_path):
print(f"❌ エクセルファイルが見つかりません: {self.excel_file_path}")
return None
# エクセルファイルを読み込み
df_tickers = pd.read_excel(self.excel_file_path)
# KPCAと同じシンプルな方法でプライム銘柄を抽出
df_tickers = df_tickers[df_tickers["市場・商品区分"] == "プライム(内国株式)"].copy()
df_tickers["ticker_code"] = df_tickers["コード"].astype(str).str.zfill(4)
unique_tickers = df_tickers["ticker_code"].dropna().unique().tolist()
print(f"✅ {len(unique_tickers)}銘柄のリストを取得しました")
return unique_tickers
except Exception as e:
print(f"❌ エクセルファイル読み込みエラー: {e}")
print("📋 エラーの詳細:")
import traceback
traceback.print_exc()
return None
# === Phase 1: 財務データ取得(並列処理) ===
def fetch_financial_data_by_ticker(self, ticker):
"""指定銘柄の全基準財務データを取得"""
try:
# 4桁のtickerコードを5桁に変換(後ろに0を追加)
jquants_code = f"{ticker}0"
url = f"https://api.jquants.com/v1/fins/statements?code={jquants_code}"
response = self.session.get(url, headers=self.headers, timeout=30)
if response.status_code == 200:
data = response.json().get('statements', [])
if data:
# データを整形
df = pd.DataFrame(data)
df['ticker_code'] = ticker
# 基準別に分類
ifrs_data = df[df['TypeOfDocument'].str.contains('IFRS', na=False)]
jp_data = df[df['TypeOfDocument'].str.contains('JP', na=False)]
us_data = df[df['TypeOfDocument'].str.contains('US', na=False)]
# 基準不明のデータ
other_data = df[
~df['TypeOfDocument'].str.contains('IFRS|JP|US', na=False)
]
result = {
'ticker': ticker,
'ifrs': ifrs_data,
'jp': jp_data,
'us': us_data,
'other': other_data,
'all': df
}
return result
else:
return None
else:
return None
except Exception as e:
return None
def fetch_financial_data_parallel(self, tickers, max_workers=10):
"""並列処理で財務データを取得"""
print(f"📊 並列処理で財務データを取得中({max_workers}ワーカー)...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(self.fetch_financial_data_by_ticker, ticker): ticker
for ticker in tickers}
results = {}
for future in tqdm(concurrent.futures.as_completed(futures),
total=len(futures), desc="財務データ並列取得中"):
ticker = futures[future]
try:
result = future.result()
results[ticker] = result
except Exception as e:
print(f"❌ {ticker}: {e}")
results[ticker] = None
return results
def save_financial_data(self, ticker_data, output_dir):
"""財務データを銘柄別に保存"""
try:
ticker = ticker_data['ticker']
ticker_dir = f"{output_dir}/{ticker}"
os.makedirs(ticker_dir, exist_ok=True)
# 基準別にCSV保存
if not ticker_data['ifrs'].empty:
ticker_data['ifrs'].to_csv(f"{ticker_dir}/financial_ifrs.csv", index=False, encoding='utf-8-sig')
if not ticker_data['jp'].empty:
ticker_data['jp'].to_csv(f"{ticker_dir}/financial_jp.csv", index=False, encoding='utf-8-sig')
if not ticker_data['us'].empty:
ticker_data['us'].to_csv(f"{ticker_dir}/financial_us.csv", index=False, encoding='utf-8-sig')
if not ticker_data['other'].empty:
ticker_data['other'].to_csv(f"{ticker_dir}/financial_other.csv", index=False, encoding='utf-8-sig')
# 全データも保存
ticker_data['all'].to_csv(f"{ticker_dir}/financial_all.csv", index=False, encoding='utf-8-sig')
# サマリーファイルを作成
summary = {
'ticker': ticker,
'total_records': len(ticker_data['all']),
'ifrs_records': len(ticker_data['ifrs']),
'jp_records': len(ticker_data['jp']),
'us_records': len(ticker_data['us']),
'other_records': len(ticker_data['other']),
'fetch_date': datetime.now().strftime('%Y-%m-%d %H:%M:%S')
}
summary_df = pd.DataFrame([summary])
summary_df.to_csv(f"{ticker_dir}/financial_summary.csv", index=False, encoding='utf-8-sig')
return True
except Exception as e:
return False
# === Phase 2: 株価データ取得(並列処理) ===
def calculate_date_range(self):
"""過去5年分の日付範囲を計算"""
end_date = datetime.now().date()
start_date = end_date - timedelta(days=5*365) # 5年分
print(f"📅 取得期間: {start_date} ~ {end_date}")
return start_date, end_date
def fetch_daily_prices_by_ticker(self, ticker, start_date, end_date):
"""指定銘柄の過去5年分の株価データを取得"""
try:
# 4桁のtickerコードを5桁に変換(後ろに0を追加)
jquants_code = f"{ticker}0"
# 日付を文字列に変換
start_str = start_date.strftime('%Y-%m-%d')
end_str = end_date.strftime('%Y-%m-%d')
url = f"https://api.jquants.com/v1/prices/daily_quotes?code={jquants_code}&from={start_str}&to={end_str}"
response = self.session.get(url, headers=self.headers, timeout=30)
if response.status_code == 200:
data = response.json()
daily_quotes = data.get('daily_quotes', [])
if daily_quotes:
# データを整形
df = pd.DataFrame(daily_quotes)
df['ticker_code'] = ticker
# 日付をdatetime型に変換
df['Date'] = pd.to_datetime(df['Date'])
# 数値型に変換
numeric_columns = ['Open', 'High', 'Low', 'Close', 'Volume', 'TurnoverValue']
for col in numeric_columns:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
return df
else:
return None
else:
return None
except Exception as e:
return None
def fetch_prices_data_parallel(self, tickers, start_date, end_date, max_workers=10):
"""並列処理で株価データを取得"""
print(f"📈 並列処理で株価データを取得中({max_workers}ワーカー)...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(self.fetch_daily_prices_by_ticker, ticker, start_date, end_date): ticker
for ticker in tickers}
results = {}
for future in tqdm(concurrent.futures.as_completed(futures),
total=len(futures), desc="株価データ並列取得中"):
ticker = futures[future]
try:
result = future.result()
results[ticker] = result
except Exception as e:
print(f"❌ {ticker}: {e}")
results[ticker] = None
return results
def save_prices_data(self, ticker, prices_data, output_dir):
"""株価データを銘柄別に保存"""
try:
ticker_dir = f"{output_dir}/{ticker}"
if prices_data is not None and not prices_data.empty:
# 株価データをCSV保存
prices_data.to_csv(f"{ticker_dir}/daily_prices.csv", index=False, encoding='utf-8-sig')
# サマリーファイルを作成
summary = {
'ticker': ticker,
'total_records': len(prices_data),
'valid_records': prices_data['Close'].notna().sum(),
'start_date': prices_data['Date'].min().strftime('%Y-%m-%d'),
'end_date': prices_data['Date'].max().strftime('%Y-%m-%d'),
'min_price': prices_data['Close'].min(),
'max_price': prices_data['Close'].max(),
'avg_price': prices_data['Close'].mean(),
'fetch_date': datetime.now().strftime('%Y-%m-%d %H:%M:%S')
}
summary_df = pd.DataFrame([summary])
summary_df.to_csv(f"{ticker_dir}/prices_summary.csv", index=False, encoding='utf-8-sig')
return True
else:
return False
except Exception as e:
return False
# === Phase 3: バッチ処理(200銘柄ずつ) ===
def create_ticker_batches(self, tickers):
"""銘柄リストを200銘柄ずつのバッチに分割"""
batches = []
for i in range(0, len(tickers), self.batch_size):
batch = tickers[i:i + self.batch_size]
batches.append(batch)
return batches
def load_batch_financial_data(self, ticker_batch):
"""バッチ内の銘柄の財務データを一括読み込み"""
print(f" 📊 財務データ一括読み込み中...")
batch_financial = {}
for ticker in ticker_batch:
ticker_dir = os.path.join(self.base_dir, ticker)
# IFRS基準を優先
ifrs_file = os.path.join(ticker_dir, "financial_ifrs.csv")
jp_file = os.path.join(ticker_dir, "financial_jp.csv")
us_file = os.path.join(ticker_dir, "financial_us.csv")
if os.path.exists(ifrs_file):
df = pd.read_csv(ifrs_file)
standard = 'IFRS'
elif os.path.exists(jp_file):
df = pd.read_csv(jp_file)
standard = 'JP'
elif os.path.exists(us_file):
df = pd.read_csv(us_file)
standard = 'US'
else:
continue
df['accounting_standard'] = standard
batch_financial[ticker] = df
print(f" ✅ {len(batch_financial)}銘柄の財務データ読み込み完了")
return batch_financial
def load_batch_prices_data(self, ticker_batch):
"""バッチ内の銘柄の株価データを一括読み込み"""
print(f" 📈 株価データ一括読み込み中...")
batch_prices = {}
for ticker in ticker_batch:
ticker_dir = os.path.join(self.base_dir, ticker)
prices_file = os.path.join(ticker_dir, "daily_prices.csv")
if os.path.exists(prices_file):
df = pd.read_csv(prices_file)
df['Date'] = pd.to_datetime(df['Date'])
df = df.sort_values('Date')
batch_prices[ticker] = df
print(f" ✅ {len(batch_prices)}銘柄の株価データ読み込み完了")
return batch_prices
def merge_batch_data(self, batch_financial, batch_prices):
"""バッチ内の財務データと株価データを一括統合"""
print(f" 🔗 データ一括統合中...")
all_merged_data = []
for ticker in batch_financial.keys():
if ticker not in batch_prices:
continue
df_financial = batch_financial[ticker]
df_prices = batch_prices[ticker]
# 日付で昇順ソート(安定な時系列処理のため)
df_prices = df_prices.sort_values('Date')
# 財務データの前処理
df_financial['DisclosedDate'] = pd.to_datetime(df_financial['DisclosedDate'])
# 必要なカラムの変換
required_columns = {
'NetSales': 'net_sales',
'OperatingProfit': 'operating_profit',
'Profit': 'profit',
'EarningsPerShare': 'eps',
'BookValuePerShare': 'bps',
'Equity': 'equity',
'TotalAssets': 'total_assets'
}
for old_name, new_name in required_columns.items():
if old_name in df_financial.columns:
df_financial[new_name] = pd.to_numeric(df_financial[old_name], errors='coerce')
# 書類タイプの分類
df_financial['is_quarterly'] = df_financial['TypeOfDocument'].str.contains('1Q|2Q|3Q', na=False)
df_financial['is_annual'] = df_financial['TypeOfDocument'].str.contains('FY|Annual', na=False)
# ソート(日付順)
df_financial = df_financial.sort_values('DisclosedDate')
# 株価データの各日付に対して、その日付以前の直近の財務データを参照
for _, price_row in df_prices.iterrows():
current_date = price_row['Date']
# その日付以前の直近の財務データを取得
available_financial = df_financial[df_financial['DisclosedDate'] <= current_date]
if not available_financial.empty:
# 最新の財務データを選択
latest_financial = available_financial.iloc[-1]
# 統合データを作成
merged_row = {
'ticker_code': ticker,
'price_date': current_date,
'close_price': price_row['Close'],
'volume': price_row['Volume'],
'disclosure_date': latest_financial['DisclosedDate'],
'type_of_document': latest_financial['TypeOfDocument'],
'accounting_standard': latest_financial['accounting_standard'],
'net_sales': latest_financial.get('net_sales'),
'operating_profit': latest_financial.get('operating_profit'),
'profit': latest_financial.get('profit'),
'eps': latest_financial.get('eps'),
'bps': latest_financial.get('bps'),
'equity': latest_financial.get('equity'),
'total_assets': latest_financial.get('total_assets'),
'is_quarterly': latest_financial.get('is_quarterly'),
'is_annual': latest_financial.get('is_annual')
}
all_merged_data.append(merged_row)
if all_merged_data:
df_merged = pd.DataFrame(all_merged_data)
print(f" ✅ 統合完了: {len(df_merged)}件")
return df_merged
else:
print(f" ⚠️ 統合データなし")
return None
def calculate_batch_metrics(self, df_merged):
"""バッチ内の財務指標を一括計算(最終修正版)"""
print(f" 🧮 財務指標一括計算中...")
if df_merged is None or df_merged.empty:
return None
# 数値型に変換(ゼロ除算を防ぐため、0をNaNに変換)
numeric_columns = ['close_price', 'net_sales', 'operating_profit', 'profit', 'eps', 'bps', 'equity', 'total_assets']
for col in numeric_columns:
if col in df_merged.columns:
df_merged[col] = pd.to_numeric(df_merged[col], errors='coerce')
# 0をNaNに変換(ゼロ除算を防ぐ)
if col in ['net_sales', 'operating_profit', 'profit', 'eps', 'bps', 'equity']:
df_merged[col] = df_merged[col].replace(0, np.nan)
# === TTMベースの財務指標のみ計算 ===
# 単一期間の指標は計算せず、TTMベースの指標のみに統一
print(f" 📊 TTMベースの財務指標のみ計算中...")
# === TTM 指標の計算 ===
try:
# TTM計算の元となる四半期データを抽出(重複排除)
period = (
df_merged[['ticker_code', 'disclosure_date', 'type_of_document',
'net_sales', 'operating_profit', 'profit', 'eps', 'equity']]
.drop_duplicates()
.sort_values(['ticker_code', 'disclosure_date'])
.reset_index(drop=True)
)
# --- 四半期単独の値を正確に算出(修正版) ---
# 注意: EPS はもともと期間値である可能性が高いため、累計差分は行わずそのまま使用
for metric in ['net_sales', 'operating_profit', 'profit', 'eps']:
# 各銘柄ごとに処理
for ticker in period['ticker_code'].unique():
ticker_data = period[period['ticker_code'] == ticker].copy()
ticker_data = ticker_data.sort_values('disclosure_date')
ticker_data = ticker_data.reset_index(drop=True)
ticker_data[f'{metric}_q'] = ticker_data[metric]
# EPS 以外の指標は累計から差分を取って四半期値化
if metric != 'eps':
# 1Qの場合は累計値をそのまま使用
is_1q = ticker_data['type_of_document'].str.contains('1Q', na=False)
# 2Q以降は累計値から前四半期を引く
for i in range(1, len(ticker_data)):
if not is_1q.iloc[i]: # 1Q以外の場合
prev_value = ticker_data[metric].iloc[i-1]
curr_value = ticker_data[metric].iloc[i]
if pd.notna(prev_value) and pd.notna(curr_value):
ticker_data.loc[i, f'{metric}_q'] = curr_value - prev_value
# 元のデータフレームに反映
period.loc[period['ticker_code'] == ticker, f'{metric}_q'] = ticker_data[f'{metric}_q'].values
# === TTM計算(優先順位付き) ===
# 最優先: 直近4四半期の合計
# 第2優先: 前年FYの年間値
# 第3優先: 利用可能な四半期データの合計(4未満でも)
# 最後: NaN(データ不足)
for metric in ['net_sales', 'operating_profit', 'profit', 'eps']:
# 1. 最優先: 直近4四半期の合計
period[f'{metric}_ttm'] = period.groupby('ticker_code')[f'{metric}_q'].rolling(
4, min_periods=4
).sum().reset_index(level=0, drop=True)
# 2. フォールバック処理(TTMがNaNの場合)
for ticker in period['ticker_code'].unique():
ticker_data = period[period['ticker_code'] == ticker].copy()
missing_ttm = ticker_data[f'{metric}_ttm'].isna()
if missing_ttm.any():
# 第2優先: 前年FYデータを検索
prev_fy_data = ticker_data[
(ticker_data['type_of_document'].str.contains('FY|Annual', na=False)) &
(ticker_data['disclosure_date'] < ticker_data.loc[missing_ttm, 'disclosure_date'].min())
]
if not prev_fy_data.empty:
# 最新の前年FYデータを使用
latest_prev_fy = prev_fy_data.loc[prev_fy_data['disclosure_date'].idxmax()]
# TTMがNaNの行に前年FY値を設定
period.loc[
(period['ticker_code'] == ticker) &
(period[f'{metric}_ttm'].isna()),
f'{metric}_ttm'
] = latest_prev_fy[metric]
else:
# 第3優先: 利用可能な四半期データの合計(4未満でも)
for idx in ticker_data[missing_ttm].index:
# その時点で利用可能な四半期データを取得
available_data = ticker_data[
(ticker_data['disclosure_date'] <= ticker_data.loc[idx, 'disclosure_date']) &
(ticker_data[f'{metric}_q'].notna())
]
if len(available_data) > 0:
# 利用可能なデータの合計
period.loc[idx, f'{metric}_ttm'] = available_data[f'{metric}_q'].sum()
# 自己資本は平均値なので、同様の処理
period['avg_equity_ttm'] = period.groupby('ticker_code')['equity'].rolling(
4, min_periods=4
).mean().reset_index(level=0, drop=True)
# 自己資本のフォールバック処理
for ticker in period['ticker_code'].unique():
ticker_data = period[period['ticker_code'] == ticker].copy()
missing_equity = ticker_data['avg_equity_ttm'].isna()
if missing_equity.any():
# 前年FYデータを検索
prev_fy_data = ticker_data[
(ticker_data['type_of_document'].str.contains('FY|Annual', na=False)) &
(ticker_data['disclosure_date'] < ticker_data.loc[missing_equity, 'disclosure_date'].min())
]
if not prev_fy_data.empty:
latest_prev_fy = prev_fy_data.loc[prev_fy_data['disclosure_date'].idxmax()]
period.loc[
(period['ticker_code'] == ticker) &
(period['avg_equity_ttm'].isna()),
'avg_equity_ttm'
] = latest_prev_fy['equity']
else:
# 利用可能なデータの平均
for idx in ticker_data[missing_equity].index:
available_data = ticker_data[
(ticker_data['disclosure_date'] <= ticker_data.loc[idx, 'disclosure_date']) &
(ticker_data['equity'].notna())
]
if len(available_data) > 0:
period.loc[idx, 'avg_equity_ttm'] = available_data['equity'].mean()
# TTMベースの指標を計算(ゼロ除算を防ぐ)
period['opm_ttm'] = np.where(
(period['net_sales_ttm'] > 0) & (period['operating_profit_ttm'].notna()),
(period['operating_profit_ttm'] / period['net_sales_ttm']) * 100,
np.nan
)
period['roe_ttm'] = np.where(
(period['avg_equity_ttm'] > 0) & (period['profit_ttm'].notna()),
(period['profit_ttm'] / period['avg_equity_ttm']) * 100,
np.nan
)
# 計算したTTMの値を日次データにマージ
df_merged = df_merged.merge(
period[['ticker_code', 'disclosure_date', 'net_sales_ttm', 'operating_profit_ttm',
'profit_ttm', 'eps_ttm', 'avg_equity_ttm', 'opm_ttm', 'roe_ttm']],
on=['ticker_code', 'disclosure_date'],
how='left'
)
except Exception as e:
logger.warning(f"TTM基本計算でエラーが発生しました: {e}")
for col in ['net_sales_ttm', 'operating_profit_ttm', 'profit_ttm', 'eps_ttm', 'avg_equity_ttm', 'opm_ttm', 'roe_ttm']:
df_merged[col] = np.nan
# --- PER/ROE変化率とその他の指標 ---
# PER TTMの計算
try:
df_merged['per_ttm'] = np.where(df_merged['eps_ttm'] > 0, df_merged['close_price'] / df_merged['eps_ttm'], np.nan)
except Exception:
df_merged['per_ttm'] = np.nan
# PBR(FY参照ロジック)
try:
df_merged['pbr'] = self.calculate_pbr_with_fy_reference(df_merged)
except Exception:
df_merged['pbr'] = np.nan
# ROE TTM変化率(四半期ごと)の計算
try:
quarterly_data = (
df_merged[['ticker_code', 'disclosure_date', 'roe_ttm']]
.dropna(subset=['roe_ttm'])
.drop_duplicates()
.sort_values(['ticker_code', 'disclosure_date'])
)
quarterly_data['roe_ttm_change'] = quarterly_data.groupby('ticker_code')['roe_ttm'].pct_change()
if 'roe_ttm_change' in df_merged.columns:
df_merged = df_merged.drop(columns=['roe_ttm_change'])
df_merged = df_merged.merge(
quarterly_data[['ticker_code', 'disclosure_date', 'roe_ttm_change']],
on=['ticker_code', 'disclosure_date'],
how='left'
)
except Exception:
df_merged['roe_ttm_change'] = np.nan
# 日次リターンを計算し、冗長な列を整理
df_merged = df_merged.sort_values(['ticker_code', 'price_date'])
df_merged['daily_return'] = df_merged.groupby('ticker_code')['close_price'].pct_change()
df_merged = df_merged.drop(columns=['per_ttm_change', 'pbr_change'], errors='ignore')
# === その他の指標(TTMベースのみ) ===
try:
# 総資産回転率(TTM)
df_merged['asset_turnover_ttm'] = np.where(
(df_merged['total_assets'] > 0) & (df_merged['net_sales_ttm'].notna()),
df_merged['net_sales_ttm'] / df_merged['total_assets'],
np.nan
)
# 自己資本比率(TTM)
df_merged['equity_ratio_ttm'] = np.where(
(df_merged['total_assets'] > 0) & (df_merged['avg_equity_ttm'].notna()),
(df_merged['avg_equity_ttm'] / df_merged['total_assets']) * 100,
np.nan
)
except Exception as e:
print(f" ⚠️ その他指標計算エラー: {e}")
for col in ['asset_turnover_ttm', 'equity_ratio_ttm']:
df_merged[col] = np.nan
# 無限大・NaN値を処理
df_merged = df_merged.replace([np.inf, -np.inf], np.nan)
print(f" ✅ 指標計算完了")
return df_merged
def calculate_pbr_with_fy_reference(self, df_merged):
"""
PBR計算(4Q以外は直近FYデータを参照)
Args:
df_merged: 統合されたデータフレーム
Returns:
PBRの計算結果(Series)
"""
try:
# 必要列の存在チェックと補助列の作成
df = df_merged.copy()
if 'disclosure_date' in df.columns:
df = df.sort_values(['ticker_code', 'disclosure_date'])
elif 'price_date' in df.columns:
df = df.sort_values(['ticker_code', 'price_date'])
# 年次判定の補助列(is_annual が無ければ type_of_document で代替)
if 'is_annual' not in df.columns:
df['is_annual'] = df.get('type_of_document', pd.Series(index=df.index)).astype(str).str.contains('FY|Annual', na=False)
# 直近FYのBPSを前方埋め
df['fy_bps_only'] = np.where(df['is_annual'], df['bps'], np.nan)
df['prev_fy_bps'] = df.groupby('ticker_code')['fy_bps_only'].ffill()
# 四半期判定の補助列
if 'is_quarterly' not in df.columns:
df['is_quarterly'] = df.get('type_of_document', pd.Series(index=df.index)).astype(str).str.contains('1Q|2Q|3Q', na=False)
# PBR: 1-3Qは直近FYのBPS、FY行でbpsがNaNのときも直近FYのBPSでフォールバック
use_prev_fy_bps = (
(df['is_quarterly']) |
(df['is_annual'] & df['bps'].isna())
) & pd.notna(df['prev_fy_bps']) & (df['prev_fy_bps'] > 0)
pbr = np.where(
use_prev_fy_bps,
df['close_price'] / df['prev_fy_bps'],
np.where(pd.notna(df['bps']) & (df['bps'] > 0), df['close_price'] / df['bps'], np.nan)
)
# 元の行順に合わせた Series を返す
pbr_series = pd.Series(pbr, index=df.index)
pbr_series = pbr_series.reindex(df_merged.index)
return pbr_series
except Exception as e:
print(f" ⚠️ PBR計算エラー: {e}")
# エラー時は通常の計算にフォールバック
return df_merged['close_price'] / df_merged['bps']
def save_batch_data(self, df_batch, batch_num):
"""バッチデータを保存"""
try:
if df_batch is None or df_batch.empty:
return False
# 出力ディレクトリ作成
os.makedirs(self.integrated_dir, exist_ok=True)
# バッチファイルを保存
batch_file = os.path.join(self.integrated_dir, f"batch_{batch_num:03d}.parquet")
df_batch.to_parquet(batch_file, index=False)
print(f" 💾 バッチデータ保存: {batch_file} ({len(df_batch):,}件)")
return True
except Exception as e:
print(f" ❌ バッチ保存エラー: {e}")
return False
def process_batch(self, ticker_batch, batch_num):
"""1バッチ(200銘柄)の処理"""
try:
print(f"\n🔄 バッチ {batch_num} 処理開始 ({len(ticker_batch)}銘柄)")
# 1. 200銘柄分のデータを一括読み込み
batch_financial = self.load_batch_financial_data(ticker_batch)
batch_prices = self.load_batch_prices_data(ticker_batch)
if not batch_financial or not batch_prices:
print(f" ❌ バッチ {batch_num}: データ読み込み失敗")
return False
# 2. 200銘柄分を一括統合
batch_merged = self.merge_batch_data(batch_financial, batch_prices)
if batch_merged is None:
print(f" ❌ バッチ {batch_num}: 統合失敗")
return False
# 3. 200銘柄分の財務指標を一括計算
batch_with_metrics = self.calculate_batch_metrics(batch_merged)
if batch_with_metrics is None:
print(f" ❌ バッチ {batch_num}: 指標計算失敗")
return False
# 4. 200銘柄分を一括保存
success = self.save_batch_data(batch_with_metrics, batch_num)
return success
except Exception as e:
print(f"❌ バッチ {batch_num} の処理エラー: {e}")
return False
# === Phase 4: 全バッチ統合 ===
def combine_all_batches(self):
"""全バッチファイルを結合して最終統合ファイルを作成"""
try:
print("\n🚀 全バッチファイルの最終統合開始")
# バッチファイル一覧取得
batch_files = [f for f in os.listdir(self.integrated_dir)
if f.startswith("batch_") and f.endswith(".parquet")]
batch_files.sort()
if not batch_files:
print("❌ バッチファイルが見つかりません")
return False
print(f"📋 統合対象バッチファイル: {len(batch_files)}個")
# 全バッチデータを結合
all_batch_data = []
total_records = 0
for batch_file in tqdm(batch_files, desc="バッチファイル統合中"):
batch_path = os.path.join(self.integrated_dir, batch_file)
try:
df_batch = pd.read_parquet(batch_path)
all_batch_data.append(df_batch)
total_records += len(df_batch)
print(f" ✅ {batch_file}: {len(df_batch):,}件")
except Exception as e:
print(f" ❌ {batch_file} 読み込み失敗: {e}")
if all_batch_data:
# 全データを結合
final_integrated_data = pd.concat(all_batch_data, ignore_index=True)
# 最終統合ファイルを保存
final_output_file = os.path.join(self.integrated_dir, "all_companies_integrated_final.csv")
final_integrated_data.to_csv(final_output_file, index=False, encoding='utf-8-sig')
print(f"\n🎉 全バッチ統合完了!")
print(f" 総件数: {len(final_integrated_data):,}件")
print(f" 銘柄数: {final_integrated_data['ticker_code'].nunique()}銘柄")
# 日付をdatetime型に変換してから処理
final_integrated_data['price_date'] = pd.to_datetime(final_integrated_data['price_date'])
print(f" 期間: {final_integrated_data['price_date'].min().date()} ~ {final_integrated_data['price_date'].max().date()}")
print(f" 出力先: {final_output_file}")
# 最終サマリーを作成
self.create_final_summary(final_integrated_data)
return True
else:
print("❌ 統合データがありません")
return False
except Exception as e:
print(f"❌ 全バッチ統合エラー: {e}")
logger.error(f"全バッチ統合エラー: {e}")
return False
def create_final_summary(self, final_data):
"""最終統合データのサマリーを作成"""
try:
print("\n📋 最終統合データのサマリーを作成中...")
# 基準別の統計
standard_stats = final_data.groupby('accounting_standard').agg({
'ticker_code': 'nunique',
'price_date': 'count'
}).rename(columns={'ticker_code': 'company_count', 'price_date': 'total_records'})
# 銘柄別の統計
company_stats = final_data.groupby('ticker_code').agg({
'price_date': 'count',
'roe_ttm': 'mean',
'per_ttm': 'mean',
'opm_ttm': 'mean',
'pbr': 'mean'
}).rename(columns={'price_date': 'daily_records'})
# サマリーファイルを保存
standard_stats.to_csv(os.path.join(self.integrated_dir, "final_standard_summary.csv"), encoding='utf-8-sig')
company_stats.to_csv(os.path.join(self.integrated_dir, "final_company_summary.csv"), encoding='utf-8-sig')
print("✅ 最終サマリー作成完了")
except Exception as e:
print(f"❌ 最終サマリー作成エラー: {e}")
# === メイン実行 ===
def run_complete_pipeline(self):
"""完全なパイプラインを実行"""
try:
print("🚀 完全な財務分析パイプライン(高速化版・エクセル読み込み対応)開始")
start_time = datetime.now()
# 1. 認証
if not self.get_jquants_token():
return
# 2. エクセルファイルから銘柄リスト取得
tickers = self.get_prime_tickers_from_excel()
if not tickers:
print("❌ 銘柄リストが取得できませんでした")
return
# 3. 出力ディレクトリ作成
os.makedirs(self.base_dir, exist_ok=True)
print(f"📁 出力ディレクトリ: {self.base_dir}")
# === Phase 1: 財務データ取得(並列処理) ===
print(f"\n📊 Phase 1: 財務データ並列取得開始 ({len(tickers)}銘柄)")
all_financial_data = self.fetch_financial_data_parallel(tickers, max_workers=10)
# 財務データを保存
financial_success = 0
for ticker, ticker_data in all_financial_data.items():
if ticker_data:
if self.save_financial_data(ticker_data, self.base_dir):
financial_success += 1
print(f"✅ Phase 1 完了: {financial_success}/{len(tickers)}銘柄")
# === Phase 2: 株価データ取得(並列処理) ===
print(f"\n📈 Phase 2: 株価データ並列取得開始 ({len(tickers)}銘柄)")
start_date, end_date = self.calculate_date_range()
all_prices_data = self.fetch_prices_data_parallel(tickers, start_date, end_date, max_workers=10)
# 株価データを保存
prices_success = 0
for ticker, prices_data in all_prices_data.items():
if prices_data is not None:
if self.save_prices_data(ticker, prices_data, self.base_dir):
prices_success += 1
print(f"✅ Phase 2 完了: {prices_success}/{len(tickers)}銘柄")
# === Phase 3: バッチ処理(200銘柄ずつ) ===
print(f"\n🔄 Phase 3: バッチ処理開始 ({self.batch_size}銘柄ずつ)")
# バッチ分割
ticker_batches = self.create_ticker_batches(tickers)
print(f"📋 バッチ数: {len(ticker_batches)}(各{self.batch_size}銘柄)")
# 各バッチを処理
batch_success = 0
for batch_num, ticker_batch in enumerate(ticker_batches, 1):
success = self.process_batch(ticker_batch, batch_num)
if success:
batch_success += 1
# 進捗表示
progress = (batch_num / len(ticker_batches)) * 100
print(f"📊 バッチ処理進捗: {progress:.1f}%")
print(f"✅ Phase 3 完了: {batch_success}/{len(ticker_batches)}バッチ")
# === Phase 4: 全バッチ統合 ===
print(f"\n🚀 Phase 4: 全バッチ統合開始")
integration_success = self.combine_all_batches()
# 完了
end_time = datetime.now()
duration = (end_time - start_time).total_seconds()
print(f"\n🎉 完全なパイプライン完了!")
print(f" 処理時間: {duration:.2f}秒")
print(f" 財務データ: {financial_success}/{len(tickers)}銘柄")
print(f" 株価データ: {prices_success}/{len(tickers)}銘柄")
print(f" バッチ処理: {batch_success}/{len(ticker_batches)}バッチ")
print(f" 最終統合: {'成功' if integration_success else '失敗'}")
print(f" 出力先: {self.base_dir} + {self.integrated_dir}")
except Exception as e:
print(f"❌ パイプライン実行エラー: {e}")
logger.error(f"パイプライン実行エラー: {e}")
def main():
"""メイン実行"""
# デフォルトはNone(クラス内で絶対パスを使用)
excel_file_path = None
# カスタムファイルパスが指定されている場合
if len(os.sys.argv) > 1:
excel_file_path = os.sys.argv[1]
print(f"📁 指定されたエクセルファイル: {excel_file_path}")
pipeline = CompleteFinancialAnalysisPipelineExcel(excel_file_path)
pipeline.run_complete_pipeline()
if __name__ == "__main__":
main()
注意事項
- API制限: APIに短時間に大量のリクエストを行うと、一時的にアクセスが制限される可能性があります。なお、J-Quantsの場合は、timesleepを0秒にして、並列取得をしても制限されることは今のところ確認していません。
- メモリ使用量: バッチサイズはシステムのメモリ容量に応じて調整が必要です。デフォルトの200より大幅に増やすと、メモリ不足(MemoryError)が発生する可能性があります。
- データ品質: APIから取得するデータの完全性は、データ提供元に依存します。一部の銘柄でデータが欠損している、または取得できない場合がありますが、その場合でもパイプラインは該当銘柄をスキップして処理を継続します。エラーの詳細はログファイルで確認できます。
-
環境変数ファイル: 認証情報は
J-Quants.envファイルに格納する必要があります。ファイル名と内容が正しく設定されていることを確認してください。
Q&A
-
Q. API 制限に引っかかったら?
A.max_workersを 5 などへ下げ、リトライ間隔 (time.sleep) を挟むと改善します。 -
Q. バッチサイズを増やせる?
A. 200 までは 24 GB RAM で検証済ですが、Parquet 書き込み速度が低下します。
まとめ
J-Quants APIを活用して東証プライム約1600銘柄の財務・株価データを取得・統合して、財務データセットを構築する方法を紹介しました。
活用方法
- 機械学習の教師データ: 時系列財務指標と株価データの組み合わせで予測モデルを構築
- ファンダメンタル分析: 長期的な財務指標の変化と株価の相関を分析
- スクリーニング基盤: 定期的な財務指標の更新と銘柄選定の自動化
今後の発展
次回は、今回構築した財務データセットを使った財務スクリーニングの方法を紹介します。