機械学習において、カテゴリーデータなど文字列のデータは数値データへ直さなければ機械学習モデルに入れることができません。また、数値データでも順序尺度でないデータはカテゴリー変数として扱うべきです。本記事では、カテゴリー変数を機械が理解できる形に直す手法を紹介します。
今回はポケモンと旅する特徴量エンジニアリング-数値編-の時と同様にポケモンのデータセットを利用します。
ライブラリーの読み込み
import pandas as pd
from sklearn.feature_extraction import FeatureHasher
データ読み込み
df = pd.read_csv('./data/121_280_bundle_archive.zip')
df.head()
データ
| # | Name | Type 1 | Type 2 | Total | HP | Attack | Defense | Sp. Atk | Sp. Def | Speed | Generation | Legendary |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Bulbasaur | Grass | Poison | 318 | 45 | 49 | 49 | 65 | 65 | 45 | 1 | False |
| 2 | Ivysaur | Grass | Poison | 405 | 60 | 62 | 63 | 80 | 80 | 60 | 1 | False |
| 3 | Venusaur | Grass | Poison | 525 | 80 | 82 | 83 | 100 | 100 | 80 | 1 | False |
| 3 | VenusaurMega Venusaur | Grass | Poison | 625 | 80 | 100 | 123 | 122 | 120 | 80 | 1 | False |
| 4 | Charmander | Fire | NaN | 309 | 39 | 52 | 43 | 60 | 50 | 65 | 1 | False |
ダミーエンコーディング
ダミーエンコーディングは特徴量エンジニアリングにおいて、カテゴリー変数を扱う時、最も人気&頻繁に登場する手法です。各カテゴリー変数を0, 1のビットで表現します。カテゴリー値をが該当する部分のビットは1となり、該当しない部分のビットは0となります。
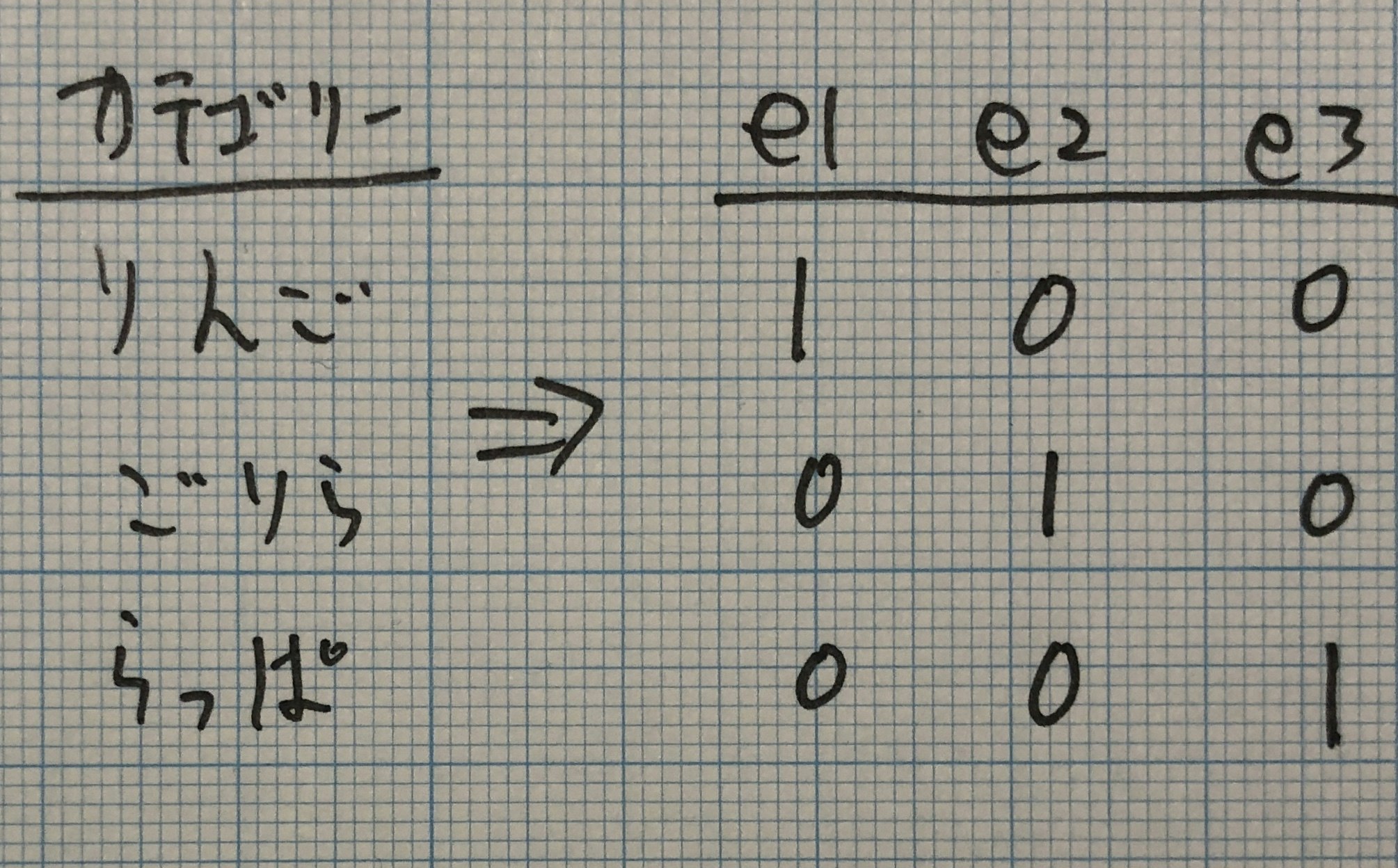
pandasにはダミーエンコーディングを簡単に関数があります。コードを見ていきましょう。
# One-hot Encoding
gdm = pd.get_dummies(df['Type 1'])
gdm = pd.concat([df['Name'], gdm], axis=1)
Bulbasaur(フシギダネ)のGrass(草)タイプに該当するビットが1になっている事を確認できます。
| Name | Bug | Dark | Dragon | Electric | Fairy | Fighting | Fire | Flying | Ghost | Grass | Ground | Ice | Normal | Poison | Psychic | Rock | Steel | Water |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bulbasaur | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Ivysaur | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Venusaur | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| VenusaurMega Venusaur | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Charmander | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
ラベルエンコーディング
ダミーエンコーディングは0, 1のビットで表現してたのですが、ラベルエンコーディングは整数で表現します。
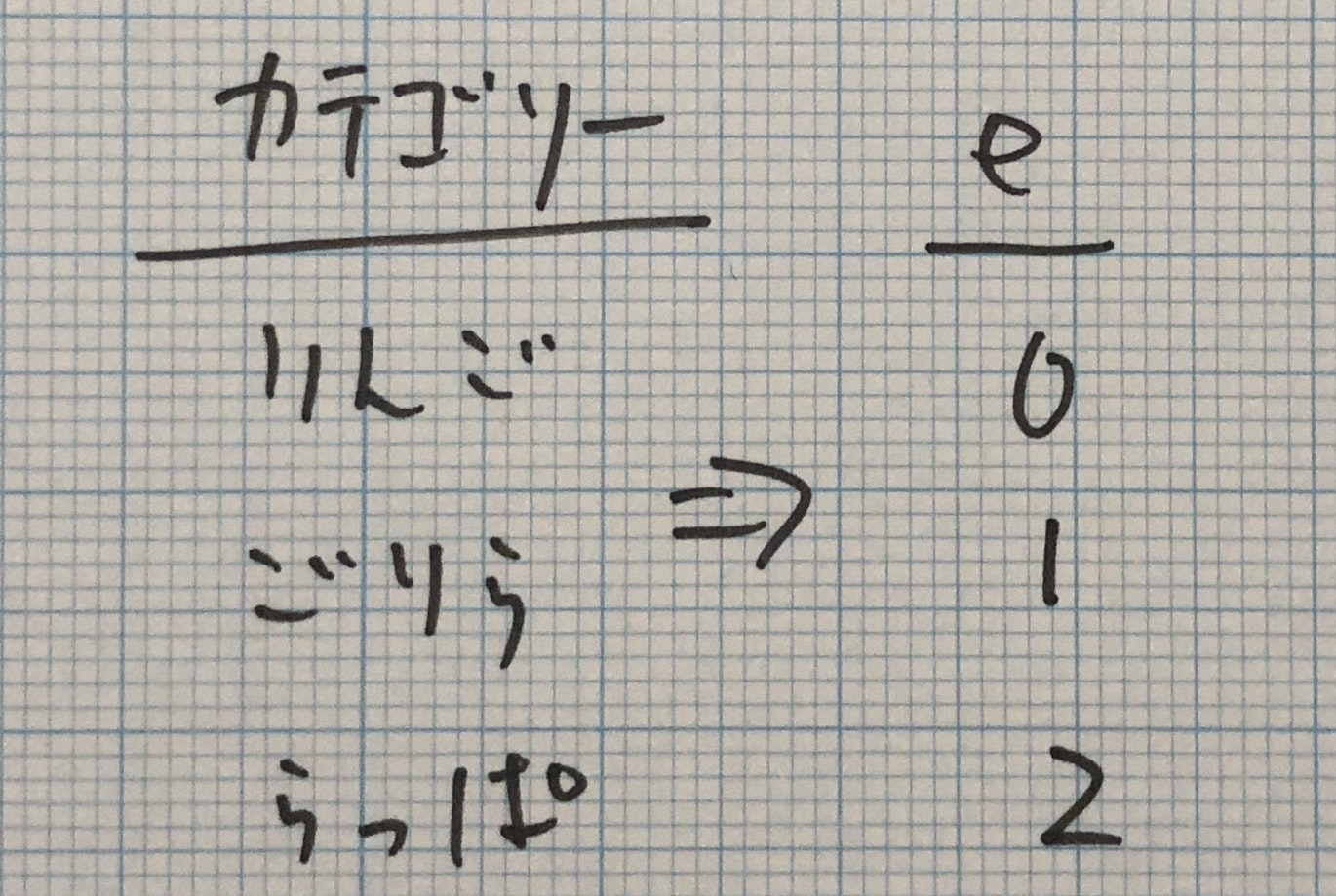
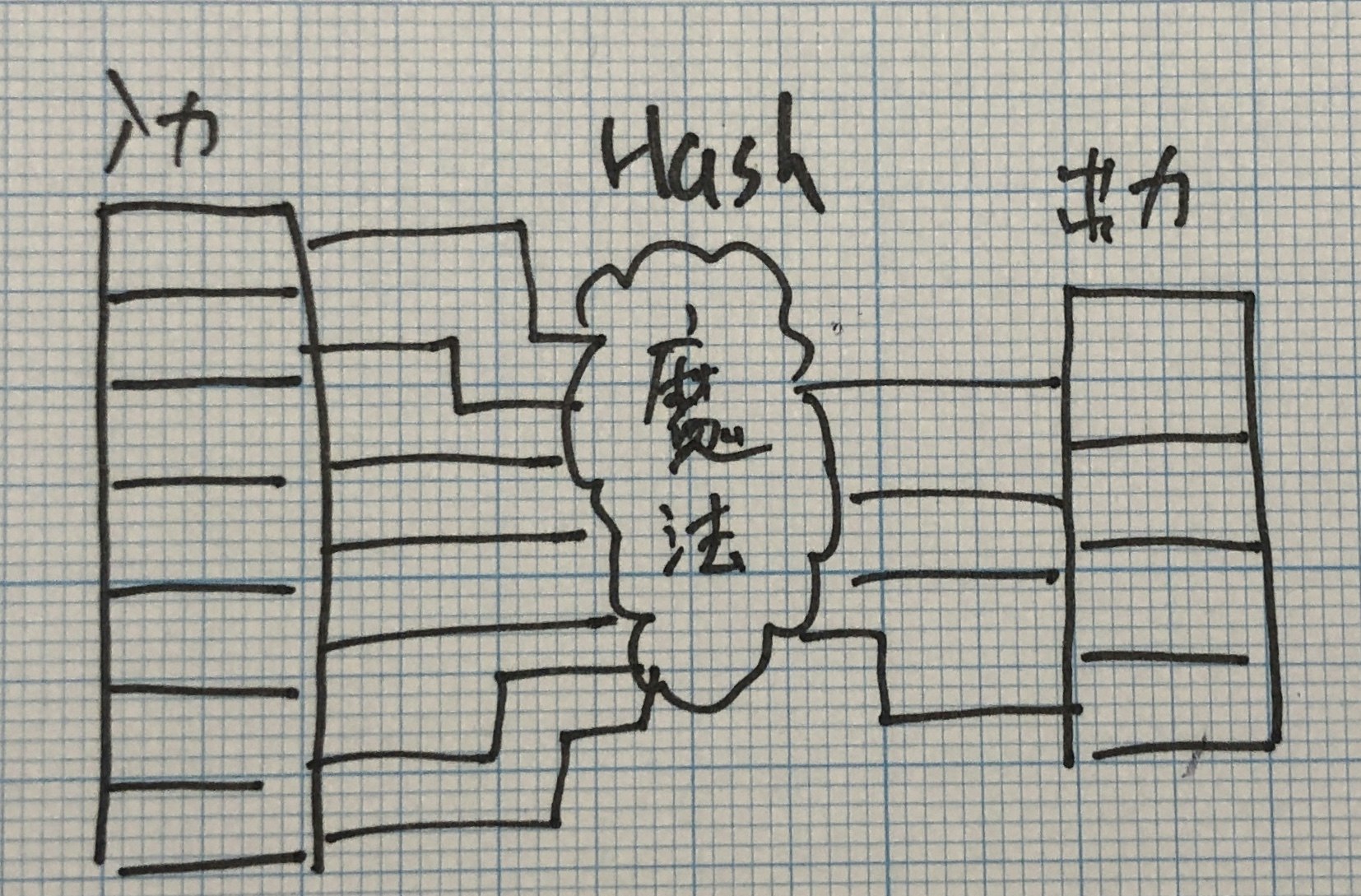
特徴量ハッシング
特徴量ハッシングと今までの変換の違いは、特徴量ハッシングは変換後のカテゴリー数が少なくなることです。ハッシュ関数という魔法の関数を利用することで、入力された特徴数を減らすイメージして頂ければ問題ないです。 どんな勉強もイメージで覚えたほうが頭に入りやすいですからね。
コードを見ていきましょう。sklearnにはFeatureHasherモジュールがありますので、これを利用しましょう。ポケモンのタイプを特徴量ハッシングで5つに絞っていきます。
「こんなのどんな時に使うんや!」と思うかもしれませんね。通常はカテゴリー変数が多すぎる時に使うと覚えてください。
fh = FeatureHasher(n_features=5, input_type='string')
hash_table = pd.DataFrame(fh.transform(df['Type 1']).todense())
変換後の特徴量
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 2 | 0 | 0 | 0 | -1 |
| 2 | 0 | 0 | 0 | -1 |
| 2 | 0 | 0 | 0 | -1 |
| 2 | 0 | 0 | 0 | -1 |
| 1 | -1 | 0 | -1 | 1 |
さいごに
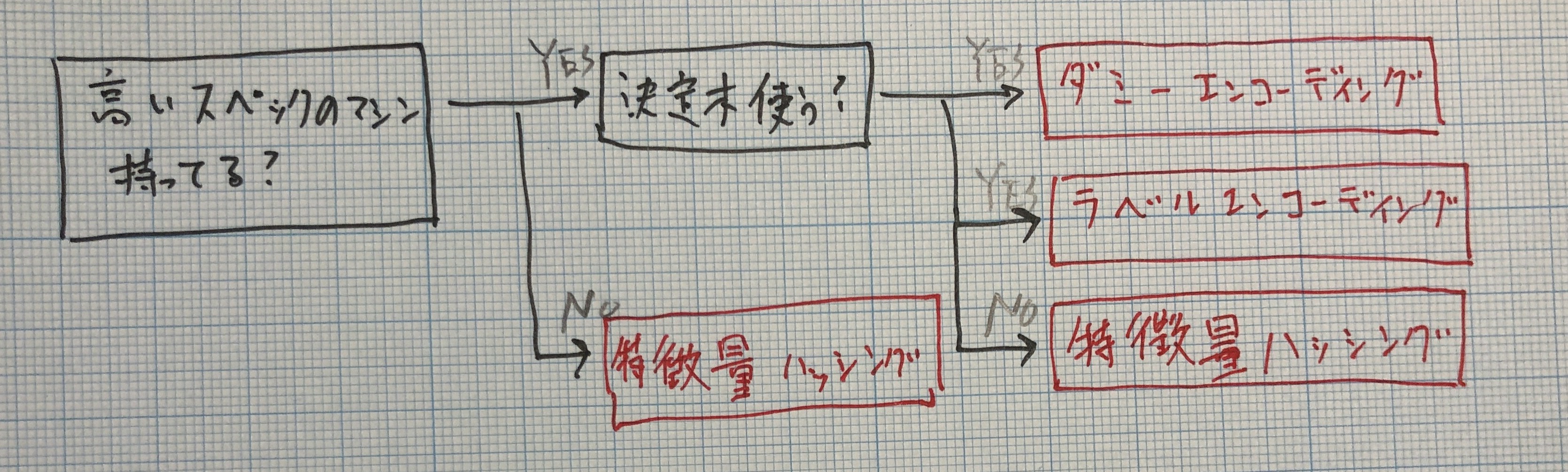
これらの手法はどんな時にどれを選べば良いでしょうか?一つの答えとして、分析用の計算機のスペックによって手法を使い分ける事があります。ダミーエンコーディングやラベルエンコーディングはシンプルな一方、カテゴリー変数が多すぎるとメモリーエラーを起こしたり可能性があります。その時は特徴量を圧縮する特徴量ハッシングを検討しても良いかもしれません。
ただし、最近は高スペックの計算機が無料で利用できるようになってきていますし、Kaggleで多く利用されている決定木モデルであるGBDTはラベルエンコーディングを処理できます。特徴量ハッシングの出番はそこまで大きくないと考えられます。