1. この記事は
学習済みのVideo Vision Transformer:ViViTモデルに新しいデータセットを適用させるファインチューニングの手法を説明します。ファインチューニングによって、ユーザが独自に用意した比較的少なめのデータセットでも効率的に学習させることが可能です。
2. 前提知識として
ViViTモデルは、2021年にGoogleが発表した動画認識のための機械学習モデルです。ViViTモデルはRNN(再帰的ニューラルネットワーク)構造を持たず、データをトークンと呼ばれる単位に分割し、トークン同士を相互参照させる自己注意機構を応用したモデルです。ViViTモデルの原型であるTransformerモデルは、ChatGPTなどの多くの自然言語処理のサービスの基盤となっています。
ViViTモデルは、入力した数秒の動画クリップから動画に映っている人物の動作を推論し識別することができます。Hugging Faceで学習済みViViTモデルが公開されているので、動画認識を実際に試すことができます。Hugging FaceのViViTモデルを利用して動画認識を行う方法を以下の記事にまとめました。
ViViTモデルは(原型であるTransformerモデルの)特性上、CNN(畳み込みニューラルネットワーク)のような帰納的バイアスを持ちません。CNNの帰納的バイアスとは、例えばパディング層を追加することで画像の位置ずれに柔軟に対応できる特性のことです。つまり、ViViTモデルは同じ人物が同じ動作をしたとしても、画面内での位置がずれていたら同じものと認識されません。そのためViViTモデルではその欠点を補うために、学習には大量のデータセットが必要となります。
実際、上の記事で使用している学習済みViViTモデルはkinetics-400という大規模データセット(それと、おそらく莫大なGPUリソースを使用して)で訓練されています。そのため、ViViTモデルを初期状態でイチから学習して個別のタスクに適用するのは現実的でありません。
そのため、学習済みのViViTモデルをファインチューニングすることで、新規のデータセットに対して比較的容易に適応させ、目的のタスクを実現します。
3. 転移学習とは
転移学習とは、「あるタスクのためにデータセットで訓練させた機械学習モデルを他のタスクに適用する方法」全般のことを指します。つまり、「学習済み機械学習モデルの再利用」です。
3.1. ファインチューニングとは
転移学習の手法のひとつです。ファインチューニングでは、学習済みモデルの全体のパラメータを新しいデータセットで再訓練させます。モデルの一部のパラメータを再学習する方法(後述する「狭義の転移学習」のこと)に比べて、ファインチューニングは再学習の対象がモデル全体であるため計算コストを要します。しかし、再学習用のデータが大量にある場合はファインチューニングが向いているそうです。
3.2. 転移学習とファインチューニングの違い
広義で転移学習とは「学習済み機械学習モデルの再利用」する手法全般のことを指しますが、狭義で転移学習とは、学習済みモデルの一部のパラメータのみを新しいデータセットで再訓練させることを指すようです。一部のパラメータとは具体的には、新しく取り替えたり追加された出力層のパラメータのことです。それに対してファインチューニングは、学習済みモデルの全ての層のパラメータを再訓練させます。
4. 開発環境
PyTorch、HuggingFace ViViT、Google Colabを使用します。HuggingFaceとは、機械学習モデルのライブラリです。
5. ファインチューニングの概要
まず、ファインチューニングの概要や考え方を説明します。後のコーディングはここでの説明を元に行っています。
5.1. データセット
ファインチューニングに使用するデータセットは、1つの動画に1つの動作で、全64種類の動作が収録された全3,200本の動画データであるとします。
5.2. 学習済みViViTモデル
ファインチューニングするViViTモデルは、HuggingFaceで公開されているモデル vivit-b-16x2-kinetics400 を使用します。このモデルは、GoogleがYouTubeから収集した306,245本の動画クリップを元に400種類の動作で構成された大規模なデータセット Kinetics-400 で学習されています。収録されている動作とラベルの一覧は下記のデータセットの論文にまとめられています。
5.3. ViViTモデルの入出力
図1にViViTモデルの入出力の概略を示しました。今回使用するvivit-b-16x2-kinetics400の場合、入力側データは、動画ファイルから任意の32枚のフレームを抽出してベクトル化する必要があります。ベクトルのシェイプは(-1, 32, 3, 224, 224)でなければなりません。-1はバッチサイズによる可変長の次元、32はフレーム数、3はRGB 3チャネル分の色情報、224, 224はフレームの縦横に相当するサイズです。
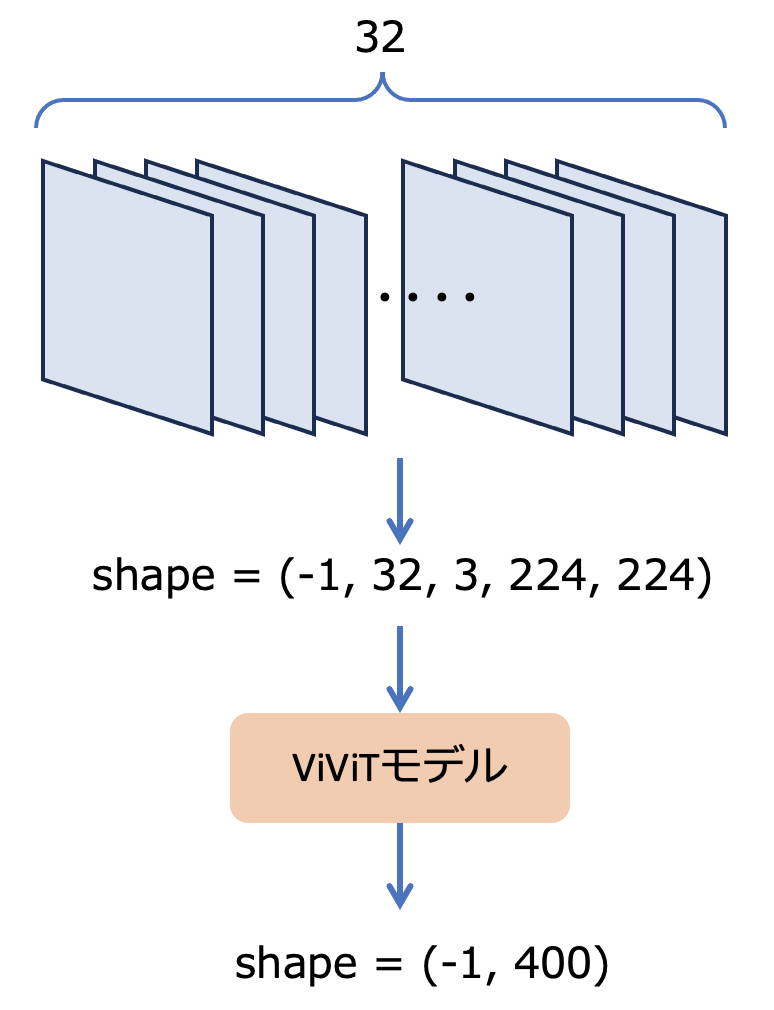 図1: ViViTモデルの入出力
図1: ViViTモデルの入出力
出力側のベクトルのシェイプは(-1, 400)です。-1はバッチサイズによる可変長の次元で、入力の次元と一致します。400はkinetics-400の400種類のラベルに対応しています。
5.4. ViViTモデルのファインチューニング手法
vivit-b-16x2-kinetics400 は出力シェイプが(-1, 400)なのに対し、新に学習で使用するデータセットはラベルの数が64です。したがって、出力シェイプを(-1, 64)に変更する必要があります。
詳細は後に確認するとして、この投稿でのファインチューニングでは、出力側ベクトルのシェイプを学習させるデータセットのラベルと適合させるために、出力層を新しいものと取り替えます。
取り替えた出力層のパラメータは初期化された状態なので、これは再学習の対象になります。加えて、モデルの既存のパラメータ部分も新しいデータで再学習させます。したがって、再学習の対象はモデルの全てのパラメータということになります。
5.5. フレームの取得
入力データのフレーム数は32であるため、任意の長さの動画から必要な32フレームを抜き出す必要があります。動画データセットの動画は全て違うフレーム数であることが予想されるので、これも考慮する必要があります。ここでは、$N$ は入力データのフレーム数で、$N = 32$ とします。$L$ をその動画の全フレーム数、$S_{rate}$ をフレームのサンプリングレートとします。
$L < N$ のとき:
動画のフレーム数が足りないため、この動画データは使用できません。
$L \geqq N$ のとき:
$S_{rate} = \lfloor\frac{L}{N} \rfloor$として、ランダムな開始位置からのサンプリングレートを考慮した$N$枚のフレームを取得します。例えば$L = 85$の場合、$S_{rate} = \lfloor\frac{85}{32} \rfloor = 2$ となり、フレーム取得のイメージは図4のようになります。
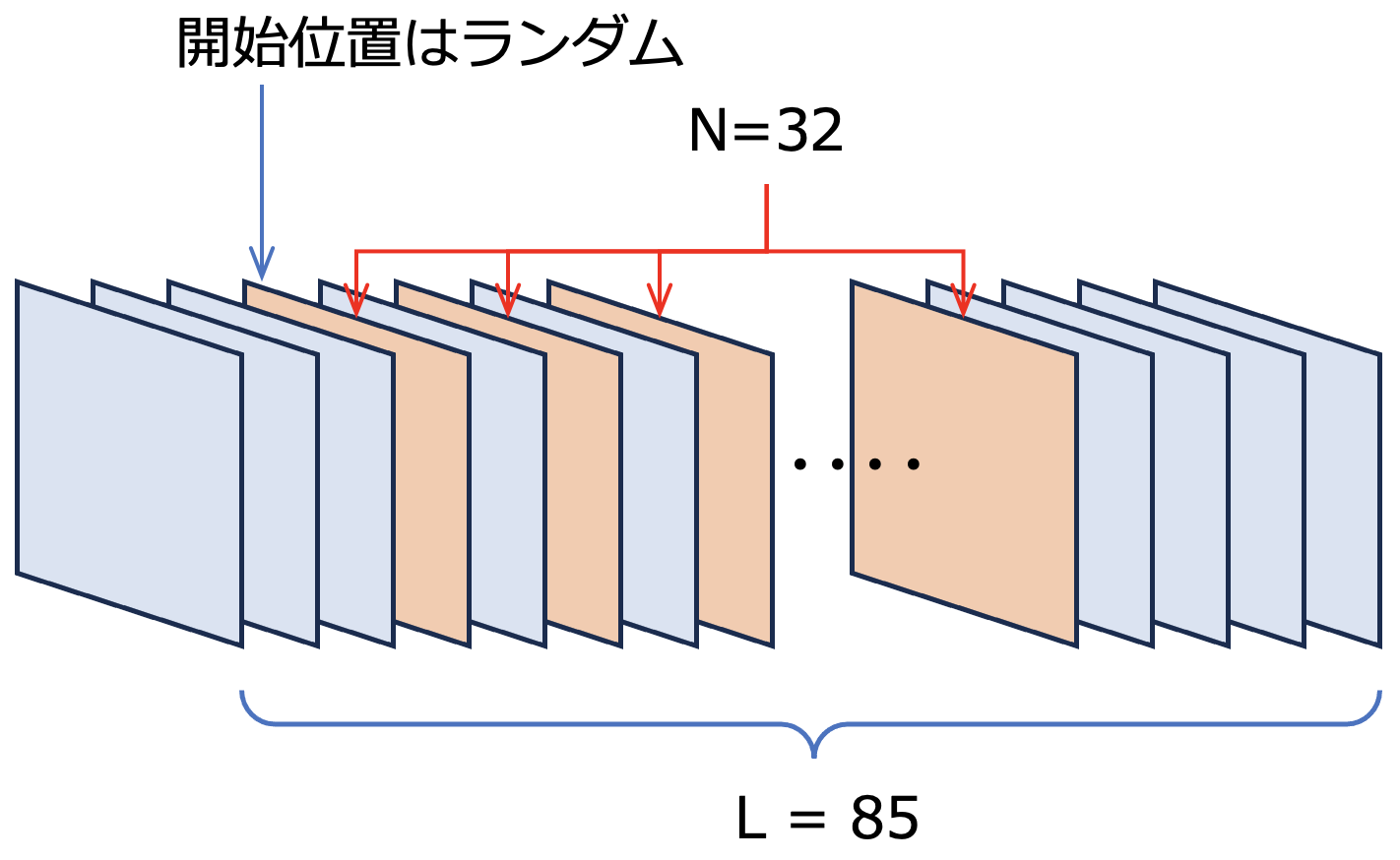
図4: フレーム取得のイメージ
6. ファインチューニングのコーディング
前セクションでの解説を元に、実際のコードを説明します。下記のコード(A)〜(H)を順番に実行します。
6.1. 準備
6.1.1. GPUチェック
まずはPCにGPUが搭載されていて、GPUが使用可能な状態かを調べます。以下のコードを実行すると、GPUが使用できる場合、device = 'cuda'となります。このdeviceは後に使用します。
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
GPUが使用できない場合、device = 'cpu'となります。この状態でもファインチューニングはできますが、パフォーマンスは低下します。
6.1.2. VideoDatasetクラス
PyTorchで動画データセットを扱えるように、torch.utils.data.Datasetクラスをカスタマイズして独自のVideoDatasetクラスを定義します。カスタマイズする背景や手法は、PyTorchのDatasetで動画データセットを扱えるようにするを参考にしてください。ここではその記事の内容をViViTモデル用に拡張しています。
まずは、VideoDatasetクラスの全体を掲載します。torch.utils.data.Datasetクラスを継承して、__init__, __len__, __getitem__の各関数をオーバーライドします。
from torch.utils.data import Dataset
import cv2
import av
class VideoDataset(Dataset):
def __init__(self, paths, labels, clip_length=32, image_processor=None):
# (1) 動画ファイルパスのリスト
self.paths = paths
# (2) 正解ラベルのリスト
self.labels = labels
# (3) 学習に使用するフレーム数
self.clip_length = clip_length
# (4) 学習に使用するフレームインデックスのリスト
self.indices = []
# (5) イメージプロセッサ
self.image_processor = image_processor
# (6) 動画ファイルごとに学習に使用するフレームインデックスの取得
for path in self.paths:
# (7) OpenCVで全フレーム数を取得
cap = cv2.VideoCapture(path)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# (8) フレームのサンプリングレートを取得
sample_frame_rate = frame_count // self.clip_length
# (9) フレーム数とサンプリングレートでインデックスのリストを取得
indices = sample_frame_indices(clip_len=clip_length, sample_frame_rate=sample_frame_rate, seg_len=frame_count)
# (10) インデックスリストをリストに保存
self.indices.append(indices)
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
# (11) 取得する動画のファイルパス
path = self.paths[index]
# (12) 取得する動画の正解ラベル
label = self.labels[index]
# (13) 取得する動画のインデックスリスト
indices = self.indices[index]
# (14) インデックスリストのフレームを取得
container = av.open(path)
frames = read_video_pyav(container=container, indices=indices)
# (15) ViViTモデルの入力形式に変換
inputs = self.image_processor(list(frames), return_tensors='pt')
# (16) 1番目の次元を削除
pixel_values = inputs.data["pixel_values"]
pixel_values = pixel_values.squeeze(0)
inputs.data["pixel_values"] = pixel_values
return inputs, label
6.1.2.1. __init__関数
__init__関数はまず、pathsとlabelsを引数として受け取り、(1)と(2)でインスタンス変数に保存しています。残りの引数clip_lengthは学習に使用するフレーム長さ(学習モデルに依存します。ここではclip_length=32)、image_processorはイメージプロセッサ(イメージプロセッサは後ほど説明します)です。同様に(3)と(5)でインスタンス変数に保存しています。
次に、(6)のfor文ブロックで、各動画のフレームインデックスのリストを取得しています。ブロックの中身を以下で説明します。
# (7) OpenCVで全フレーム数を取得
cap = cv2.VideoCapture(path)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
まず、(7)ではOpenCVの機能を利用して動画のフレーム数を取得しています。
# (8) フレームのサンプリングレートを取得
sample_frame_rate = frame_count // self.clip_length
次に、(8)でフレームのサンプリングレートを計算します。さきほど取得したframe_countは$L$に、clip_lengthは$N$に、sample_frame_rateは$S_{rate}$に相当します。
# (9) フレーム数とサンプリングレートでインデックスのリストを取得
indices = sample_frame_indices(clip_len=clip_length, sample_frame_rate=sample_frame_rate, seg_len=frame_count)
# (10) インデックスリストをリストに保存
self.indices.append(indices)
(9)ではsample_frame_indices関数を使用して、動画ファイルからサンプリングするフレームのインデックスのリストを取得します。sample_frame_indices関数の実装と説明は Video Vision Transformer:ViViTで動画を分類する を参照してください。
6.1.2.2. __len__関数
データセットのサイズ(データ数)を返します。
6.1.2.3. __getitem__関数
__getitem__関数へは引数としてindexが渡されます。このindexはデータセット中のデータの位置で、(11), (12), (13)で個別のデータを取得しています。
# (14) インデックスリストのフレームを取得
container = av.open(path)
frames = read_video_pyav(container=container, indices=indices)
# (15) ViViTモデルの入力形式に変換
inputs = self.image_processor(list(frames), return_tensors='pt')
(14)では、av.open()で動画ファイルを開き、read_video_pyav関数でindicesに格納されているインデックスのリストに従ってフレームを取得します。read_video_pyav関数の実装と説明は Video Vision Transformer:ViViTで動画を分類する を参照してください。
(15)では、取得したフレームを__init__関数で渡されたイメージプロセッサに渡しています。イメージプロセッサは、入力データのリサイズや正規化を行ってViViTモデルへの入力に適した形式へ変換し、テンソルで返します。
# (16) 1番目の次元を削除
pixel_values = inputs.data["pixel_values"]
pixel_values = pixel_values.squeeze(0)
inputs.data["pixel_values"] = pixel_values
ここで、inputsのデータ型はtransformers.BatchFeatureで、学習に使用されるデータ本体は、inputs.data['pixel_values']に格納されています。
inputs.data['pixel_values']はshape=(1, 32, 3, 224, 224)のテンソルです。これをそのまま__getitem__の戻り値とすると、データローダで生成した$n$個分のデータのミニバッチがshape=(n, 1, 32, 3, 224, 224)というサイズになってしまいました。ViViTモデルへの入力サイズはshape=(n, 32, 3, 224, 224)とする必要があるため、(16)で不要な次元を削除しています。
6.1.3. データセット
データセットは、1動画ファイルに1動作が含まれているものとします。それぞれのファイルパスをpathsにリストとして格納します。
paths = ['video001.mp4', 'video002.mp4', 'video003.mp4', 'video005.mp4', ... ]
動画ファイルの正解ラベルはlabelsに格納します。labelsの中身は文字列のリストで、pathsの各動画の正解ラベルに相当する番号がpathsと同じ順番で入っています。
labels = ['3', '5', '2', '1', ... ]
6.1.4. データセットのロード
from transformers import VivitImageProcessor
# kinetics-400学習済みViViTモデル用イメージプロセッサの取得
image_processor = VivitImageProcessor.from_pretrained("google/vivit-b-16x2-kinetics400")
# データセットのロード
data_set = VideoDataset(paths, labels, clip_length=32, image_processor=image_processor)
先ほど定義したVideoDatasetクラスをインスタンス化します。引数にはpathsとlabelsのリスト、フレーム数の32のほかに、イメージプロセッサを指定します。イメージプロセッサはkinetics-400の学習済みモデル専用のもので、そのモデルの入力に適したサイズ変更、正規化を提供します。
6.1.5. データセットの分割
from torch.utils.data import DataLoader, random_split
# データセットを分割
train_data, val_data = random_split(data_set, [0.8, 0.2])
# データセットでデータローダーを作成
train_loader = DataLoader(train_data, batch_size=10, shuffle=True)
val_loader = DataLoader(val_data, batch_size=10, shuffle=False)
ロードしたデータセットをランダムに 訓練:検証 = 8:2 の割合で分割します。分割後の訓練データ・検証データでデータローダを作成します。それぞれのバッチサイズは10、訓練データのみシャッフルしています。なお、モデル分割は機械学習の通常の手順として行いますが、この投稿では訓練データを扱うコードのみ掲載で、検証のコードには言及していません。
6.1.6. 学習済みモデルのロード
from transformers import VivitForVideoClassification
# 学習済みモデルをロード
model = VivitForVideoClassification.from_pretrained("google/vivit-b-16x2-kinetics400")
VivitForVideoClassification.from_pretrainedで学習済みViViTモデルをロードします。ロードされたデータをmodelに保持していますが、今後はこのmodelに対して操作や学習を行います。
6.1.7. 出力層の取り替え
まず、ロードしたViViTモデルがどのような構成かprint文で確認してみます。
print(model)
VivitForVideoClassification(
(vivit): VivitModel(
... 途中省略 ...
)
(classifier): Linear(in_features=768, out_features=400, bias=True)
)
printの出力によると学習済みViViTモデルは、VivitForVideoClassificationクラスインスタンスの直下にViViTクラスインスタンスとLinearクラスインスタンスが配置される構成となっています。Linearクラスのインスタンス変数名はclassifierのようです。out_features=400とあるので、この変数が置き換える出力層であるようです。そこで、classifierを新たなLinearで置き換えます。
from torch import nn
# 新たな出力層
classifier = nn.Linear(in_features=768, out_features=64)
# デバイスに転送
classifier.to(device)
#置き換え
model.classifier = classifier
このコードを実行した後、同じようにprint(model)します。
VivitForVideoClassification(
(vivit): VivitModel(
... 途中省略 ...
)
(classifier): Linear(in_features=768, out_features=64, bias=True)
)
出力層のclassifierが、out_features=64のLinearと置き換わっていることが分かります。
6.1.8. 変数をデバイスに転送する関数
def to_device(device, inputs, labels):
# (1) inputsのデータ本体を転送
if inputs:
pixel_values = inputs.data["pixel_values"]
pixel_values = pixel_values.to(device)
inputs.data["pixel_values"] = pixel_values
# (2) 文字列リストのlabelをlong, テンソルに変換してから転送
if labels:
# 出力層からの出力がNクラスのとき、損失関数に渡すラベル範囲は0~(N-1)である必要がある
labels = [int(label) - 1 for label in labels]
labels = torch.tensor(labels).long()
labels = labels.to(device)
return inputs, labels
device='cuda'の場合のために、変数をGPUに転送する関数です。以下のトレーニングのコードでは、データローダからミニバッチを受け取ったタイミングでこの関数を呼んでいます。データローダからの戻り値は(inputs, labels)のタプルとなっています。
(1)でinputsから中身であるinputs.data["pixel_values"]を取り出し、デバイスに転送しています。
labelsが正解ラベルをテキストのリストとして保持しているため、(2)のブロックではまずintに変換し、long型のテンソルに変換してからデバイスに転送しています。
6.2. 学習
以下のコードで学習を開始します。学習の方法はPyTorchの標準的な学習方法と同じです。データセットは訓練用と検証用に分割しましたが、ここでは訓練用コードのみ掲載しています。
import numpy as np
import torch
from torch import nn
import torch.optim as optim
from tqdm import tqdm
# 学習率
lr = 0.001
# 損失関数
criterion = nn.CrossEntropyLoss()
# 最適化関数
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
# 学習履歴
history = np.zeros((0, 3))
# エポック数
epochs = 10
# (1) エポックごとに繰り返し
for epoch in range(0, epochs):
# 1エポックあたりの精度
epoch_accuracy = 0
# 1エポックあたりの累積損失
epoch_loss = 0
# 1エポックあたりのデータ累積件数
total_batch_size = 0
model.train()
# (2) ミニバッチごとに繰り返し
for inputs, labels in tqdm(train_loader):
# 1バッチのデータ件数
batch_size = len(labels)
# 1エポックのデータ累積件数
total_batch_size += batch_size
# (3) inputsとlabelsをテンソルに変換してGPUに送る
inputs, labels = to_device(device, inputs, labels)
# 勾配の初期化
optimizer.zero_grad()
# (4) 予測計算
outputs = model(**inputs)
# (5) 損失計算
logits = outputs.logits
loss = criterion(logits, labels)
# 勾配計算
loss.backward()
# パラメータ修正
optimizer.step()
# (6) 予測ラベル導出
max_values, indices = torch.max(logits, dim=1)
# このエポックでの損失と精度の累積値
# (7)
epoch_loss += loss.item() * batch_size
# (8)
epoch_accuracy += (indices == labels).sum().item()
# (9) 精度計算
mean_train_accuracy = epoch_accuracy / total_batch_size
# (10) 損失計算
mean_train_loss = epoch_loss / total_batch_size
# 結果表示
epoch_num = epoch + 1
print(
f'Epoch [{epoch_num}/{epochs}], loss: {mean_train_loss:.5f} acc: {mean_train_accuracy:.5f}'
)
# 記録
item = np.array([epoch_num, mean_train_loss, mean_train_accuracy])
# (11)
history = np.vstack((history, item))
(1)のfor文ブロックで全ての処理がエポックごとに繰り返され、精度や損失など結果は(11)のhistoryに格納されます。(2)では作成したデータローダを使用してミニバッチ処理をしています。
(4)でmodelに学習用データを渡していますが、**inputとして渡さないといけない点に注意が必要です。modelからの戻り値outputsはImageClassifierOutputというクラスのインスタンスで、推論の結果はoutputs.logitsです。logitsはshape=(n, 64)となっていて、ミニバッチのデータ数$n$それぞれの推論結果が格納されています。(6)で各データの最大値とそのインデックスを取得します。
損失は平均計算されているとのことなので、(7)では平均前の値に戻しています。(7)と(8)の損失と精度は、そのエポックでの累積値となっています。(9), (10)でバッチサイズあたりの平均を計算して、この学習の結果としています。
7. 結果例
図5と図6は、とある公開データセット(64クラス, データ数3,200)でファインチューニングを行った結果です。エポック数は10と少ないですが、かなりの短期間で精度が向上していることが分かります。
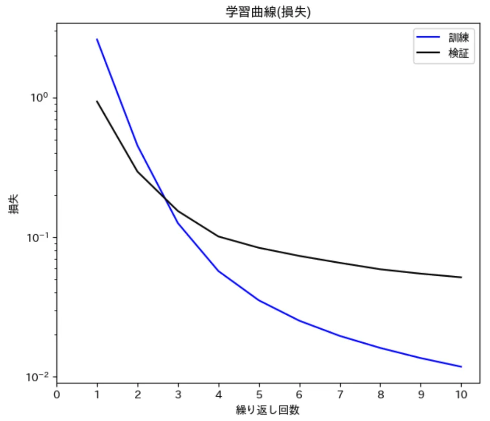 図5:学習曲線(損失)の例
図5:学習曲線(損失)の例
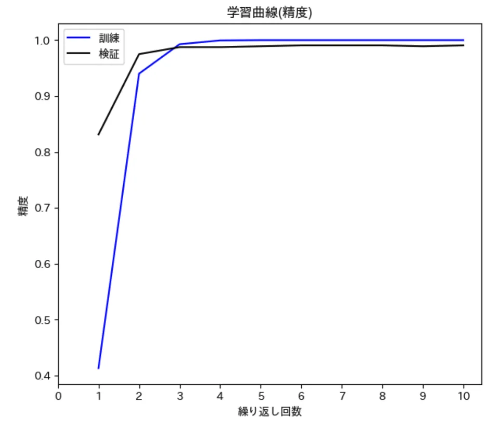 図6:学習曲線(精度)の例
図6:学習曲線(精度)の例
参考文献
[1] 最短コースでわかる PyTorch&深層学習プログラミング, 赤石 雅典
[2] Video Vision Transformer (ViViT)