前書き
最近Kaggleのタイタニックコンペでデータ分析の学習に取り組み始めましたが、
pandasの使い方がどうしてもおぼつかない状態でした。
そのため、諸先輩方のKernelを参考によく使いそうな操作を繰り返して身体に染み込ませることにしました。
まずはタイタニックコンペのチュートリアル的なKernelを一つこなすなどして、
ある程度pandasを動かしてからご利用いただければと思います。
また、本記事はPythonインタープリタで実施することを想定しています。
記事中の解答例とは違う方法でも全く問題ございません。
より楽な方法、より一般的な方法がございましたら教えていただけますととてもありがたいです。
0.はじめに
pandasをimportしておく
.py
import pandas as pd
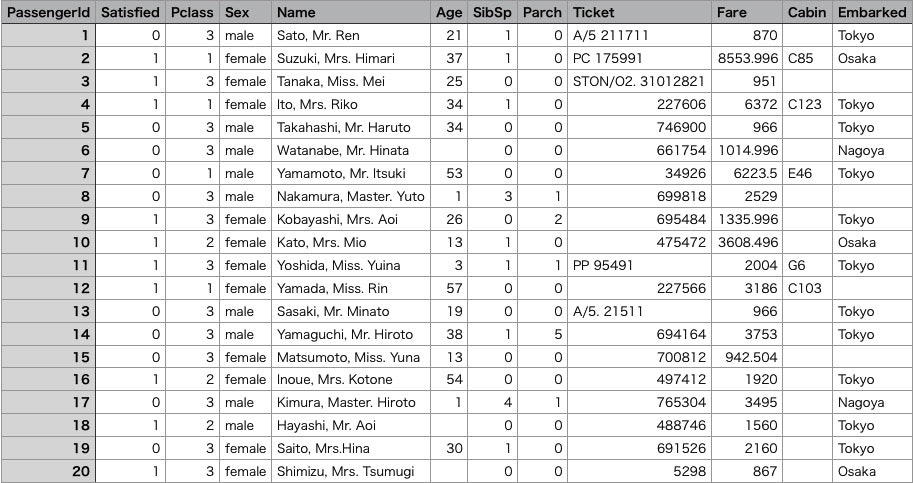
以下のファイルを使用するのでダウンロードしておく。
pandas_train.csv (Googleドライブ)
※KaggleのタイタニックコンペのCSVファイルを適当に架空の情報に書き換えました。
Titanic: Machine Learning from Disaster | Kaggle
実行環境
$ python3 --version
Python 3.6.5
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.14.5
$ pip3 show pandas
Name: pandas
Version: 0.24.2
1.新しいDataFrameを作る
1-1.以下のdf_sampleという名前のDataFrameを作成する
| A | B | C | D | |
|---|---|---|---|---|
| 0 | a | aa | aaa | aaaa |
| 1 | b | bb | bbb | bbbb |
| 2 | c | cc | ccc | cccc |
| 3 | d | dd | ddd | dddd |
| 4 | e | ee | eee | eeee |
回答1-1
1-1.py
df_sample = pd.DataFrame({ "A" : ["a","b","c","d","e"],
"B" : ["aa","bb","cc","dd","ee"],
"C" : ["aaa","bbb","ccc","ddd","eee"],
"D" : ["aaaa","bbbb","cccc","dddd","eeee"]})
# >>> df_sample
# A B C D
# 0 a aa aaa aaaa
# 1 b bb bbb bbbb
# 2 c cc ccc cccc
# 3 d dd ddd dddd
# 4 e ee eee eeee
2.あるCSVファイルを操作する
以下のファイルを使用する。
pandas_train.csv (Googleドライブ)
2-1. pandas_train.csvを読み込んで変数dfに格納する
回答2-1
2-1.py
df = pd.read_csv("{ファイルパス}/pandas_train.csv")
2-2. 2-1でdfに格納したデータをpandas_train2.csvというファイル名で出力する
回答2-2
2-2.py
df.to_csv("{ファイルパス}/pandas_train2.csv")
2-3. pandas_train.csv内のSatisfied列を全て0に変更する
回答2-3
2-3.py
df["Satisfied"] = 0
# >>> df["Satisfied"]
# 0 0
# 1 0
# 2 0
# 3 0
# 4 0
# 5 0
# 6 0
# 7 0
# 8 0
# 9 0
# 10 0
# 11 0
# 12 0
# 13 0
# 14 0
# 15 0
# 16 0
# 17 0
# 18 0
# 19 0
# Name: Satisfied, dtype: int64
2-4. Age列を数値で4等分にビン分割してAgeBinという列を作成する
回答2-4
2-4.py
df["AgeBin"] = pd.cut(df["Age"], 4)
# 4等分にした年齢層ごとのSatisfiedの数は以下のように表示される
# >>> pd.crosstab(df["AgeBin"],df["Satisfied"])
# Satisfied 0 1
# AgeBin
# (0.944, 15.0] 3 2
# (15.0, 29.0] 2 2
# (29.0, 43.0] 3 2
# (43.0, 57.0] 1 2
2-5. Fare列を人数で4等分にビン分割してFareBinという列を作成する
回答2-5
2-5.py
df["FareBin"] = pd.qcut(df["Fare"], 4)
2-6. Age列の欠損値をAge列の中央値で埋める
回答2-6
2-6.py
df["Age"].fillna(df["Age"].median(), inplace = True)
# >>> df["Age"].isnull().sum()
# 0
2-7. Embarked列の欠損値をEmbarked列の最頻値で埋める
回答2-7
2-7.py
df["Embarked"].fillna(["Embarked"].mode()[0], inplace = True)
# >>> df["Embarked"].isnull().sum()
# 0
2-8. PassengerId, Ticketという列を削除する
回答2-8
2-8.py
df.drop(["PassengerId", "Ticket"], axis=1, inplace=True)
# >>> df.columns
# Index(['Satisfied', 'Pclass', 'Sex', 'Name', 'Age', 'SibSp', 'Parch', 'Fare',
# 'Cabin', 'Embarked', 'AgeBin', 'FareBin'],
# dtype='object')
2-9. SibSp列の値とParch列の値の和に1を足した値を持つFamirySize列を作成する
回答2-9
2-9.py
df["FamilySize"] = df["SibSp"] + df["Parch"] + 1
# >>> df.loc[:,["FamilySize","SibSp","Parch"]]
# FamilySize SibSp Parch
# 0 2 1 0
# 1 2 1 0
# 2 1 0 0
# 3 2 1 0
# 4 1 0 0
# 5 1 0 0
# 6 1 0 0
# 7 5 3 1
# 8 3 0 2
# 9 2 1 0
# 10 3 1 1
# 11 1 0 0
# 12 1 0 0
# 13 7 1 5
# 14 1 0 0
# 15 1 0 0
# 16 6 4 1
# 17 1 0 0
# 18 2 1 0
# 19 1 0 0
2-10. 全て値が1のIsAlone列を作成し、2-9のFamilySize列が1より大きい行のみ0に変更する
回答2-10
2-10.py
df["IsAlone"] = 1
df["IsAlone"].loc[dataset["FamilySize"] > 1] = 0
# >>> df.loc[:,["IsAlone","FamilySize"]]
# IsAlone FamilySize
# 0 0 2
# 1 0 2
# 2 1 1
# 3 0 2
# 4 1 1
# 5 1 1
# 6 1 1
# 7 0 5
# 8 0 3
# 9 0 2
# 10 0 3
# 11 1 1
# 12 1 1
# 13 0 7
# 14 1 1
# 15 1 1
# 16 0 6
# 17 1 1
# 18 0 2
# 19 1 1
2-11. df内のSex列, Embarked列をone-hotエンコーディングに変更する
回答2-11
2-11.py
df = pd.get_dummies(df, columns=["Sex","Embarked"])
# >>> df.head(5)
# Satisfied Pclass Name Age SibSp Parch Fare Cabin FareBin FamilySize IsAlone Sex_female Sex_male Embarked_Nagoya Embarked_Osaka Embarked_Tokyo
# 0 0 3 Sato, Mr. Ren 21.0 1 0 870.000 NaN (866.999, 966.0] 2 0 0 1 0 0 1
# 1 1 1 Suzuki, Mrs. Himari 37.0 1 0 8553.996 C85 (3523.374, 8553.996] 2 0 1 0 0 1 0
# 2 1 3 Tanaka, Miss. Mei 25.0 0 0 951.000 NaN (866.999, 966.0] 1 1 1 0 0 0 1
# 3 1 1 Ito, Mrs. Riko 34.0 1 0 6372.000 C123 (3523.374, 8553.996] 2 0 1 0 0 0 1
# 4 0 3 Takahashi, Mr. Haruto 34.0 0 0 966.000 NaN (866.999, 966.0] 1 1 0 1 0 0 1
2-12. df内のSatisfied列以外を取り出してdf_1, Satisfied列とName列だけを取り出してdf_2という新しいDataframeを作成する
回答2-12
2-12.py
df_1 = df.drop(["Satisfied"], axis = 1)
# >>> df_1.head(5)
# Pclass Name Age SibSp Parch Fare Cabin AgeBin FareBin FamilySize IsAlone Sex_female Sex_male Embarked_Nagoya Embarked_Osaka Embarked_Tokyo
# 0 3 Sato, Mr. Ren 21.0 1 0 870.000 NaN (15.0, 29.0] (866.999, 966.0] 2 0 0 1 0 0 1
# 1 1 Suzuki, Mrs. Himari 37.0 1 0 8553.996 C85 (29.0, 43.0] (3523.374, 8553.996] 2 0 1 0 0 1 0
# 2 3 Tanaka, Miss. Mei 25.0 0 0 951.000 NaN (15.0, 29.0] (866.999, 966.0] 1 1 1 0 0 0 1
# 3 1 Ito, Mrs. Riko 34.0 1 0 6372.000 C123 (29.0, 43.0] (3523.374, 8553.996] 2 0 1 0 0 0 1
# 4 3 Takahashi, Mr. Haruto 34.0 0 0 966.000 NaN (29.0, 43.0] (866.999, 966.0] 1 1 0 1 0 0 1
df_2 = df[["Satisfied","Name"]]
# >>> df_2.head(5)
# Satisfied Name
# 0 0 Sato, Mr. Ren
# 1 0 Suzuki, Mrs. Himari
# 2 0 Tanaka, Miss. Mei
# 3 0 Ito, Mrs. Riko
# 4 0 Takahashi, Mr. Haruto
3.CSVファイルの情報を確認する
pandas_train.csvをdfに格納しなおしてから実施します。
.py
df = pd.read_csv("{ファイルパス}/pandas_train.csv")
3-1. dfの行数と列数を表示する
回答3-1
3-1.py
df.shape
# (20, 12)
3-2. dfの列の名前の一覧を表示する
回答3-2
3-2.py
df.columns
# Index(['PassengerId', 'Satisfied', 'Pclass', 'Sex', 'Name', 'Age', 'SibSp',
# 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
# dtype='object')
3-3. dfの各列の欠損値でないデータの数とデータの型を表示する
回答3-3
3-3.py
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 20 entries, 0 to 19
# Data columns (total 12 columns):
# PassengerId 20 non-null int64
# Satisfied 20 non-null int64
# Pclass 20 non-null int64
# Sex 20 non-null object
# Name 20 non-null object
# Age 17 non-null float64
# SibSp 20 non-null int64
# Parch 20 non-null int64
# Ticket 20 non-null object
# Fare 20 non-null float64
# Cabin 5 non-null object
# Embarked 16 non-null object
# dtypes: float64(2), int64(5), object(5)
3-4. dfの各列の欠損値の数を表示する
回答3-4
3-4.py
df.isnull().sum()
# PassengerId 0
# Satisfied 0
# Pclass 0
# Sex 0
# Name 0
# Age 3
# SibSp 0
# Parch 0
# Ticket 0
# Fare 0
# Cabin 15
# Embarked 4
# dtype: int64
3-5. dfの各数値データの要約統計量を表示する
回答3-5
3-5.py
df.describe()
# PassengerId Satisfied Pclass Age SibSp Parch Fare
# count 20.00000 20.000000 20.000000 17.000000 20.000000 20.000000 20.000000
# mean 10.50000 0.500000 2.450000 27.000000 0.700000 0.500000 2663.924400
# std 5.91608 0.512989 0.825578 17.779904 1.080935 1.192079 2167.066511
# min 1.00000 0.000000 1.000000 1.000000 0.000000 0.000000 867.000000
# 25% 5.75000 0.000000 2.000000 13.000000 0.000000 0.000000 966.000000
# 50% 10.50000 0.500000 3.000000 26.000000 0.000000 0.000000 1962.000000
# 75% 15.25000 1.000000 3.000000 37.000000 1.000000 0.250000 3523.374000
# max 20.00000 1.000000 3.000000 57.000000 4.000000 5.000000 8553.996000
3-6. dfの各数値データの要約統計量を10%刻みで表示する
回答3-6
3-6.py
df.describe(percentiles=[.1,.2,.3,.4,.5,.6,.7,.8,.9])
# PassengerId Satisfied Pclass Age SibSp Parch Fare
# count 20.00000 20.000000 20.000000 17.000000 20.000000 20.000000 20.000000
# mean 10.50000 0.500000 2.450000 27.000000 0.700000 0.500000 2663.924400
# std 5.91608 0.512989 0.825578 17.779904 1.080935 1.192079 2167.066511
# min 1.00000 0.000000 1.000000 1.000000 0.000000 0.000000 867.000000
# 10% 2.90000 0.000000 1.000000 2.200000 0.000000 0.000000 935.253600
# 20% 4.80000 0.000000 1.800000 13.000000 0.000000 0.000000 963.000000
# 30% 6.70000 0.000000 2.000000 17.800000 0.000000 0.000000 1000.297200
# 40% 8.60000 0.000000 3.000000 22.600000 0.000000 0.000000 1470.398400
# 50% 10.50000 0.500000 3.000000 26.000000 0.000000 0.000000 1962.000000
# 60% 12.40000 1.000000 3.000000 32.400000 1.000000 0.000000 2307.600000
# 70% 14.30000 1.000000 3.000000 34.600000 1.000000 0.000000 3278.700000
# 80% 16.20000 1.000000 3.000000 37.800000 1.000000 1.000000 3637.396800
# 90% 18.10000 1.000000 3.000000 53.400000 1.200000 1.100000 6238.350000
# max 20.00000 1.000000 3.000000 57.000000 4.000000 5.000000 8553.996000
3-7. dfの各オブジェクト型データの要素数、ユニーク数、最頻値、最頻値の出現回数を表示
回答3-7
3-7.py
df.describe(include="O")
# Sex Name Ticket Cabin Embarked
# count 20 20 20 5 16
# unique 2 20 20 5 3
# top female Shimizu, Mrs. Tsumugi PP 95491 G6 Tokyo
# freq 11 1 1 1 11
3-8. dfのSatisfied列で0の数と1の数を表示した後、0の割合と1の割合を表示
回答3-8
3-8.py
df["Satisfied"].value_counts()
# 1 10
# 0 10
# Name: Satisfied, dtype: int64
df["Satisfied"].value_counts()/len(df["Satisfied"])
# 1 0.5
# 0 0.5
# Name: Satisfied, dtype: float64
3-9. 男女別のSatisfiedの0と1の数と割合をクロス集計で表示
回答3-9
3-9.py
pd.crosstab(df["Sex"], df["Satisfied"])
# Sex female male
# Satisfied
# 0 2 8
# 1 9 1
pd.crosstab(df["Sex"], df["Satisfied"], normalize="index")
# Sex female male
# Satisfied
# 0 0.2 0.8
# 1 0.9 0.1
3-10. 各行について、Satisfiedが0であるかどうかの真偽値を表示する
回答3-10
3-10.py
df["Satisfied"] == 0
# 0 True
# 1 False
# 2 False
# 3 False
# 4 True
# 5 True
# 6 True
# 7 True
# 8 False
# 9 False
# 10 False
# 11 False
# 12 True
# 13 True
# 14 True
# 15 False
# 16 True
# 17 False
# 18 True
# 19 False
3-11. 各行について、Satisfiedが0の行を全て表示する
回答3-11
3-11.py
df[df["Satisfied"] == 0]
# PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked
# 0 1 0 3 male Sato, Mr. Ren 21.0 1 0 A/5 211711 870.000 NaN Tokyo
# 4 5 0 3 male Takahashi, Mr. Haruto 34.0 0 0 746900 966.000 NaN Tokyo
# 5 6 0 3 male Watanabe, Mr. Hinata NaN 0 0 661754 1014.996 NaN Nagoya
# 6 7 0 1 male Yamamoto, Mr. Itsuki 53.0 0 0 34926 6223.500 E46 Tokyo
# 7 8 0 3 male Nakamura, Master. Yuto 1.0 3 1 699818 2529.000 NaN NaN
# 12 13 0 3 male Sasaki, Mr. Minato 19.0 0 0 A/5. 21511 966.000 NaN Tokyo
# 13 14 0 3 male Yamaguchi, Mr. Hiroto 38.0 1 5 694164 3753.000 NaN Tokyo
# 14 15 0 3 female Matsumoto, Miss. Yuna 13.0 0 0 700812 942.504 NaN NaN
# 16 17 0 3 male Kimura, Master. Hiroto 1.0 4 1 765304 3495.000 NaN Nagoya
# 18 19 0 3 female Saito, Mrs.Hina 30.0 1 0 691526 2160.000 NaN Tokyo
3-12. Satisfiedが1の行でAge列だけを表示する。ただしAgeが欠損値の行は省く
回答3-12
3-12.py
df[df["Satisfied"] == 1].Age.dropna()
# 1 37.0
# 2 25.0
# 3 34.0
# 8 26.0
# 9 13.0
# 10 3.0
# 11 57.0
# 15 54.0
# Name: Age, dtype: float64
3-13. dfの上から5行目までを表示する
回答3-13
3-13.py
df.head(5)
# PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked
# 0 1 0 3 male Sato, Mr. Ren 21.0 1 0 A/5 211711 870.000 NaN Tokyo
# 1 2 1 1 female Suzuki, Mrs. Himari 37.0 1 0 PC 175991 8553.996 C85 Osaka
# 2 3 1 3 female Tanaka, Miss. Mei 25.0 0 0 STON/O2. 31012821 951.000 NaN NaN
# 3 4 1 1 female Ito, Mrs. Riko 34.0 1 0 227606 6372.000 C123 Tokyo
# 4 5 0 3 male Takahashi, Mr. Haruto 34.0 0 0 746900 966.000 NaN Tokyo
3-14. df内のデータの中から無作為に選んだ5行を表示する
回答3-14
3-14.py
df.sample(5)
# PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked
# 6 7 0 1 male Yamamoto, Mr. Itsuki 53.0 0 0 34926 6223.5 E46 Tokyo
# 15 16 1 2 female Inoue, Mrs. Kotone 54.0 0 0 497412 1920.0 NaN Tokyo
# 10 11 1 3 female Yoshida, Miss. Yuina 3.0 1 1 PP 95491 2004.0 G6 Tokyo
# 17 18 1 2 male Hayashi, Mr. Aoi NaN 0 0 488746 1560.0 NaN Tokyo
# 3 4 1 1 female Ito, Mrs. Riko 34.0 1 0 227606 6372.0 C123 Tokyo
3-15. df内のAge列だけを表示する
回答3-15
3-15.py
df["Age"]
# または
# df.Age
# 0 21.0
# 1 37.0
# 2 25.0
# 3 34.0
# 4 34.0
# 5 NaN
# 6 53.0
# 7 1.0
# 8 26.0
# 9 13.0
# 10 3.0
# 11 57.0
# 12 19.0
# 13 38.0
# 14 13.0
# 15 54.0
# 16 1.0
# 17 NaN
# 18 30.0
# 19 NaN
# Name: Age, dtype: float64
3-16. df内のAge列とName列だけを表示する
回答3-16
3-16.py
df.loc[:,["Age","Name"]]
# Age Name
# 0 21.0 Sato, Mr. Ren
# 1 37.0 Suzuki, Mrs. Himari
# 2 25.0 Tanaka, Miss. Mei
# 3 34.0 Ito, Mrs. Riko
# 4 34.0 Takahashi, Mr. Haruto
# 5 NaN Watanabe, Mr. Hinata
# 6 53.0 Yamamoto, Mr. Itsuki
# 7 1.0 Nakamura, Master. Yuto
# 8 26.0 Kobayashi, Mrs. Aoi
# 9 13.0 Kato, Mrs. Mio
# 10 3.0 Yoshida, Miss. Yuina
# 11 57.0 Yamada, Miss. Rin
# 12 19.0 Sasaki, Mr. Minato
# 13 38.0 Yamaguchi, Mr. Hiroto
# 14 13.0 Matsumoto, Miss. Yuna
# 15 54.0 Inoue, Mrs. Kotone
# 16 1.0 Kimura, Master. Hiroto
# 17 NaN Hayashi, Mr. Aoi
# 18 30.0 Saito, Mrs.Hina
# 19 NaN Shimizu, Mrs. Tsumugi
3-17. df内の奇数の行だけを表示する
回答3-17
3-17.py
df.iloc[lambda x: x.index % 2 == 1]
# PassengerId Satisfied Pclass Sex Name Age SibSp Parch Ticket Fare Cabin Embarked
# 1 2 1 1 female Suzuki, Mrs. Himari 37.0 1 0 PC 175991 8553.996 C85 Osaka
# 3 4 1 1 female Ito, Mrs. Riko 34.0 1 0 227606 6372.000 C123 Tokyo
# 5 6 0 3 male Watanabe, Mr. Hinata NaN 0 0 661754 1014.996 NaN Nagoya
# 7 8 0 3 male Nakamura, Master. Yuto 1.0 3 1 699818 2529.000 NaN NaN
# 9 10 1 2 female Kato, Mrs. Mio 13.0 1 0 475472 3608.496 NaN Osaka
# 11 12 1 1 female Yamada, Miss. Rin 57.0 0 0 227566 3186.000 C103 NaN
# 13 14 0 3 male Yamaguchi, Mr. Hiroto 38.0 1 5 694164 3753.000 NaN Tokyo
# 15 16 1 2 female Inoue, Mrs. Kotone 54.0 0 0 497412 1920.000 NaN Tokyo
# 17 18 1 2 male Hayashi, Mr. Aoi NaN 0 0 488746 1560.000 NaN Tokyo
# 19 20 1 3 female Shimizu, Mrs. Tsumugi NaN 0 0 5298 867.000 NaN Osaka
参考にさせていただきました
カレーちゃん - YouTube
A Data Science Framework: To Achieve 99% Accuracy | Kaggle