はじめに
Googleの音声認識APIサービスであるCloud Speech-to-Textでは、Python向けだと以下の2種類のライブラリ、4種類のメソッドが公式から提供されています。
Speech-to-Text v1
・recognize()
・longrunningrecognize()
Speech-to-Text Client Libraries
・recognize()
・long_running_recognize()
いずれも音声データを読み込ませると、認識結果のテキスト(transcript)、結果の信頼度(confidence:0〜1の間)が返ってくるものですが、それぞれの違いを体系的に整理している記事が公式含めなかなか見当たらなかったので、実際に使い比べて整理してみました。
前提
- Google Cloud Platformを利用します。
- Bash環境およびPython環境を利用します。
- 今回はAmazon Linux AMI release 2018.03 と Python 3.6.7 を利用しました。
1.Speech-to-Text v1 を利用した方法
- Cloud Speech-to-Text の基本で公開されている方法です。
-
google-api-python-clientパッケージを利用します - 1分未満の音声ファイルには
recognize()メソッドを利用して同期的に音声認識を行います。 - 1分以上の音声ファイルには
longrunningrecognize()メソッドを利用して非同期的に音声認識を行います。 - 1分未満の音声ファイルはローカルまたはGoogle Cloud Storageのいずれかに配置します。
- 1分以上の音声ファイルはGoogle Cloud Storageに配置する必要があります。
- 正式版として提供されている方法となります。
Speech-to-Text v1 は正式にリリースされており、https://speech.googleapis.com/v1/speech エンドポイントから一般向けに提供されています。
以下は、Google Cloud Storageに配置した音声ファイルを音声認識させて結果を出力するサンプルプログラムを作成する手順となります。
※この手順では音声認識させる音声ファイルをGoogle Cloud Storage上で一般公開状態に設定します。検証する場合は公開されても問題のない音声ファイルを利用してください。
Google Cloud Platformの準備
まだの場合はGoogle Cloud Platformのアカウントを登録します。
無料トライアルもあるので活用しましょう。
アカウント登録が済んだら、リソースの管理ページから新規プロジェクトを作成します。
以降は作成したプロジェクトに対して設定を行っていきます。
API ライブラリでCloud Speech-to-Text APIを有効にします。
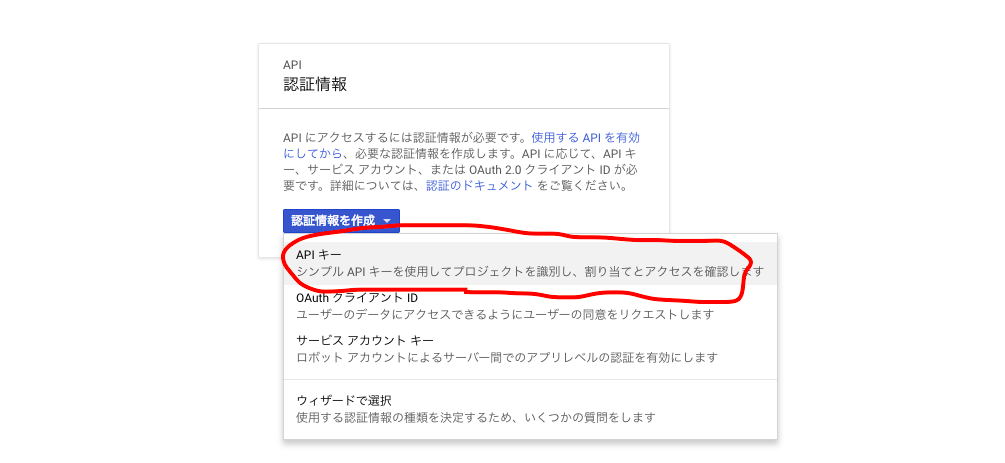
認証情報ページで新しいAPIキーを作成します。
キーの値が表示されるので控えておきます。
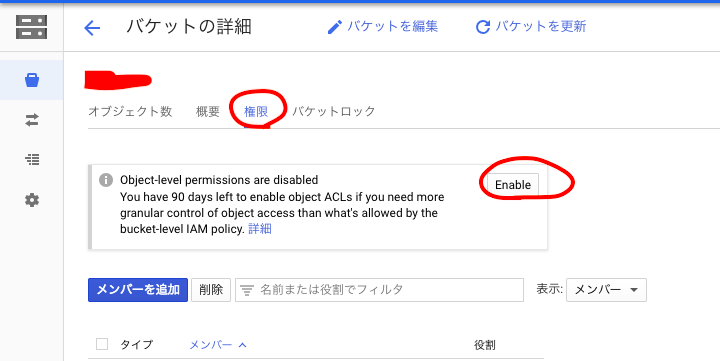
Google Cloud Storageで新しいバケットを作成します。
作成したバケットで、[バケットの詳細]-[権限]に[Enable]ボタンが表示されている場合はクリックしてACLを有効化しておきます。
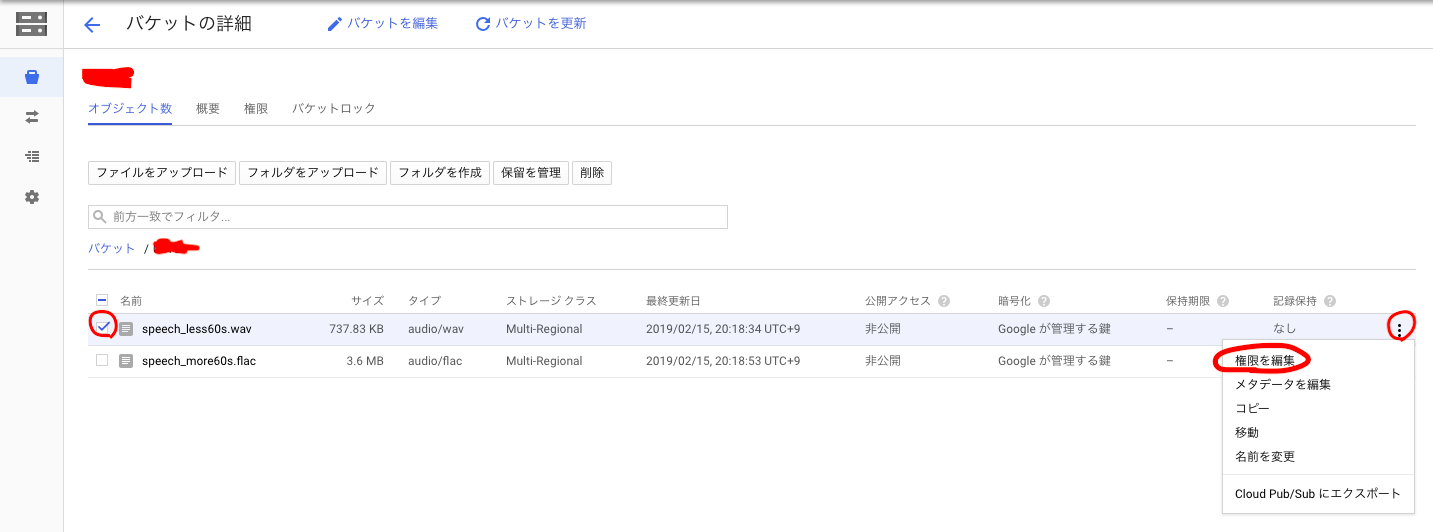
音声認識を行いたいFLACまたはWAV形式のファイルをバケットにアップロードします。再生時間に応じて処理時間も大きくなるので、まずは1分前後の短いデータで試しましょう。
またこのときアップロードしたファイルにアクセスを設定し、一般公開しておきます。(URLが分かれば認証なしで誰でもアクセスできる状態)
ファイルを選択して[権限を編集]をクリック。
「AllUsers」を「読み取り」アクセス権で追加したら[保存]をクリック。
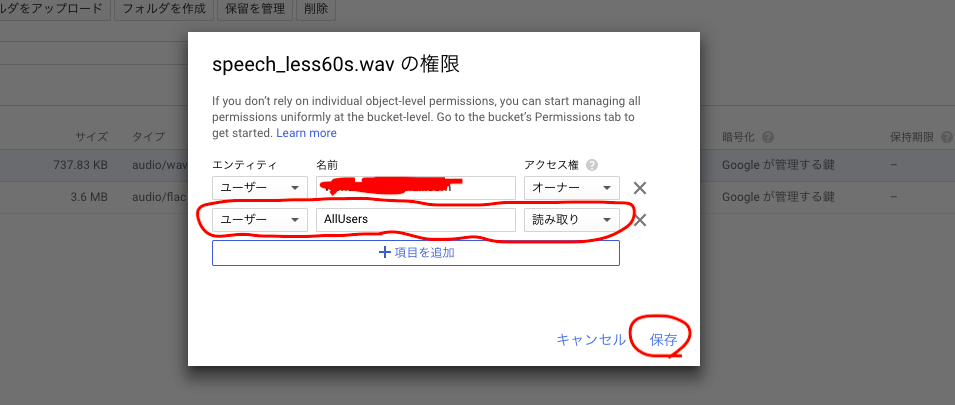
一般公開設定になりました。

Python環境の準備
Bash環境のプロジェクトフォルダ内で作業を行っていきます。
Pythonパッケージをインストール。
$ cat << EOF > requirements.txt
google-api-python-client #Speech-to-Text v1のパッケージ
requests #Google Cloud Storageおよびオペレーションエンドポイントへのリクエスト用
python-magic #音声ファイルmime判定用
pydub #WAVファイル情報取得用
mutagen #FLACファイル情報取得用
EOF
$ pip install -r requirements.txt -t .
以下のスクリプトを作成。
スクリプト内のYourAPIKeyに先程控えたAPIキー値、YourBucketNameに先程作成したバケット名を書き込んで、bucketname変数とkey変数で使えるようにします。
# coding:utf8
import sys
import json
import httplib2
from googleapiclient import discovery
from mutagen.flac import FLAC
from pydub import AudioSegment
import magic
import requests
import time
key = 'YourAPIKey'
filename = sys.argv[1]
bucketname = 'YourBucketName'
# GCSから音声データダウンロード
uri = 'https://storage.googleapis.com/' + bucketname + '/' + filename
r = requests.get(uri)
# ダウンロード結果チェック
if r.status_code != 200:
print('Request to {0} returned {1} error.'.format(uri,r.status_code))
sys.exit()
# ダウンロードした音声データからencoding、rate、lengthの情報を取得
mime = magic.Magic(mime=True).from_buffer(r.content)
if mime == 'audio/x-wav' and '.wav' in filename.lower():
encoding = 'LINEAR16'
sound = AudioSegment(r.content)
if sound.channels != 1:
print('Must use single channel (mono) audio')
sys.exit()
rate = sound.frame_rate
length = sound.duration_seconds
elif mime == 'audio/x-flac' and '.flac' in filename.lower():
encoding = 'FLAC'
filepath = '/tmp/' + filename
with open(filepath, 'wb') as f:
f.write(r.content)
f.close()
sound = FLAC(filepath).info
if sound.channels != 1:
print('Must use single channel (mono) audio')
sys.exit()
rate = sound.sample_rate
length = sound.length
else:
print('Acceptable type is only "wav" or "flac".')
sys.exit()
print('\n-*- audio info -*-')
print('filename : ' + filename)
print('mimetype : ' + mime)
print('sampleRate : ' + str(rate))
print('playtime : ' + str(length) + 's')
# リクエスト作成準備
service = discovery.build(
'speech',
'v1',
http=httplib2.Http(),
discoveryServiceUrl='https://{api}.googleapis.com/$discovery/rest?version={apiVersion}',
developerKey=key,
cache_discovery=False
)
# リクエストボディ定義
body={
'config': {
'encoding': encoding,
'sampleRateHertz': rate,
'languageCode': 'ja-JP'
},
'audio': {
'uri': 'gs://' + bucketname + '/' + filename
}
}
if length < 60:
# 再生時間が1分未満の場合
#サービスリクエスト作成
service_request = service.speech().recognize(body=body)
#サービスリクエスト実行、実行結果パース
results = (service_request.execute())["results"]
else:
# 再生時間が1分以上の場合
#サービスリクエスト作成
service_request = service.speech().longrunningrecognize(body=body)
#サービスリクエスト実行、オペレーション名パース
operation_name = (service_request.execute())['name']
#オペレーションエンドポイント定義
endpointUri = 'https://speech.googleapis.com/v1/operations/' + operation_name + '?key=' + key
#長時間実行オペレーション開始(この時点ではまだ音声認識結果は含まれていない)
content_res = requests.get(endpointUri)
results = 'Transcribing...'
print('\n' + results)
while results == 'Transcribing...':
time.sleep(10)
#10秒後にオペレーション結果取得
content_res = requests.get(endpointUri)
try:
#オペレーション結果に音声認識結果が含まれていればパース
results = (content_res.json())['response']['results']
except:
#含まれていなければリトライ
print(results)
print('\n-*- transcribe result -*-')
# 結果をコンソール出力
for index, item in enumerate(results):
print('[%d]Transcript >>>' % (index + 1), item["alternatives"][0]["transcript"])
print('[%d]Confidence >>>' % (index + 1), item["alternatives"][0]["confidence"])
動作確認
今回は音声ファイルとして私の過去の記事の以下の一文をAmazon Pollyで音声化したデータを使います。
MS公式でもドキュメントが非常に多岐にわたっており、うかつに深入りすると相当大変であることを実感しました。当初は方法1と2の手順のみを記載したタイトルの範囲内の記事にしようとしていましたが、興味本位で認証のしくみを調べていくうちにこんな枝葉に及ぶ記事になってしまっていました。
引数に音声ファイル名を指定してスクリプトを実行します。
$ python <スクリプト名> <音声ファイル名>
60秒未満のwavデータを指定した場合。
$ python sample_part1.py speech_less60s.wav
-*- audio info -*-
filename : speech_less60s.wav
mimetype : audio/x-wav
sampleRate : 16000
playtime : 23.608s
-*- transcribe result -*-
[1]Transcript >>> MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載したタイト ルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな枝葉に及ぶ記事になってしまっていました
[1]Confidence >>> 0.9452861
60秒以上のflacデータ(先程の音声を3回リピートしたファイル)を指定した場合。
$ python sample_part1.py speech_more60s.flac
-*- audio info -*-
filename : speech_more60s.flac
mimetype : audio/x-flac
sampleRate : 44100
playtime : 70.82401360544218s
Transcribing...
Transcribing...
-*- transcribe result -*-
[1]Transcript >>> MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載したタイト ルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな枝葉に及ぶ記事になってしまっていました MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載したタイトルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな枝葉に及ぶ記事になってしまっていました MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載した
[1]Confidence >>> 0.9549997
[2]Transcript >>> タイトルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな伊良波に及ぶ記事になってしまっていました
[2]Confidence >>> 0.93668646
また、翻訳結果と合わせて下記のようなpydubの警告が出力される場合がありますが、これは無視してください。(私の場合はAWS Lambdaで実行時は出なかったのにAWS Cloud9で実行すると出てきました。)
/XXX/XXX/pydub/utils.py:165: RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work
warn("Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work", RuntimeWarning)
備考
-
magic、pydub、mutagenパッケージを使って音声データからの情報取得をかなりよろしくやってくれるようにしています。これらを使わず手動で指定でも勿論OKです。 -
longrunningrecognize()メソッドはGoogleサーバー側で非同期実行となるため、オペレーションが完了するまでwhile内で待機&結果取得を繰り返しています。 -
longrunningrecognize()メソッドは音声ファイルの指定はGoogle Cloud StorageのURIを指定する必要があります。今回はAPIキーを利用しているためStorage上の音声データの権限設定を一般公開設定にしていますが、サービスアカウントを利用して一般公開しない方法もできるようです。 -
recognize()メソッドであれば、以下のようにリクエストボディのcontentフィールドに音声ファイルのローカルパスを指定することにより、GCSを使わずにローカルの音声ファイルを直接指定することもできたりします。
# リクエストボディ定義
body={
///中略///
'audio': {
'content' : 'local sound file path'
}
}
- リアルタイムで音声認識を実行するストリーミング リクエストという方法も提供されています。またそれとは別にこちらでは
recognize()メソッドを使ってほぼリアルタイムの音声認識を実現する方法も紹介されています。
2.Speech-to-Text Client Libraries を利用した方法
- 短い音声ファイルの文字変換および長い音声ファイルの文字変換で公開されている方法です。
-
google-cloud-speechパッケージを利用します - 1分未満の音声ファイルには
recognize()メソッドを利用して同期的に音声認識を行います。 - 1分以上の音声ファイルには
long_running_recognize()メソッドを利用して非同期的に音声認識を行います。 - 1分未満/以上いずれの音声ファイルもローカルまたはGoogle Cloud Storageのいずれかに配置すれば良いです。
- 2019年3月時点でアルファ版での提供となります。
クライアント ライブラリはアルファ版としてリリースされており、下位互換性のない方法で変更される可能性があります。クライアント ライブラリの本番環境での使用は、現在推奨されていません。
以下は、Google Cloud Storage(以降、GCS)に配置した音声ファイルを音声認識させて結果を出力するサンプルプログラムを作成する手順となります。
※この手順では音声ファイルを一般公開しない方法で音声認識を行います。
Google Cloud Platformの準備
まだの場合はGoogle Cloud Platformのアカウントを登録します。
無料トライアルもあるので活用しましょう。
アカウント登録が済んだら、リソースの管理ページから新規プロジェクトを作成します。
以降は作成したプロジェクトに対して設定を行っていきます。
API ライブラリでCloud Speech-to-Text APIとGoogle Cloud Storageを有効にします。(ライブラリ内で左の文言で検索したらヒットします)
サービスアカウントの作成ページで新しいサービスアカウントキーを作成します。
役割はストレージオブジェクト閲覧者を指定してください。
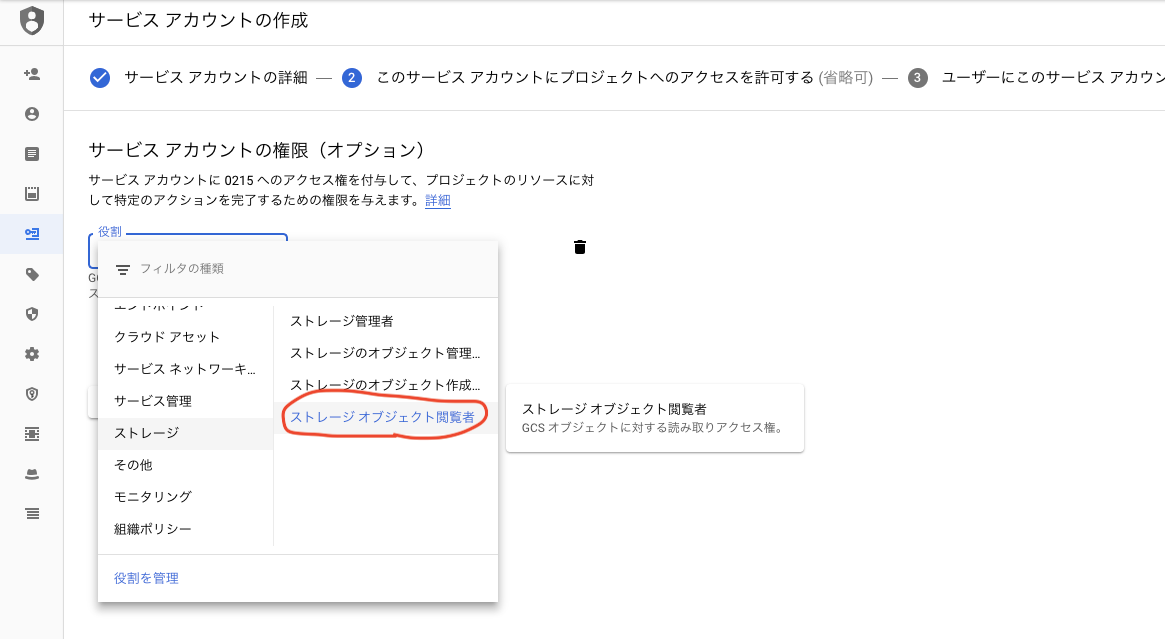
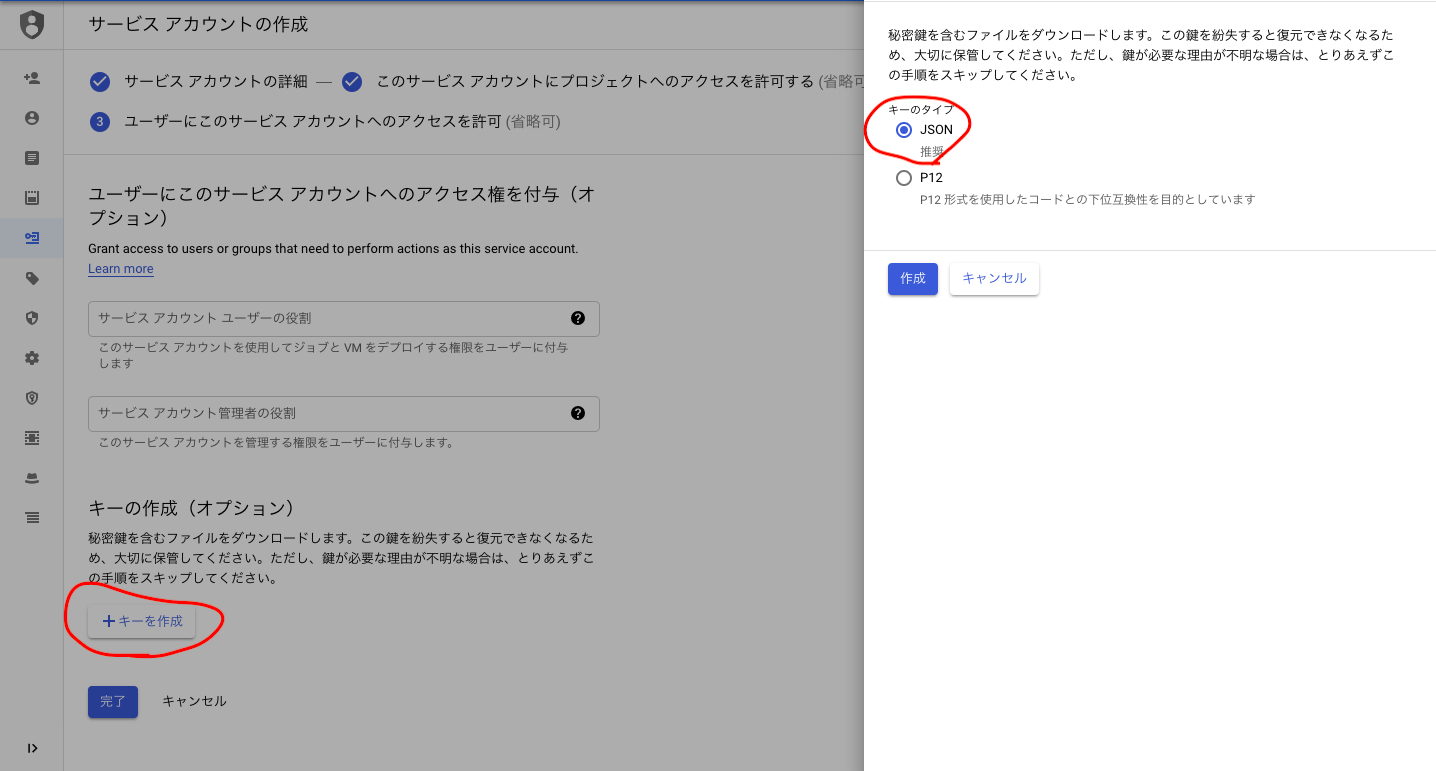
[キーの作成(オプション)]でキーのタイプJSONを指定し、jsonファイルのキーをローカルにダウンロードして後ほど利用するbash環境のプロジェクトフォルダ内に配置しておきます。
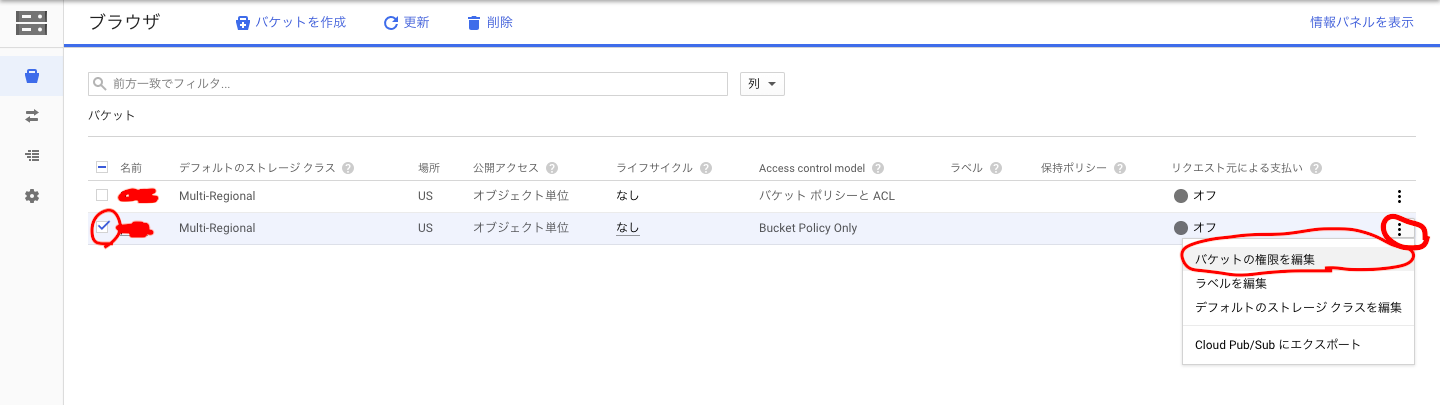
Google Cloud Storageで新しいバケットを作成します。
作成したバケットを選択して[バケットの権限を編集]をクリック。
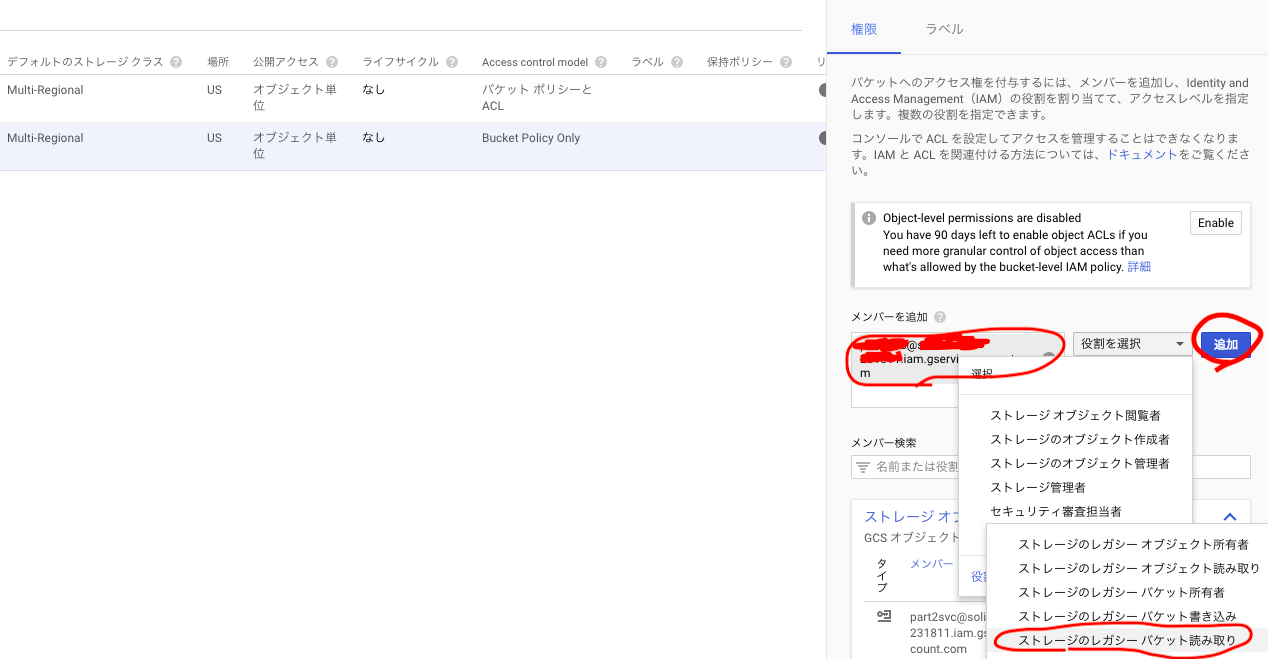
先程作成したサービスアカウントをメール名(<ID名>@<プロジェクトID>.iam.gserviceaccount.com)で追加し、ストレージのレガシー バケット読み取り役割を付与します。
音声認識を行いたいFLACまたはWAV形式のファイルをバケットにアップロードします。再生時間に応じて処理時間も大きくなるので、まずは1分前後の短いデータで試しましょう。
Python環境の準備
Bash環境のプロジェクトフォルダ内で作業を行っていきます。
Pythonパッケージをインストール。
$ cat << EOF > requirements.txt
google-cloud-speech #Speech-to-Text Client Librariesのパッケージ
google-cloud-storage #Google Cloud Storageから音声データ取得用
protobuf #google.protobufインポート用
python-magic #音声ファイルmime判定用
pydub #WAVファイル情報取得用
mutagen #FLACファイル情報取得用
EOF
$ pip install -r requirements.txt -t .
$ pip install --upgrade google-cloud-speech
※公式ページにあるようにgoogle-cloud-speechはupgradeをしなければ、私の場合はスクリプト実行時にModuleNotFoundError: No module named 'google.cloud'となりました。
先程ダウンロードしたjsonキーを環境変数に設定。
export GOOGLE_APPLICATION_CREDENTIALS=<jsonキーファイル名>
以下のスクリプトを作成。
スクリプト内のYourBucketNameに先程作成したバケット名を書き込んで、bucketname変数で使えるようにします。
# coding:utf8
import sys
from google.cloud import speech
from google.cloud import storage as gcs
from mutagen.flac import FLAC
from pydub import AudioSegment
import magic
filename = sys.argv[1]
bucketname = 'YourBucketName'
# gcsからデータをダウンロード
client = gcs.Client()
bucket = client.get_bucket(bucketname)
blob = gcs.Blob(filename, bucket)
content = blob.download_as_string()
# ダウンロードした音声データからencoding、rate、lengthの情報を取得
mime = magic.Magic(mime=True).from_buffer(content)
if mime == 'audio/x-wav' and '.wav' in filename:
encoding = 'LINEAR16'
sound = AudioSegment(content)
if sound.channels != 1:
print('Must use single channel (mono) audio')
sys.exit()
rate = sound.frame_rate
length = sound.duration_seconds
elif mime == 'audio/x-flac' and '.flac' in filename:
encoding = 'FLAC'
with open(filename, 'wb') as f:
f.write(content)
f.close()
sound = FLAC(filename).info
if sound.channels != 1:
print('Must use single channel (mono) audio')
sys.exit()
rate = sound.sample_rate
length = sound.length
else:
print('Acceptable type is only "wav" or "flac".')
sys.exit()
print('\n-*- audio info -*-')
print('filename : ' + filename)
print('mimetype : ' + mime)
print('sampleRate : ' + str(rate))
print('playtime : ' + str(length) + 's')
print('\nWaiting for operation to complete...')
client = speech.SpeechClient()
audio = {'uri':'gs://' + bucketname + '/' + filename}
config = {'encoding':encoding,'sample_rate_hertz':rate,'language_code':'ja-JP'}
if length < 60:
# 再生時間が1分未満の場合
response = client.recognize(config, audio)
else:
# 再生時間が1分以上の場合
operation = client.long_running_recognize(config, audio)
response = operation.result(timeout=length)
print('\n-*- transcribe result -*-')
# 結果をコンソール出力
for index, item in enumerate(response.results):
print('[%d]Transcript >>>' % (index + 1), item.alternatives[0].transcript)
print('[%d]Confidence >>>' % (index + 1), item.alternatives[0].confidence)
動作確認
今回も方法1のときと同じ音声ファイルを利用します。
引数に音声ファイル名を指定してスクリプトを実行します。
$ python <スクリプト名> <音声ファイル名>
60秒未満のwavデータを指定した場合。
$ python sample_part2.py speech_less60s.wav
-*- audio info -*-
filename : speech_less60s.wav
mimetype : audio/x-wav
sampleRate : 16000
playtime : 23.608s
Waiting for operation to complete...
-*- transcribe result -*-
[1]Transcript >>> MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載したタイト ルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな伊良波に及ぶ記事になってしまっていました
[1]Confidence >>> 0.9612300992012024
60秒以上のflacデータ(先程の音声を3回リピートしたファイル)を指定した場合。
$ python sample_part2.py speech_more60s.flac
-*- audio info -*-
filename : speech_more60s.flac
mimetype : audio/x-flac
sampleRate : 44100
playtime : 70.82401360544218s
Waiting for operation to complete...
-*- transcribe result -*-
[1]Transcript >>> MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載したタイト ルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな枝葉に及ぶ記事になってしまっていました MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載したタイトルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな枝葉に及ぶ記事になってしまっていました MS 公式でもドキュメントが非常に多岐にわたっており部活に深入りすると相当大変であることを実感しました当初は方法1と2の手順のみを記載した
[1]Confidence >>> 0.9548822641372681
[2]Transcript >>> タイトルの範囲内の記事にしようとしていましたが興味本位で認証の仕組みを調べていくうちにこんな伊良波に及ぶ記事になってしまっていました
[2]Confidence >>> 0.9366810321807861
方法1と同様にpydubの警告が出力される場合がありますが、こちらも無視してください。
備考
-
long_running_recognize()メソッドは音声ファイルの指定はGCSのURIを指定する必要があります。 -
recognize()メソッドであれば、リクエストボディのcontentフィールドに音声ファイルのローカルパスを指定することにより、GCSを使わずにローカルの音声ファイルを直接指定することもできます。 - 方法1と比べて方法2の方がコードの記述が明らかに簡潔になっています。
- jsonキーの利用、バケットの権限設定を行うだけで、音声ファイルを公開設定せずに済むようになっています。
- 方法1と比べてGCSのパッケージの利用が余計なように感じますが、実務ではローカルに音声ファイルを用意してGCSにアップロードしてから音声認識を実行するというパターンが多いと思うので、結局はGCSパッケージを使うことになるかと思います。
おわりに
- それぞれのライブラリのpypiサイトを見てみると、どちらもバージョンのリリースは現在も順調に続けられており、GitHubでも活発に活動が行われてますが、方法2の
google-cloud-speechのパッケージの方はGoogleCloudのほぼすべての機能のAPIをまかなうgoogle-cloud-pythonのいちコンポーネントとして提供されているものとなるため、将来的にはSpeech-to-Text Client Librariesに一本化されていきこちらの方が残るのではと考えています。
https://pypi.org/project/google-api-python-client/
https://pypi.org/project/google-cloud-speech/
-
今回の手順のようなプログラムはシステムの自動化の一環の中に組み込む使い方向けとなりますので、そうでなくて手動でもいいのでただ単に手元の音声ファイルの文字起こしがしたい!というひとは、すでにあるwriter.appなどの文字起こしサービスを素直に利用された方がいいかと思います。
-
Google Cloud Speech-to-Textの機能は、以下のようにすでに様々な企業の音声・メディアソリューションのバックエンド技術に使われていたりします。
AIでリアルタイム字幕 AbemaTVのニュース番組で試験放送
音声・ビデオ通話データと翻訳AIなどの連携キットを無償公開--NTT Com
課題
- Pythonパッケージに頼らずにRestfulなプロトコルのみで音声認識を利用できないか。(こことか見ながらできそう?)
- Google Cloud Speech-to-Textは原則としてコーデックはWAV、FLACにのみ対応、他にもチャネル数やサンプリングレートで条件があったりするので、非対応の音声ファイルはffmpegで前処理を噛ませたい。