You can find the English version of this article here ⇒ Pandas Fundamentals
はじめに
今回の投稿の目的は、PythonライブラリであるPandasの基本的な機能と使い方を説明することです。
概要
Pandasは表形式のデータ(例:表計算やデータベースのデータ)を処理するためのPythonライブラリです。
データ分析や、機械学習の分野でよく使われます。
インストール
最新版は pip を用いてインストールすることができます。
pip install pandas
概念
まずは、ライブラリで使われている概念や用語を説明しておきましょう。
Series(シリーズ)
Seriesはリストのような一次元のデータ構造であり、色々なデータ型が格納できます(int, float, dict等)
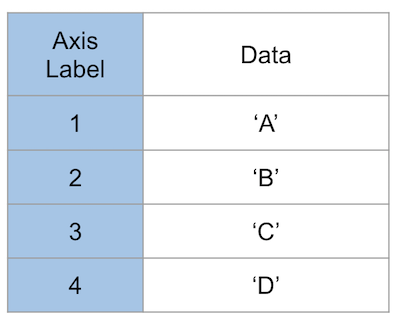
DataFrame(データフレーム)
- テーブルのように複数行と列をもつ2次元のデータ構造である
- 各カラムをSeriesと考えることができる
- 概念的にスプレッドシートまたデータベーステーブルに類似している
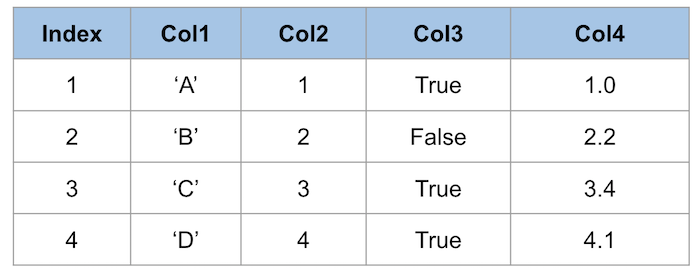
今回の投稿では、DataFrameの使い方に最も注目していきます。
DataFrame作成
多くの場合、ファイルやデータベースから既存のデータを読み込むことでDataFrameを作成します。
たとえば、CSV(カンマ区切り形式)ファイルを読み込むには、次のようにします。
import pandas as pd
df = pd.read_csv('example.csv')
df
また、PythonのdictオブジェクトからDataFramesを作成することもできます。
import pandas as pd
data = {'A': [1, 2, 3],
'B': ['X', 'Y', 'Z'],
'C': [0.1, 0.2, 0.3]}
df = pd.DataFrame(data)
>>> df
A B C
0 1 X 0.1
1 2 Y 0.2
2 3 Z 0.3
カラムのデータをアクセスする
DataFrame内のデータにアクセスする方法を見てみましょう。
以下のDataFrameを例として使います。
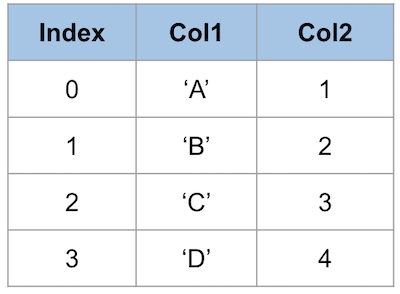
1つのカラムのデータにアクセスするには、主に2つの方法があります。
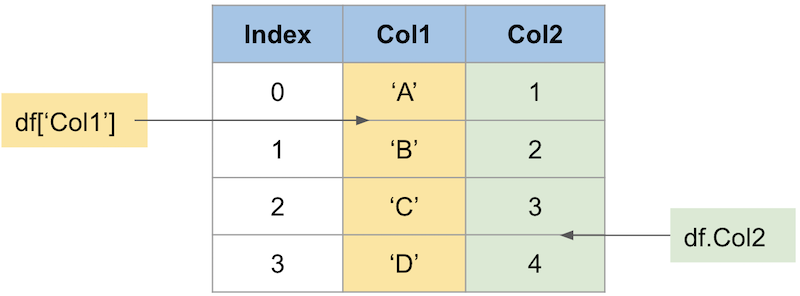
複数のカラムのデータにアクセスするにはカラム名のリストを入れます。
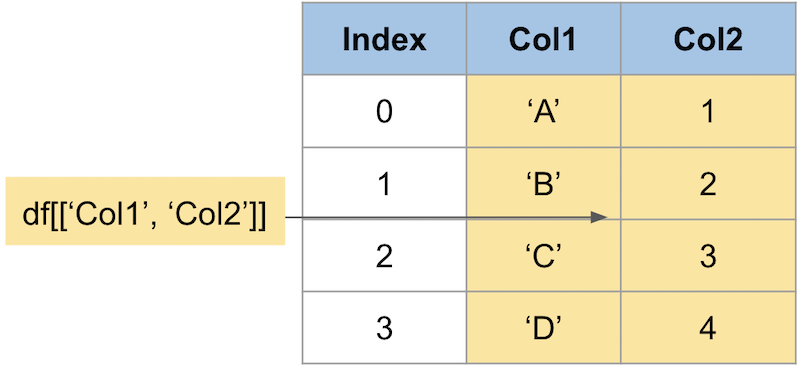
インデックス
次に、「インデックス」とは何か、どのように使えるのかを説明します。
DataFrameまたはSeriesの行と列を選択するために使用します。
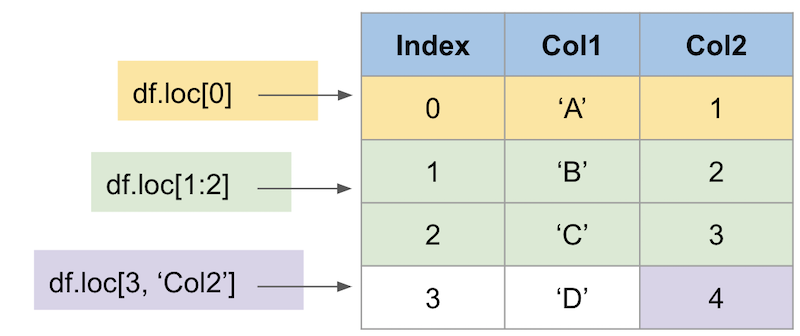
インデックスにアクセスするには、主に3つの方法があります。
-
locは特定のラベルを持つ列または行を取得する -
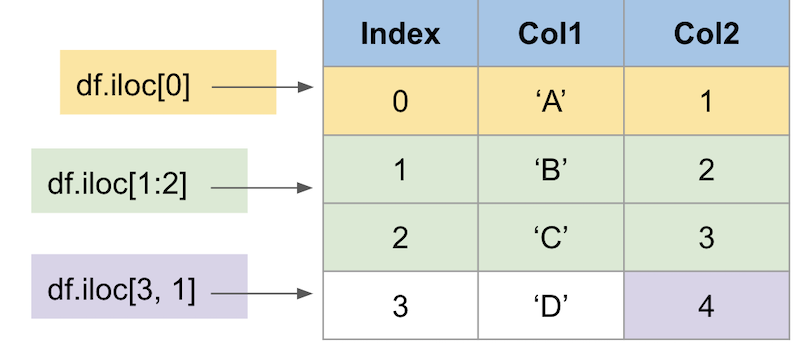
ilocは特定の位置で行または列を取得する -
ixは通常、locのように動作しようとしますが、ラベルがインデックスに存在しない場合、ilocのように動作します。 (非推奨なのでlocまたはilocを使用してください)
注:インデックスで数値ラベルがよく使用されるため、行を選択したときにilocとlocが同じ結果を返す可能性がある。 ただし、インデックスの順序が変更された場合(データがソートされた場合など)、結果は同じにならない可能性もある
それでは、locが使われている使用事例を見てみましょう。
それでは、ilocを使って同じデータを選択してみましょう。
多くの場合、インデックスには数値ラベルが使用されるので、行を選択する際に iloc と loc が同じ結果を返すことがあります。
しかし、以下の例のようにインデックスの順序が変更されている場合、結果は同じではないかもしれません。
data = {'Col1': ['A', 'B', 'C', 'D'],
'Col2': [1, 2, 3, 4]}
df = pd.DataFrame(data)
>>> df
Col1 Col2
0 A 1
1 B 2
2 C 3
3 D 4
DataFrameをCol2で並べ替えると、データの位置が変わるので、locとilocの結果が異なります。
df.sort_values('Col2', ascending=False)
Col1 Col2
3 D 4
2 C 3
1 B 2
0 A 1
条件付きステートメント
条件付きステートメントを適用することにより、DataFrameの一部を選択できます。 これには2つの方法があります。
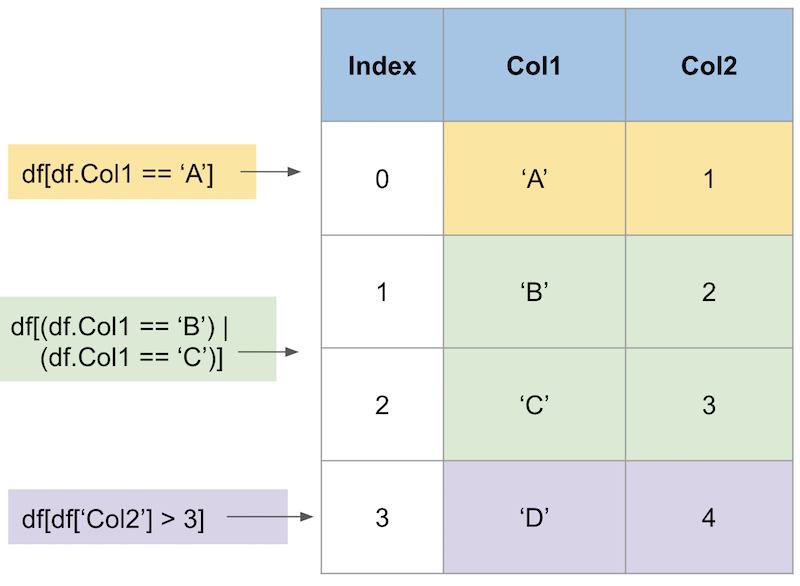
複数の条件を使用している場合は、それぞれの条件を括弧で囲む必要があることに注意してください。
例えば、これの代わりに
df[df.Col1 == 'A' | df.Col2 == 2]
>>> TypeError: cannot compare a dtyped [int64] array with a scalar of type [bool]
次のようにします。
>>> df[(df.Col1 == 'A') | (df.Col2 == 2)]
Col1 Col2
0 A 1
1 B 2
算術演算
代入を実行することで、DataFrame の内容を変更することができます。
また、以下の例にあるように、DataFrameに対して算術演算を行うこともできます。
算術演算は変更したDataFrameのコピーを返す
例として、Data Frame, dfを変更しましょう
data = {'Col1': ['A', 'B', 'C', 'D'],
'Col2': [1, 2, 3, 4],
'Col3': [1, 2, 3, 4]}
df = pd.DataFrame(data)
>>> df
Col1 Col2 Col3
0 A 1 1
1 B 2 2
2 C 3 3
3 D 4 4
まずは1つのセルの値を掛け合わせてみましょう。
>>> df.loc[0, 'Col2'] * 2
2
次に、Col3のすべての値から1を引いてみましょう。
df['Col3'] - 1
0 0
1 1
2 2
3 3
Name: Col3, dtype: int64
次に、Col3のすべての値に1を足して、その結果を元のDataFrameに代入してみましょう。
df['Col3'] += 1
>>> df
Col1 Col2 Col3
0 A 1 2
1 B 2 3
2 C 3 4
3 D 4 5
最後に、Col3の値が3より大きい場合にCol2に0の値を代入する条件を用いてみましょう。
df.loc[df.Col3 > 3, 'Col2'] = 0
>>> df
Col1 Col2 Col3
0 A 1 2
1 B 2 3
2 C 0 4
3 D 0 5
よく使う関数
Pandasは算術演算に加えて、DataFrameの処理を簡単にするための多くの関数を提供されています。
いくつかよく使う関数を紹介します。
| 関数名 | 目的 | 使用事例 |
|---|---|---|
| df.dropna() | 空値「NaN」のもつ行を外す | df = df.dropna() |
| df.fillna() | 指定された値で空値のもつ列をデフォルトする | df = df.fillna(1) |
| df.rename() | 列の名前を変更する | df.rename(columns={‘old’: ‘new’}) |
| df.sort_values() | 列でデータをソートする | df.sort_values(by=[’col1’]) |
| df.describe() | 列の統計情報を表示する (平均値, 最大値, 最小値, 等) | df.col1.describe() |
参考資料