はじめに
色々な統計手法をRで試すために、標準データセットを使い試してみる場合もありますが、都合の良い架空データを自作し試したくなる場合もあります。今回、架空データを作るのに色々なサイトを見て試した結果を残します。
なお、標準データセットについては@wakuteka様のR言語 標準データセットの私的まとめのページがわかりやすく情報がまとまっており、活用する上で大変参考になるかと思います。
単変量データの生成
rxxxx(xxxxは確率分布指定)という関数で指定の確率分布の乱数を発生させることができるので、これを使います。確率分布を指定するので、毎回同じデータを作りたい場合はset.seed()で乱数の種を固定する必要があります。
# 確率分布関数からの乱数を使ってデータを生成
norm_data <- rnorm(n=100, mean=1, sd=1) #正規分布
unif_data <- runif(n=100, min=0, max=10) #一様分布
pois_data <- rpois(n=100, lambda=5) #ポアソン分布
人工データの発生のP13にcut関数を使う例がありましたので、私なりにカテゴリーの仮想データを作ってみました。
# 20人分のテスト結果の仮想データ。
# 乱数から得点を生成し、カテゴリ(不可,可,良,優)に変換してみる。
> test_point <- trunc(rnorm(n=20, mean=70, sd=13))
> test_point
[1] 61 66 81 84 62 70 56 60 62 52 43 79 75 59 82 93 36 84 85 71
> test_categoly <- cut(test_point, breaks=c(0,60,70,80,100), labels = c("不可","可","良","優"))
> test_categoly
[1] 可 可 優 優 可 可 不可 不可 可 不可 不可 良 良 不可 優 優
[17] 不可 優 優 良
Levels: 不可 可 良 優
他の確率分布からもデータ作成が出来ます。確率分布と乱数が、表もまとまっており便利と思います。
多変量データの生成
上記を入力にして、単純に式や関係をコーディングして作ります。
任意の母相関係数を持つデータ
Rで架空データの作成のP12-13を参考に試してみました。
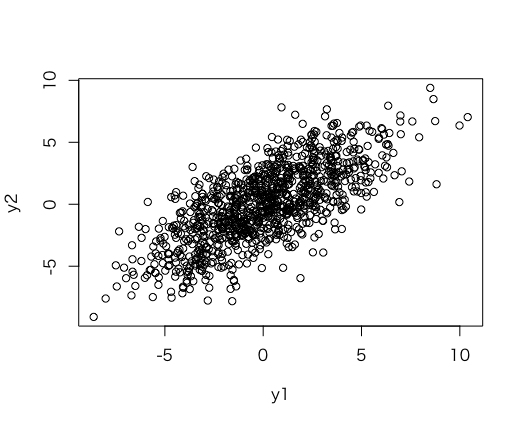
# 母相関係数0.7のデータを作ってみる
> rho <- 0.7
> x <- rnorm(n=1000,mean=0,sd=3)
> e1 <- rnorm(n=1000,mean=0,sd=3)
> e2 <- rnorm(n=1000,mean=0,sd=3)
> y1 <- sqrt(rho)*x+sqrt(1-rho)*e1
> y2 <- sqrt(rho)*x+sqrt(1-rho)*e2
> cor(y1,y2)
[1] 0.7137821
> plot(y1, y2)
ただ、MASSパッケージにmvrnormのという関数があり、上記と同様のことが出来ました。
# 母相関係数0.7のデータをmvrnormを使って作ってみる
> mu <- c(0,0)
> sigma <- matrix(c(1,0.7,0.7,1), nrow=2, ncol=2)
> y1_y2 <- mvrnorm(n=1000, mu=mu, Sigma=sigma)
> cor(y1_y2)
[,1] [,2]
[1,] 1.0000000 0.7140944
[2,] 0.7140944 1.0000000
> plot(y1_y2)

3変数以上も同様に作成していけると思います。
回帰モデルに基づいたデータの作成
人工データの発生のP32を参考にしましたが、入力(x)を乱数で作成し、単純にモデルを食わせたデータ(y)を作るだけです。
> n <- 1000
> a <- 10 #切片
> b <- 10 #回帰係数
> x <- rnorm(n=n) #変数x(回帰モデルへの入力データ)
> e <- rnorm(n=n) #回帰モデルの残差(正規分布と仮定しているので)
> y <- b*x + a + e #線形回帰モデルに基づいたデータを作成
> plot(x,y)
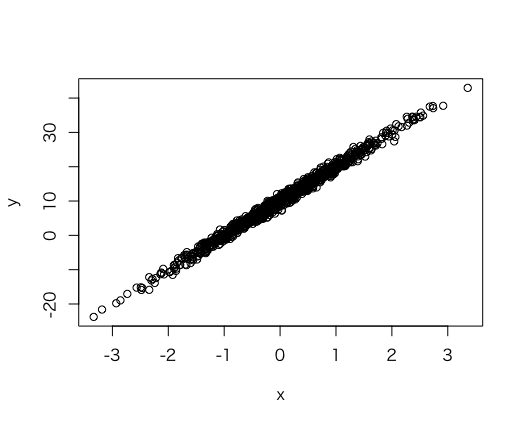
綺麗になりすぎたので、標準偏差を大きくします。
> e <- rnorm(n=n, sd=10) #残差の標準偏差を大きくします。
> y <- b*x + a + e
> plot(x,y)
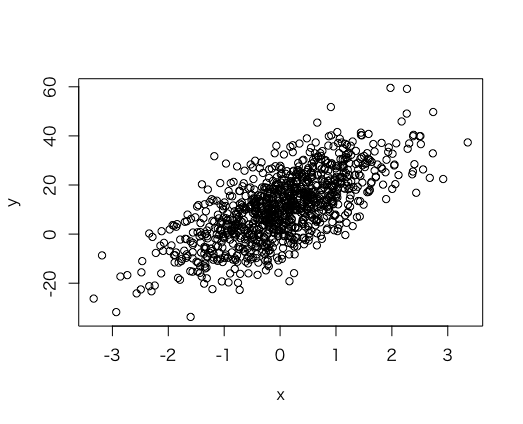
他のモデルから生成する際も、同様にすれば簡単に作れそうです。
時系列データの生成
必要な点数分の入力データを作りts関数を通せば良いようです。Rで季節変動のある時系列データを扱ってみるでは、ホワイトノイズの要素、周期的に発生するスパイクの要素、ステップ状の変化などそれぞれ作成して足して作成されています。時系列データではトレンド要素も考慮される場合がありますが、同様に足せば良いように思いましたので、seqを活用し加えて見ました。
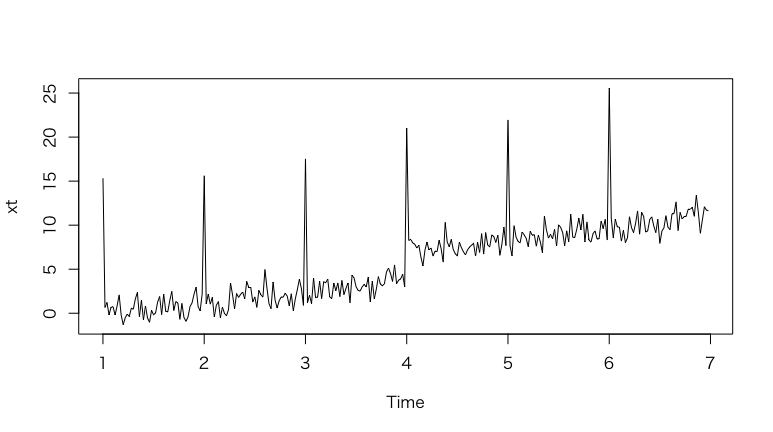
# tjo様が作成されたデータにさらにトレンド要素を足した時系列データを作ってみる
> x1<-rnorm(300) #ホワイトノイズの要素
> x2<-rep(c(15,rep(0,49)),6) #周期的に発生するスパイクの要素
> x3<-c(rep(0,150),rep(3,150)) #特定のタイミングで発生するステップ状の変化
> x4<-seq(0,8,length=300) #トレンドの要素。
> x<-x1+x2+x3+x4 #全て足し合わせる
> xt<-ts(as.numeric(x),frequency=50) #xをnumeric型、周期50で時系列データを作成
> plot(xt)
最後に
乱数発生で単変量データを作る、多変量データは「相関係数の式や各モデル式を通して作成する」という単純な発想で、とても簡単に作成できることが改めて理解できました。