はじめに
こんにちは、カスヤです。
Lookerを触り始めることになったので、LookMLについて、そしてその反映結果について、公式の説明を基にしつつ、自身の解釈も加えて残しておこうと思います。前半ではLookMLオブジェクトの構成要素に焦点を当て、後半ではこれらの要素がビジュアライゼーションにどのように反映されるかについて詳しく解説していきます。
LookMLとは
データモデリング言語。Googleのデータプラットフォーム製品、Lookerで使用される専用言語のこと。LookMLを書く目的は、データモデルの定義(データベースの情報をLookerに渡すための定義)をするためである。
データモデルの定義レイヤーを持たせる理由
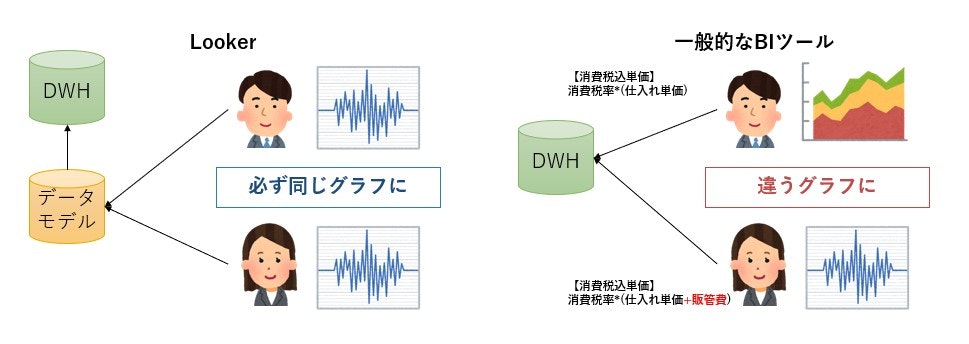
LookerはよくBIツールと比較されるけれど、ほかのBIツールと違いデータモデルを定義するレイヤーを持っている。
これの何が良いかというと、一般的にBIツールのデータソースとしてデータベースを選択した際、同じDBを参照しているはずの2つのレポートが謎の差を出して表示される場合がある。
これを調査していくと参照設定が少し違い、それが差分を生んでいることがある。
このように、レポート運用で問題になりがちなレポートデータの揺れはデータモデリング層を設けることで防ぐことができるよね、という理由。(これをデータのガバナンスが効くと言う。)
 [筆者図説]
[筆者図説]
データモデリングを行うLookMLオブジェクトの構造
データモデリングを行うために計6つのオブジェクトで構成されていて、
関係性を図で表すとこのようになる。
これらの要素はすべてコードで構成されていて、
Lookerサービス内で提供されるGitリポジトリに管理することができる。
 [筆者図説]
[筆者図説]
Big Queryにサンプルデータ(ecommerce)を用意し、それをLookMLで定義していきながら構成要素を説明していく。
Project
データモデリングを格納する場所。一番大きい要素。プロジェクト1個に対して以降の要素はN個 作成できる。例えば「2024_ecommerce」など任意の名前を付けられる。
Model
関連性を格納する場所。厳密にはズレるかもしれないが参照単位としては「Modelファイル1個≒DBのスキーマ1本」のようなイメージ。
- データベースの接続情報
- Exploreを複数定義した集合体
上記を含んだオブジェクトがModel。
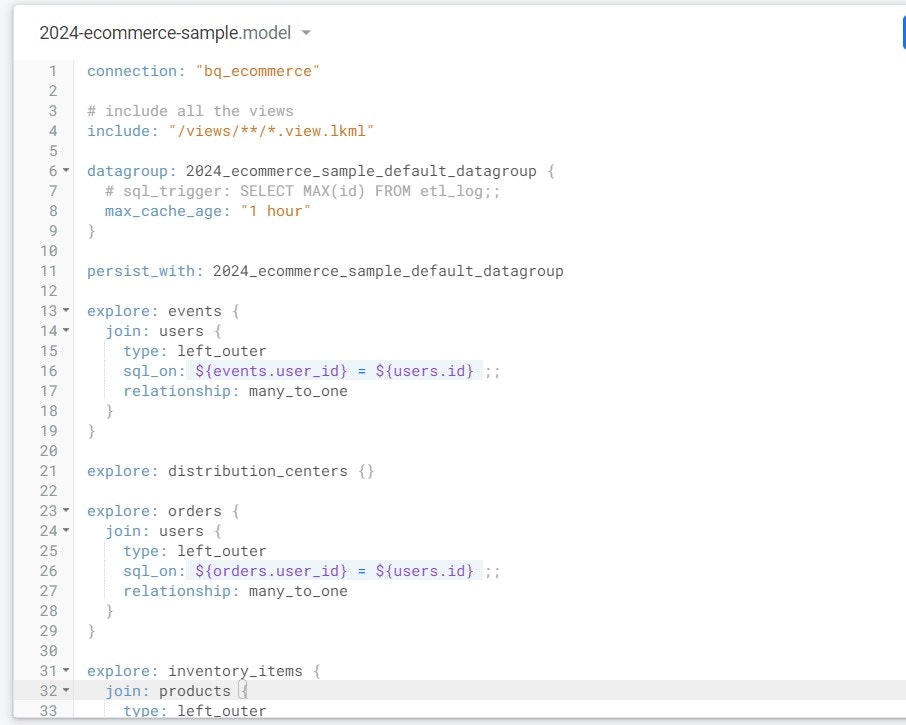
例えばBig Queryに用意したデータセットを参照するとModelファイルはこのような見た目になる。
Explore
上の図で見えているように、modelファイルに属する。1つあるいは複数のViewをjoinしたものがExploreになる。Viewのjoin種類は以下。
- left_outer(デフォルト)
- full_outer
- inner
- cross
ここで定義したものが後編のビジュアライゼーションでフィールドとして選択出来るようになる。
View
単位にすると「Viewファイル1個≒テーブル1本」このイメージが近い。
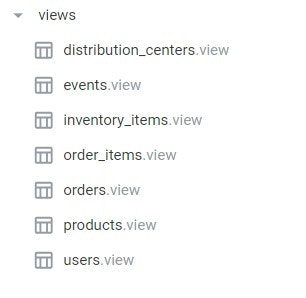
Big Queryに7本のテーブルが存在する状態で参照すると7本作成された。
Dimensionの集合体がViewになる。
Dimensions
単位にすると「Dimension1個≒テーブルのカラム1個」このイメージが近い。
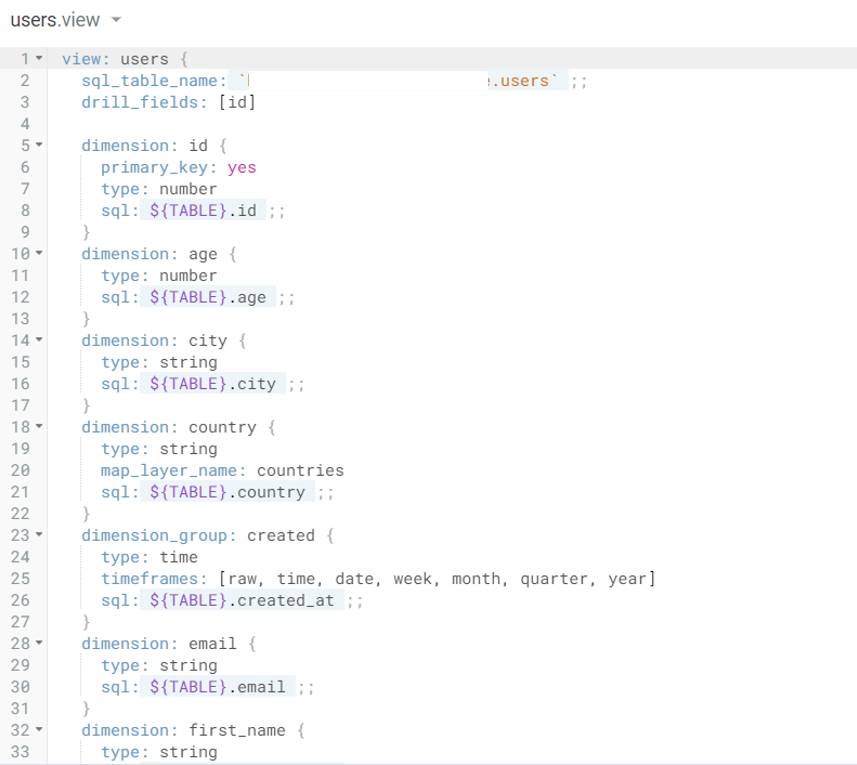
DBのどのカラムを取得するかを定義する。カラムは勿論そのまま参照することも出来るし、
計算したり関数でカラム同士を結合したり追加の定義をした上で参照することもできる。
Measures
関数定義を保持する。Dimensionと同じレベルに定義する。
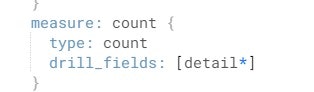
sumやaverage、countをしてLookerオブジェクトをレポートやダッシュボードに表示できるように定義する。さらに細かい条件でデータをフィルターしながら、カウントすることなどもできる。
以上、
とりあえず前編でした。