宣伝
2021年最後のMLOps勉強会は12月8日(水)を予定しています。
内容はベクトル近傍探索技術とA/Bテストの2本立てです。
ぜひご参加ください!
やりたいこと
DataRobot × Vertex Feature Storeでオンライン推論してみて、実際にオンライン推論に耐えれるパフォーマンスで処理してくれるのか確認しておきたい
モチベーション
最近、日本のお客様でもバッチ的な学習及び推論だけでなく、オンライン推論にチャレンジしたいというニーズも増えてきているように思います。しかし、オンライン推論を実現するためには、学習時と推論時で異なる性能要件を満たすストレージやデータベースが必要になります。
具体的には、学習時には基本大量のデータが必要なためデータウェアハウスやデータレイクといったデータベースやストレージからデータを取得または特徴量エンジニアリングして結果を保管するといった形で活用します。一方、オンライン推論では少量の特徴量を素早く取り出す必要が出てきますが、読み込みに時間のかかるデータウェアハウスやデータレイクではこの要件を満たすことができないため、KVS(Key-Value Store)など少量データを素早く取り出すことができるデータベースやストレージが必要となります。
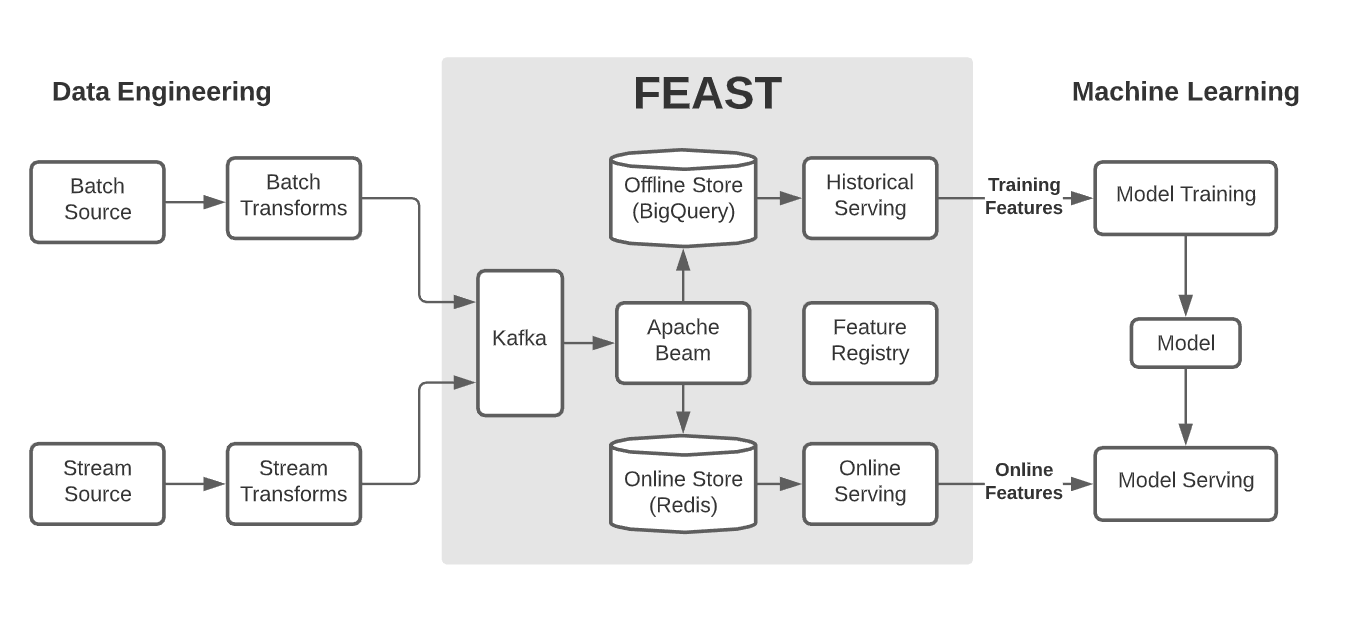
出典:A State of Feast
上記の画像で言うと、Offline Storeがデータウェアハウスやデータレイクで、Online StoreがKVSを指します。このようにバッチ処理用とオンライン処理用にストアを分けた場合、どちらのストアにも同じデータをロードしたり、双方のストアでデータのやりとりをしたりと複雑なパイプラインを構築する必要が出てくるため、非ITテック企業がいきなり挑戦するには、運用含めハードルが高かったりします。
そういった課題を解決するために生まれたのがFeature Storeであり、Google CloudではVertex Feature Storeとして爆誕しています。素晴らしいですね。

出典:Vertex Feature Store で特徴量管理の MLOps はこう変わる
Vertex Feature Storeが生まれた歴史やどんなに素晴らしい機能を持ち合わせているかについてはや公式ドキュメントや先人たちの素晴らしい記事をご確認いただくとして、私はピュアに実際にオンライン推論で耐えれるパフォーマンスを出してくれるのかを確認したいと思います。(そしてパフォーマンス出るならオンライン推論をお待ちのお客様へ提案のオプションとして使いたい。まぁ、Feastと同じアーキテクチャならRedisだからそのままならそりゃ早いだろうという話かもですが、体感しておきたいのです)
【書き起こし】Vertex PipelinesとFeature Storeを活用した不正防止システム – Liu Songjie【Merpay Tech Fest 2021】
Vertex AIを活用したMLOpsの実現【後編】
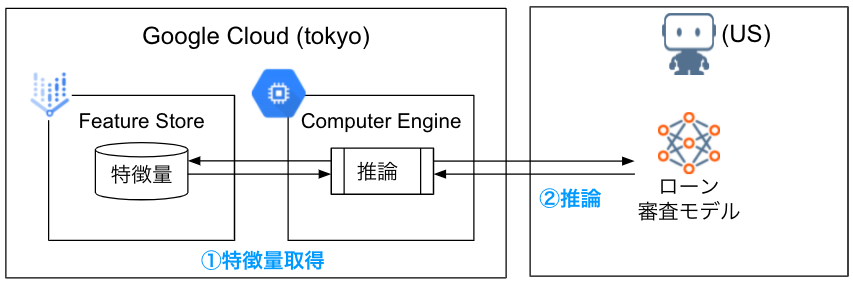
検証イメージ
検証は東京リージョンにあるGoogle CloudのFeature Store、Computer Engineと、USリージョンにあるDataRobotを活用して実施します。まずは、事前にDataRobotにローン審査で貸し倒れを予測するモデルを作成し、Feature Storeには推論用の特徴量をロードします。そして、Computer Engine上で①特徴量取得と②推論を100回繰り返して、①のみ、①+②それぞれで1回あたりどれぐらいの処理時間になるのか確認します。
事前準備
それでは事前準備を始めます。
- DataRobotにローン審査で貸し倒れを予測するモデルを作成
- Feature Storeに推論用の特徴量をロード
- 実験用のpythonライブラリインストール
DataRobotにローン審査で貸し倒れを予測するモデルを作成
DataRobotでモデルを作ってデプロイし、予測可能な状態にします。
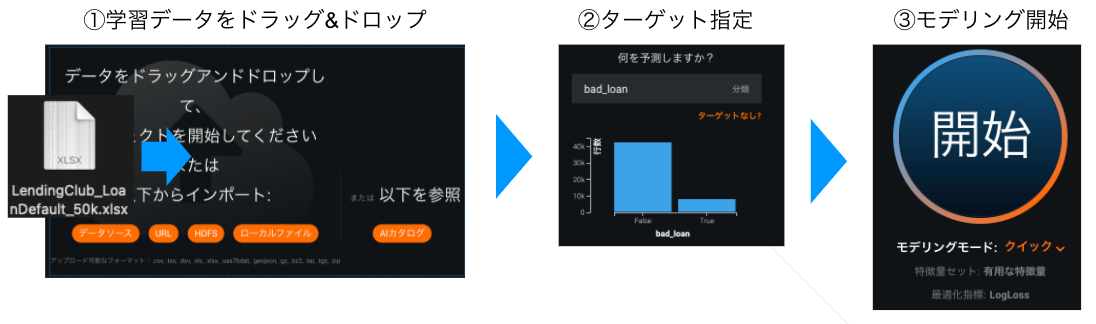
モデル作成
まずは学習データをドラッグ&ドロップでアップロードして、ターゲット指定し、「開始」ボタンをクリックするだけ、簡単ですね。
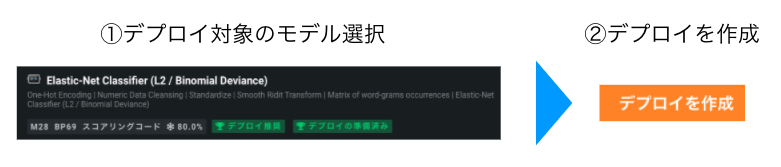
デプロイ
続いてデプロイ。モデル作成を開始すると、AutoMLで沢山モデルが作成されるので、一番精度の良いモデルを選択し、「デプロイを作成」でデプロイします。
これだけで、APIで予測する環境が自動で構築され、モニタリング(正常性、データドリフト、精度)、モデル更新、並行稼働など運用に必要な機能が即時に利用できるようになります。何も考えず、ポチポチ進めます。
Feature Storeに推論用の特徴量をロード
次にFeature Storeに推論用の特徴量をロードします。直感的には、Feature Storeという箱を作成して、Entity(表)、Feature(列)を定義して、Entityにデータをインポートするイメージです。それぞれの正式な定義はこちらを確認ください。
Feature store作成
公式ドキュメントに従って、Feature Storeを作成します。ノード数は100件予測するだけなので、ケチって1に。

Entity、Featureを定義
公式ドキュメントに従って、Entity、Featureを定義します。特段難しい操作はないですが、Featureを一つひとつ丁寧に定義しないといけないのは少し手間でした。(GCSからBigQueryにデータ取り込むみたいに自動でスキーマ定義できるのかと思ってました)

推論用の特徴量をロード
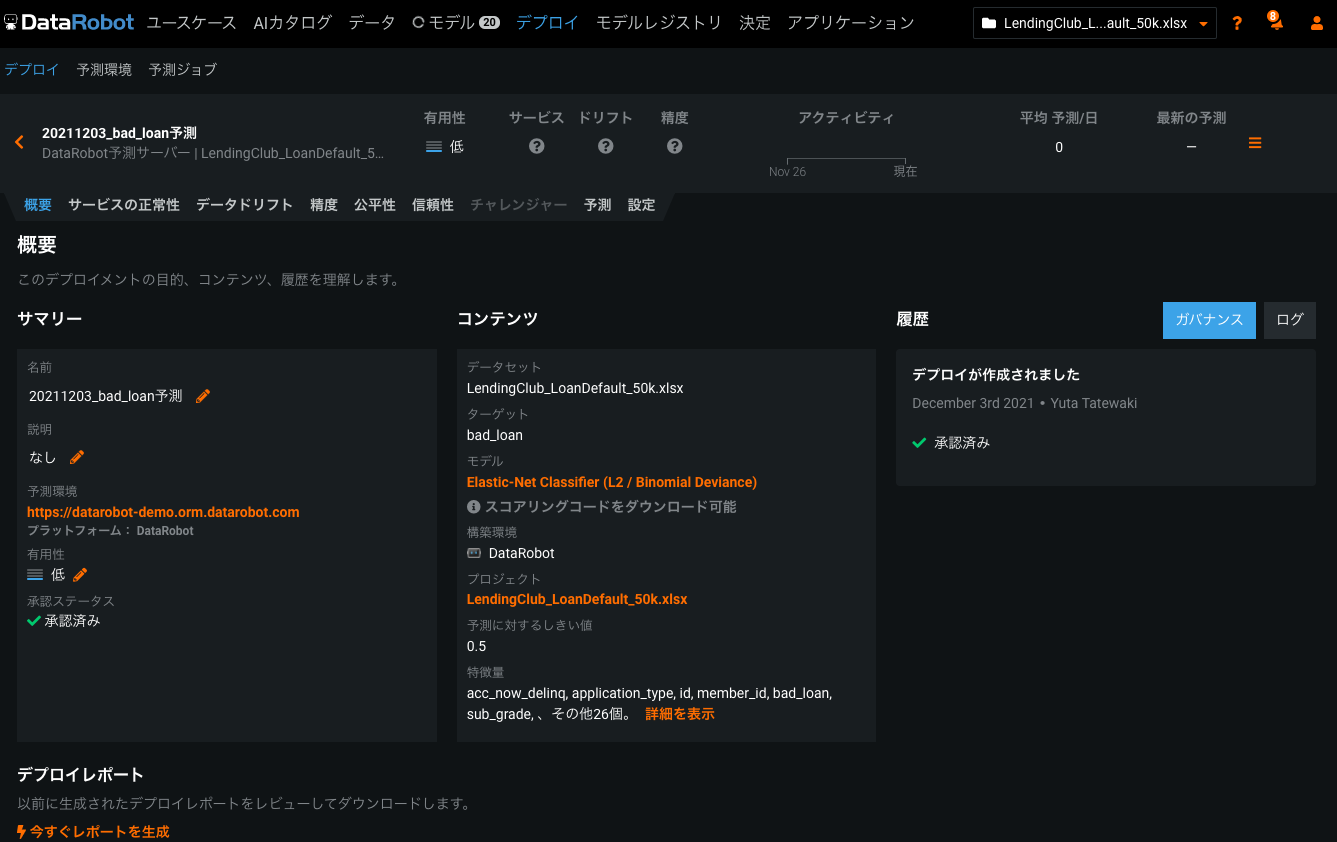
GCSにアップしているCSVファイルをロードする対象として指定します。
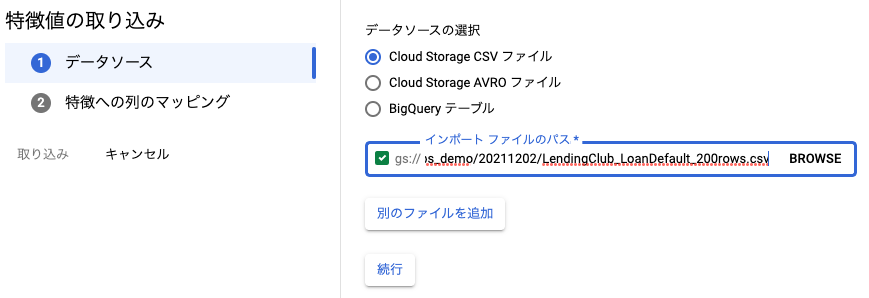
ロードするCSVとFeatureとのマッピング、一意の列、タイムスタンプを指定してロードします。
実験用のpythonライブラリインストール
最後に、Computer Engineに実験用のpythonライブラリをインストールします。
!pip install pandas
!pip install google-cloud
!pip install google-cloud-aiplatform
!pip install pydata-google-auth
実験
実験コード
import pydata_google_auth
from google.cloud import aiplatform
from pandas.io.json import json_normalize
import json
import requests
import time
credentials = pydata_google_auth.get_user_credentials(
['https://www.googleapis.com/auth/cloud-platform'],
)
# カラム名定義
COLUMN_NAME = ["id","member_id","loan_amount","purpose_type","purpose_detail","title","emp_length","home_ownership","annual_inc","zip_code","addr_state","dti","grade","sub_grade","delinq_2yrs","earliest_cr_line","inq_last_6mths","mths_since_last_delinq","mths_since_last_record","open_acc","pub_rec","revol_bal","revol_util","total_acc","initial_list_status","collections_12_mths_ex_med","mths_since_last_major_derog","application_type","acc_now_delinq","tot_coll_amt","tot_cur_bal"]
# カラム行作成
column_row = ""
for i in COLUMN_NAME:
column_row += i + ","
COLUMN_ROW = column_row[:-1]
# 開始番号
START_NUM = 1
# 終了番号
END_NUM = 101
# DataRobotアクセス、認証情報
API_TOKEN = 'NjE…'
LOCATION = 'htt…'
DEPLOYMENT_ID = '61a…'
DATAROBOT_KEY = '2ad…'
# GCPアクセス、認証情報
LOCATION_GCP = "asia-northeast1"
API_ENDPOINT = "asia-northeast1-aiplatform.googleapis.com"
PROJECT = "ai-…"
# 特徴量取得
def read_feature_values_sample(
project: str,
featurestore_id: str,
entity_type_id: str,
entity_id: str,
location: str = LOCATION_GCP,
api_endpoint: str = API_ENDPOINT,
):
client_options = {"api_endpoint": api_endpoint}
client = aiplatform.gapic.FeaturestoreOnlineServingServiceClient(
credentials=credentials,
client_options=client_options
)
entity_type = f"projects/{project}/locations/{location}/featurestores/{featurestore_id}/entityTypes/{entity_type_id}"
feature_selector = aiplatform.gapic.FeatureSelector(
#id_matcher=aiplatform.gapic.IdMatcher(ids=["age", "gender", "liked_genres"])
id_matcher=aiplatform.gapic.IdMatcher(ids=COLUMN_NAME)
)
read_feature_values_request = aiplatform.gapic.ReadFeatureValuesRequest(
entity_type=entity_type, entity_id=entity_id, feature_selector=feature_selector
)
read_feature_values_response = client.read_feature_values(
request=read_feature_values_request
)
return read_feature_values_response
# 予測リクエスト
def request_predict(data):
headers = {'Content-Type': 'text/csv', 'Authorization': 'Token {}'.format(API_TOKEN), 'Datarobot-key': DATAROBOT_KEY}
url = '{location}/predApi/v1.0/deployments/{deployment_id}/predictions'.format(
location=LOCATION, deployment_id=DEPLOYMENT_ID
)
resp = requests.post(url, data=data, headers=headers)
if resp.status_code >= 400:
raise RuntimeError(resp.content)
return resp
# 予測処理時間チェック
def check_predict_time():
full_time = 0
for i in list(range(START_NUM, END_NUM, 1)):
start = time.time()
feature = read_feature_values_sample(PROJECT,"aie_jp_feature_store","customer_loan_info",str(i))
value_row = ""
for i in feature.entity_view.data:
value_row += i.value.string_value + ","
value_row = value_row[:-1]
predict_data = '\n'.join([COLUMN_ROW, value_row])
request_predict(predict_data)
process_time = time.time() - start
print(process_time)
full_time += process_time
avg_time = full_time / CONTINUE_NUM
print('avg:' + str(avg_time))
# 特徴量取得処理時間チェック
def check_get_features_time():
full_time = 0
for i in list(range(START_NUM, END_NUM, 1)):
start = time.time()
feature = read_feature_values_sample(PROJECT,"aie_jp_feature_store","customer_loan_info",str(i))
process_time = time.time() - start
print(process_time)
full_time += process_time
avg_time = full_time / CONTINUE_NUM
print('avg:' + str(avg_time))
実験結果
①特徴量取得を100回実行
結果
- Average 0.274 sec / request
check_get_features_time()
0.26268815994262695
0.3037567138671875
0.2528853416442871
0.3494291305541992
0.34375524520874023
0.4218630790710449
…省略
0.10626888275146484
0.32819509506225586
0.3135831356048584
0.2529292106628418
avg:0.2744241166114807
①特徴量取得+②推論を100回実行
結果
- Average 0.989 sec / request
check_predict_time()
1.1247999668121338
1.046828031539917
1.046875
…省略
0.9218287467956543
0.9375073909759521
0.9062390327453613
avg:0.9895281982421875
所感
①特徴量取得を100回実行は、Average 0.274 sec / request という結果に。同じ東京リージョン内で完結する処理だったため、なんとなくもう少し早いかなーと思っていましたが、msecレベルで処理はできているので良しとしましょう。
①特徴量取得+②推論は、Average 0.989 sec / request という結果に。DataRobotがUSリージョンにあるので、平均1秒なら上々なパフォーマンスではないかなと思います。①特徴量取得+②推論を全てUSリージョンで完結させるパターンで最初試そうかと思ったのですが、日本のお客様は日本リージョンにデータやアプリ置くことが多いと思うので、今回の構成の方がより現実的な処理時間が確認できたのではないかと思います。