Elmは、とりあえずコンパイラに言われるがまま型パズルをするだけでアプリケーションをすぐに書き上げることができるとても素晴らしい言語であることは、すでに皆さんご存知でしょう。
しかし、現バージョンのElm(v0.19.1)では、深くネストしたデータ構造を更新する方法がそこそこめんどくさいです。
特に、深くなっているデータがレコードだった場合、更新が非常に煩雑になってしまいます。こちらについては、すでに@ababup1192さんによってElmでネストしたRecordを更新するという記事が書かれております。
ですが、他言語では当たり前のようにやっていた、階層が深いデータ構造に対する更新する手段は本当にElmに存在しないのでしょうか?そこで、Elmにとっての更新とは何かを考察し、より良い手段がないかを模索した記録としてこの記事を残したいと思います。
ネストしたデータを更新する処理の具体例
例として適当なモデルを用意します。
-- [先ほどの記事](https://qiita.com/ababup1192/items/34e926ffc934336242ca)のモデルの例をお借りし、
-- characterを複数のキャラクタを持つようなモデルに変更しました。
type alias Model =
{ characters : Array Character
}
type alias Character =
{ name : String
, point : Point
}
type alias Point =
{ x : Int
, y : Int
}
例として、3番目のユーザのy座標を0に設定するという処理を考えます。jsでお気持ちを書くと
characters[3].point.y = 0
といったノリです。
setYOfThirdCharacterToZero : Model -> Model
setYOfThirdCharacterToZero =
case model.characters |> Array.get 3 of
Nothing ->
model
Just character ->
let
point =
character.point
newPoint =
{ point | y = 0 }
newCharacter =
{ character | point = newPoint }
newCharacters =
model.characters
|> Array.set 3 newCharacter
in
{ model | characters = newCharacters }
characters[3].point.y = 0といった機能を表す、特化した関数setYOfThirdCharacterToZero は実装することができました。
しかし、yを0にする以外なにもしていないと言っていいほどの実装のはずが、他言語と比べると幾分か冗長なようにみえます。
それこそ、お気持ちとして提示したjsではsetYOfThirdCharacterToZero = characters => characters[3].point.y = 0というように、たった一行で書くことができるくらい、本当はシンプルな処理のはずです1。
複雑なデータを単純にするアプローチ
複雑なものは複雑なまま扱うのではなく、単純な構造にしてから処理をする方が書く側も読む側も混乱せずにすみます。後述する手法より、まずはこちらのアプローチを試してください。
公式の見解
Elmのような言語ではよくある手法としてLensと呼ばれる便利データ型や関数群を用いて複雑なデータを扱うことがよくある(?)のですが、elm-packagesでlensと検索をかけるとこのようなヒントが表示されます。
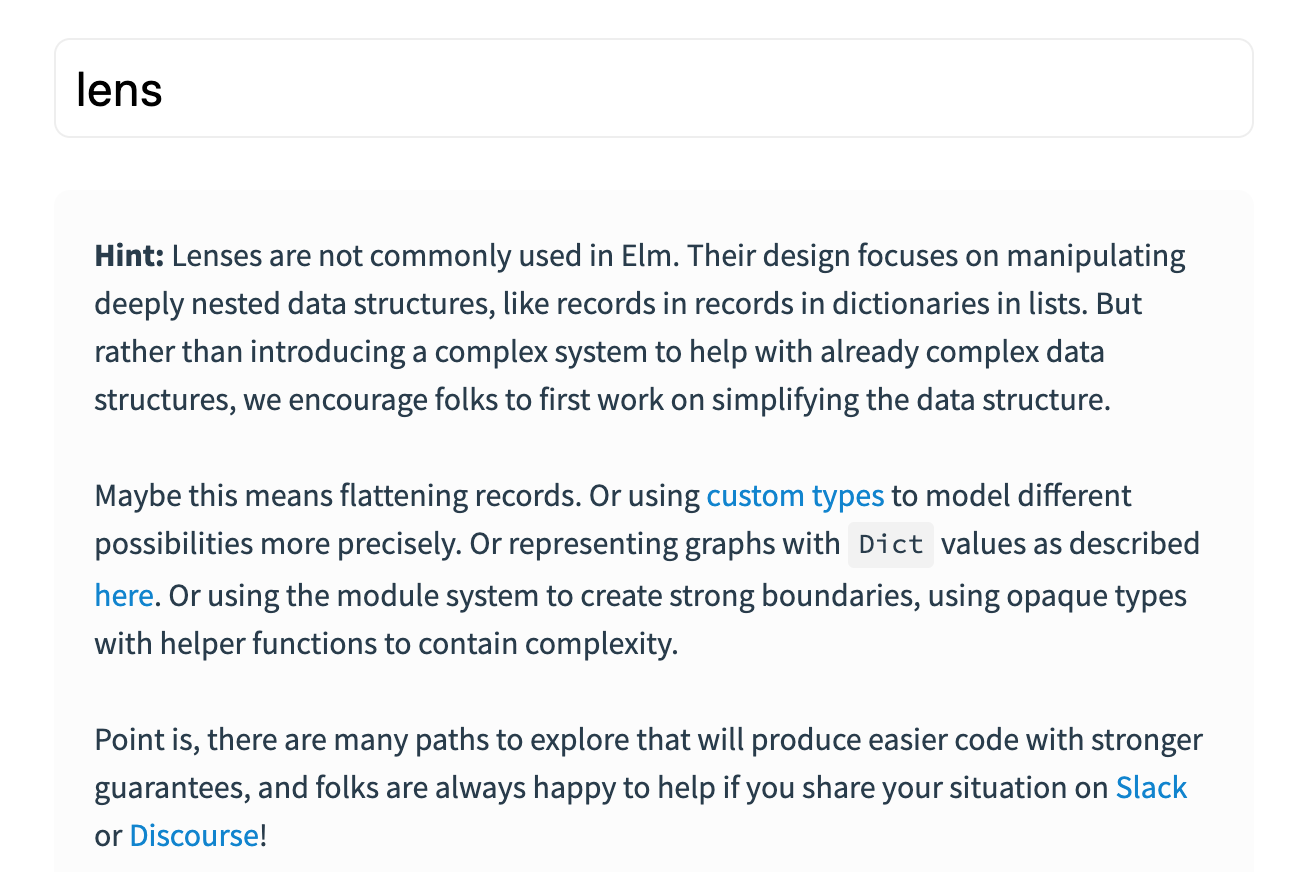
筆者は英語がよわよわなので、google翻訳したのちにお気持ちを汲み取ると
- 複雑なデータのための複雑なヘルパを用意するんじゃなくて、複雑なデータを単純にした方がよいよ
- レコードがネストした場合はそれを同じ階層に入れることができないか検討して
- custom typesを使えば条件に基づくデータが正確に表現できるよ
- グラフはDictとしてこのように表現できるよ
- モジュールシステムを使うことで、opaque typesによる、型による表現で複雑さを抑えることができるよ
ということが書いてあるみたいです。
結局、難しく考えずに簡単にやりましょうってことでしょうか。技術大好きなエンジニアなのでどうしても複雑な物をコントロールしたくなりますが、よくよくデータを見ると、過度にデータ構造を作りすぎて不必要に複雑になっている可能性があるかを観察する必要がありそうです。
難しかった構造を単純にする
今回の例では、Characterの中のフィールドにpoint : Pointがいますが、もしPointにxとyの更新に関して特別な制約がなく、単純にデータを保持するだけのような場合、この実装は必要以上に複雑になっている可能性があります。上のヒントによると、
type alias Character =
{ name : String
, x : Int
, y : Int
}
このように実装することが可能そうです。すると、結果的に一段ネストが浅くなるため、いちいち中間データをletで束縛する必要がなくなります。
custom typeを使おうというお話はもちろんElm日本コミュニティによる公式ドキュメントの翻訳がすでに存在し、丁寧な記載があります。
(本題)そもそも、階層が深いような複雑なデータを扱いたい場合
上記の内容は、不必要に複雑だったデータ型をシンプルにする手法でした。では、複雑なデータを複雑なまま扱う方法はどうすればいいのでしょうか?
ここでlensのアプローチの一部分をそのまま流用することで楽に更新することが可能です。難しいので、順を追って説明します。
以下の説明では、setterとmodifierという単語を使いますが、なんと呼べばいいのかわからないので勝手にそういう名前を付けました。
setterとは
Elmでは、変数が状態を持つことはありません。代わりに、ある値を元に値を別の値に変換するような関数を作ることで他言語でいうsetterのような挙動を表現することができます。
setX : Int -> Point -> Point
setX i point =
{ point | x = i }
setY : Int -> Point -> Point
setY i point =
{ point | y = i }
この関数を使うことで、jsでいうpoint.x = 10みたいなものが表現できます。
実際に型パズルをしてその過程をみてみます。
-- サンプルデータの定義がこんな感じで定義されてるとして、
point : Point
point = { x = 30, y = 20 }
-- セッターと呼ばれる関数の型
setX : Int -> Point -> Point
-- 10にsetXを適用し、Pointの更新関数が手に入る!
setX 10 : Point -> Point
-- 実際に`setX 10`でできた関数をPointに適用してみる
setX 10 point -- result: { x = 0, y = 20 }
-- パイプ形式にして
point |> setX 10 -- result: { x = 0, y = 20 }
さきほどは、setほにゃららという関数を作りましたが、早速ネストしたデータ型に対してどのように使えるかを考えてみます。
キャラクターのy座標を3増やすといったシチュエーションの場合、
setPoint : Point -> Character -> Character
setPoint point character =
{ character | point = point }
character : Character
character =
{ name = "カレーうどん"
, point =
{ x = 10
, y = 20
}
}
-- ちょっと煩雑?
newCharacter =
let
newPoint = character.point
|> setY (character.point.y + 3)
in
character
|> setPoint newPoint
十分シンプルなように思いますが、それは階層が浅いからです(だから最初に構造を単純にすることを奨めているのかな?)。これをもっとシンプルにするために、setterをもっと抽象化します。
modifierを作る
setterは中に入れたい値を引数にとって、親データの更新関数を返していました。modifierと呼ばれるものは中に入れたい値の代わりに、中身をどう更新するかを渡します。
では、yを更新する関数を引数にとってPointのyを更新するmodifierとして、updateYを定義します。
updateY : (Int -> Int) -> Point -> Point
updateY updateFunction point =
{ y = updateFunction point.y }
ある座標point: Pointのyを3インクリメントするコードは
point |> updateY ((+) 3)
と書くことができます。
modifierはsetterとして使える
setterを抽象化したmodifierですが、抽象化したというくらいなのでmodifierはsetterとして使えるべきです。
では、setterが値をセットするというのはどういうことかを考えてみます。すると、引数をガン無視して常に同じ値を返す更新関数を使ことによって、常に特定の値に更新をするような関数をつくることができます。
-- このようなデータに対して...
point = { x = 100, y = 200 }
-- 常に0を返す更新関数を渡すと
point |> updateX (\_ -> 0) -- result: { x = 0, y = 200 }
-- どんな値が入ってても0に更新してくれる!
-- ある値を元に、それしか返さない関数を作る関数は
-- always : a -> b -> a という標準関数がすでにある
point |> updateX (always 0) -- result: { x = 0, y = 200 }
-- 上二つの結果は、これと一緒
point |> setX 0
同様に、Characterの保持しているPointを更新する関数もupdatePoint : (Point -> Point) -> Character -> Characterといった型で実装をすることができます。
modifierは更新関数変換器
updateX : (Int -> Int) -> Point -> Pointという型をよくよくみていると、xの更新関数(Int->Int)をPointの更新関数(Point->Point)に変換しているように見えてくるかと思います。これは、あるデータ型の一部分に注目した更新関数を元のデータの更新関数に変換してくれるようなものになります。
これがとっても大事な概念なので次に進む前によくよく咀嚼しておいてください!
modifierは合成することができる
ここが本記事の真骨頂です。Elmには標準関数に(>>)という関数があります。これは (a -> b) -> (b -> c) -> (a -> c)という型を持っており、二つの関数の出口(b型)と入り口(b型)をつなげてくれる演算子として使うことができます。(>>)は、関数と関数をつなげて関数を作る関数です。
先ほど、modifierは更新関数を引数にとって別の更新関数を返すものとして説明しましたが、更新関数変換器ことmodifierは、更新関数を引数にとって更新関数を返すような関数です。
そうなんです、modifierとmodifierをつなげるとそれもまたmodifierになってしまいます!!!!
-- 関数と関数を合成して関数になった
setX 0 >> setY 0 : Point -> Point
-- modifierとmodifierを合成してmodifierになった!
updateY >> updatePoint : (Int -> Int) -> Character -> Character
Array.Extra.updateはmodifierだった!
Array.Extra.update関数は、何番目を更新するかの引数を与えた場合、先ほどと同様のmodifierと同じ形型になります。
jsでお気持ちで書いていたcharacters[3].point.y = 0という処理は、この知識をもってすれば一行で書けてしまいます。
model
|> (updateCharacters << Array.Extra.update 3 << updatePoint << updateY) (always 0)
まとめ
- 難しくせず、簡単なデータ構造でいい場合は簡単なデータ構造を選ぶ
- どうしても複雑な構造をいじる必要があったらmodifierを定義して見通しをよくすることができるよ
今日にまにあえぇ!!!
-
世の中そんな甘くありません。3番目の要素がなかったら例外が投げられますし、代入をしてるので引数のオブジェクトに対して変更が加わるので、この関数を呼ぶタイミングに気を使う必要が出てきてしまいます。そしてelmのように例外を投げず引数に作用しないよう丁寧に書くとしたら、結局elmと同じくらい大変な処理を書くことになります。 ↩