OpenShift AI
Red Hat® OpenShift® AI とは、柔軟でスケーラブルな人工知能 (AI) および機械学習 (ML) プラットフォームです。このプラットフォームにより、企業はハイブリッドクラウド環境全体で AI 対応アプリケーションを大規模に作成および提供できるようになります。
OpenShift AI はオープンソース・テクノロジーを使用して構築されており、実験、モデル提供、革新的なアプリケーションの提供のための、信頼性と一貫性に優れた運用機能を提供します。
GPU Node
AI 学習等で使用する GPU Node を設定します。
ここでは、Red Hat OpenShift on IBM Cloud (ROKS) 4.14 の環境に、以下のドキュメントを参考にして OpenShift AI 導入後に GPU Node を設定してみます。
上記に記載のある通り、以下の NVIDIA のドキュメントを参照してみます。
Installing the Node Feature Discovery (NFD) Operator
Operator Hub から Node Feature Discovery (NFD) Operator をデフォルト設定で導入します。
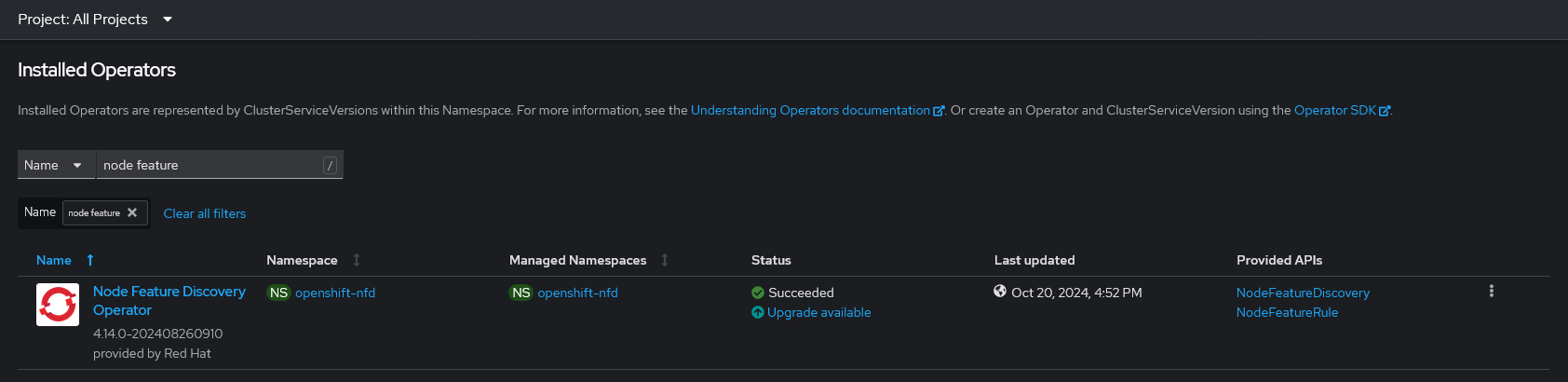
完了すると openshift-nfd Project に以下のようなリソースが配置されます。
$ oc get all -n openshift-nfd
Warning: apps.openshift.io/v1 DeploymentConfig is deprecated in v4.14+, unavailable in v4.10000+
NAME READY STATUS RESTARTS AGE
pod/nfd-controller-manager-585b4785d8-dsr2t 2/2 Running 0 22h
pod/nfd-master-66c886fb64-bkt5m 1/1 Running 0 19d
pod/nfd-worker-4bljq 1/1 Running 9 (19d ago) 55d
pod/nfd-worker-7nnwd 1/1 Running 9 (19d ago) 55d
pod/nfd-worker-clntr 1/1 Running 9 (19d ago) 55d
pod/nfd-worker-dr4fr 1/1 Running 9 (19d ago) 55d
pod/nfd-worker-p7qxd 1/1 Running 15 (7d19h ago) 55d
pod/nfd-worker-ph9kq 1/1 Running 9 (19d ago) 55d
pod/nfd-worker-q8qqv 1/1 Running 9 (19d ago) 55d
pod/nfd-worker-slf59 1/1 Running 2 (6d1h ago) 6d1h
pod/nfd-worker-vg6jl 1/1 Running 10 (10d ago) 55d
pod/nfd-worker-w49gp 1/1 Running 12 (19d ago) 55d
pod/nfd-worker-w8tgt 1/1 Running 9 (19d ago) 55d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nfd-controller-manager-metrics-service ClusterIP 192.16.206.100 <none> 8443/TCP 55d
service/nfd-master ClusterIP 192.16.104.236 <none> 12000/TCP 55d
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/nfd-worker 11 11 11 11 11 <none> 55d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nfd-controller-manager 1/1 1 1 55d
deployment.apps/nfd-master 1/1 1 1 55d
NAME DESIRED CURRENT READY AGE
replicaset.apps/nfd-controller-manager-585b4785d8 1 1 1 22h
replicaset.apps/nfd-controller-manager-64b8dfcb6b 0 0 0 55d
replicaset.apps/nfd-master-66c886fb64 1 1 1 55d
NFD Operator の NodeFeatureDiscovery Tab でインスタンスを、デフォルト設定で作成します。
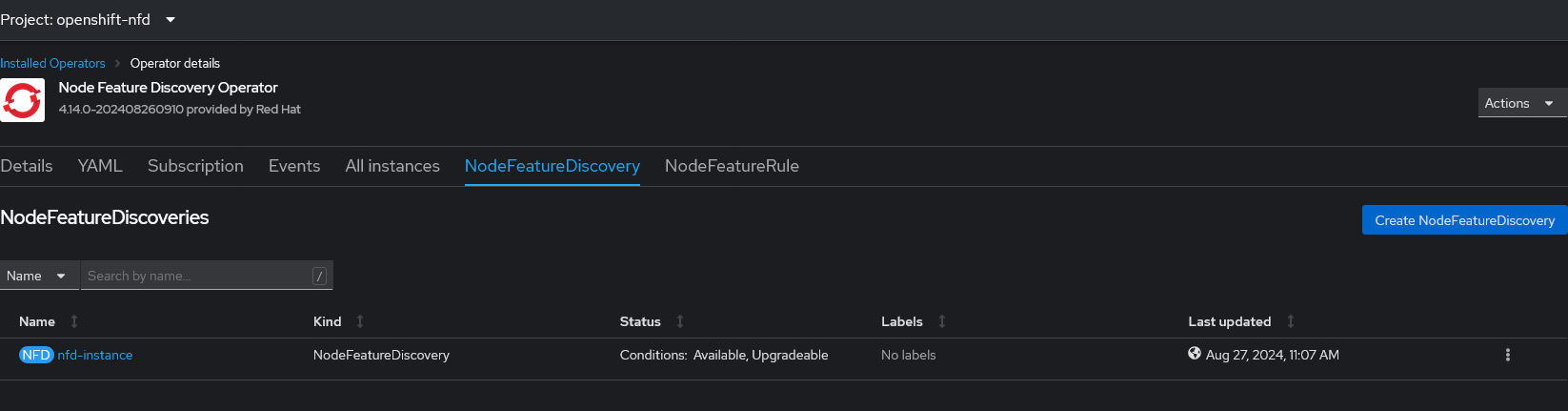
GPU Node で feature.node.kubernetes.io/pci-10de.present Label が true に設定されていることを確認します。
今回の環境では INSTANCE-TYPE (=Flavor) が gx3.24x120.l40s と gx3.16x80.l4 の Node に設定されている事が分かります。
$ oc get node -L "feature.node.kubernetes.io/pci-10de.present" -L "beta.kubernetes.io/instance-type" -L "nvidia.com/gpu.product" -L "nvidia.com/mig.capable"
NAME STATUS ROLES AGE VERSION PCI-10DE.PRESENT INSTANCE-TYPE GPU.PRODUCT MIG.CAPABLE
99.888.0.16 Ready master,worker 91d v1.27.15+6147456 cx2.16x32
99.888.0.17 Ready master,worker 91d v1.27.15+6147456 cx2.16x32
99.888.0.4 Ready master,worker 140d v1.27.13+048520e mx2.8x64
99.888.0.5 Ready master,worker 140d v1.27.13+048520e mx2.8x64
99.888.0.6 Ready master,worker 140d v1.27.13+048520e mx2.8x64
99.888.128.4 Ready master,worker 9d v1.27.16+03a907c true gx3.16x80.l4 NVIDIA-L4 false
99.888.128.5 Ready master,worker 91d v1.27.15+6147456 cx2.16x32
99.888.128.6 Ready master,worker 91d v1.27.15+6147456 cx2.16x32
99.888.64.4 Ready master,worker 91d v1.27.15+6147456 cx2.16x32
99.888.64.5 Ready master,worker 91d v1.27.15+6147456 cx2.16x32
GPU Node で NVIDIA GPU を確認してみます。
sh-4.4# lspci | grep -i nvidia
04:01.0 3D controller: NVIDIA Corporation AD104GL [L4] (rev a1)
Installing the NVIDIA GPU Operator
Operator Hub から NVIDIA GPU Operator をデフォルト設定で導入します。
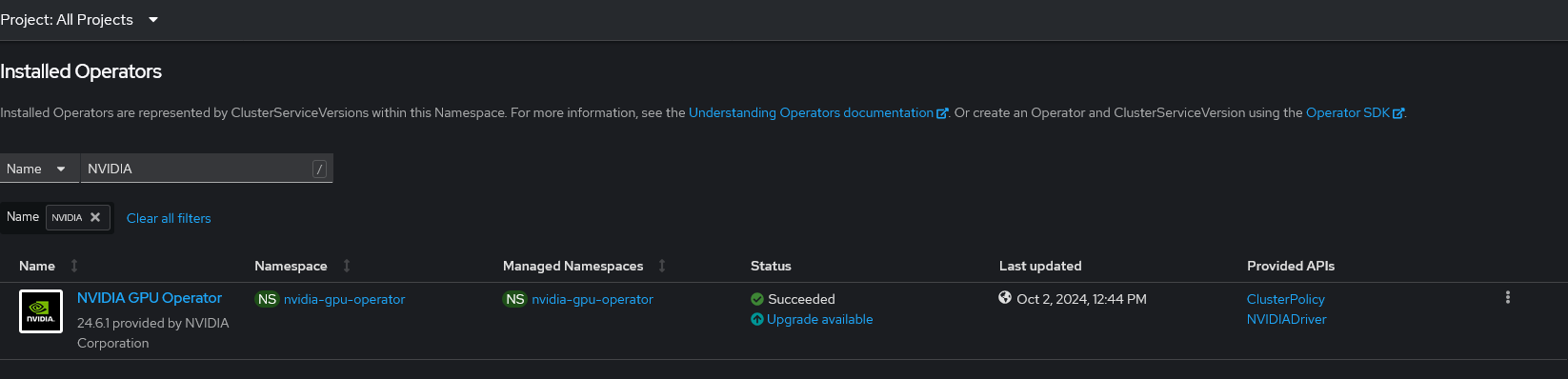
完了すると nvidia-gpu-operator Project に以下のようなリソースが配置されます。
$ oc get all -n nvidia-gpu-operator
NAME READY STATUS RESTARTS AGE
pod/gpu-feature-discovery-vpm77 1/1 Running 0 7d19h
pod/gpu-feature-discovery-x6sl9 1/1 Running 0 6d2h
pod/gpu-operator-789c7877fc-7n5vj 1/1 Running 0 19d
pod/nvidia-container-toolkit-daemonset-c9ds5 1/1 Running 0 6d2h
pod/nvidia-container-toolkit-daemonset-gmnpn 1/1 Running 0 7d19h
pod/nvidia-cuda-validator-8jhkk 0/1 Completed 0 6d2h
pod/nvidia-cuda-validator-ltwhz 0/1 Completed 0 7d19h
pod/nvidia-dcgm-exporter-4dndg 1/1 Running 0 6d2h
pod/nvidia-dcgm-exporter-pd58s 1/1 Running 0 7d19h
pod/nvidia-dcgm-p4bmn 1/1 Running 0 6d2h
pod/nvidia-dcgm-rsk5g 1/1 Running 0 7d19h
pod/nvidia-device-plugin-daemonset-r58dx 1/1 Running 0 6d2h
pod/nvidia-device-plugin-daemonset-sxqct 1/1 Running 0 7d19h
pod/nvidia-driver-daemonset-5hv4v 1/1 Running 0 6d2h
pod/nvidia-driver-daemonset-9qq6x 1/1 Running 1 55d
pod/nvidia-node-status-exporter-fs6v5 1/1 Running 0 6d2h
pod/nvidia-node-status-exporter-sjc9n 1/1 Running 1 55d
pod/nvidia-operator-validator-f5pr9 1/1 Running 0 7d19h
pod/nvidia-operator-validator-pcdvf 1/1 Running 0 6d2h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/gpu-operator ClusterIP 192.16.247.242 <none> 8080/TCP 55d
service/nvidia-dcgm ClusterIP 192.16.157.103 <none> 5555/TCP 55d
service/nvidia-dcgm-exporter ClusterIP 192.16.182.25 <none> 9400/TCP 55d
service/nvidia-node-status-exporter ClusterIP 192.16.173.104 <none> 8000/TCP 55d
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/gpu-feature-discovery 2 2 2 2 2 nvidia.com/gpu.deploy.gpu-feature-discovery=true 55d
daemonset.apps/nvidia-container-toolkit-daemonset 2 2 2 2 2 nvidia.com/gpu.deploy.container-toolkit=true 55d
daemonset.apps/nvidia-dcgm 2 2 2 2 2 nvidia.com/gpu.deploy.dcgm=true 55d
daemonset.apps/nvidia-dcgm-exporter 2 2 2 2 2 nvidia.com/gpu.deploy.dcgm-exporter=true 55d
daemonset.apps/nvidia-device-plugin-daemonset 2 2 2 2 2 nvidia.com/gpu.deploy.device-plugin=true 55d
daemonset.apps/nvidia-device-plugin-mps-control-daemon 0 0 0 0 0 nvidia.com/gpu.deploy.device-plugin=true,nvidia.com/mps.capable=true 55d
daemonset.apps/nvidia-driver-daemonset 2 2 2 2 2 nvidia.com/gpu.deploy.driver=true 55d
daemonset.apps/nvidia-mig-manager 0 0 0 0 0 nvidia.com/gpu.deploy.mig-manager=true 55d
daemonset.apps/nvidia-node-status-exporter 2 2 2 2 2 nvidia.com/gpu.deploy.node-status-exporter=true 55d
daemonset.apps/nvidia-operator-validator 2 2 2 2 2 nvidia.com/gpu.deploy.operator-validator=true 55d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/gpu-operator 1/1 1 1 55d
NAME DESIRED CURRENT READY AGE
replicaset.apps/gpu-operator-789c7877fc 1 1 1 55d
例えば nvidia-driver-daemonset-5hv4v Pod を確認してみると、GPU Node の /run/nvidia を Pod の /run/nvidia に Mount していることが分かります。
On Pod
$ oc exec -ti nvidia-driver-daemonset-5hv4v -- ls -la /run/nvidia
total 20
drwxr-xr-x. 6 root root 140 Oct 15 04:56 .
drwxr-xr-x. 1 root root 4096 Oct 15 04:59 ..
dr-xr-xr-x. 1 root root 4096 Oct 15 04:55 driver
drwxr-xr-x. 3 root root 60 Oct 15 05:00 mps
-rw-r--r--. 1 root root 6 Oct 15 04:56 nvidia-driver.pid
drwxr-xr-x. 2 root root 60 Oct 21 11:58 toolkit
drwxr-xr-x. 2 root root 140 Oct 21 11:59 validations
On GPU Node
sh-4.4# ls -la /run/nvidia
total 12
drwxr-xr-x. 6 root root 140 Oct 14 23:56 .
drwxr-xr-x. 49 root root 1300 Oct 21 04:55 ..
dr-xr-xr-x. 1 root root 4096 Oct 14 23:55 driver
drwxr-xr-x. 3 root root 60 Oct 15 00:00 mps
-rw-r--r--. 1 root root 6 Oct 14 23:56 nvidia-driver.pid
drwxr-xr-x. 2 root root 60 Oct 21 06:58 toolkit
drwxr-xr-x. 2 root root 140 Oct 21 06:59 validations
Pod 上では NVIDIA Driver に関する各種 Process が実行されていることが分かります。
[root@nvidia-driver-daemonset-5hv4v drivers]# ps -ef | grep $(cat /run/nvidia/nvidia-driver.pid)
root 26209 26197 0 Oct15 ? 00:00:00 /bin/bash -x /usr/local/bin/nvidia-driver init
root 53023 26209 0 Oct15 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep infinity
root 153810 151857 0 02:41 pts/0 00:00:00 grep --color=auto 26209
[root@nvidia-driver-daemonset-5hv4v drivers]# ps -ef | grep 26197
root 26197 1 0 Oct15 ? 00:00:00 /usr/bin/conmon -b /var/data/crioruntimestorage/overlay-containers/
root 26209 26197 0 Oct15 ? 00:00:00 /bin/bash -x /usr/local/bin/nvidia-driver init
root 52962 26197 0 Oct15 ? 00:00:01 nvidia-persistenced --persistence-mode
root 154453 151857 0 02:42 pts/0 00:00:00 grep --color=auto 26197
[root@nvidia-driver-daemonset-5hv4v drivers]# head -n 50 /usr/local/bin/nvidia-driver
#! /bin/bash -x
# Copyright (c) 2018-2020, NVIDIA CORPORATION. All rights reserved.
set -eu
RUN_DIR=/run/nvidia
PID_FILE=${RUN_DIR}/${0##*/}.pid
DRIVER_VERSION=${DRIVER_VERSION:?"Missing DRIVER_VERSION env"}
KERNEL_UPDATE_HOOK=/run/kernel/postinst.d/update-nvidia-driver
NUM_VGPU_DEVICES=0
NVIDIA_MODULE_PARAMS=()
NVIDIA_UVM_MODULE_PARAMS=()
NVIDIA_MODESET_MODULE_PARAMS=()
NVIDIA_PEERMEM_MODULE_PARAMS=()
TARGETARCH=${TARGETARCH:?"Missing TARGETARCH env"}
USE_HOST_MOFED="${USE_HOST_MOFED:-false}"
DNF_RELEASEVER=${DNF_RELEASEVER:-""}
RHEL_VERSION=${RHEL_VERSION:-""}
RHEL_MAJOR_VERSION=8
OPEN_KERNEL_MODULES_ENABLED=${OPEN_KERNEL_MODULES_ENABLED:-false}
[[ "${OPEN_KERNEL_MODULES_ENABLED}" == "true" ]] && KERNEL_TYPE=kernel-open || KERNEL_TYPE=kernel
DRIVER_ARCH=${TARGETARCH/amd64/x86_64} && DRIVER_ARCH=${DRIVER_ARCH/arm64/aarch64}
echo "DRIVER_ARCH is $DRIVER_ARCH"
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
source $SCRIPT_DIR/common.sh
_update_package_cache() {
if [ "${PACKAGE_TAG:-}" != "builtin" ]; then
echo "Updating the package cache..."
if ! yum -q makecache; then
echo "FATAL: failed to reach RHEL package repositories. "\
"Ensure that the cluster can access the proper networks."
exit 1
fi
fi
}
_cleanup_package_cache() {
if [ "${PACKAGE_TAG:-}" != "builtin" ]; then
echo "Cleaning up the package cache..."
rm -rf /var/cache/yum/*
fi
}
_get_rhel_version_from_kernel() {
local rhel_version_underscore rhel_version_arr
rhel_version_underscore=$(echo "${KERNEL_VERSION}" | sed 's/.*el\([0-9]\+_[0-9]\+\).*/\1/g')
[root@nvidia-driver-daemonset-5hv4v drivers]# which nvidia-persistenced
/usr/bin/nvidia-persistenced
[root@nvidia-driver-daemonset-5hv4v drivers]# nvidia-persistenced --help
nvidia-persistenced: version 550.90.07
The NVIDIA Persistence Daemon.
A tool for maintaining persistent driver state, specifically for use by the NVIDIA Linux driver.
Copyright (C) 2013-2018 NVIDIA Corporation.
nvidia-persistenced [options]
-v, --version
Print the utility version and exit.
-h, --help
Print usage information for the command line options and exit.
-V, --verbose
Controls how much information is printed. By default, nvidia-persistenced will only print errors and warnings to syslog for unexpected events, as well as startup and shutdown notices. Specifying this
flag will cause nvidia-persistenced to also print notices to syslog on state transitions, such as when persistence mode is enabled or disabled, and informational messages on startup and exit.
-u USERNAME, --user=USERNAME
Runs nvidia-persistenced with the user permissions of the user specified by the USERNAME argument. This user must have write access to the /var/run/nvidia-persistenced directory. If this directory does
not exist, nvidia-persistenced will attempt to create it prior to changing the process user and group IDs. If this option is not given, nvidia-persistenced will not attempt to change the process user
ID.
-g GROUPNAME, --group=GROUPNAME
Runs nvidia-persistenced with the group permissions of the group specified by the GROUPNAME argument. If both this option and the --user option are given, this option will take precedence when
determining the group ID to use. If this option is not given, nvidia-persistenced will use the primary group ID of the user specified by the --user option argument. If the --user option is also not
given, nvidia-persistenced will not attempt to change the process group ID.
--persistence-mode, --no-persistence-mode
By default, nvidia-persistenced starts with persistence mode enabled for all devices. Use '--no-persistence-mode' to force persistence mode off for all devices on startup.
--uvm-persistence-mode, --no-uvm-persistence-mode
UVM persistence mode is only supported on the single GPU confidential computing configuration. By default, nvidia-persistenced starts with UVM persistence mode disabled for all devices. Use
'--uvm-persistence-mode' to force UVM persistence mode on for supported devices on startup.
--nvidia-cfg-path=PATH
The nvidia-cfg library is used to communicate with the NVIDIA kernel module to query and manage GPUs in the system. This library is required by nvidia-persistenced. This option tells nvidia-persistenced
where to look for this library (in case it cannot find it on its own). This option should normally not be needed.
For more detailed usage information, please see the nvidia-persistenced manpage and the "Using the nvidia-persistenced Utility" section of the NVIDIA Linux Graphics Driver README.
別の nvidia-container-toolkit-daemonset-c9ds5 Pod を確認してみると、NVIDIA Driver の Validation Check と nvidia-toolkit の処理を行っていることが分かります。
$ oc exec -ti nvidia-container-toolkit-daemonset-c9ds5 -- cat -n /usr/bin/entrypoint.sh
Defaulted container "nvidia-container-toolkit-ctr" out of: nvidia-container-toolkit-ctr, driver-validation (init)
1 #!/bin/bash
2
3 until [[ -f /run/nvidia/validations/driver-ready ]]
4 do
5 echo "waiting for the driver validations to be ready..."
6 sleep 5
7 done
8
9 set -o allexport
10 cat /run/nvidia/validations/driver-ready
11 . /run/nvidia/validations/driver-ready
12
13 #
14 # The below delay is a workaround for an issue affecting some versions
15 # of containerd starting with 1.6.9. Staring with containerd 1.6.9 we
16 # started seeing the toolkit container enter a crashloop whereby it
17 # would recieve a SIGTERM shortly after restarting containerd.
18 #
19 # Refer to the commit message where this workaround was implemented
20 # for additional details:
21 # https://github.com/NVIDIA/gpu-operator/commit/963b8dc87ed54632a7345c1fcfe842f4b7449565
22 #
23 sleep 5
24
25 exec nvidia-toolkit
NVIDIA GPU Operator の ClusterPolicy Tab でインスタンスを、デフォルト設定で作成します。
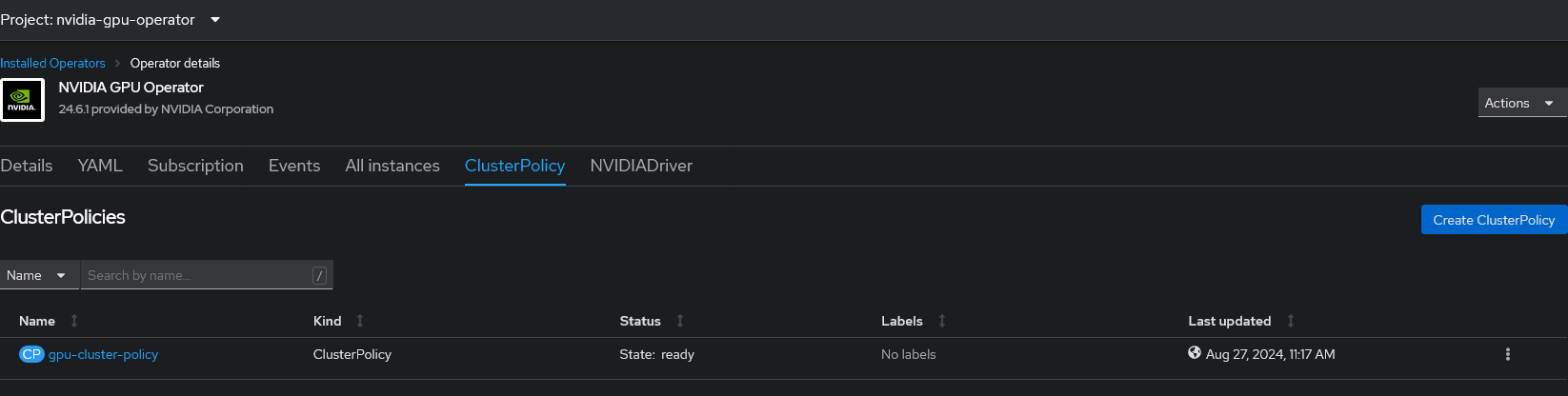
以上で、基本的な GPU Node の設定は完了です。
Node Labels
今回導入した2つの Operator は非常に多くの Node Label を設定します。これらを使用する事で詳細な確認が可能です。
feature.node.kubernetes.io/cpu-cpuid.ADX
feature.node.kubernetes.io/cpu-cpuid.AESNI
feature.node.kubernetes.io/cpu-cpuid.AMXBF16
feature.node.kubernetes.io/cpu-cpuid.AMXINT8
feature.node.kubernetes.io/cpu-cpuid.AMXTILE
feature.node.kubernetes.io/cpu-cpuid.AVX
feature.node.kubernetes.io/cpu-cpuid.AVX2
feature.node.kubernetes.io/cpu-cpuid.AVX512BF16
feature.node.kubernetes.io/cpu-cpuid.AVX512BITALG
feature.node.kubernetes.io/cpu-cpuid.AVX512BW
feature.node.kubernetes.io/cpu-cpuid.AVX512CD
feature.node.kubernetes.io/cpu-cpuid.AVX512DQ
feature.node.kubernetes.io/cpu-cpuid.AVX512F
feature.node.kubernetes.io/cpu-cpuid.AVX512FP16
feature.node.kubernetes.io/cpu-cpuid.AVX512IFMA
feature.node.kubernetes.io/cpu-cpuid.AVX512VBMI
feature.node.kubernetes.io/cpu-cpuid.AVX512VBMI2
feature.node.kubernetes.io/cpu-cpuid.AVX512VL
feature.node.kubernetes.io/cpu-cpuid.AVX512VNNI
feature.node.kubernetes.io/cpu-cpuid.AVX512VPOPCNTDQ
feature.node.kubernetes.io/cpu-cpuid.AVXVNNI
feature.node.kubernetes.io/cpu-cpuid.CLDEMOTE
feature.node.kubernetes.io/cpu-cpuid.CMPXCHG8
feature.node.kubernetes.io/cpu-cpuid.FMA3
feature.node.kubernetes.io/cpu-cpuid.FSRM
feature.node.kubernetes.io/cpu-cpuid.FXSR
feature.node.kubernetes.io/cpu-cpuid.FXSROPT
feature.node.kubernetes.io/cpu-cpuid.GFNI
feature.node.kubernetes.io/cpu-cpuid.HYPERVISOR
feature.node.kubernetes.io/cpu-cpuid.IA32_ARCH_CAP
feature.node.kubernetes.io/cpu-cpuid.IBPB
feature.node.kubernetes.io/cpu-cpuid.IBRS
feature.node.kubernetes.io/cpu-cpuid.LAHF
feature.node.kubernetes.io/cpu-cpuid.MD_CLEAR
feature.node.kubernetes.io/cpu-cpuid.MOVBE
feature.node.kubernetes.io/cpu-cpuid.MOVDIR64B
feature.node.kubernetes.io/cpu-cpuid.MOVDIRI
feature.node.kubernetes.io/cpu-cpuid.OSXSAVE
feature.node.kubernetes.io/cpu-cpuid.SERIALIZE
feature.node.kubernetes.io/cpu-cpuid.SHA
feature.node.kubernetes.io/cpu-cpuid.SPEC_CTRL_SSBD
feature.node.kubernetes.io/cpu-cpuid.STIBP
feature.node.kubernetes.io/cpu-cpuid.SYSCALL
feature.node.kubernetes.io/cpu-cpuid.SYSEE
feature.node.kubernetes.io/cpu-cpuid.TSXLDTRK
feature.node.kubernetes.io/cpu-cpuid.VAES
feature.node.kubernetes.io/cpu-cpuid.VMX
feature.node.kubernetes.io/cpu-cpuid.VPCLMULQDQ
feature.node.kubernetes.io/cpu-cpuid.WAITPKG
feature.node.kubernetes.io/cpu-cpuid.WBNOINVD
feature.node.kubernetes.io/cpu-cpuid.X87
feature.node.kubernetes.io/cpu-cpuid.XGETBV1
feature.node.kubernetes.io/cpu-cpuid.XSAVE
feature.node.kubernetes.io/cpu-cpuid.XSAVEC
feature.node.kubernetes.io/cpu-cpuid.XSAVEOPT
feature.node.kubernetes.io/cpu-cpuid.XSAVES
feature.node.kubernetes.io/cpu-hardware_multithreading
feature.node.kubernetes.io/cpu-model.family
feature.node.kubernetes.io/cpu-model.id
feature.node.kubernetes.io/cpu-model.vendor_id
feature.node.kubernetes.io/kernel-config.NO_HZ
feature.node.kubernetes.io/kernel-config.NO_HZ_FULL
feature.node.kubernetes.io/kernel-selinux.enabled
feature.node.kubernetes.io/kernel-version.full
feature.node.kubernetes.io/kernel-version.major
feature.node.kubernetes.io/kernel-version.minor
feature.node.kubernetes.io/kernel-version.revision
feature.node.kubernetes.io/memory-numa
feature.node.kubernetes.io/pci-1013.present
feature.node.kubernetes.io/pci-10de.present
feature.node.kubernetes.io/pci-1af4.present
feature.node.kubernetes.io/system-os_release.ID
feature.node.kubernetes.io/system-os_release.VERSION_ID
feature.node.kubernetes.io/system-os_release.VERSION_ID.major
feature.node.kubernetes.io/system-os_release.VERSION_ID.minor
nvidia.com/cuda.driver-version.full
nvidia.com/cuda.driver-version.major
nvidia.com/cuda.driver-version.minor
nvidia.com/cuda.driver-version.revision
nvidia.com/cuda.driver.major
nvidia.com/cuda.driver.minor
nvidia.com/cuda.driver.rev
nvidia.com/cuda.runtime-version.full
nvidia.com/cuda.runtime-version.major
nvidia.com/cuda.runtime-version.minor
nvidia.com/cuda.runtime.major
nvidia.com/cuda.runtime.minor
nvidia.com/gfd.timestamp
nvidia.com/gpu-driver-upgrade-state
nvidia.com/gpu.compute.major
nvidia.com/gpu.compute.minor
nvidia.com/gpu.count
nvidia.com/gpu.deploy.container-toolkit
nvidia.com/gpu.deploy.dcgm
nvidia.com/gpu.deploy.dcgm-exporter
nvidia.com/gpu.deploy.device-plugin
nvidia.com/gpu.deploy.driver
nvidia.com/gpu.deploy.gpu-feature-discovery
nvidia.com/gpu.deploy.node-status-exporter
nvidia.com/gpu.deploy.nvsm
nvidia.com/gpu.deploy.operator-validator
nvidia.com/gpu.family
nvidia.com/gpu.machine
nvidia.com/gpu.memory
nvidia.com/gpu.mode
nvidia.com/gpu.present
nvidia.com/gpu.product
nvidia.com/gpu.replicas
nvidia.com/gpu.sharing-strategy
nvidia.com/mig.capable
nvidia.com/mig.strategy
nvidia.com/mps.capable
nvidia.com/vgpu.present