はじめに
私が所属する組織では、情報の蓄積や共有を目的にNotionを使用しています。
その蓄積されているNotion上の情報をベクトル化し、それを元にLLMが回答を生成するRAG(Retrieval-Augmented Generation)を構築する機会があったので、どのような仕組みで構築したのかご紹介できればと思います。
特に本記事では、Notionから取得したデータをAWS Lambdaを用いてベクトル化してS3へ保持するプロセスと、そのベクトル化されたデータを元にLLMによる応答を生成する仕組みに焦点を当てて解説します!
実際に構築したシステム構成
実際に構築したシステムの構成図は以下になります。
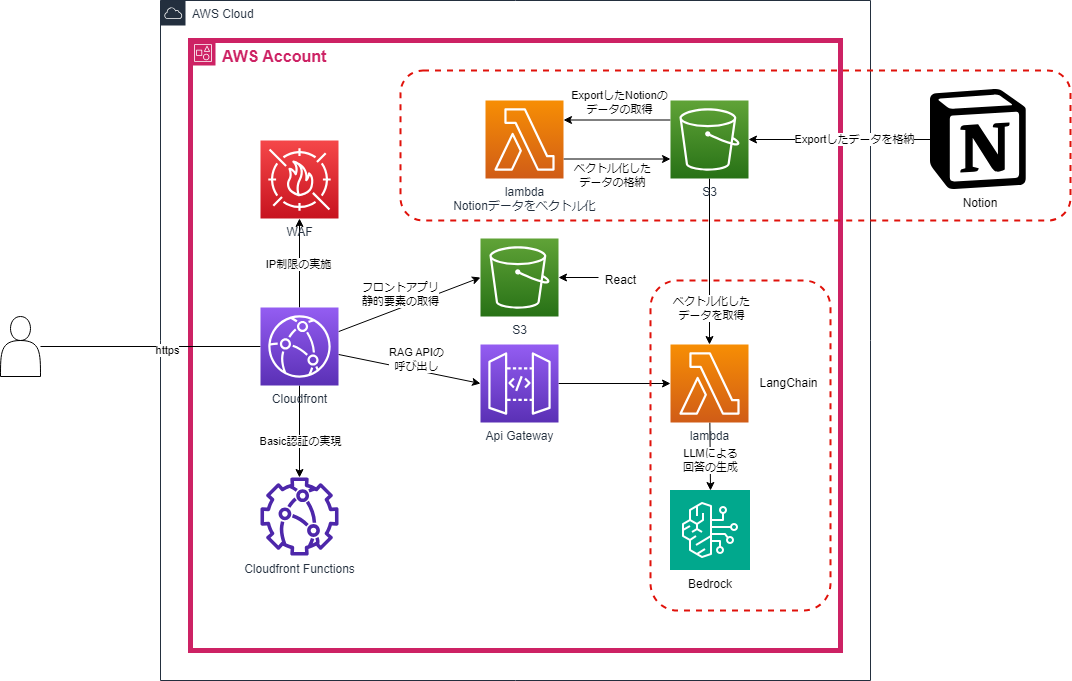
本記事では図中の赤点線で囲まれた部分について詳細に説明します。
また、各コンポーネントの役割は以下となります。
CloudFront
CDN。S3上に格納したReactベースの静的コンテンツの配信及びAPIのエンドポイントを提供します。
CloudFront Functions
CloudFront経由でS3上の静的コンテンツへアクセスする際のBasic認証を実現します。
今回構築したシステムの利用はあくまでも社内の一部グループ内に留まっており、厳格な認証機能は不要であったためこのような仕様になっています。
WAF
IP制限を実施し、許可されたIPアドレスからしかアクセスを許可しない設定としています。
API Gateway
LLMとチャットベースのやり取りを行うためのAPIを提供します。
Lambda
2つの役割を持ったLambdaを構築します。
- NotionデータのベクトルDB化
S3上に格納したNotionのExportデータをベクトルDB化し、S3上へ格納します。
ベクトル化にはBedrockで提供されているテキストembeddingモデルを使用します。 - チャットAPIの処理
API Gatewayで受け取ったリクエストを元に処理を行います。
APIに指定された内容を元に、ベクトルDB上に類似との高いドキュメントの検索を行います。
類似度の高いドキュメントをベースに回答を行うようにプロンプトを構築し、Bedrock上で提供されているLLMモデルを使用して回答を行います。
S3
2つの役割を持ったS3を構築します。
- フロントエンドのコンテンツ配信用S3
- NotionのExportデータ、及びそれらをベクトルDB化したデータの格納用S3
Bedrock
LLMモデルの提供サービスです。
Notionデータのベクトル化
さっそくですが、Notionデータをベクトル化するlambdaを構築していきましょう。
構築自体は後々にAWS CDKで実施するので、使用したライブラリやソースコードなどの解説を行います。
Lambdaの基本設定
Pythonを使用して実装します。
ライブラリのサイズがlambdaのデプロイ制限(250MB)を超えてしまうので、dockerイメージでのデプロイが必須となっています。
- ランタイム:Python 3.12
- 使用したライブラリ:
- langchain==0.2.6
- langchain-aws==0.1.9
- langchain-community==0.2.6
- faiss-cpu==1.8.0.post1
- 割り当てが必要なIAMポリシー:S3及びBedrockの実行権限
実際のコード
import boto3
import os
import shutil
from langchain_community.document_loaders import NotionDirectoryLoader
from langchain_community.vectorstores import FAISS
from langchain_aws import BedrockEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# バケット名
bucket_name = os.environ["S3_BUCKET_NAME"]
# Notionのデータが格納されたs3上のフォルダ
orig_docs_dir = "notion_export"
# Notionデータをダウンロードするローカルフォルダ
save_notion_dir = "/tmp/notion_export"
# ベクトルデータを格納するローカルフォルダ
save_vector_dir = "/tmp/notion_index_faiss"
## 前回の実行結果を削除する関数
def delete_last_exec_result(s3_client):
# 'notion_index_faiss'プレフィックスを持つオブジェクトのリストを取得
response = s3_client.list_objects_v2(Bucket=bucket_name, Prefix='notion_index_faiss/')
# オブジェクトが存在する場合、削除を実行
if 'Contents' in response:
# 削除するオブジェクトのリストを作成
delete_objects = [{'Key': obj['Key']} for obj in response['Contents']]
# オブジェクトの削除を実行
s3_client.delete_objects(Bucket=bucket_name, Delete={'Objects': delete_objects})
print(f"Deleted {len(delete_objects)} objects.")
else:
print("No objects found.")
## s3上のNotion Exportデータをダウンロードする関数
def download_dir_s3(dirpath, s3bucket):
for obj in s3bucket.objects.filter(Prefix = dirpath):
# /tmp配下にs3バケット上のNotionデータをすべてダウンロード
key = "/tmp/" + obj.key
if not os.path.exists(os.path.dirname(key)):
os.makedirs(os.path.dirname(key))
s3bucket.download_file(obj.key, key)
## 生成したVectorデータをs3にアップロードする関数
def upload_dir_s3(dirpath, s3bucket):
for root,dirs,files in os.walk(dirpath):
for file in files:
s3bucket.upload_file(
os.path.join(root,file),
## 保存先のs3のパスは/tmp/を削除したものとする
os.path.join(root,file).replace("/tmp/","")
)
## lambda handler
def handler(event, context):
s3 = boto3.resource('s3')
s3_bucket = s3.Bucket(bucket_name)
s3_client = boto3.client('s3')
# 前回の実行結果(ベクトルデータ)があればS3上のフォルダごと削除する
delete_last_exec_result(s3_client)
# S3上のnotion_exportフォルダからNotionのエクスポートデータを取得
download_dir_s3(orig_docs_dir, s3_bucket)
# ダウンロードしたデータを読み込み
loader = NotionDirectoryLoader(save_notion_dir)
docs = loader.load()
print("complete load notion data from s3.")
# テキスト分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=5000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# ベクトルDBの作成
vector_store = FAISS.from_documents(
documents=splits,
embedding=BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
region_name="us-east-1"
)
)
# ローカル上にベクトルDBを保存
vector_store.save_local(save_vector_dir)
# S3へデータ保存
upload_dir_s3(save_vector_dir, s3_bucket)
print("complete save vector data to s3.")
# tmpディレクトリの中身をすべて削除
shutil.rmtree(save_notion_dir)
shutil.rmtree(save_vector_dir)
print("complete delete tmp directory.")
return
handlerの中身を処理を追って簡単に説明します。
1. Notionエクスポートデータのダウンロード
delete_last_exec_result関数により、前回の実行結果を削除します。
その後、download_dir_s3関数を実行し、Notionエクスポートデータをtmpディレクトリ上へダウンロードします。
s3 = boto3.resource('s3')
s3_bucket = s3.Bucket(bucket_name)
s3_client = boto3.client('s3')
# 前回の実行結果(ベクトルデータ)があればS3上のフォルダごと削除する
delete_last_exec_result(s3_client)
# S3上のnotion_exportフォルダからNotionのエクスポートデータを取得
download_dir_s3(orig_docs_dir, s3_bucket)
2. エクスポートデータの読み込み & テキスト分割の実施
Notionのデータ取り込みには「Markdown & CSV」形式でエクスポートしたデータを使用します。
そのデータをlangchainから提供されているNotionDirectoryLoaderを使用して取り込みを行います。
データ取り込み後、ベクトル化を行う前にテキスト分割を行います。
# ダウンロードしたデータを読み込み
loader = NotionDirectoryLoader(save_notion_dir)
docs = loader.load()
print("complete load notion data from s3.")
# テキスト分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=5000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
3. ベクトルDBの作成、S3へのデータ保存
テキスト分割したデータを元に、ベクトルDBの作成を行います。
今回、ベクトルDBにはFAISSを使用しており、エンベディングモデルにはamazon titan text embedding v2を使用しています。
ベクトルDB作成後、S3上へ作成したDBの保存を行います。
# ベクトルDBの作成
vector_store = FAISS.from_documents(
documents=splits,
embedding=BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
region_name="us-east-1"
)
)
# ローカル上にベクトルDBを保存
vector_store.save_local(save_vector_dir)
# S3へデータ保存
upload_dir_s3(save_vector_dir, s3_bucket)
print("complete save vector data to s3.")
# tmpディレクトリの中身をすべて削除
shutil.rmtree(save_notion_dir)
shutil.rmtree(save_vector_dir)
print("complete delete tmp directory.")
return
S3へ保存したベクトルDBを利用したLLMによる応答生成
次に、S3からベクトルDBデータを取得してLLMに回答を生成させるlambdaを構築しましょう。
Lambdaの基本設定
Pythonを使用して実装します。ランタイム、必要なライブラリは前項の項目と全く同一です。
実際のコード
import boto3
import json
import os
import shutil
from langchain_aws import ChatBedrock
from langchain_aws import BedrockEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
# バケット名
bucket_name = os.environ["S3_BUCKET_NAME"]
# VectorDBデータが格納されたs3上のフォルダ
s3_vector_dir = "notion_index_faiss"
# VectorDBデータが格納されたローカルフォルダ
local_vector_dir = "/tmp/notion_index_faiss"
## s3上のNotion Exportデータをダウンロードする関数
def download_dir_s3():
# s3バケットのオブジェクトを取得
s3 = boto3.resource('s3')
s3_bucket = s3.Bucket(bucket_name)
for obj in s3_bucket.objects.filter(Prefix = s3_vector_dir):
# /tmp配下にs3バケット上のNotionデータをすべてダウンロード
key = "/tmp/" + obj.key
if not os.path.exists(os.path.dirname(key)):
os.makedirs(os.path.dirname(key))
s3_bucket.download_file(obj.key, key)
def handler(event, context):
# リクエストボディを取得
input = json.loads(event.get("body"))
if not input.get("question"):
return {
"statusCode": 400,
"body": json.dumps({"error": "invalid parameter"})
}
question = input.get("question")
print("complete get request body.")
# s3上のVectorデータをダウンロード
download_dir_s3()
print("complete load notion data from s3.")
# llm及びembeddingモデルの初期化
llm = ChatBedrock(
model_id="anthropic.claude-3-haiku-20240307-v1:0",
region_name="us-east-1",
)
embeddings = BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
region_name="us-east-1"
)
# ベクトルDBのロード
vectorstore = FAISS.load_local(
local_vector_dir,
embeddings,
allow_dangerous_deserialization=True,
)
retriever = vectorstore.as_retriever()
retriever.search_kwargs = {"k": 6} # 類似文書の数を指定、デフォルトの4から6に変更
chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
results = chain(question)
print("complete get answer from llm.")
print("answer: " + results["result"])
# tmpディレクトリの中身をすべて削除
shutil.rmtree(local_vector_dir)
returnBody ={
"answer": results["result"]
}
return {
"statusCode": 200,
"body": json.dumps(returnBody)
}
こちらも同様にhandlerの中身を処理を追って簡単に説明します。
1. リクエストボディから質問文を取得
ここで構築するLambdaはAPI Gatewayと繋いでAPIとして運用する用途を想定しているので、指定された質問文をここで取得します。
# リクエストボディを取得
input = json.loads(event.get("body"))
if not input.get("question"):
return {
"statusCode": 400,
"body": json.dumps({"error": "invalid parameter"})
}
question = input.get("question")
print("complete get request body.")
2. S3上のベクトルDBデータを取得、使用するLLMモデルの定義
download_dir_s3関数にて、前項で定義したLambdaによって生成されたベクトルDBデータをS3から取得します。
合わせて、使用するBedrockのLLMモデルを定義しています。
今回、使用するLLMモデルはコストを重視してClaude3-haikuを採用しています。
# s3上のVectorデータをダウンロード
download_dir_s3()
print("complete load notion data from s3.")
# llm及びembeddingモデルの初期化
llm = ChatBedrock(
model_id="anthropic.claude-3-haiku-20240307-v1:0",
region_name="us-east-1",
)
embeddings = BedrockEmbeddings(
model_id="amazon.titan-embed-text-v2:0",
region_name="us-east-1"
)
3. ベクトルDBを使用した回答の生成
取得したベクトルDBデータを元にベクトルストアを構築し、それを元にretrieverを作成します。
それを元に質問文から回答を生成します。
# ベクトルDBのロード
vectorstore = FAISS.load_local(
local_vector_dir,
embeddings,
allow_dangerous_deserialization=True,
)
retriever = vectorstore.as_retriever()
retriever.search_kwargs = {"k": 6} # 類似文書の数を指定、デフォルトの4から6に変更
chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
results = chain(question)
print("complete get answer from llm.")
print("answer: " + results["result"])
4. データのクリーニング & 回答の返却
ベクトルデータを保持していたtmpディレクトリ上のデータを全て削除し、回答を返却します。
# tmpディレクトリの中身をすべて削除
shutil.rmtree(local_vector_dir)
returnBody ={
"answer": results["result"]
}
return {
"statusCode": 200,
"body": json.dumps(returnBody)
}
AWS CDKを利用したLambdaとS3のデプロイ
AWS CDKとは、AWS上のリソースをコードで定義・管理が可能なフレームワークです。
利用方法などは公式ページを参照してください。
CDKを使ったlambdaのデプロイを行います。
また、CDKはtypescriptを使用しています。
利用しているNode.jsのバージョンとcdkのバージョンは以下となります。
- Node.js: v20.15.0
- aws-cdk: 2.147.0
ディレクトリ構成
最終的なディレクトリ構成は以下となります。
├── bin
│ └── langchain_app.ts
├── lib
│ ├── constructs
│ │ ├── s3.ts
│ │ └── lambda.ts
│ └── langchain_app_stack.ts
├── src
│ └── lambda
│ ├── rag_api_function
│ │ ├── Dockerfile
│ │ ├── rag_api_function.py
│ │ └── requirements.txt
│ └── vector_save_function
│ ├── Dockerfile
│ ├── vector_save_function.py
│ └── requirements.txt
├── cdk.json
├── jest.config.js
├── package-lock.json
├── package.json
└── tsconfig.json
ファイルの内容
以下に構成するファイルの内容を記述しておきます。
デプロイを行うと、S3とlambdaが出来上がるはずです。
- lib/langchain_app_stack.ts
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { s3 } from './constructs/s3';
import { lambda } from './constructs/lambda';
// 入力のインターフェース
type appProps = cdk.StackProps & {
webacl: _wafv2.CfnWebACL;
}
export class LangchainAppStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: appProps) {
super(scope, id, props);
// s3
const s3Buckets = new s3(this, "s3", {})
// lambda
const lambdaFunction = new lambda(this, "lambda", {
s3Bucket: s3Buckets.regDataBucket
})
}
}
- lib/constructs/s3.ts
import { Construct } from "constructs";
import {
RemovalPolicy,
aws_s3 as _s3
} from "aws-cdk-lib";
// 入力のインターフェース
export interface S3Props {
}
// コンストラクトの本体
export class s3 extends Construct {
readonly regDataBucket: _s3.Bucket;
readonly frontAppBucket: _s3.Bucket;
constructor(scope: Construct, id: string, props: S3Props) {
super(scope, id);
// S3バケットを作成、Notionデータおよびベクトル保存用
this.regDataBucket = new _s3.Bucket(this, 'ragdata-bucket', {
bucketName: 'bucket-XXXXX',
removalPolicy: RemovalPolicy.DESTROY,
autoDeleteObjects: true
});
}
}
- lib/constructs/lambda.ts
import { Construct } from "constructs";
import {
Duration,
aws_s3 as _s3,
aws_lambda as _lambda,
aws_iam as _iam,
} from "aws-cdk-lib";
// 入力のインターフェース
export interface lambdaProps {
s3Bucket: _s3.Bucket;
}
// コンストラクトの本体
export class lambda extends Construct {
readonly vectorSaveFunction : _lambda.Function;
readonly ragApiFunction : _lambda.Function;
constructor(scope: Construct, id: string, props: lambdaProps) {
super(scope, id);
// lambda環境変数設定
const lambdaEnv = {
"S3_BUCKET_NAME": props.s3Bucket.bucketName,
}
// ベクトルDBの保持lambdaの作成
const vectorSaveFunction = new _lambda.DockerImageFunction(this, 'VectorSaveFunction', {
functionName: 'VectorSaveFunction',
code: _lambda.DockerImageCode.fromImageAsset('./src/lambda/vector_save_function'),
timeout: Duration.seconds(300),
environment: lambdaEnv,
})
// LLMによる応答を実施するlambdaの作成
const ragApiFunction = new _lambda.DockerImageFunction(this, 'RagApiFunction', {
functionName: 'RagApiFunction',
code: _lambda.DockerImageCode.fromImageAsset('./src/lambda/rag_api_function'),
timeout: Duration.seconds(300),
environment: lambdaEnv,
})
// s3の操作権限付与
props.s3Bucket.grantReadWrite(vectorSaveFunction);
props.s3Bucket.grantDelete(vectorSaveFunction);
props.s3Bucket.grantReadWrite(ragApiFunction);
// bedrockの権限付与
const vectorSaveFunctionRole = vectorSaveFunction.role as _iam.Role;
vectorSaveFunctionRole.addManagedPolicy(
_iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonBedrockFullAccess")
);
const ragApiFunctionRole = ragApiFunction.role as _iam.Role;
ragApiFunctionRole.addManagedPolicy(
_iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonBedrockFullAccess")
);
this.vectorSaveFunction = vectorSaveFunction;
this.ragApiFunction = ragApiFunction;
}
}
- src/lambda/rag_api_function/Dockerfile
FROM --platform=linux/amd64 public.ecr.aws/lambda/python:3.12
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
COPY . ${LAMBDA_TASK_ROOT}
CMD [ "rag_api_function.handler" ]
- src/lambda/rag_api_function/requirements.txt
langchain==0.2.6
langchain-aws==0.1.9
langchain-community==0.2.6
faiss-cpu==1.8.0.post1
- src/lambda/vector_save_function/Dockerfile
FROM --platform=linux/amd64 public.ecr.aws/lambda/python:3.12
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
COPY . ${LAMBDA_TASK_ROOT}
CMD [ "vector_save_function.handler" ]
実際の挙動
では、実際にAPI Gatewayと繋げてRAG APIを実行してみましょう。
モザイクがかかっていますが、実際にNotion上に記載のある内容が返却されています。
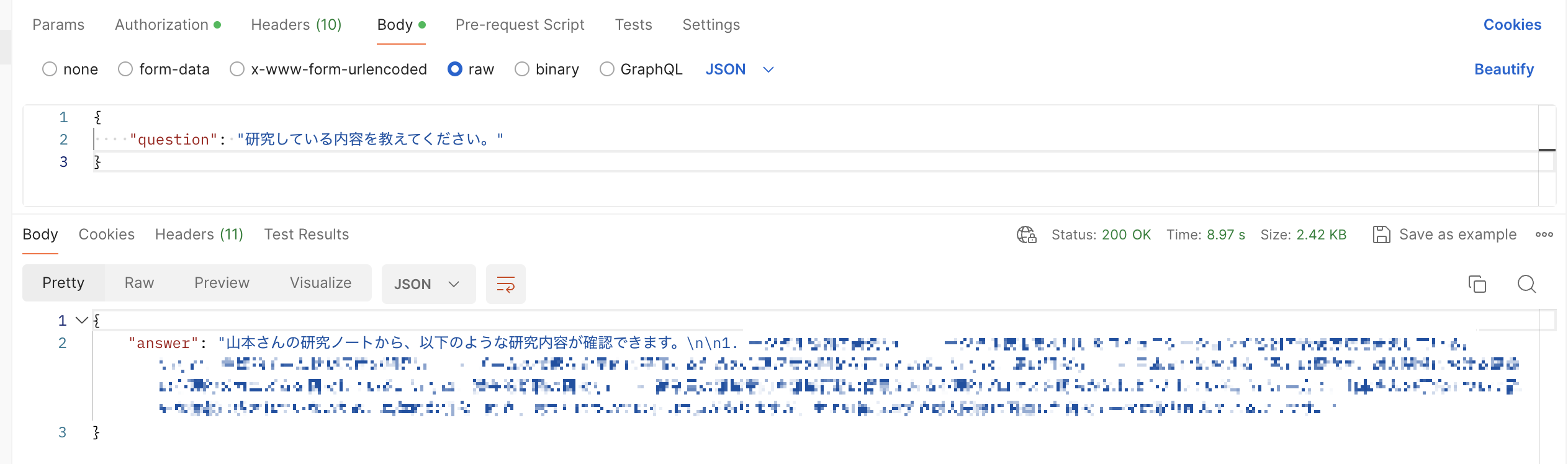
まとめ
AWSのサーバレスアーキテクチャを利用してRAGアプリを構築してみました。
コスト重視のためにサーバレスを中心とした構成をとっていますが、今回の構成だと回答するlambdaを呼び出す際にエクスポートしたデータを毎回S3から呼び出さないといけません。回答までの時間が重視されるシステムにおいてはボトルネックになりうる点はご承知おきいただければと思います。
本記事がどなたかのお役に立てば幸いです。