こんにちは。私がAidemyでデータ分析講座コースを受講いたしました。今回は学んだスキルを活用して、上場企業を株価予測をしてみました。
※私の環境:
Python3
Chrome
Google Colaboratory
Windows 10
目次
1.目的
2. データセット
3. 機械学習モデル
4. 予測モデルの構築と検証
5. 結果
6. 反省
1.目的
上場会社の株価データセットを用いて、株価予測するLSTMの機械学習モデルを構築すること。
2.データセット
Yahoo Financeである上場企業Lasertec(6920.T)の時列データ
3.機械学習モデル
LSTM(Long Short-Term Memory: ニューラルネットワークの一種で、長期的な依存関係を学習することができる特徴ある。
4.予測モデルの構築と検証
4-1. ライブラリのインポート
import keras
import pandas as pd
from datetime import datetime
import numpy as np
from matplotlib import style
import matplotlib.pyplot as plt
import yfinance as yf
import warnings
warnings.filterwarnings('ignore')
4-2. データセットの読み込む
# yahoo finance からLasertecの2018年1月1日以来の時列データセットを抽出し、データの形式を確認
df = yf.download("6920.T",start='2018-01-01',end = datetime.now(),interval="1d")
df.head()
Output 1
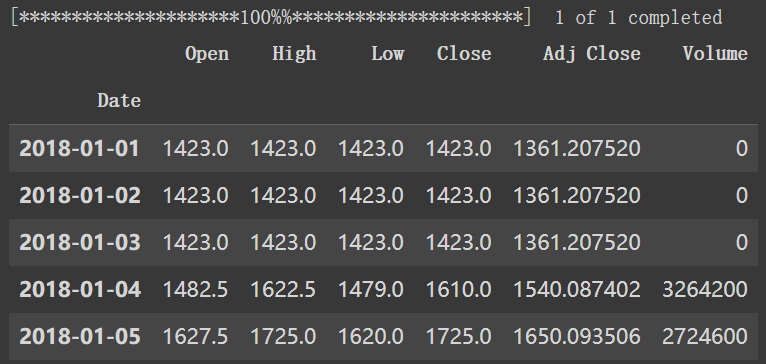
ここでは、取得できたデータの特徴量は分かるようになりました。
open: 当日始めた株売買の株価
High: 当日一番高い株価
Low:当日一番低い株価
Close: 当日株売買終了時点の株価
Adj Close:株価調整後の終値
今回は株売買終了時点の株価「Close」列のデータセットを利用する。
# datasetをplotして可視化
plt.figure(figsize=(16,6))
plt.title('Close Price History')
plt.plot(df['Close'])
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close Price of Lasertec', fontsize=18)
plt.show()
Output 2
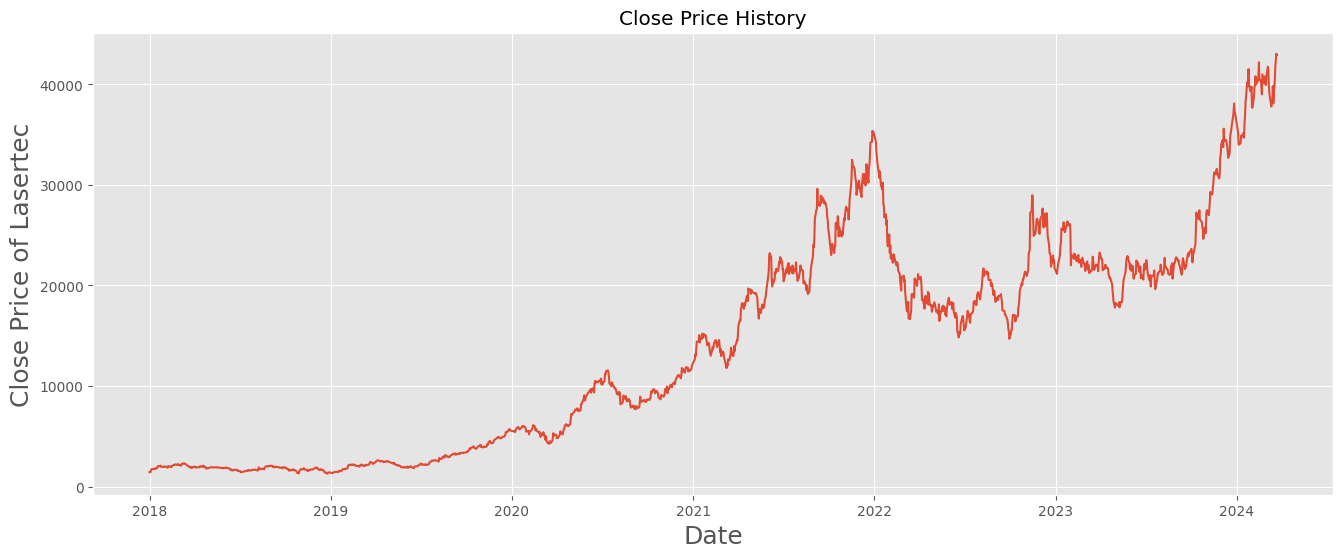
このグラフは2018年1月1日から今までの株価グラフを示している。データセットは完全に揃っていることを確認できます。
4-3.データの前処理
取得したデータセットでは、数値の尺度が異なり、学習効果をよくするため、統一することが必要です。ここはsklearnのMinMaxScalerを利用して、データセットを正規化し、データを0~1の範囲にスケーリングします。
# Closeコラムのみ抽出
data = df.filter(["Close"])
dataset = data.values
# データの正規化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(dataset)
scaled_data
Output 3
4-4.データの分割
# データを訓練データと検証データに分割し、7割が訓練用に設定
training_data_len = int(np.ceil(len(dataset) * 0.7))
training_data_len
train_data = scaled_data[0: int(training_data_len), :]
train_data.shape
Output 4

4-5. 訓練データの処理
LSTMは、データが特定の形式(通常は3D配列)であることが必要です。ここは60単位のタイムステップ(time_step=60)を作成し、次にNumpyを使用してそれを配列に変換します。x_trianの学習例として、60単位のタイムステップをそれぞれ1つの特徴を含む3次元配列に変換します。
#訓練データの取得
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i,0])
y_train.append(train_data[i,0])
# 訓練データのreshape
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train,(x_train.shape[0], x_train.shape[1], 1))
x_train.shape
Output 5

4-6. モデル構築(LSTM)
kerasでLSTMアルゴリズムを作成、訓練データを使って学習
# kerasから必要なライブラリを導入
from keras.models import Sequential
from keras.layers import Dense, LSTM
#LSTMモデル構築
model = Sequential()
model.add(LSTM(128,return_sequences = True, input_shape=(x_train.shape[1], 1)))
model.add(LSTM(64, return_sequences = False))
model.add(Dense(25))
model.add(Dense(1))
model.compile(optimizer='adam',loss='mean_squared_error')
#訓練用モデル構築
model.fit(x_train, y_train, batch_size = 1, epochs =1)
Output 6

4-7. 予測データの作成
検証用データでも4-5の通り、LSTMを利用するため、検証用データも同じの変換を実施します。
# 検証用データを取得とデータ変換
test_data = scaled_data[training_data_len - 60: , :]
x_test = []
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i,0])
y_test = dataset[training_data_len:, :]
x_test = np.array(x_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1],1))
# 予測値の算出
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
# RMSEを利用して予測精度を確認
from sklearn.metrics import mean_squared_error
test_score = np.sqrt(mean_squared_error(y_test,predictions))
print('Test Score: %.2f RMSE' % (test_score))
Output 7

4-8. 予測値の可視化
データをプロットします。
train = data[: training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize = (16,6))
plt.title('LSTM Model')
plt.xlabel('Date', fontsize =18)
plt.ylabel('Close Price of Lasertec', fontsize =18)
plt.plot(train['Close'])
plt.plot(valid[['Close','Predictions']])
plt.legend(['Train','Real','Prediction'], loc='lower right')
plt.show()
Output 8
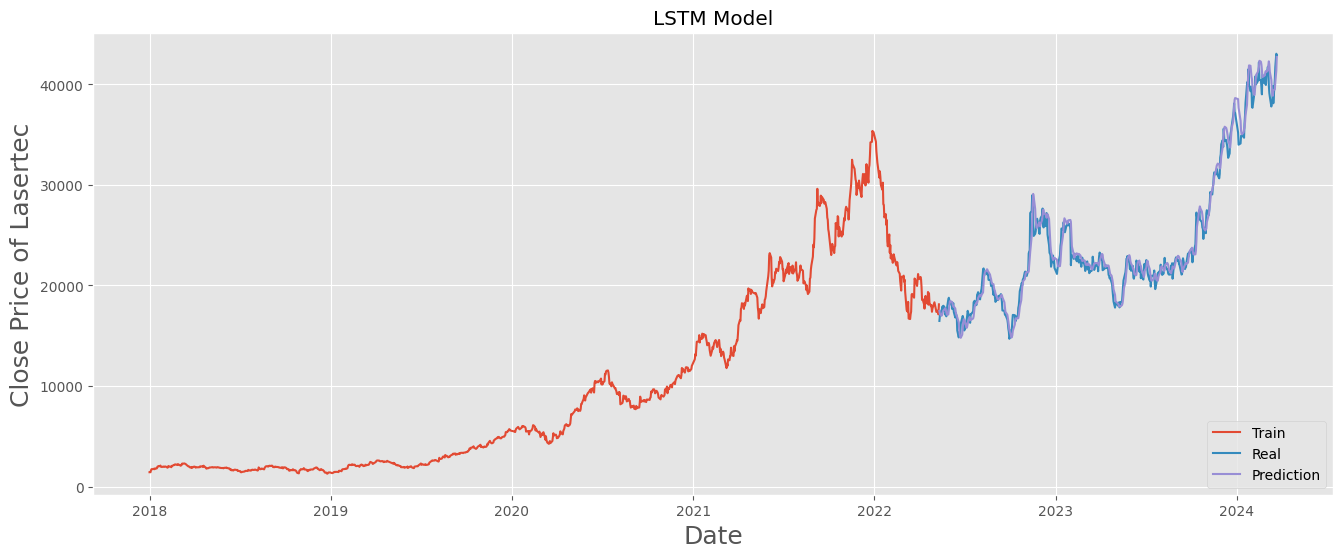
このグラフではReal(テスト値)部分とPrediction(予測値)部分は大きな離れが出なかったので、見た目は精度が高くできたと思います。
5. 結果
LSTMモデルを利用して、Lasertecの株価予測モデルを構築できました。しかし、株価は多くの影響に受けられやすいので、参考程度で実用レベルにならないと思います。
6. 反省
データ予測でまだ別のモデルもできますので、LSTMモデルは予測精度が高いモデルかどうか、まだ分かりません。本来は各モデルを構築して比べて考察する予定だったが、想像より時間かかりましたので、今回は諦めました。今度、落ち着いてから、また作ってみようと思います。