タイトルのとおりです。Googleで見つかる情報がバージョンが違うせいなのか、微妙に書式が違っていたりしたので、自分で実施した内容を初心者向けにまとめておきます。
やりたかったこと
私の雑記ブログで細かい動機は紹介しておりますが、
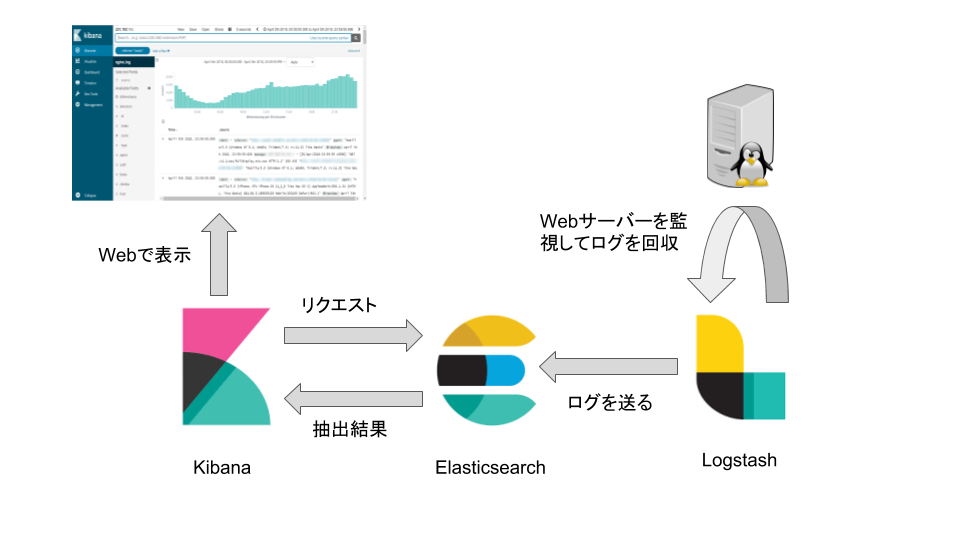
- VPS上のWebアクセスログを収集したい
- 収集したログのreferrerからドメインを抽出する
- そのドメインの件数を知りたい
ということが目的です。
環境
- CentOS 6.9
- nginx 1.10.2
- Logstash 6.2.3
- Elasticsearch 6.2.3
- Kibana 6.2.3
導入
インストール
RedHad系であればrpmパッケージでインストールできますが、そのためにはリポジトリの登録が必要です。/etc/yum.repos.dにファイルを作成します。
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[logstash-6.x]
name=Logstash repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-logstash
enabled=1
autorefresh=1
type=rpm-md
[kibana-6.x]
name=Kibana repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-kibana
enabled=1
autorefresh=1
type=rpm-md
インストールします。
$ yum install logstash
$ yum install elasticsearch
$ yum install kibana
設定
Logstash
/etc/logstash/conf.d に設定ファイルを作成します。
input {
file {
path => "/var/log/nginx/access.log"
start_position => beginning
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
locale => "en"
}
mutate {
replace => { "type" => "nginx_log" }
}
}
output {
elasticsearch {
hosts => ["localhost"]
index => "nginx_log"
}
}
input
入力ソースを指定します。start_positionのbeginningは「該当するファイルの先頭から読み込む」という意味です。endを指定すると、Logstash起動後に書き込まれたものが対象になります。
filter
読み込んだログの抽出・変換などの条件を設定します。
grok はログのレコードをフィルタします。 match の書式に一致したレコードのみがElasticsearchに転送されます。grokの書式は以下のGitHubページを確認しましょう。
GitHub - grok-patterns
date はタイムスタンプを生成します。デフォルトではログの転送時間が設定されますが、それだと過去のログの時系列がメチャクチャになってしまうのでここで指定するのがベターでしょう。match に合致するログ内の値をフィールド**@timestamp**に設定します。
mutate は値の変換とかいろいろやってくれます。今回はtypeというフィールドの値を固定で設定していますが、さほど意味はありません。
output
elasticsearch にログの転送先となるElasticsearchサーバーの情報を指定します。hosts に配列形式でホスト名を、index にElasticsearchで使われるIndexパターンを指定します。index を指定しない場合はデフォルト値logstashが設定されます。
Elasticsearch
単純な使い方であれば特に設定変更の必要は無いと思います。強いて挙げるとすればバインドアドレスとポートの設定ぐらいでしょうか。
……
network.host: 127.0.0.1 #指定しない場合はおそらく0.0.0.0
http.port:9200 #デフォルトポートは9200
……
Kibana
外部(Webブラウザ)から接続を受け付けるためのホスト名と、接続先ElasticsearchのURLが主な設定項目です。
……
server.host: "www.mydomain.ne.jp" #デフォルトはlocalhost
server.port: 5601 #デフォルト5601
elasticsearch.url: "http://localhost:9200" #接続するElasticsearchのURL
……
起動
Logstashだけ初期起動用のスクリプトがありませんでした。また、複数のログを収集したい時にどうするのかは良く分かっていませんがpipelines.ymlをゴニョゴニョするのかなと思っています。
$ /etc/init.d/elasticsearch start
$ /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/nginx.conf &
$ /etc/init.d/kibana start
Kibanaによるログの可視化
ここまでくればhttp://www.mydomain.ne.jp:5601とかでKibanaにアクセスできます。
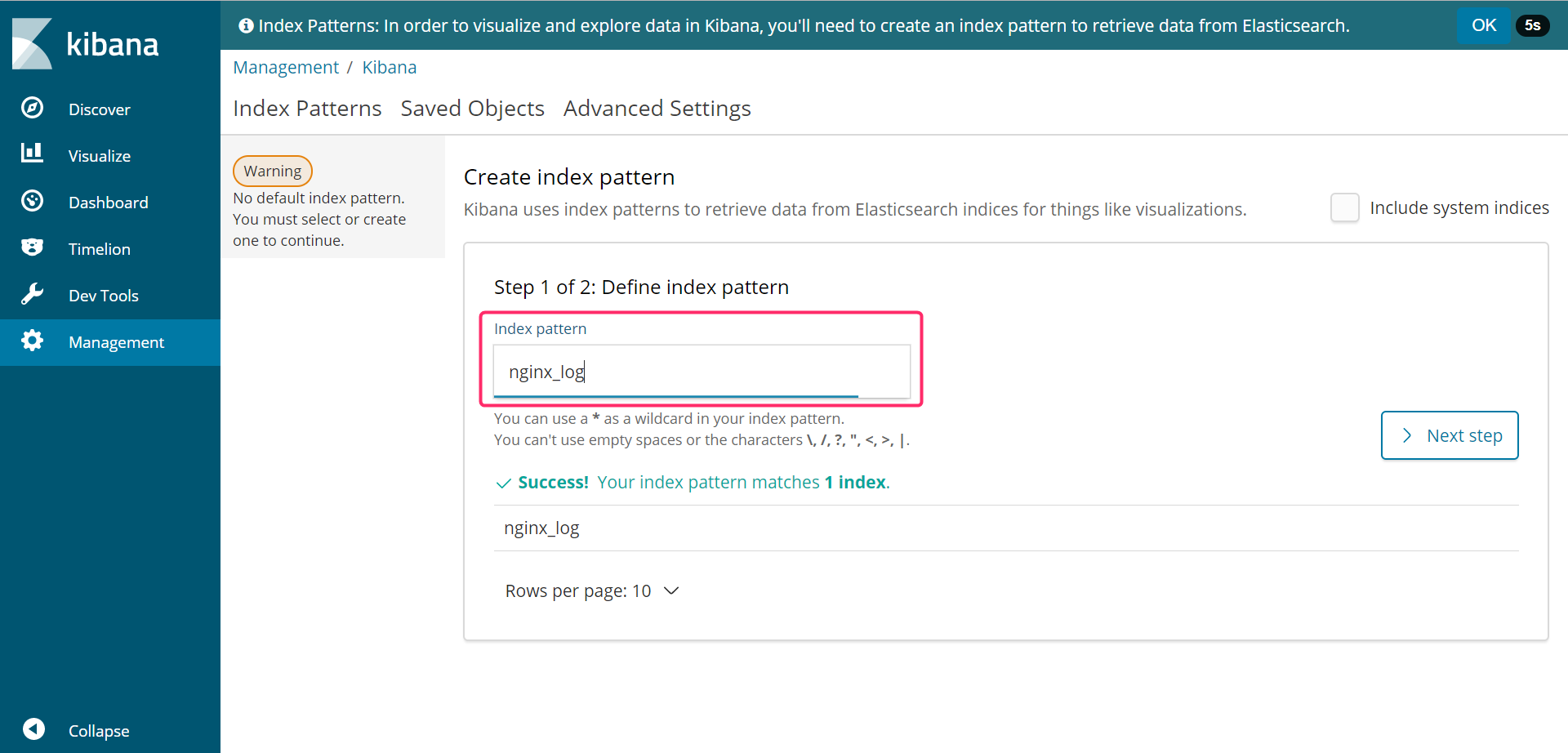
初期設定
が、デフォルトのインデックスパターンを定義する必要があります。これは実際にElasticsearchに蓄積されているインデックスパターンのみ指定可能なため、必ずElasticsearch→Logstashの順に起動してから設定しましょう。
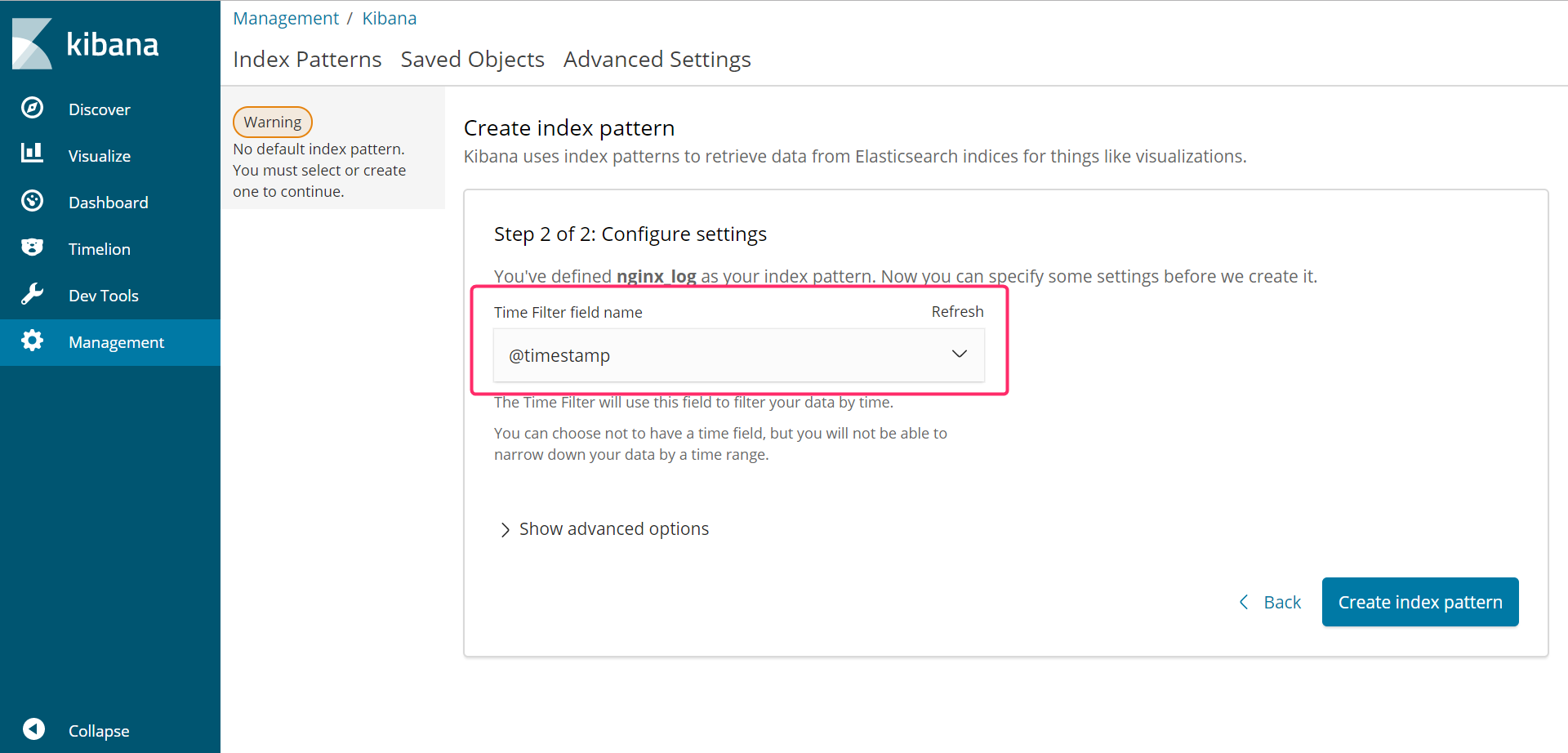
さらにログ可視化の時間軸とするフィールドを選択します。基本は**@timestamp**で良いと思います。
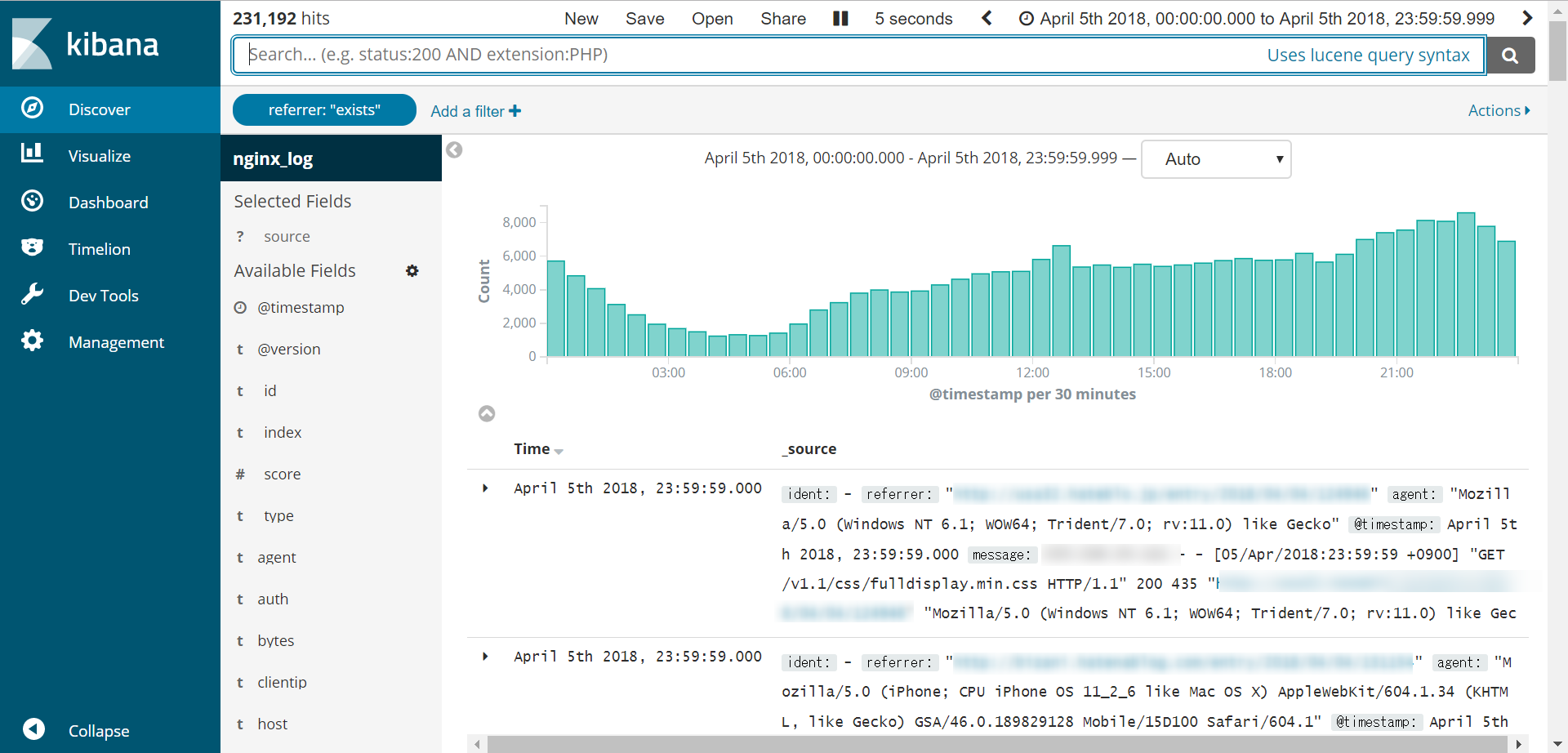
Discoverで確認
これで時間帯ごとのアクセス数とログ1件ずつの内容がDiscoverに表示されます!
scripted fieldsでフィールドを整形
Elasticsearchではpainlessまたはexpressionというスクリプト言語を使い、**格納されたログのフィールドを整形することができます。**ただしexpressionは次のメジャーバージョンで削除される予定なので、painlessを利用するのが無難でしょう。
painlessはJavaに似た言語仕様となっているようです。ElasticのページにAPIリファレンスが掲載されています。
Appendix A. Painless API Reference
今回はScript Fieldsを使ってreferrerからドメイン部分を抽出してみます。
Kibanaの**「Management」→「scripted fields」を選択し、「Add Scripted Field」**を選択します。
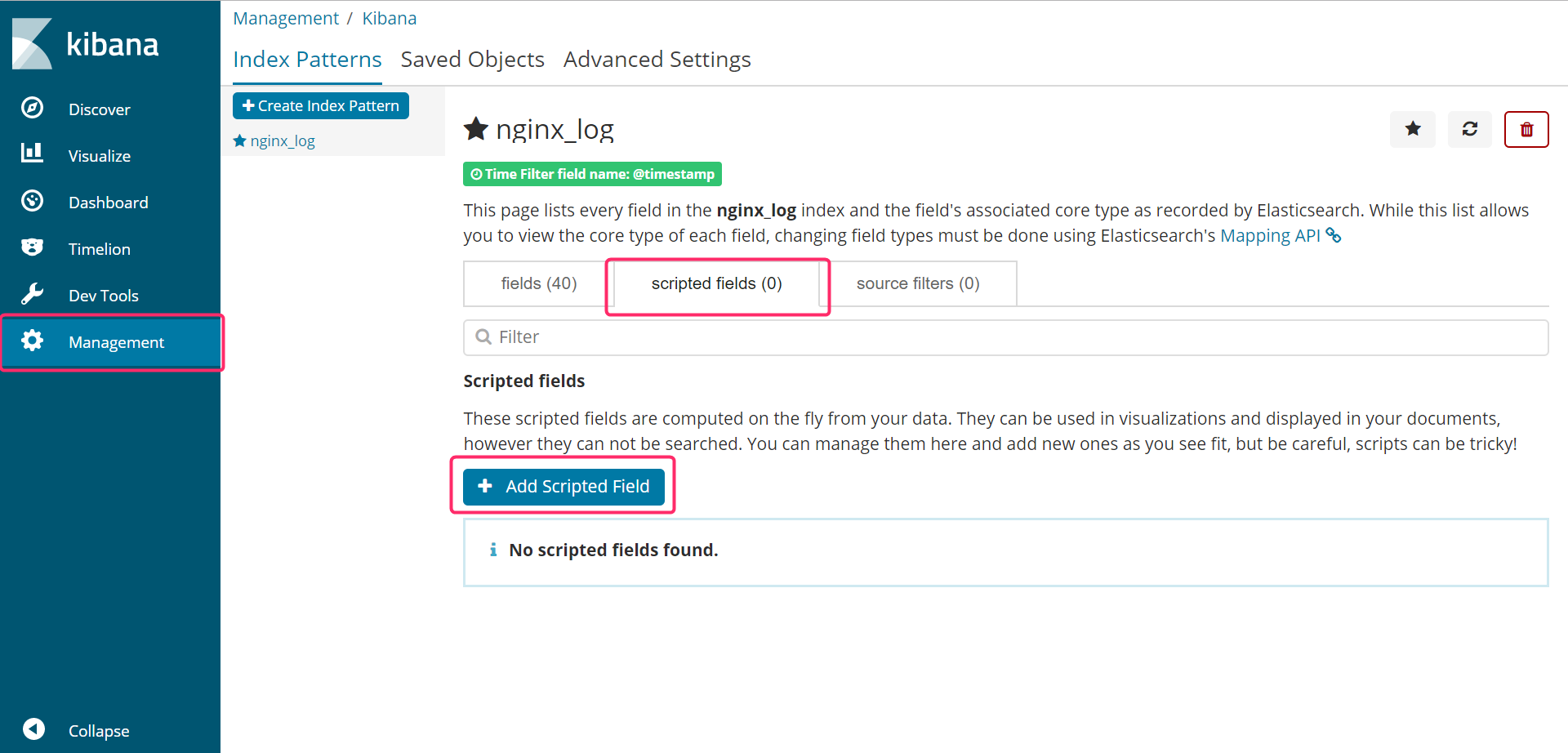
フォームが表示されるので必要な設定を行います。主な項目はname language format scriptです。
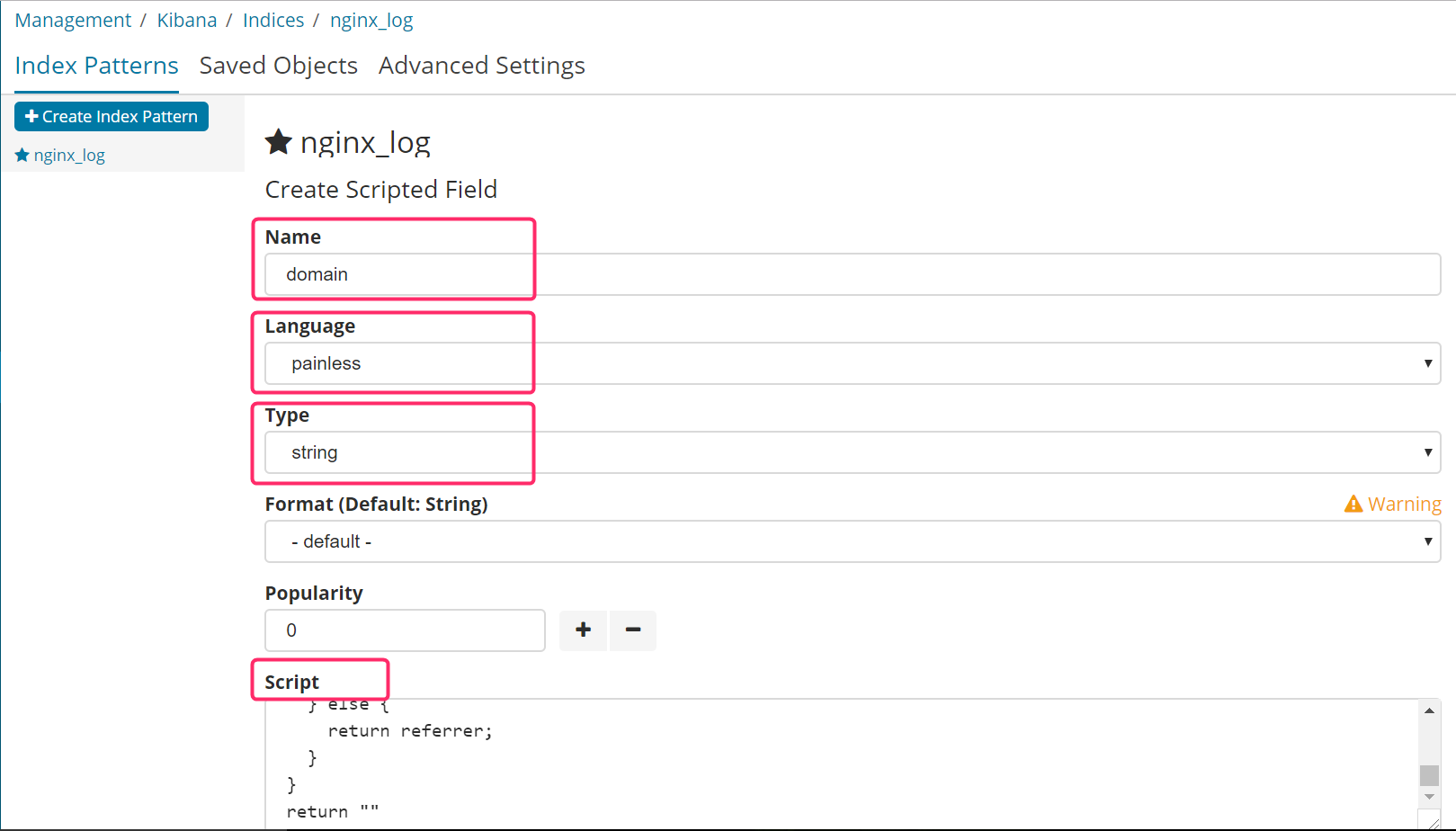
nameは抽出結果に与えるフィールドの名称を設定します。ここではdomainとします。languageはpainlessを選択します。format はスクリプトが返す値の型を設定します。string、date、numberなどがあります。
script にスクリプトをコーディングします。今回は「http://」または「https://」 から次の「/」までの文字列を抽出します。
def referrer = doc['referrer.keyword'].value;
if(referrer!=null){
int index = -1;
if(referrer.indexOf("http://") == 1) {
index = referrer.indexOf("/",8);
}else if(referrer.indexOf("https://") == 1) {
index = referrer.indexOf("/",9);
}
if(index > 0) {
return referrer.substring(0,index);
} else {
return referrer;
}
}
return ""
特に特筆すべき点も無い(私も雰囲気で書いている)ですが、留意点は以下の点でしょうか。
- Elasticsearch内のフィールド値は
doc[`フィールド名`].valueで取得します。 - フィールド値に付いている
keywordは、string属性の値を全文一致で検索するという指定属性らしいです。(この部分については、よく分かっていません) - painlessからstring属性の値を取得したところ、1文字目に「\」が入っていたため、indexOf周りの判定は1文字目からカウントしています。
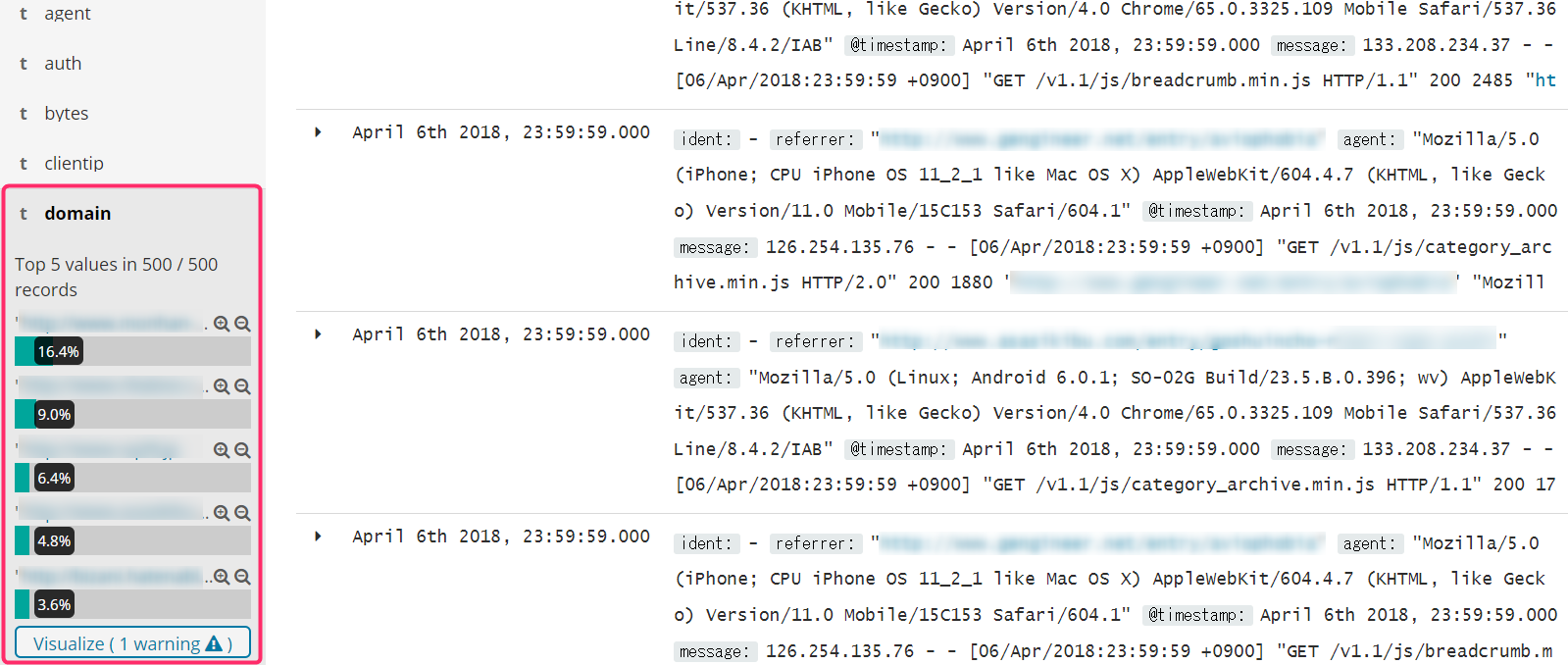
最後に一番下のCreate Fieldを実行して、Discoverを見てみるとフィールドdomain が追加されています。
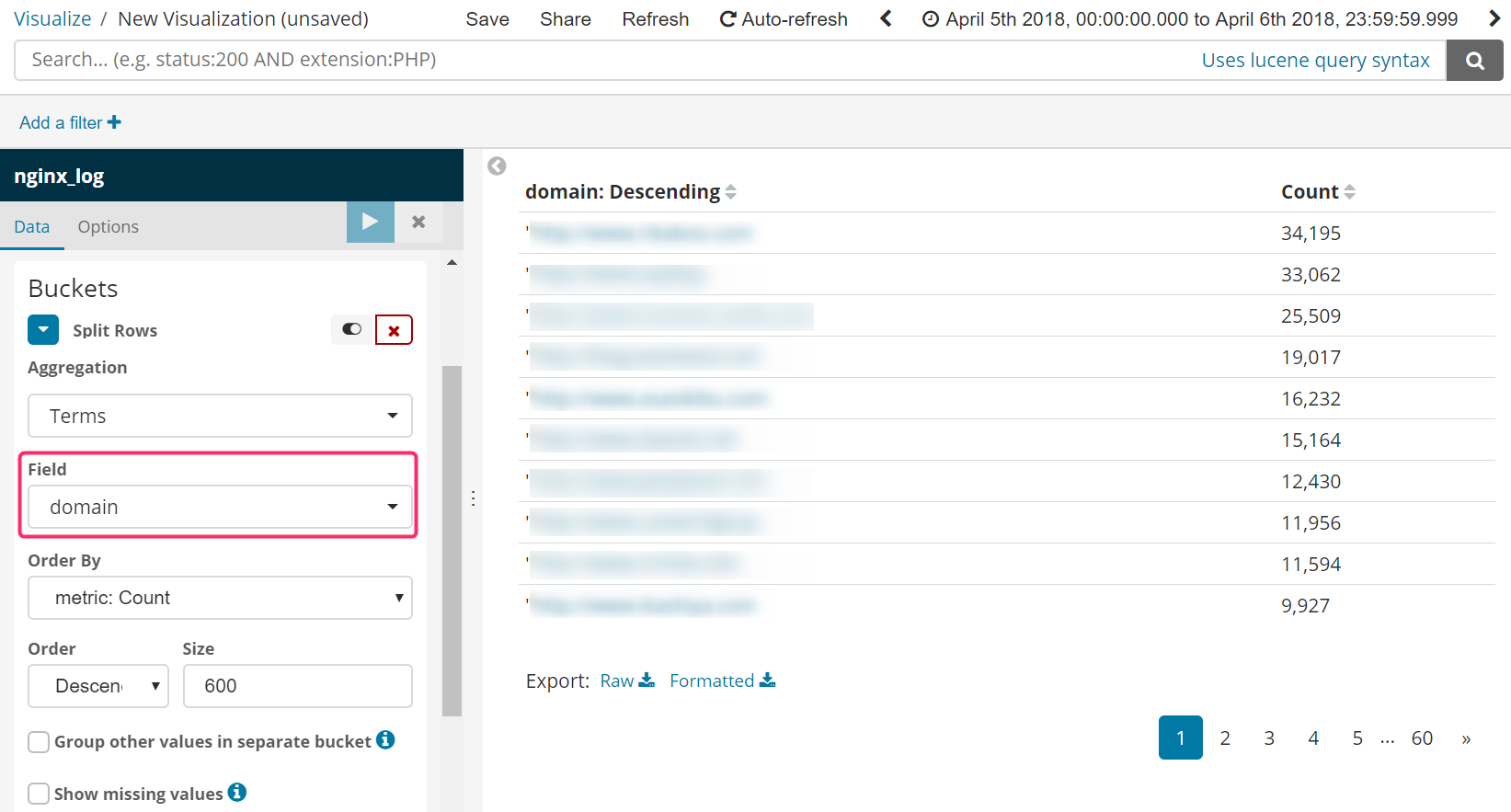
Visualize
あとはこのdomainを使って好きにVisualizeすることができます。ただし現時点の私はVisualizeで値のユニーク数をカウントさせる方法を知りません。Data Tableを使って**「1ページあたりの表示数×ページ数」**を確認するというイマイチな方法になってしまいました。
おまけ:KibanaのアクセスをBasic認証する
よくよく考えると自分のPCからサーバー上のKibanaへのアクセスは、Kibanaのポートがフルオープンになってしまいます。しかし残念ながら無料版のKibanaには認証機能が付いていません。
そこでKibanaにWebサーバー(nginx)経由でアクセスし、その際にBasic認証で自分以外がアクセスできないように設定してみます。
まずはBasic認証用にユーザー名とパスワードの組み合わせファイルを作成します。
# apr1はハッシュ関数の指定
$ echo "ユーザー名:$(openssl passwd -apr1 パスワード)" > /etc/nginx/.httpasswd
次にnginxのconfファイルを作成します。
server {
listen 8000; # 任意のポート
server_name www.mydomain.ne.jp;
access_log /var/log/nginx/kibana_access_log;
error_log /var/log/nginx/kibana_error_log;
auth_basic "Enter your ID and password.";
auth_basic_user_file "/etc/nginx/.htpasswd"; #作成したパスワードファイル
location / {
#外部からの接続を遮断するためにKibanaのサーバ名をlocalhostに変更
proxy_pass http://localhost:5601/;
}
}
最後にKibanaのサーバ名をlocalhostに変更して再起動します。
……
server.host: "localhost"
……
$ /etc/init.d/kibana restart
$ service nginx reload
これで外部からKibanaへの接続はポート8000のみで可能 & Basic認証が必須になりました。
ただし本格運用であればSSLによる認証を検討すべきでしょうから、あくまで自己責任でお願いします。