注意
- この記事は Dealing with Imbalanced Classes in Machine Learning を和訳したものです。
- 元記事中で
class imbalanceやimbalanced classificationなどと表現されている概念は、必要に応じて不均衡データなどの表現に置き換えています。
はじめに
現実世界の分類問題ではしばしば、不均衡データを扱わざるを得ない状況になる場合があります。不均衡データとは、データセットに含まれるインスタンスのクラスが占める割合が均一にならないようなもののことを指します。不均衡データを用いた機械学習では、評価指標と手法の適切な調整が重要で、これが行われないと、あなたが取り組みたい真の目的に対して無意味な指標が最適化されてしまう可能性があります。
例えば、AとBの2つのクラスがあるとします。クラスAがデータセットの90%を、クラスBが残りの10%をそれぞれ占めますが、あなたは特にクラスBのインスタンスの識別を正しく行いたい、というような状況を考えます。全てのインスタンスに対してクラスがAであると予測する予測器の精度 (Accuracy) は90%になりますが、これは今回のあなたの目的にとっては全く無意味なものです。一方で、適切に補正された手法を用いると、単純な精度 (Accuracy) こそ下がるかもしれませんが、かなり高い真陽性率1を実現できるはずであり、これは今回の問題設定でまさにあなたが最適化すべき指標であると言えます。こういった状況は、オンラインでの不適切なコンテンツの検知や、医療での疾患マーカーに関する分析などでしばしば表れます。
以下では、不均衡データをうまく扱うために使用できるいくつかの手法について説明します。ほとんど全ての場合に適用可能な技法もあれば、データが特定の不均衡さをもつ場合に適した技法もあります。この記事では、2クラス分類の観点からこれらの手法について説明しますが、ほとんどの場合、多クラス分類についても同じことが言えます。また、分類の目的は少数派のクラスを正しく特定することであるとします。(そうでなければ、不均衡データを扱う手法はそもそも必要とされないはずです。)
評価指標
一般に、不均衡データに関する分類問題は、recall (再現率。実際に正であるもののうち、正であると予測されたものの割合。)と precision (適合率。正と予測したデータのうち、実際に正であるものの割合。)との間のトレードオフに帰着します。少数派のクラスのインスタンスを検出したいという状況では、たいていの場合適合率よりも再現率を強く考慮します。なぜなら、検出という文脈では、負例に誤ったラベルを付けるよりも、正例を見逃す方がコストがかかるからです。例えば、不適切なコンテンツを検出しようとしている場合、不適切だと判断されたコンテンツが実際は不適切ではなかったということに手動のレビュワーが気付くというのは瑣末な問題ですが、不適切であるというフラグが立てられていないにもかかわらず実際は不適切だったコンテンツを特定するのは非常に難しいです。したがって、不均衡データの分類問題に取り組むときは、再現率、適合率、AUROCなどの、精度よりも適した評価指標の使用を検討してください。パラメータまたはモデルを選択するときに最適化する指標を切り替えることは、少数派クラスを検出する際のパフォーマンスの向上に大きく寄与するでしょう。
コスト考慮型学習
通常の学習では、すべての誤分類を等しく扱いますが、これを不均衡な分類問題にも同様に適用してしまうと問題が発生することがあります。なぜなら、学習器にとっては、過半数を占めるクラスよりも少数派のクラスを重視して識別するための特別な理由が存在しないからです。コスト考慮型学習ではこれを変更し、クラス $t$ のインスタンスを誤ってクラス $p$ と分類してしまった際のコストを指定する関数 $C(p, t)$ (通常は行列で表現されます)を使用します。 これにより、少数派クラスの誤分類のペナルティを過半数クラスの誤分類のそれよりも重くすることで recall が向上することを期待できます。コスト関数 $C(p, t)$ の定義として、クラス $t$ のインスタンスの数がデータセット中に占める割合の逆数がよく用いられます。この定義を用いた場合、クラスが占める割合が小さくなればなるほどペナルティが大きくなることになります。

サンプリング
不均衡データを補正する簡単な方法は、少数派クラスのインスタンスを oversampling するか、または多数派クラスのインスタンスを undersampling することです。これによって、理論上は、正例と負例のバランスがとれたデータセットを作成することが可能です。 しかしながら、実際には、上記の単純なサンプリング手法には欠陥があります。少数を oversampling すると、少数派クラスのインスタンスが重複して学習に使用されることによって、モデルの過学習につながる可能性があります。 同様に、多数を undersampling すると、2つのクラスの間で重要な違いをもたらすインスタンスが学習から除外されてしまう可能性があります。
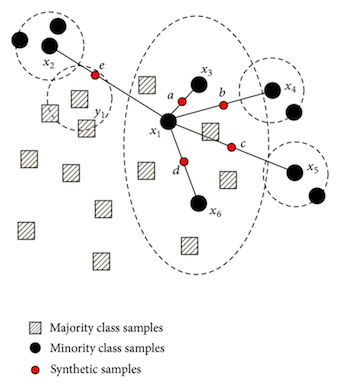
シンプルな oversampling や undersampling を超える、より強力なサンプリング手法も存在します。 最もよく知られているものはSMOTEで、端的に言うと隣接するインスタンスの凸結合から少数派クラスの新しいインスタンスを作成するという手法です。もう少し噛み砕くと、下の図が示すように、少数派クラスのインスタンスのうち2つの間に直線を引き、その直線からある点をサンプリングし、少数派クラスの新しいインスタンスとする、という処理を行います。これにより、重複したインスタンスを使用するのではなく、新しい人工的なインスタンスを作成するため、重大な過学習を伴わずにデータセットのバランスを整えることができます。 しかし、これらは既存のデータ点から作成されるため、過学習を完全に防ぐことができるわけではありません。
異常検知
より極端な場合には、異常検知の文脈のもとでの分類を考える方がよいかもしれません。 異常検知では、データ点の「通常の」分布があると仮定し、その分布から十分に逸脱したデータは異常であると判断します。不均衡データに関する分類問題を異常検知問題として捉え直す場合、過半数クラスをデータ点の「通常の」分布として扱い、少数クラスのインスタンスを異常なデータ点とみなします。異常検知のアルゴリズムは、クラスタリングに基づく手法、1クラスSVM、Isolation Forests など多数存在します。
おわりに
以上に紹介した手法を組み合わせることで、不均衡データに対してより良い分類器を構築できます。先に述べたように、不均衡さの度合いに応じて最適な手法は異なります。例えば、単純なサンプリング手法はわずかな不均衡さをもつデータへの対策には適しますが、極端な不均衡データに対しては異常検知に基づく手法が必要になることがあります。結局のところ、不均衡データの扱い方として万能な方法はありません。可能性のある手法を試し、正しい評価指標にどのようにどのような影響を及ぼすかを確認していく必要があります。
-
True positive rate. 実際に陽性であるサンプルのうち、分類器によって正しく陽性であると判定されたサンプルの割合。Recall とも呼ばれる。 ↩