最近、業務で文章からキーフレーズを抽出するアルゴリズムを選定する機会があったので、その際に調べたアルゴリズム間の比較を簡単にまとめておこうと思います。
環境
- Ubuntu 22.04; Intel Core i7 9700K
- Python3.10
比較したアルゴリズム
すべてアルゴリズムを1から実装はせず、Pythonを使ってパッと試せるアルゴリズムをいくつか試しました。カッコ内はライブラリ名です。自分で中身を書かなくてもこれだけの数のアルゴリズムをライブラリから利用できるのは嬉しいですね。
- YAKE (textacy)
- SGRank (textacy)
- sCAKE (textacy)
- TextRank (textacy)
- RAKE (rake-ja)
- MultipartiteRank (pke)
- PositionRank (pke)
- TopicRank (pke)
textacy内のアルゴリズムでは日本語パイプラインとして ja_core_news_sm を使いました。
python -m spacy download ja_core_news_sm
想定するデータ形式
扱っていたデータは、(id, text)という2つのカラムからなるCSV形式のデータで、データ数のオーダーは100万行でした。さらに、キーフレーズ抽出は毎日行うことを想定したものだったので試すときには速度を重視して見ていました。
また、1データあたりのテキストの平均長さは300字です。
ソースコード
下のようなコードを親クラスにして、各アルゴリズムで extract_phrases を実装していく形を取りました。
import pandas as pd
import neologdn
import re
import string
from statistics import StatisticsError
from tqdm import tqdm
import textacy
from textacy.extract.keyterms import yake, sgrank, textrank, scake
from rake_ja import Tokenizer, JapaneseRake
from pke.unsupervised import MultipartiteRank, PositionRank, TopicRank
class KeywordExtractor:
def __init__(
self,
data: pd.DataFrame,
) -> None:
self.data = data
self.data = self.data.fillna("")
# 前処理
def _preprocess(self, x: str) -> str:
emoji_pattern = re.compile(
"["
"\U0001F600-\U0001F64F" # emoticons
"\U0001F300-\U0001F5FF" # symbols & pictographs
"\U0001F680-\U0001F6FF" # transport & map symbols
"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+",
flags=re.UNICODE,
)
x = emoji_pattern.sub(r"", x)
x = neologdn.normalize(x)
x = re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-]+", "", x)
x = re.sub(r"[!-/:-@[-`{-~]", r" ", x)
x = re.sub("[■-♯]", " ", x)
x = re.sub(r"(\d)([,.])(\d+)", "\1\3", x)
x = re.sub(r"\d+", "0", x)
x = re.sub(r"・", ", ", x)
x = re.sub(r"[\(\)「」【】]", "", x)
return x
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
raise NotImplementedError
def apply_keywords_extract(self) -> pd.DataFrame:
tqdm.pandas()
self.data[["scores", "keywords"]] = self.data.progress_apply(
self.extract_phrases, axis=1, result_type="expand"
)
return self.data
YAKE
class YAKE(KeywordExtractor):
def __init__(self, data: pd.DataFrame):
super().__init__(data)
self.ja = textacy.load_spacy_lang("ja_core_news_sm")
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
doc = textacy.make_spacy_doc(self._preprocess(data["text"]), lang=self.ja)
try:
keywords_with_score = [
(kps, score) for kps, score in yake(doc, normalize="lemma", topn=5)
]
keywords = [
keywords_with_score[i][0] for i in range(len(keywords_with_score))
]
# YAKEで計算されるスコアは数字が小さいほど順位が高い
scores = [
-keywords_with_score[i][1] for i in range(len(keywords_with_score))
]
except StatisticsError:
keywords = []
scores = []
return scores, keywords
SGRank
class SGRank(KeywordExtractor):
def __init__(self, data: pd.DataFrame):
super().__init__(data)
self.ja = textacy.load_spacy_lang("ja_core_news_sm")
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
doc = textacy.make_spacy_doc(self._preprocess(data["text"]), lang=self.ja)
keywords_with_score = [
(kps, score) for kps, score in sgrank(doc, normalize="lemma", topn=5)
]
keywords = [keywords_with_score[i][0] for i in range(len(keywords_with_score))]
scores = [keywords_with_score[i][1] for i in range(len(keywords_with_score))]
return scores, keywords
TextRank
class TextRank(KeywordExtractor):
def __init__(self, data: pd.DataFrame):
super().__init__(data)
self.ja = textacy.load_spacy_lang("ja_core_news_sm")
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
doc = textacy.make_spacy_doc(self._preprocess(data["text"]), lang=self.ja)
keywords_with_score = [
(kps, score) for kps, score in textrank(doc, normalize="lemma", topn=5)
]
keywords = [keywords_with_score[i][0] for i in range(len(keywords_with_score))]
scores = [keywords_with_score[i][1] for i in range(len(keywords_with_score))]
return scores, keywords
sCAKE
class sCAKE(KeywordExtractor):
def __init__(self, data: pd.DataFrame):
super().__init__(data)
self.ja = textacy.load_spacy_lang("ja_core_news_sm")
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
doc = textacy.make_spacy_doc(self._preprocess(data["text"]), lang=self.ja)
keywords_with_score = [
(kps, score) for kps, score in scake(doc, normalize="lemma", topn=5)
]
keywords = [keywords_with_score[i][0] for i in range(len(keywords_with_score))]
scores = [keywords_with_score[i][1] for i in range(len(keywords_with_score))]
return scores, keywords
Rake
class Rake(KeywordExtractor):
def __init__(self, data: pd.DataFrame):
super().__init__(data)
self.tokenizer = Tokenizer()
self.punctuations = string.punctuation + ",.。、"
self.stopwords = (
"か な において にとって について する これら から と も が は て で に を は し た の ない よう いる という".split()
+ "により 以外 それほど ある 未だ さ れ および として といった られ この ため こ たち ・ ご覧".split()
)
self.rake = JapaneseRake(
max_length=3,
punctuations=self.punctuations,
stopwords=self.stopwords,
)
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
tokens = self.tokenizer.tokenize(self._preprocess(data["text"]))
self.rake.extract_keywords_from_text(tokens)
scrs_kwds = self.rake.get_ranked_phrases_with_scores()
if len(scrs_kwds) > 0:
return [x[0] for x in scrs_kwds], [x[1] for x in scrs_kwds]
else:
return [], []
MultipartiteRank
class MultipartiteRank_(KeywordExtractor):
def __init__(self, data: pd.DataFrame) -> None:
super().__init__(data)
self.extractor = MultipartiteRank()
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
self.extractor.load_document(
input=data["text"], language="ja", normalization=None
)
self.extractor.candidate_selection(pos={"NOUN", "PROPN", "ADJ", "NUM"})
self.extractor.candidate_weighting()
kwds_scrs = self.extractor.get_n_best(n=5)
if len(kwds_scrs) > 0:
return [x[1] for x in kwds_scrs], [x[0] for x in kwds_scrs]
else:
return [], []
PositionRank
class PositionRank_(KeywordExtractor):
def __init__(self, data: pd.DataFrame) -> None:
super().__init__(data)
self.extractor = PositionRank()
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
self.extractor.load_document(
input=data["text"], language="ja", normalization=None
)
self.extractor.candidate_selection()
self.extractor.candidate_weighting()
kwds_scrs = self.extractor.get_n_best(n=5)
if len(kwds_scrs) > 0:
return [x[1] for x in kwds_scrs], [x[0] for x in kwds_scrs]
else:
return [], []
TopicRank
class TopicRank_(KeywordExtractor):
def __init__(self, data: pd.DataFrame) -> None:
super().__init__(data)
self.extractor = TopicRank()
def extract_phrases(self, data: pd.Series) -> tuple[list[float], list[str]]:
self.extractor.load_document(
input=data["text"], language="ja", normalization=None
)
self.extractor.candidate_selection(pos={"NOUN", "PROPN", "ADJ", "NUM"})
self.extractor.candidate_weighting()
kwds_scrs = self.extractor.get_n_best(n=5)
if len(kwds_scrs) > 0:
return [x[1] for x in kwds_scrs], [x[0] for x in kwds_scrs]
else:
return [], []
比較結果
実行時間
500行のCSVを使って実行時間の計測を行いました。
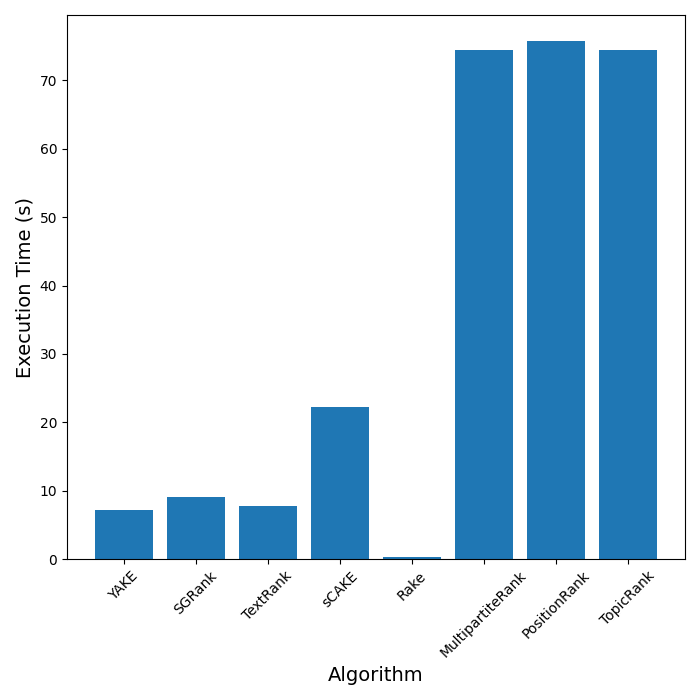
実行時間はRakeがダントツになっています(Rapid Automatic Keyword Extractorなだけありますね)。最後3つがかなり遅くなっているのはグラフ系アルゴリズムだからということもありそうですが、ライブラリ(pke)のせいという要素もあるでしょうか?
キーフレーズの質
質を定量的に確かめるのは難しいので、人間の目でどのようなキーフレーズが抽出されているか見てみます。試しに、私のWantedlyのプロフィールを入力にしてみます。
https://www.wantedly.com/id/hayashi_yudai
| アルゴリズム | キーフレーズ |
|---|---|
| YAKE | ['GIT Java', 'データ', 'ユーザー', '良い', 'python c'] |
| SGRank | ['django ニューラル ネットワーク python c', 'ウォンテッドリー 株式 会社', '機械 学習 sqlite', '応用 物理', 'データ サイエンティスト'] |
| TextRank | ['django ニューラル ネットワーク python c', '機械 学習 sqlite', 'ウォンテッドリー 株式 会社', 'データ サイエンティスト', 'データ エンジニア'] |
| sCAKE | ['データ サイエンティスト', 'データ エンジニア', 'ユーザー', '良い 体験', '良い 仕事'] |
| Rake | ['ウォンテッドリー 株式 会社', '応用 物理', 'データ サイエンティスト', 'データ エンジニア', 'データ'] |
| MultipartiteRank | ['データ', 'ユーザー', '良い 体験', 'ニューラル ネットワーク', 'django'] |
| PositionRank | ['データ サイエンティスト', 'データ エンジニア', 'データ', 'ウォンテッドリー 株式 会社', '良い 体験'] |
| TopicRank | ['データ', 'ニューラル ネットワーク', '良い 体験', 'ユーザー', 'django'] |
最初3つはキーフレーズとしては微妙なものが多い気がしますね。1つ1つが単語を列挙しただけみたいな。後ろ3つはかかる時間は長いですがキーフレーズとして良いものが出ている印象があります。時間がかかりすぎますが、、、。
雑に試した見た感じですが、こうしてみてみるとRakeが速度も早くて質もまあまあ良さそうということがわかりました。