この記事について
逆強化学習に分類される手法の一つであるGAIL (Generative Adversarial Imitation Learning)のイメージをまとめます。
図解
推定したいもの
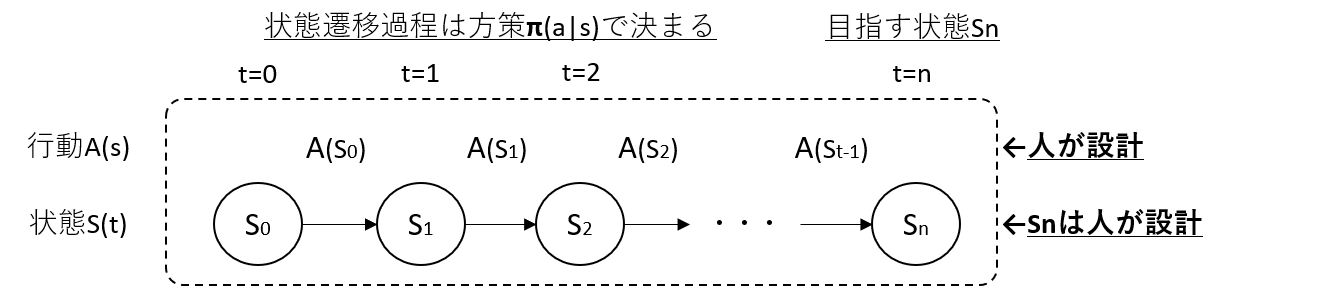
- 方策関数$\pi(a|s)$は、状態$S(t)=s$において行動$A(s)=a$を起こす確率を表す関数です
- 推定したい物は、初期状態$S_{0}$から目指すべき状態$S_{t}$へ期待通り遷移できるように調整された$\pi(a|s)$です
- $\pi(a|s)$は基本的には初等関数のような簡単な関数とはならず推定が困難なため、ディープラーニングで関数を近似します
学習で求めるモデル
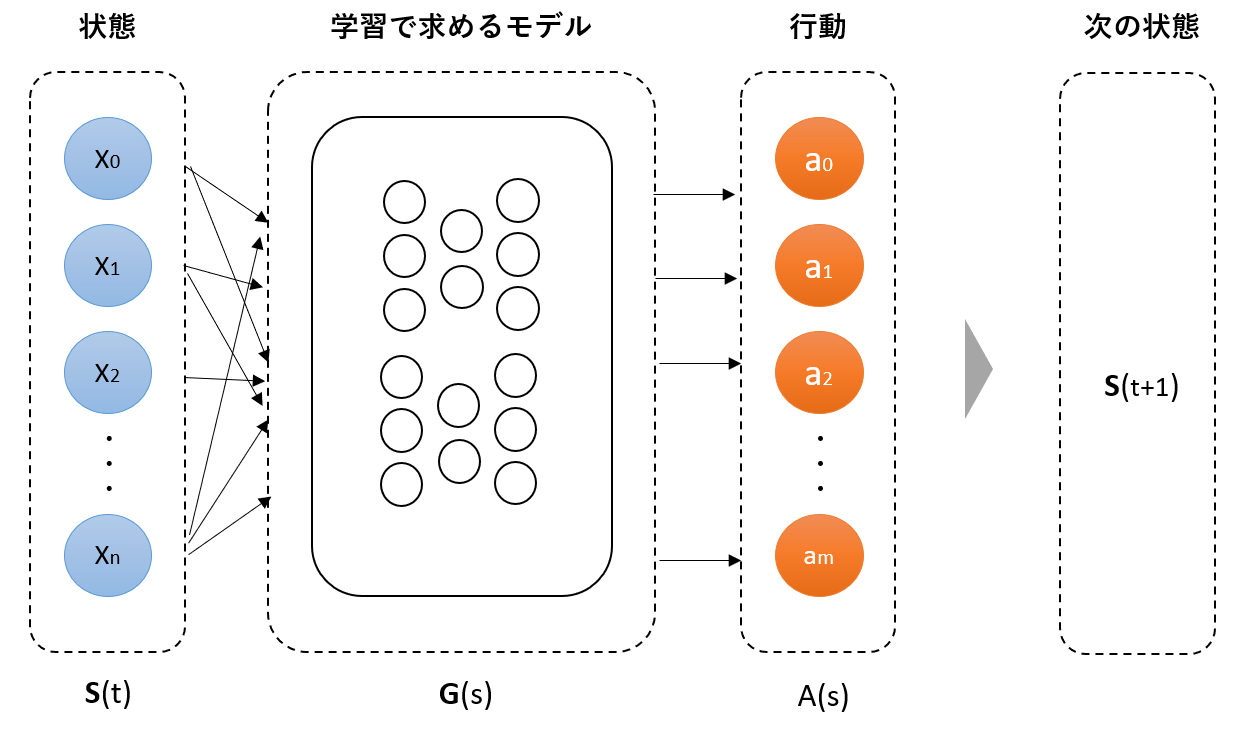
- $S(t)$は、システムがセンサにより把握する現在の環境状態に相当します(e.g. 障害物までの距離等)
- $A(s)$は、システムに対して出す制御指示に相当します(e.g. ハンドル制御角度等)
- 制御の結果、システムが動き、次の状態$S(t+1)$に遷移します
- $G(s)$は、推定したい方策$\pi(a|s)$を近似したものとなります
逆強化学習のアプローチ
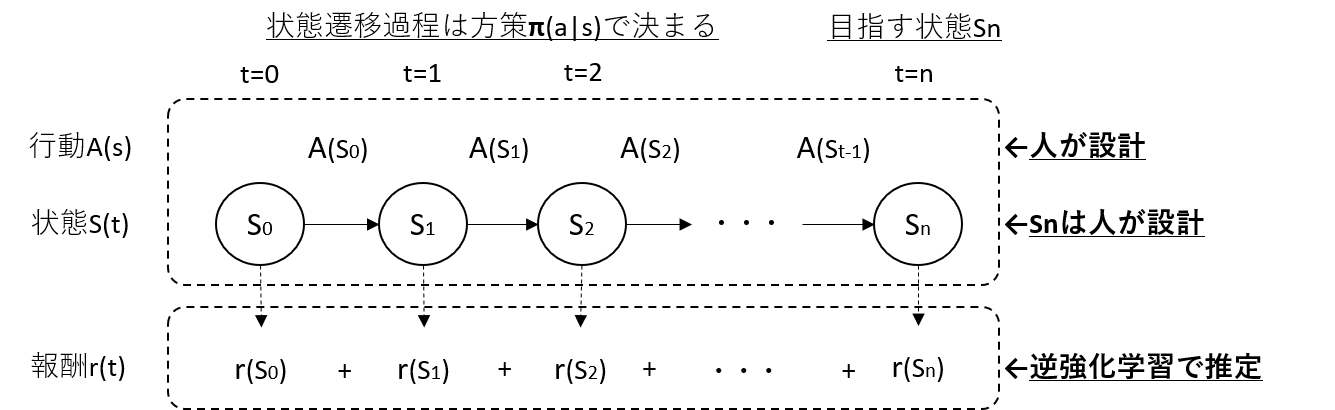
- 強化学習では状態$S(t)$で得られる報酬$r(t)$を人が設計します
- 問題が複雑になるにつれ、適切な報酬設計が困難になり、強化学習が上手く回らなくなります
- 逆強化学習では、人手によるエキスパート情報により、報酬関数を推定します
GAIL
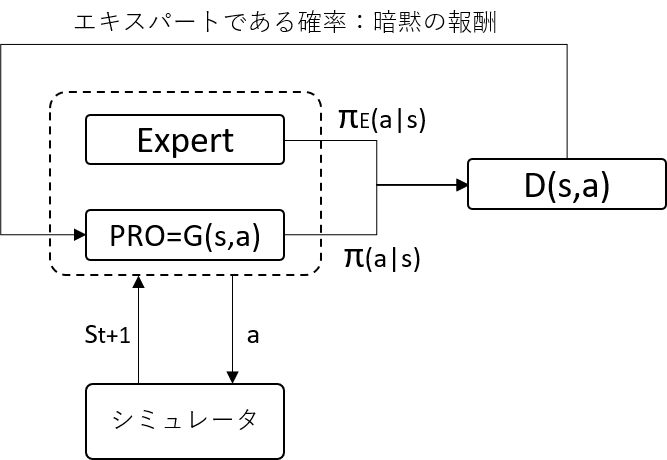
- GANを応用した逆強化学習の手法です
- エキスパートの行動と、PROが出力する行動を判別する判別器Dを配置します
- Dは入力されたものがエキスパートからの出力である確率(0~1)を出します
- PROは自身が出力した結果をDがエキスパートだと誤判定するように学習します
- そのため、Dの出力はPROへの報酬と捉えることができます
注意点
- 目標とする状態(e.g. 位置等)が変化するようなタスクでは学習が困難になる可能性があります
- 報酬はエキスパートの方策と似ているかどうかのみから決定されます
- PROが行った行動に対する環境(シミュレータ)のフィードバックは得ていません
- PROは自分の行動が環境にどのような影響を与えるのかを知ることができません
- 報酬の設計情報はDのモデルに隠蔽されているため、報酬設計を抜き取るのは困難です
- エキスパートを用意するために人が使った情報(S)と、PROへの入力情報(S)が同じでないと方策$π(a|s)$が学習できない可能性があります