※2019/10/4のMicrosoft社の発表の通り、従来の「Microsoft Flow」は新機能のUI Flowsが追加されて「Microsoft Power Automate」となりました。記事内のMicrosoft Flowの記述はPower Automateに読み替えて下さい。
はじめに
Microsoft AzureのCognitive Servicesの一つであるComputer Vision APIをMicrosoft Flowから利用した際のメモ。
毎月書面で届く請求書から請求金額をOCRしてデータ化したかった。
やってみる
Azure PortalでComputer Vision APIのリソースを作成
Azureにログインし、Computer Vision APIのリソースを作成する。以下のURLを叩けば作成画面に行ける。
[場所]は「(アジア太平洋) 東日本」を選択した。
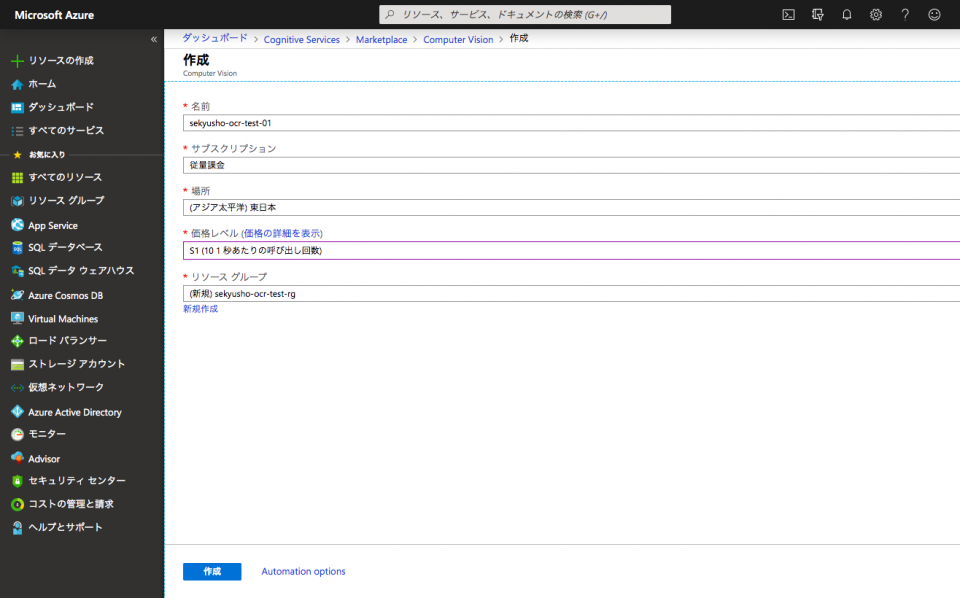
作成が完了したらリソースのページを開き、[リソース管理]-[クイックスタート]より「Key 1」と「エンドポイント」の値を控える。
フローの作成 - Computer Vision APIへの接続の作成
Microsoft Flowのページでフロー作成を行う。
フロー作成画面でアクションに「Optical Character Recognition (OCR) to Text」を選択。
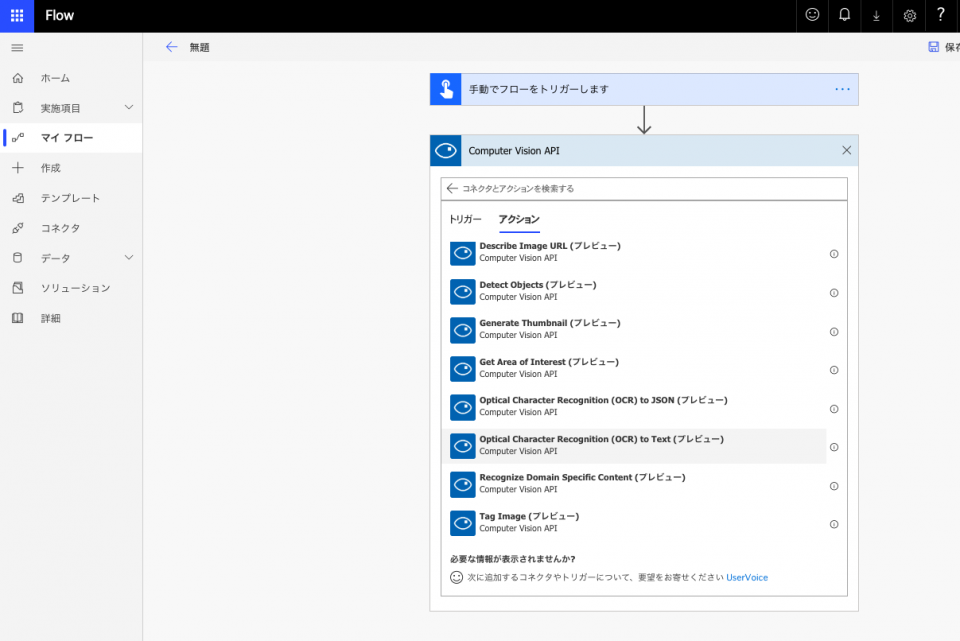
接続の構成を求められたので、[Account key]欄に先ほどAzureのComputer Vision APIリソースの画面で控えた「Key 1」のキー文字列を入力して[作成]をクリック。
「接続テストに失敗しました」と出た。
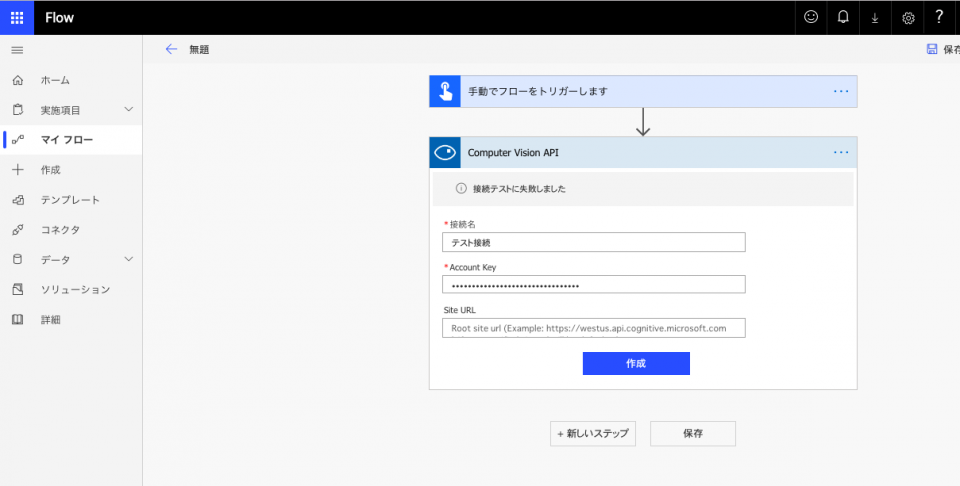
Azureサポートに問い合わせたら以下のような回答があった。
Computer Vision APIリソースのリージョンに「東日本」を選択している場合は、フローからの接続作成時に[Site URL]にComputer Vision APIリソースの「エンドポイント」を指定する必要があるらしい。
Computer Vision API のリソースを Azure ポータルから作成される際に、リージョンとして東日本を選択いただいているかと存じます。Computer Vision API はリージョン毎に異なるエンドポイントが用意されており、このエンドポイントは以下のスクリーンショットの通り、Azure ポータルの Computer Vision API のリソースの概要でご確認いただけます。API キーとエンドポイントが対応していない場合は認証エラーが発生いたしますので、Flow 側でも Computer Vision API の接続情報を設定する画面において、"Site URL" として上記エンドポイントの URL を設定いただく必要がございます。なお、"接続名" については任意の文字列を入力できる項目となっており、認証情報やエンドポイントの指定に使われることはございませんので、ご注意ください。
というわけで先ほど控えたエンドポイントのURLの方も[Site URL]で指定して、「作成」。
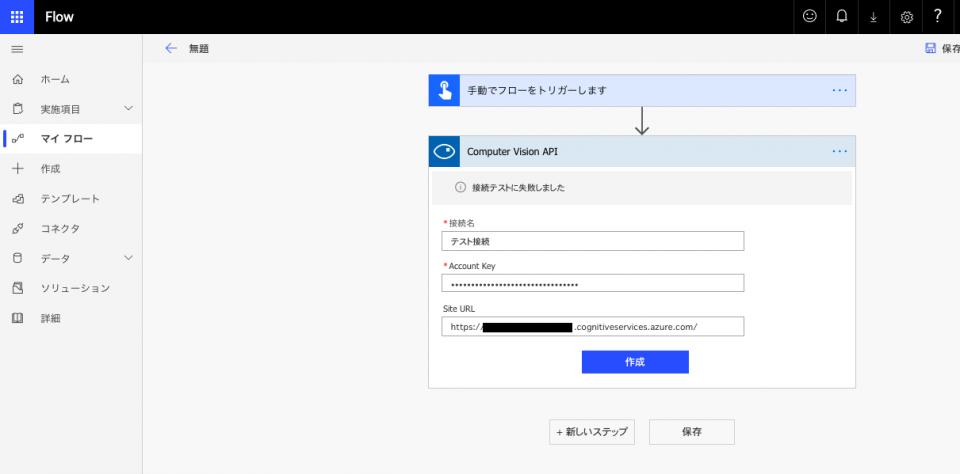
接続を作成できた。
※下記記事で紹介されている手順では、場所に「米国西部」を指定していたためエンドポイントの指定が不要であったようだ。
https://zuvuyalink.net/nrjlog/archives/4270
※そして[Site URL]の入力欄内のプレースホルダテキストをよく見ると以下のように書いてある。既定だと「westus」のエンドポイントが使われるとのこと。同じ記載は公式ページにもある。気づかなかった…。
Root site url (Example: https://westus.api.cognitive.microsoft.com ).If not specified site url will be defaulted to 'https://westus.api.cognitive.microsoft.com'.
※また更にAPI利用時のエラーの切り分けには下記ページが役立つとAzureサポートの方に教えてもらった。確かに役立ちそう。
https://blogs.msdn.microsoft.com/jpcognitiveblog/2018/02/01/troubleshooting-http-401-access-denied-invalid-subscription-key/
フローの作成 - 実際にOCRさせてみる
OneDrive for Businessに請求書の画像をアップロードし、その画像ファイルのコンテンツを「Optical Character Recognition (OCR) to Text」と「Optical Character Recognition (OCR) to JSON」でOCR対象として指定。フロー実行。
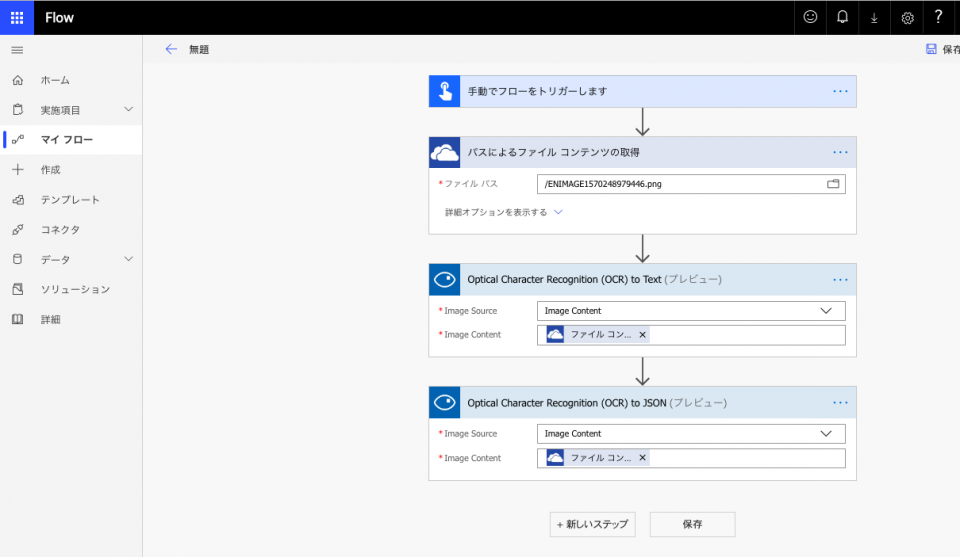
OCR結果を取得できた。
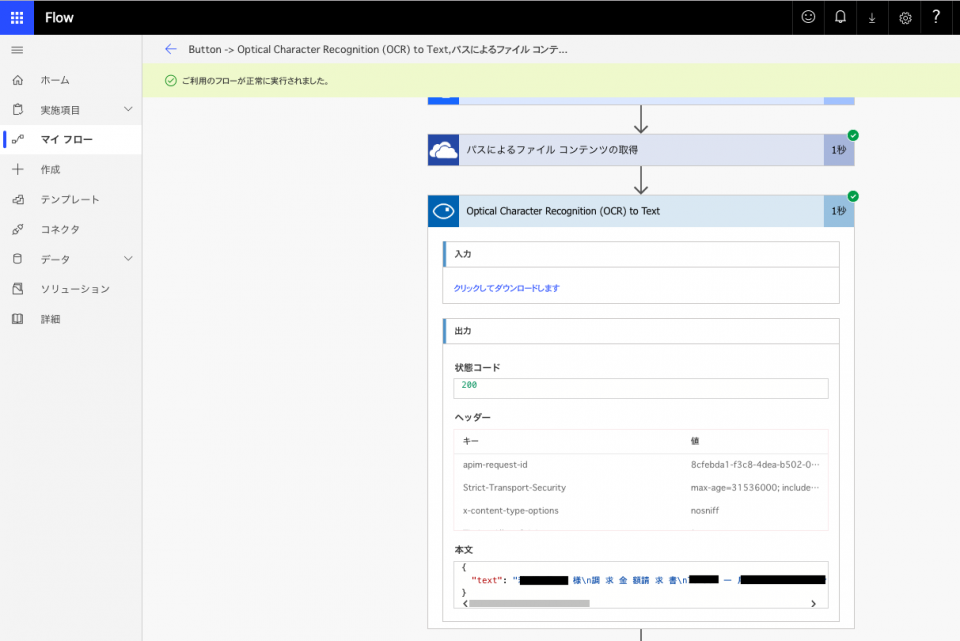
Textの方。
OCRされた書面の位置エリアごとに「\n」、文字ごとに「 (空欄)」で区切られている。
JSONの方。
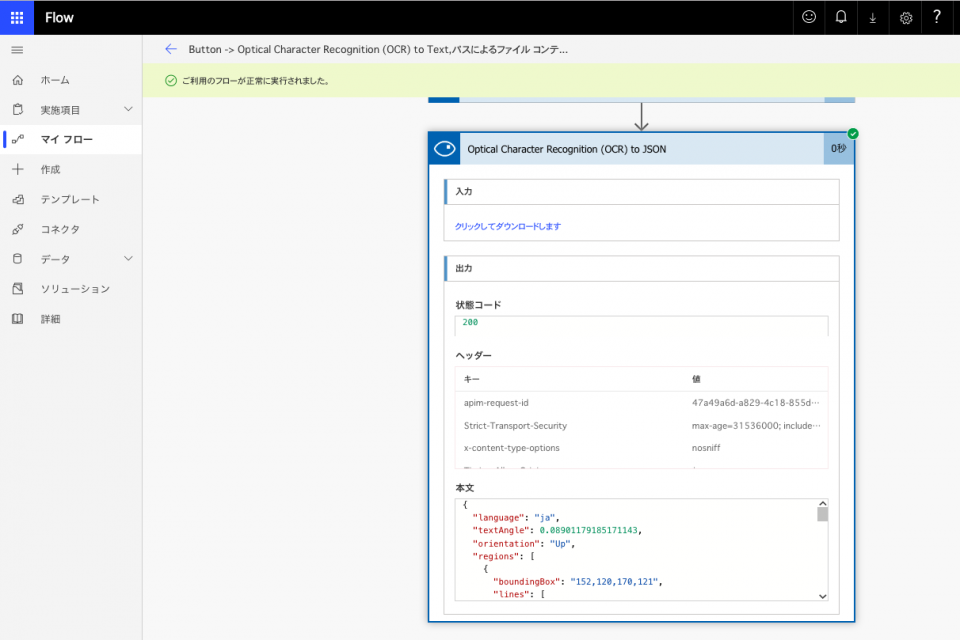
JSONの結果の[本文]のJSON文字列の一部。
OCRされた書面の位置エリアごと、文字ごとにJSONグループや階層が作られている。
{
"language": "ja",
"textAngle": 0.08901179185171143,
"orientation": "Up",
"regions": [
{
"boundingBox": "152,120,170,121",
"lines": [
{
"boundingBox": "152,120,149,19",
"words": [
{
"boundingBox": "152,120,24,18",
"text": "<氏名一文字目>"
},
{
"boundingBox": "177,120,23,18",
"text": "<氏名二文字目>"
},
{
"boundingBox": "219,120,23,18",
"text": "<氏名三文字目>"
},
{
"boundingBox": "244,120,24,18",
"text": "<氏名四文字目>"
},
{
"boundingBox": "277,121,24,18",
"text": "様"
}
]
},
{
"boundingBox": "234,224,88,17",
"words": [
{
"boundingBox": "234,224,20,17",
"text": "調"
},
{
"boundingBox": "257,224,19,17",
"text": "求"
},
{
"boundingBox": "279,224,19,16",
"text": "金"
},
{
"boundingBox": "301,224,21,17",
"text": "額"
}
]
}
]
},
{
"boundingBox": "438,169,180,79",
"lines": [
{
"boundingBox": "496,169,122,34",
"words": [
{
"boundingBox": "496,169,38,29",
"text": "請"
},
{
"boundingBox": "539,171,36,28",
"text": "求"
},
{
"boundingBox": "581,174,37,29",
"text": "書"
}
]
},
{
"boundingBox": "438,225,112,23",
"words": [
{
"boundingBox": "438,225,78,20",
"text": "<請求金額>"
},
{
"boundingBox": "525,228,6,19",
"text": "一"
},
{
"boundingBox": "532,228,18,20",
"text": "月"
}
]
}
]
}
]
}
ちなみにOCRされる画像のファイルサイズが大きいとこのようなエラーが出る。
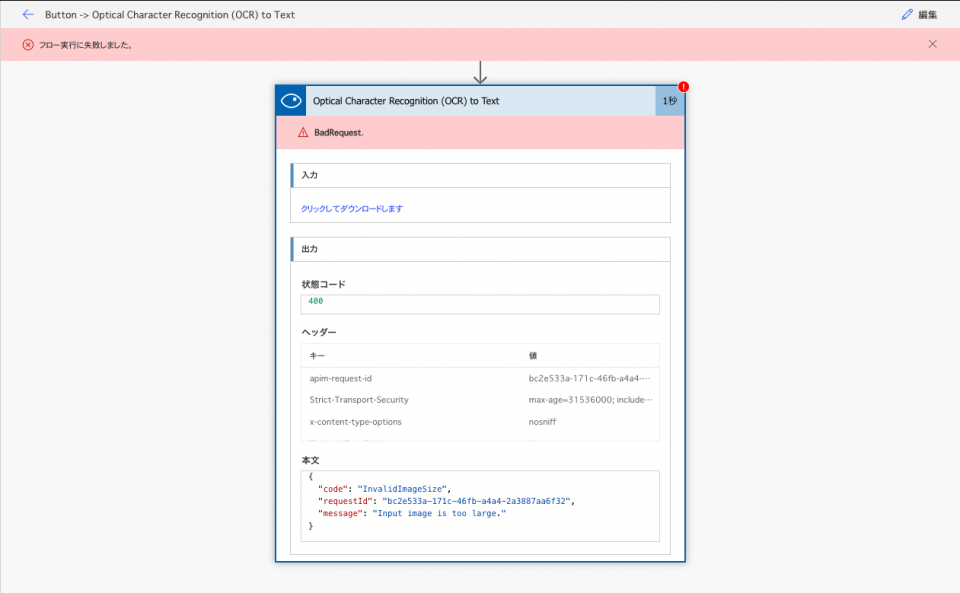
下記によると対応可能なファイルサイズは最大4MBまでらしい。
Image file size must be less than 4MB.
おわりに
請求書書面の様式が一様なら、OCR結果のJSON文字列から請求金額の数値をうまいことパースすればいけそう。
以上