この記事について
Pandasの使い方を死ぬほどわかりやすく解説していきます。
この記事をちゃんと読めばもうOKです。
Pandasを始める前にCSVファイルについての理解
全くの初心者の方は、Pandasの勉強を始める前にちょっとCSVファイルの話を聞いてください。
CSVファイルとは
CSV(comma separated value)は、読んで字の如く「値(value)をコンマ(,)で分けた(separated)」ファイルのこと。
具体例を見ていきます。
下記のようなファイルがあったとします。
使用言語,経験年数,年収
Python,10,"¥60,000,000.00"
Ruby,2,"¥3,500,000.00"
Swift,4,"¥5,000,000.00"
これをexcelやgoogleスプレットシートで開くと以下のように表示されます。
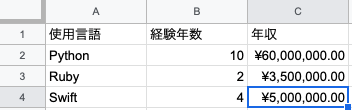
結論頭に入れてほしいことは、excelのファイルの「,」区切り版ぐらいでいいかもしれません。
目次
・Pandasとは
・インストール手順
・基本的なデータ型
・データの取り出し方(loc、iloc、head、tailとか色々)
・データ読み込み、出力
・データのソート
・欠損値の処理
データを操作する
・Series編
・DataFrame編
・統計処理
Pandasとは
Pandasとは、Pythonでデータ分析を効率的に行うためのライブラリ。なんか抽象的でなんだかわからないので、具体的な話をします。
機械学習やデータ分析を行う時その学習のためのデータがちゃんと学習するために整理されていないことが多いです。
そこでこのPandasを用いると便利にデータを成形することができます。
この機械学習を行う前のこの工程をデータの前処理(Data Preprocessing)と言います。
データの前処理といえばPandasを使う!!!!!!!!!
と頭に入れておいてください。
インストール手順
Anacondaを使ってPythonをインストールした方は、もうインストールは済んでいると思われます。
もしインストールされていなかったら
pip install pandas
Pandasを使う
Pandasを使うときはPandasのライブラリを読み込ます必要があります。
import pandas as pd
いちいち毎回pandasで呼び出すのはめんどくさいので一般的にはpdとしちゃいます。
データ型(SeriesとDataFrame)
Series
Seriesは1列のみのデータ型です。
難しく言うと、1次元データ構造。
import pandas as pd
l = [1,2,3,4,5]
series = pd.Series(l)
print(series)
==========>
0 1
1 2
2 3
3 4
4 5
dtype: int64
左側の数字はindex(行ラベル)、右側はシリーズのデータです。
DataFrame(データフレーム)
データフレームは、2次元のラベル付きデータ構造で、Pandasで一番使われるデータ構造です。
excelやスプレットシートのデータを想像するとわかりやすいと思います。
import pandas as pd
df = pd.DataFrame({
'プログラム言語' :['Python', 'Ruby', 'Go'],
'経験年数' : [1, 1, 2],
'年収' : [3000000, 2800000, 16900000]
})
print(df)
===========>
プログラム言語 経験年数 年収
0 Python 1 3000000
1 Ruby 1 2800000
2 Go 2 16900000
こんなイメージ

ちなみにデータフレーム型では、行ラベル(index)で自動的にソートされますので、並びが変わってしまう場合があります。
データの取り出し方
シリーズ
シリーズに関してはそのまま行ラベルでアクセスすればOKです。
import pandas as pd
l = [1,2,3,4,5]
series = pd.Series(l)
print(series[1])
==========>
2
データフレーム型
問題はこちらです。色々取り出し方があるので、順番に見ていきましょう。
前提として以下のようなデータがあるとします。
import pandas as pd
df = pd.DataFrame({
'プログラム言語' :['Python', 'Python','Ruby', 'Go','C#','C#'],
'経験年数' : [1, 1, 2, 3, 1,3],
'年収' : [3000000, 2800000, 16900000,1230000,2000000,500000],
'年齢' : [21,22,34,55,11,8]
})
print(df)
============>
プログラム言語 経験年数 年収 年齢
0 Python 1 3000000 21
1 Python 1 2800000 22
2 Ruby 2 16900000 34
3 Go 3 1230000 55
4 C# 1 2000000 11
5 C# 3 500000 8
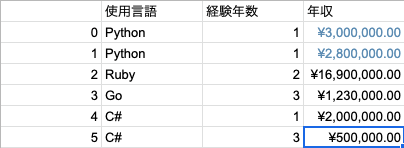
特定の列を取得
print(df['プログラム言語'])
# またはdf.'プログラム言語'でも同様の結果が得られる。
=================>
0 Python
1 Python
2 Ruby
3 Go
4 C#
5 C#
Name: プログラム言語, dtype: object
特定の行を取得
print(df[0:2])
===============>
プログラム言語 経験年数 年収 年齢
0 Python 1 3000000 21
1 Python 1 2800000 22
列の取得とわけわからなくなりそうなので、細かい説明をします。
df[]で普通にキーを入れると、pandasはこれは列名であると判断します。
df[スライス]で入力するとPandasはこれを行ラベルであると判断します。
特定の「列と行」の取得(locとiloc)
今回は行と列両方を指定します。
loc
locの基本的な使い方
loc[行の指定,列の指定]
locでは行の名前、列の名前を指定します。
iloc
ilocの基本的な使い方
iloc[行の番号、列の番号]
ilocでは行の番号、列の番号で指定します。
実際に動かす
import pandas as pd
df = pd.DataFrame({
'プログラム言語' :['Python', 'Python','Ruby', 'Go','C#','C#'],
'経験年数' : [1, 1, 2, 3, 1,3],
'年収' : [3000000, 2800000, 16900000,1230000,2000000,500000],
'年齢' : [21,22,34,55,11,8]
})
print(df.loc[0:2,'プログラム言語'])#こちらはスライスの最後の値も含まれます。あくまで行の名前しているからです。
print(df.iloc[0:2,0])#こっちではスライスの最後の値は含まれません!
=================>
0 Python
1 Python
2 Ruby
Name: プログラム言語, dtype: object
0 Python
1 Python
Name: プログラム言語, dtype: object
一応コメントを読んでください。出力結果に若干の違いがあります。
ちなみに存在していない列にアクセスするとNaNが返ってきます。
head()とtail()
head()を使うと先頭の5件
tail()を使うと後ろの5件にアクセスすることができます。
print(df.head())
==================>
プログラム言語 経験年数 年収 年齢
0 Python 1 3000000 21
1 Python 1 2800000 22
2 Ruby 2 16900000 34
3 Go 3 1230000 55
4 C# 1 2000000 11
print(df.tail())
==================>
プログラム言語 経験年数 年収 年齢
1 Python 1 2800000 22
2 Ruby 2 16900000 34
3 Go 3 1230000 55
4 C# 1 2000000 11
5 C# 3 500000 8
# 何件にアクセスするかを引数で指定できる。
print(head(2))
====================>
プログラム言語 経験年数 年収 年齢
0 Python 1 3000000 21
1 Python 1 2800000 22
print(tail(2))
=====================>
プログラム言語 経験年数 年収 年齢
4 C# 1 2000000 11
5 C# 3 500000 8
条件を指定して行を抽出する(query)
query()を使うことで、データフレームの値を指定して、それを含む行を抽出することが可能です。
普通に比較演算子を用いて指定します。
import pandas as pd
df = pd.DataFrame({
'プログラム言語' :['Python', 'Python','Ruby', 'Go','C#','C#'],
'経験年数' : [1, 1, 2, 3, 1,3],
'年収' : [3000000, 2800000, 16900000,1230000,2000000,500000],
'年齢' : [21,22,34,55,11,8]
})
print(df.query('経験年数 <= 2'))
========================>
プログラム言語 経験年数 年収 年齢
0 Python 1 3000000 21
1 Python 1 2800000 22
2 Ruby 2 16900000 34
4 C# 1 2000000 11
データの入出力
Pandasには、データ入力そして操作後にデータをファイルとして出力する機能がある。
ここでは、関数の紹介だけをします。
import pandas as pd
pd.read_CSV('ファイル名', header, sep,...)#read_CSVではデフォルトの区切り文字は「,」
pd.read_table('ファイル名', header, sep....)# read_tableではデフォルトの区切り文字は「\t」
# 出力としては、
pd.to_csv('ファイル名')
pd.to_excel('ファイル名')
pd.to_html('ファイル名')
# 等がある。
データのソート
大きく分けて2つ方法がある。
1.インデックス(行名・列名)を使う方法と値に基づいてソートする方法...sort_index()
2.列の値の大きさでソートする方法...sort_values()
import pandas as pd
df = pd.DataFrame({
'プログラム言語' :['Python', 'Python','Ruby', 'Go','C#','C#'],
'経験年数' : [1, 1, 2, 3, 1,3],
'年収' : [3000000, 2800000, 16900000,1230000,2000000,500000],
'年齢' : [21,22,34,55,11,8]
})
print(df.sort_index(ascending=False))
===============================>
プログラム言語 経験年数 年収 年齢
5 C# 3 500000 8
4 C# 1 2000000 11
3 Go 3 1230000 55
2 Ruby 2 16900000 34
1 Python 1 2800000 22
0 Python 1 3000000 21
print(df.sort_values(by="年収") )
=================================>
プログラム言語 経験年数 年収 年齢
5 C# 3 500000 8
3 Go 3 1230000 55
4 C# 1 2000000 11
1 Python 1 2800000 22
0 Python 1 3000000 21
2 Ruby 2 16900000 34
欠損値の処理
データ解析や機械学習を行う上で多くの欠損値で出くわすことになる。
欠損値とはデータのうち欠けている部分のことである。(アンケートの未回答の欄とか)
coming soon....