pandas-profilingとは
pandasのデータフレーム型のオブジェクトに関して、そのデータに関する概要を基本的な観点から確認することを容易にするレポートを生成できるライブラリ。機械学習モデルの検討の初期段階における探索的データ解析(Exploratory data analysis、EDA)にて役立ちそう。
インストール
pip install pandas-profiling
※ condaでインストールすると、pandas-profiling-1.4がインストールされ、このバージョンではエラーが吐かれてしまったため、避けました。
実行
データはお馴染みの、kaggle タイタニック号の生存者予測のデータを使います。
import pandas as pd
import pandas_profiling as pdp
X = pd.read_csv('input/train.csv')
profile = pdp.ProfileReport(X)
profile.to_file(output_file="titanic.html")
ディレクトリにtitanic.htmlというレポートが生成されました。
私のマシンでは20秒程度かかりました。
結果の見方
レポートは5つのセクションに分かれています。
- Overview
- Variables
- Correlations
- Missing values
- Sample
Overview
文字通りデータの概要の情報を確認できます。
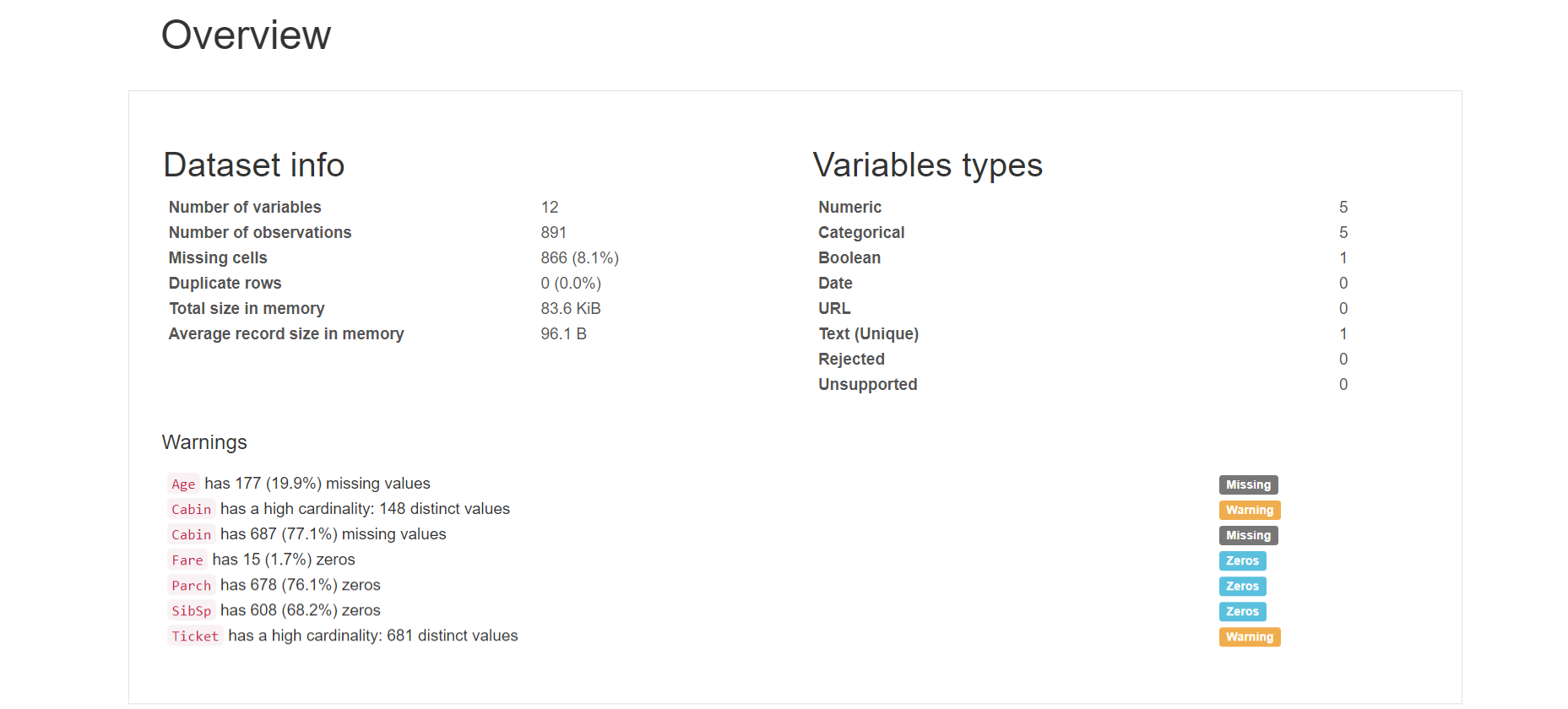
- Dataset infoでは、列数、行数、メモリ上でのデータサイズ、一行あたりの平均メモリ上データサイズなどを確認できます。
- Variables typesでは、変数タイプ毎に特徴量(列)数を集計しています。
- Warningsでは、注意が必要な列に関して示しています。ここでは、欠損値やゼロが含まれる列に関して教えてくれます。
- Cabin列に関して、「Cabin has a high cardinality: 148 distinct values」とありますが、cardinalityとは「カラムの値の種類の絶対数」を指し、「カラムの値の種類がレコード数に比べて多い」ことを意味しています。
Variables
このセクションでは、各特徴量の情報を確認できます。

- 変数タイプがNumericの場合にはヒストグラム、categoricalの場合にはラベル毎の頻度を示す棒グラフが表示されます。
- 注意が必要な個所が赤で示されます。
- 右下のToggle detailsをクリックすると、各変数についてさらに詳細な情報が確認できます。
- 個人的にはToggle detailsで異常値(extreme values)が表示されるのが便利と感じました。
Correlations
変数間の相関を確認できます。
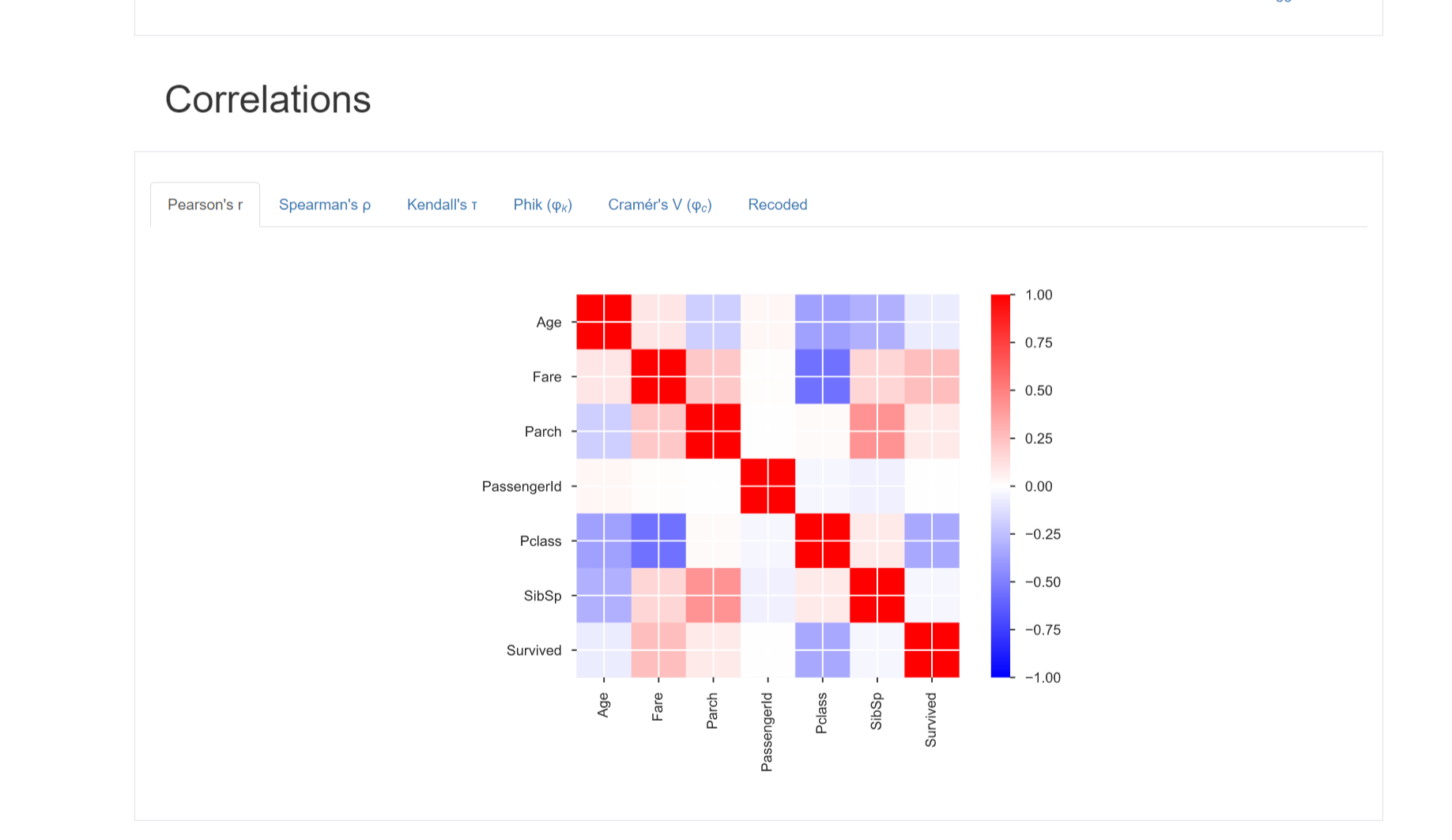
- ピアソンの積率相関係数に加え、タブを切り替えてスピアマンの順位相関係数、ケンドールの順位相関係数などのマトリクスを表示します。
Missing values
欠損値に関する情報を確認できます。
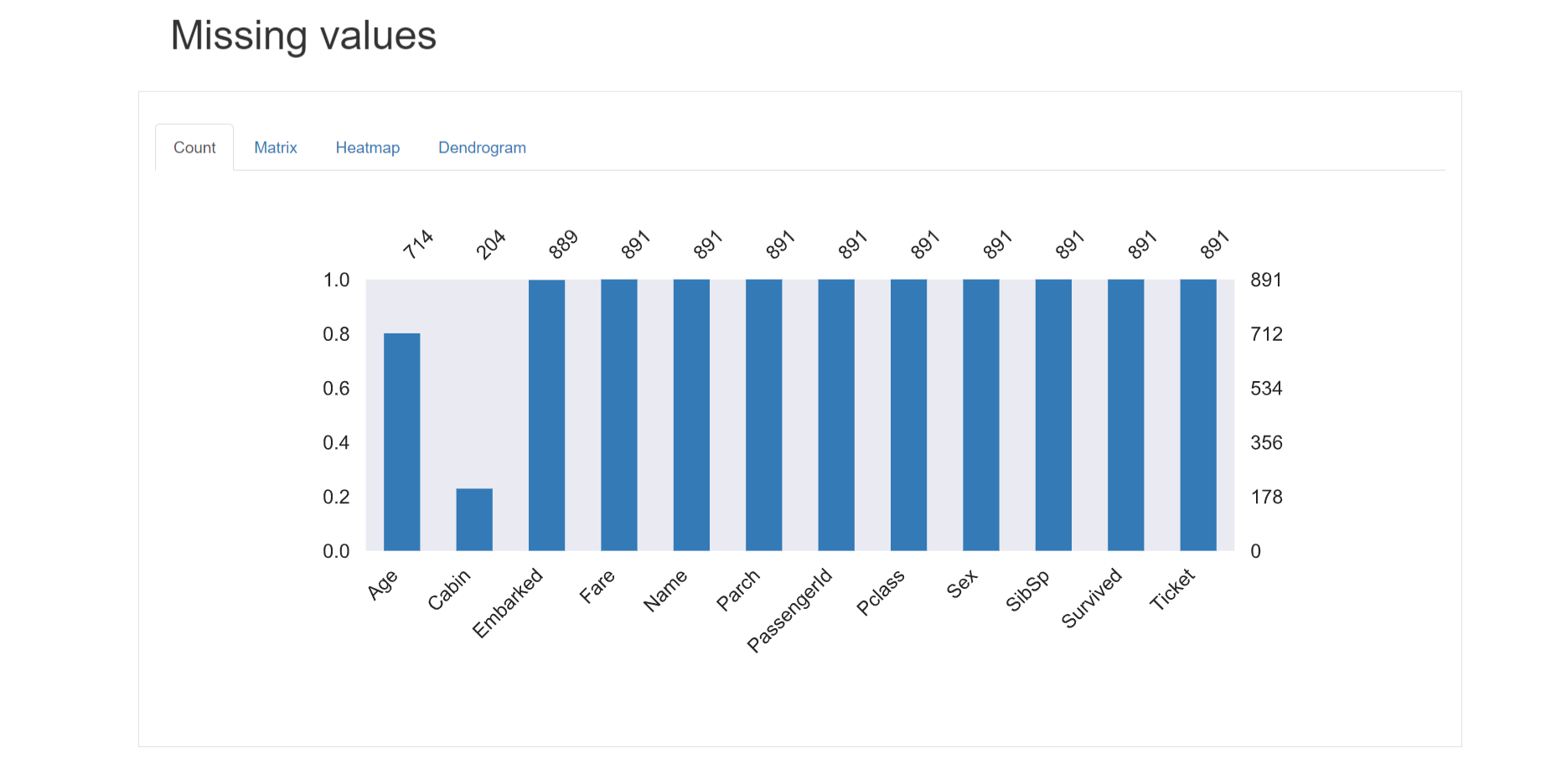
- Countタブで各列の欠損値数の棒グラフを表示
- Matrixでは欠損有無をセルの塗りつぶしで示した行列のマトリクスを表示
- Heatmapでは欠損がある列同士の欠損有無の相関を表示
- 欠損傾向が類似している列グループを示すデンドログラムを表示
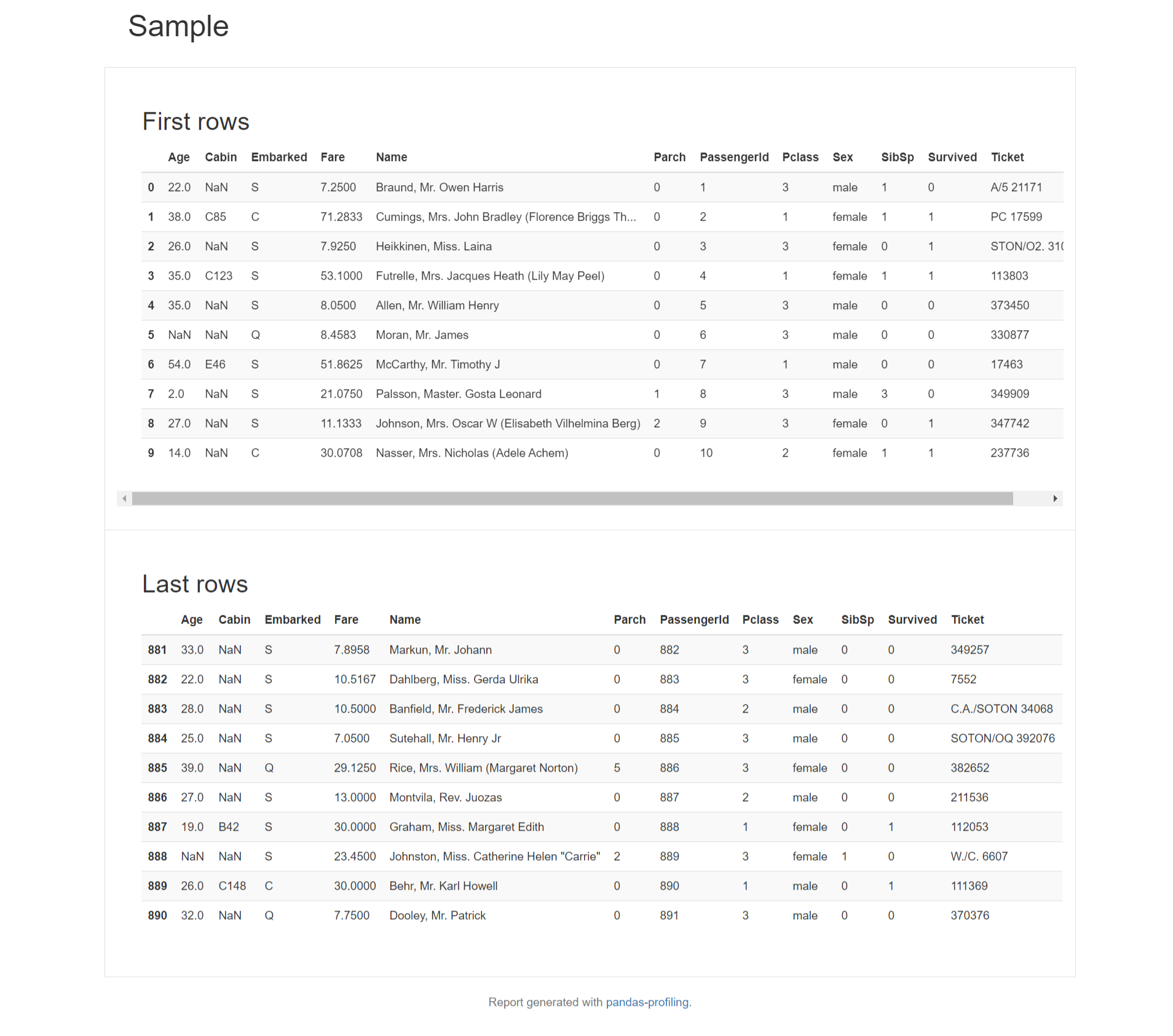
Sample
データの最初と最後の10件を表示できます。
非常に便利そうなライブラリなので、ぜひ活用したいと思います。