この記事について
Gemini 2.0 FlashのAPIを使用して画像分類を試した際のざっくりまとめ。
実施したモチベーション
物体検出関連の業務でしばしば
物体検出用のアノテーションデータのクラス定義が変更となり、あるクラスを複数クラスに分ける
という場面に遭遇。
しかし再アノテーションのコストはなるべく小さくしたいという条件もセットになりがちなため、変更の方針が適切かの確認は低コストで行いたい。(さらに言えばアノテーション修正の自動化も)
そこで Gemini 2.0 Flashなどの強力なLLM/VLMによって物体検出のラベルの自動修正に利用できないか の検証を行う。
実験
方針
問題設定
物体検出データセットの信号機クラスを点灯色のクラスに分類する。
上記設定の理由
- 分類結果で物体検出データセットのラベルを修正することで、信号機の点灯色のクラスを持つ物体検出データセットが作成できる
- 物体検出の矩形で切り抜けば画像分類用の画像にできる
- 信号機の点灯色はRGB値による単純な分類ができない
- 赤色と黄色は似たRGB値になる場合も多い
- 信号機の発光が強いと白くなる
- 周辺の明るさなど様々な影響で画像での見かけ上の色味が変わる
- 小さい被写体に対する分類能力を確認できる
より具体的には
赤色と緑色を各50枚ずつの計100枚のデータセットを作成し、
各画像をGemini 2.0 Flashで「red」、「yellow」、「green」、「unsure」の4クラスのいずれかに分類させた結果を確認する。
データ作成
- 元データはMS COCOデータセットのval2017を使用
- 信号機クラス「traffic light」の矩形で画像を切り抜き
- 切り抜く際、上下左右それぞれに10ピクセルのマージンを付与
- 切り抜いた画像を目視で赤色、黄色、緑色、不明の4クラスに分類
- 不明は信号機が横や反対を向いており点灯部分が写っていない場合や、全消灯の場合
- 赤色と緑色を(ファイル名ソートの先頭)50枚ずつ抽出して信号分類データセットとする
最終的に黄色クラスを含めなかったのは、val2017に含まれる黄色信号が圧倒的に少なかったため。
全て目視で分類したわけではないが、分類した約200枚中の各クラスの割合は以下の通り。
| 色 | 割合 |
|---|---|
| 赤色 | 約44% |
| 黄色 | 約 1% |
| 緑色 | 約28% |
| 不明 | 約27% |
分類後の信号機画像
赤色





緑色





Geminiでの画像分類実施
準備
実行環境はGoogle Colabを使用する。
Google AI StudioでGemini 2.0 FlashのAPIを使用するためのAPIキーを取得。
取得したAPIキーをGoogle Colabのシークレットタブで登録。
この記事の内容はColab、APIともに無料枠で実施可能です。
ライブラリインストール
実施時点では、Google Colabで google-genai の最新バージョンを入れると依存ライブラリの不整合が発生したためバージョンを1.1.0に下げる。
!pip install google-genai==1.1.0
実行
作成したデータセットをzip化してColabにアップロードし、unzipコマンドでzipファイルを展開。
!unzip traffic_light.zip
展開されたフォルダは以下のような構成。
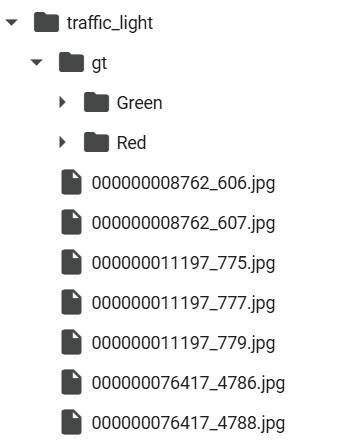
- Colabの "/content" に "traffic_light" フォルダ
- "traffic_light" 内に分類対象画像と分類後に精度確認を行うための "gt" フォルダ
- "gt" 内の "Green" と "Red" には "traffic_light" 直下の画像と同じものを分類して格納
APIがエラーを返すことを想定し、try~exceptを使って分類できたところまではJSONファイルに保存できるように実装。
from glob import glob
from io import BytesIO
import json
import os
import time
from tqdm import tqdm
from google import genai
from google.colab import userdata
from google.genai import types
from PIL import Image
# 定数
IMAGES_DIR = "/content/traffic_light"
def invoke_gemini2flash(client, image):
# プロンプトの準備
prompt = "Classify traffic light color of the red, yellow, green and unsure."
system_instruction = "Return only class name such as 'yellow'. Please include blue in green. Please return 'unsure' when you cannot classify traffic light color or you find multiple colors are flashing."
# 推論の実行
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents=[prompt, image],
config=types.GenerateContentConfig(system_instruction=system_instruction, temperature=0.5)
)
return response.text
def main():
results = {}
os.environ['GOOGLE_API_KEY'] = userdata.get("GOOGLE_API_KEY") # APIキーの準備
client = genai.Client()
try:
for img_path in tqdm(glob(os.path.join(IMAGES_DIR, "*.jpg"))):
img = Image.open(BytesIO(open(img_path, "rb").read()))
im = Image.open(img_path).resize((1024, int(1024 * img.size[1] / img.size[0])), Image.Resampling.LANCZOS)
result = invoke_gemini2flash(client, im)
results[os.path.basename(img_path)] = result
time.sleep(3) # APIリクエスト頻度調整
except Exception as e:
print(e)
# 結果の保存
with open("results1.json", "w") as f:
json.dump(results, f)
main()
実行してしばらくすると429 RESOURCE_EXHAUSTED. で中断された。
APIの高負荷を回避するための一時的な利用制限と思われる。
そのためしばらく時間をおく。
どこまで分類が終わっているかを下記で確認。
with open("results1.json", "r") as f:
results = json.load(f)
print(f"Results lenght: {len(results)}")
print(json.dumps(results, indent=4))
以下が表示され、今回は57枚の分類が終わったとわかる。
Results lenght: 57
{
"000000320232_20393.jpg": "yellow",
~略~
"000000418696_26783.jpg": "green"
}
main関数に以下の変更を加えながら全対象の画像の分類が終わるまで繰り返し実施。
- for文の
glob(os.path.join(IMAGES_DIR, "*.jpg"))をglob(os.path.join(IMAGES_DIR, "*.jpg"))[57:]の様にスライス指定に変更 - 保存ファイル名を
results2.json等適当な名前に変更
今回はresultsX.jsonが4ファイルになったため、それらを以下のコードで統合。
(resultsX.jsonに記録された量は57件、21件、21件、1件となった)
total_results = {}
for i in range(1, 5): # 4ファイル分のループ
with open(f"results{i}.json", "r") as f:
results = json.load(f)
total_results.update(results)
print(f"Total results lenght: {len(total_results)}")
print(json.dumps(total_results, indent=4))
# 統合した結果の保存
with open("results.json", "w") as f:
json.dump(total_results, f)
結果
results.jsonの内容確認
import pandas as pd
df = pd.DataFrame(total_results.items(), columns=['file_name', 'class_name'])
df

# 各class_nameの件数を表示
df['class_name'].value_counts()

「red」、「yellow」、「green」、「unsure」で青色は「green」に含めるようプロンプトで指示したはずが、「blue」や「red\nyellow\nblue」と回答したケースも含まれている。
GT情報準備
画像の格納フォルダ名からGTの分類情報を取得。
def get_gt():
gt = {}
for img_path in tqdm(glob(os.path.join(IMAGES_DIR, "gt", "*", "*.jpg"))):
gt[os.path.basename(img_path)] = os.path.basename(os.path.dirname(img_path))
# GTを保存
with open("gt.json", "w") as f:
json.dump(gt, f)
get_gt()
with open("gt.json", "r") as f:
gt = json.load(f)
print(f"GT lenght: {len(gt)}")
print(json.dumps(gt, indent=4))
GT lenght: 100
{
"000000320232_20393.jpg": "Red",
~略~
"000000144706_8979.jpg": "Green"
}
精度の確認
フォルダの頭文字を大文字にしていたため、小文字の揃えてGeminiの分類結果と比較。
# GTの大文字は小文字に揃える
gt = {k: v.lower() for k, v in gt.items()}
# 比較列追加
df['gt'] = df['file_name'].map(gt)
df['correct'] = df['class_name'] == df['gt']
df
df['correct'].value_counts()
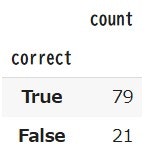
- 正答 79%
- 誤答 21%
blue の結果確認
df[df['class_name'] == 'blue'].value_counts()

GTはgreen。
画像は以下。

確かに青みが強くは感じるもののプロンプト無視なので誤答。
yellow の結果確認
df[df['class_name'] == 'yellow'].value_counts()

GTは全てred。
画像は以下。







1件目の画像は目視で分類した際も困った覚えあり。
赤の周りに光っているような画素が僅かにあったため赤とした。
その他の画像もやや黄色味は強く見える気がする。
所感
- 正答率が約8割で、目視での画像分類時点で想像したよりは高精度
- シンプルなプロンプトでも無視されてしまうことが僅かにある
- 正答8割であれば、アノテーションルール変更時の効果確認目的で利用できそう
- 効果確認の目的であれば十分な精度
- アノテーションの修正を完全に任せるには精度90%は超えてほしい
- ChatGPTなどとのアンサンブルやプロンプトチューニングが必要かもしれない
- 車の色や人の服の色の分類なら同様にできそう
- 今回は色味での分類だが、形状の違いでの分類能力も気になる