過去にWordPressを題材にしていろいろな脆弱性のケーススタディを取り上げました。
今回は、ReDoS(Regular Expressions DoS)について取り上げてみたいと思います。ReDoSとはOWASPによると以下のように記載されています。
The Regular expression Denial of Service (ReDoS) is a Denial of Service attack, that exploits the fact that most Regular Expression implementations may reach extreme situations that cause them to work very slowly (exponentially related to input size). An attacker can then cause a program using a Regular Expression to enter these extreme situations and then hang for a very long time.
名前からも想像がつくようにDoS(Denial of Service)の一種で、正規表現による照合処理のパフォーマンスがボトルネックとなって引き起こされる脆弱性になります。有名な例を挙げると2016年7月にStack OverflowがReDoSによって、サービスを約30分も停止する事態に陥りました(実際はユーザーのイレギュラーな投稿によってトップページの表示に時間が掛かってしまい、ヘルスチェックでエラーになってロードバランサーから切り離されてしまったとのことです。狙って攻撃したのか偶然なのかは不明です)。
Stack Overflowの事例ではスペースをトリムするというシンプルな正規表現がトリガーとなってしまったわけですが、なぜこのような事が起こってしまうのかを理解するために、正規表現エンジンがどのような動きをするのかを確認してみたいと思います。
 正規表現エンジンの動きを見てみる
正規表現エンジンの動きを見てみる
今回は正規表現エンジンの動きを確認するためにregular expressions 101というサイトのregex debbugerを使います。このツールを使うとどのような順番で処理が行われているのかを視覚的に確認することができます(※デバッグできるのはPHPのPCREのみ)。
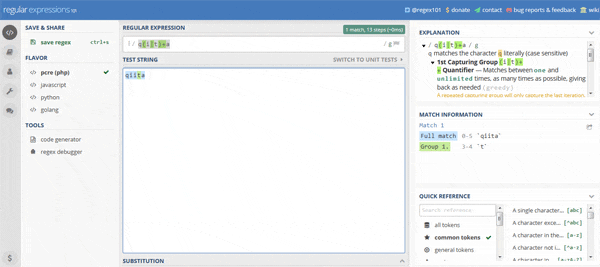
まず最初に以下のようなパターンを設定してデバッグしてみます。
q(i|t)+a
"qiita"という文字列でテストすると以下のようになりました。
赤い矢印はバックトラックが発生していることを表しています。簡単に流れを追ってみると以下のようになります。
- 照合を始めるための前処理。
- 最初の
qで照合し1文字目の"q"に一致。 - 次の
(i|t)+に移る。 -
(i|t)+の1番目のiで照合し2文字目の"i"に一致。 - グループ内で一致したのでキャプチャ。
- 再び
iに戻って照合し3文字目の"i"に一致。 - グループ内で一致したのでキャプチャ。
- 再び
iに戻って照合するが4文字目が"t"のため一致せず。 -
(i|t)+の2番目のtで照合し4文字目の"t"に一致。 - グループ内で一致したのでキャプチャ。
-
(i|t)+の1番目のiに戻って照合するが5文字目が"a"のため一致せず。 -
(i|t)+の2番目のtで照合するがこれも一致せず。 - 次の
aに移って照合し5文字目の"a"と一致。 - "qiita"とパターンが一致したので結果を返すための後処理。
ちょっとややこしいですね![]()
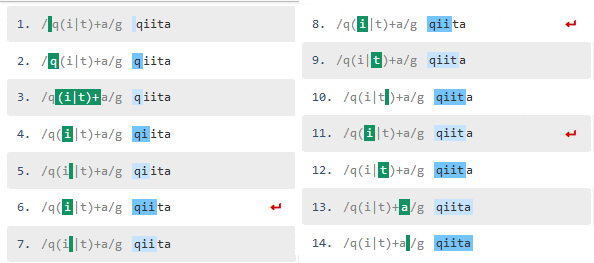
次に"qiiiita"と"i"を2文字を増やしてテストしてみましょう。
最初の例と比較して文字数が増えた分、iの照合回数が増えるので処理数も増えました。では、今度はパターンを以下のように変更してみます。
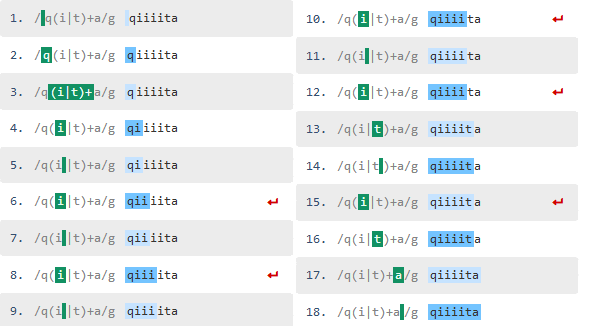
q(i+|t)+a
さっきよりも処理の数が減りました。i+となったので最長一致で"iiii"まで一致したためです。では、今度は"qiiiite"と変更してパターンに一致しないように変更します。
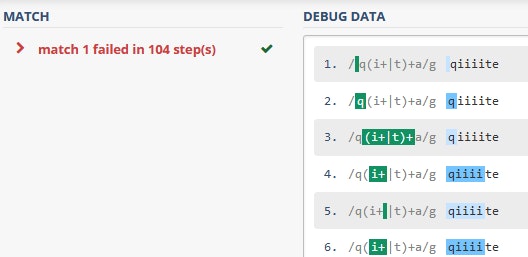
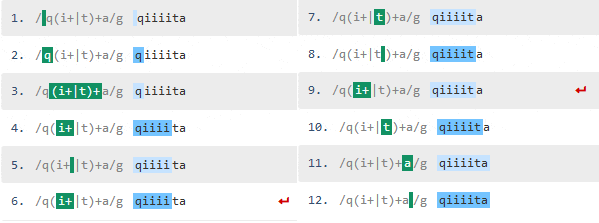
さっきとは打って変わって急に処理数が増えました。さらに文字列を増やして"qiiiiiiiiiiiiiite"に変更してみます。
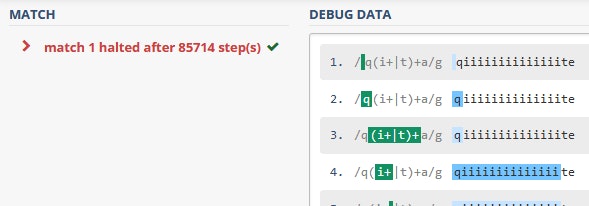
処理数が急激に増えて、制限をオーバーして停止してしまいました。なぜこのように処理が増えてしまったのか見てみましょう。
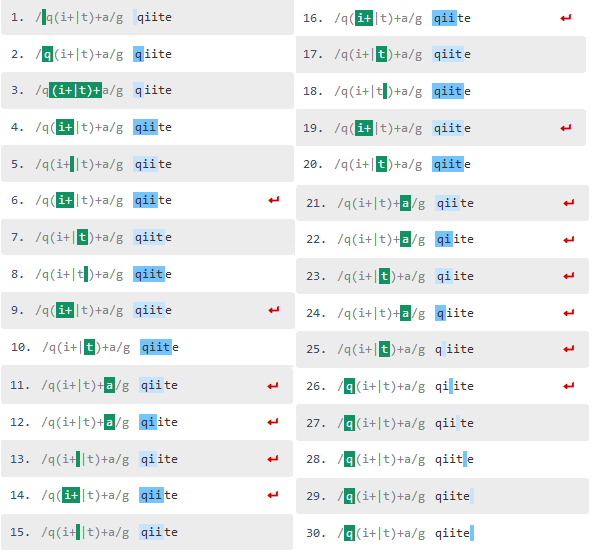
ちょっと分かりにくいのですが、最初はパターンのi+の部分が"ii"と評価されて一致していますが、"qiit"まで行って最後の"a"で一致しなかったので先程の"ii"のところまで戻って、今度は"i"と評価し直して照合を再開しています。これでも一致しないので今度はtで照合し、これも一致しないのでqに戻って照合しています。
特にi+の部分は"qiiiii....te"と"i"の数が増えれば増えるほどバックトラックの数も大幅に増えるため、処理数もそれにあわせて指数関数的に増えることになります(Catastrophic Backtracking)。
つまり、一致するデータの処理より一致しないデータの処理の方がはるかに処理の数が多くなるということです。これでReDoSの動作原理が何となくイメージできましたでしょうか?では、実際にあった脆弱性をいくつか見てみたいと思います。
 事例1.moment
事例1.moment
momentは日付関係の操作を行うためのnodeモジュールです。今回ご紹介するのは、2.15.2より前のバージョンで見つかったもので、月の書式に関する以下の正規表現です。
/D[oD]?(\[[^\[\]]*\]|\s+)+MMMM?/
"DD MMM"というような書式に一致するのですが、よく見ると最初に説明したサンプルと似ていて\s+の部分が怪しそうです。では、パターンと一致しない文字列を作って、空白文字の部分の数を増やしながら実行時間を計測してみたいと思います。
まず、スペース2個で実行してみます。すぐに処理が終わりました。

次にスペース30個で実行してみます。

わずか0.1秒足らずだったものが18秒以上掛かってしまいました。せっかくなのでPHPでも試してみたいと思います。

こちらは即座に0(一致しない)ではなくfalse(エラー)が返ってきました。PHPではpcre.backtrack_limitという設定でバックトラック処理の制限値がデフォルトで100万に設定されています。そのために途中で処理を中断してエラーになります。 1
参考)http://php.net/manual/ja/pcre.configuration.php
なお、脆弱性があった箇所は現在以下のように\s+が\sに修正されています。
/D[oD]?(\[[^\[\]]*\]|\s)+MMMM?/
事例2.marked
markedはマークダウンテキストをパース&コンパイルするためのnodeモジュールです。今回ご紹介するのは0.3.9より前のバージョンで見つかったもので、コードブロックに関する以下の正規表現です。
/^(`+)\s*([\s\S]*?[^`])\s*\1(?!`)/
構文でいくつか簡単に説明しておきますと、*?は最短一致の量指定子です。?が無いと末尾のバッククォートの前の空白文字も一致してしまうため付けられています。\1は1番目のキャプチャグループと同じテキストつまり最初のバッククォートと同じテキストであることを表しています(先頭に3つバッククォートがあったら末尾も3つという感じ)。?!は否定先読みです。バッククォートでない文字が続く場合に一致とみなされます(これがないとバッククォートが先頭3つで末尾4つでも一致してしまうため)。
これはどのような文字列が入ると問題になるかお分かりになりますでしょうか?一見しただけでは気付きにくいかもしれませんが、先頭と末尾のバッククォートの数を異なるものにしてパターンに一致しないようにし、バッククォートの中に空白文字が入れれば入れるだけ処理数が大きく増加していきます。言葉で説明するよりもデモをデバッグしていただいた方がよく分かると思いますので興味のある方は以下をご利用ください。
デモ:https://regex101.com/r/4CBPCL/1
空白文字を2000文字入れて実行した時の結果は以下になります。

約10秒ほど掛かってしまいました。なお、脆弱性があった箇所は現在以下のように修正されています。後方にあった\s*を\2に変更してバックトラックが発生しないようにしています。
/^(`+)(\s*)([\s\S]*?[^`]?)\2\1(?!`)/
事例3.mobile-detect
mobile-detectはUser-Agentからデバイスを判別するためのnodeモジュールです(PHPのMobile Detectの移植版)。今回ご紹介するのは1.4.0より前のバージョンで見つかったもので、Dell製のデバイスを判別する以下の正規表現です。
/Dell.*Streak|Dell.*Aero|Dell.*Venue|DELL.*Venue Pro|Dell Flash|Dell Smoke|Dell Mini 3iX|XCD28|XCD35|\b001DL\b|\b101DL\b|\bGS01\b/i
構文としては特に難しい内容はなく、デバイスの種類を12個並べているだけです(\bは単語の境界を表す)。これは比較的イメージしやすいかもしれませんが、"DellDellDellDell....."とつなげていくと処理数がどんどん増えて行きます。処理の流れとしては以下のような感じです。
- 文字列の最初の"Dell"が
Dell.*StreakのDellと一致。残りの"Dell....."が.*と一致。 - 終端まで到達したので
StreakのSと一致するまで一文字ずつ前に戻っていくが"DellDellDell....."なので一致するものがなく、Dell.*Aero⇒Dell.*Venueとパターンを変えながら同じ処理を繰り返していく。 - 結局どれにも一致しないので、"DellDellDellDell....."の最初の"Dell"から2番目の"Dell"に移って、また
Dell.*Streakから同じ処理を繰り返す。そしてそれが3番目の"Dell"、4番目の"Dell"と続いていく。
デモ:https://regex101.com/r/dh0smy/2
"Dell"という文字を1万回繰り返したテキストデータを作って実行した結果が以下になります。
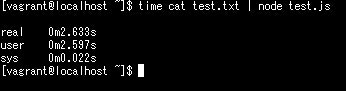
2秒以上かかっています。User-Agentは簡単に偽装できますので、大量のデータを送りつければWebサーバに高負荷をかけることが出来てしまいます。なお、修正後は以下のようにUser-Agentを500文字までに制限する処理が加えられました。
function prepareUserAgent(userAgent) {
return (userAgent || '').substr(0, 500); // mitigate vulnerable to ReDoS
}
事例4.whatwg-mimetype
whatwg-mimetypeはMIMEタイプをパースするためのnodeモジュールです。今回ご紹介するのは2.1.0より前のバージョンで見つかったもので、Content-Typeをタイプとパラメータに分割するための以下の正規表現です。
/^(.*?)\/(.*?)([\t ]*;.*)?$/
"text/html"や"multipart/form-data; boundary=aaaaa"のような文字列をパースしているのですが、見た目はシンプルで特に問題のない正規表現のようにも見えます。しかし、ここにもちょっとした見落としがあります。
例えば以下のように大量にスラッシュを続けた後、最後に改行を入れた文字列をパースさせると問題になります。
///////////////////////////.....(N個)..../////\n
試しにスラッシュを5万個用意した文字列を改行ありと無しでパースさせてみます。
改行あり

改行なし

改行なしはパターンに一致するため0.1秒足らずで処理を終了していますが、改行ありだとパターンに一致しなくなるためバックトラックが大量に発生し16秒以上掛かってしまいました。Content-Typeは簡単に偽装できますので大量のデータを送りつければWebサーバに高負荷をかけることが出来てしまいます。なお、修正後は正規表現を使わずに処理を全て書き直したようです。
まとめ
今回、いろいろな事例を見た中で多かった対応をまとめると以下の通りです。
-
*や+を削除する -
{n}を使いマッチする回数を制限する - アンカー(
^)を付ける - 文字列の長さを制限し、長い文字列は正規表現で処理させない
- 正規表現を使わずに別の方法で処理する
正規表現に長けた人であれば先読みやアトミックグループなどを使って効率の良い正規表現を書けるかもしれませんが、そうでない人の方が多いかと思います(私も毎回ググるタイプです![]() )。また、正規表現エンジンの違いにより動作が異なる場合もあるでしょう。今回のご紹介した事例は海外の優秀なプログラマーの方が作られたものでしたが、それでもやはりミスが出てしまいます。
)。また、正規表現エンジンの違いにより動作が異なる場合もあるでしょう。今回のご紹介した事例は海外の優秀なプログラマーの方が作られたものでしたが、それでもやはりミスが出てしまいます。
できるだけ複雑なパターンは避け、場合によっては多少冗長でも正規表現以外の方法で処理させることも検討した方が良いかもしれません(これはReDoSに限らず、正規表現をバリデーションとして使う場合のチェック漏れという観点からも同様だと思います)。 2
(記載内容に間違いがありましたらコメント・編集リクエストを頂けると幸いです![]() )
)
余談
URLのリライトで正規表現は避けられないので、apacheのmod_rewriteがどうなっているのか念のため調べてみました。ソースを確認したところpcre_execを実行していて、pcreapiマニュアルを確認したところ以下のように記載されていました。
The default value for the limit can be set when PCRE is built; the default default is 10 million, which handles all but the most extreme cases. You can override the default by suppling pcre_exec() with a pcre_extra block in which match_limit is set, and PCRE_EXTRA_MATCH_LIMIT is set in the flags field. If the limit is exceeded, pcre_exec() returns PCRE_ERROR_MATCHLIMIT.
1000万回ということでReDoSの心配はなさそうです。試してみましたがすぐに404が返ってきました。
追記(2021/04/21)
V8エンジンのv8.8から正規表現のバックトラックに関する実験的な機能が追加されました。
https://v8.dev/blog/non-backtracking-regexp
--enable-experimental-regexp_engine-on-excessive-backtracks enables the fallback to the non-backtracking engine on excessive backtracks.
(過剰なバックトラッキングに対して非バックトラッキング エンジンへのフォールバックを有効にする)
--regexp-backtracks-before-fallback N (default N = 50,000) specifies how many backtracks are considered “excessive”, i.e. when the fallback kicks in.
(過剰と判断するバックトラッキング数の閾値を設定する)
--enable-experimental-regexp-engine turns on recognition of the non-standard l (“linear”) flag for RegExps, as in e.g. /(a*)*b/l.
(非標準のl="linear"フラグをオンにする ※通常のIrregexpエンジンではなく新しいエンジンで処理する。ただし、ほとんどのパターンでIrregexpエンジンの方が圧倒的に処理が速いため実験的な機能)
2021/04/20にリリースされたNode.jsのバージョン16で、V8エンジンが8.6→9.0にアップグレードされ上記機能が試せるようになったので簡単に試してみました。
■フォールバックなし
$ time node -e '/D[oD]?(\[[^\[\]]*\]|\s+)+MMMM?/.test("D AA MMM");'
real 0m27.168s
user 0m27.167s
sys 0m0.000s
$ node -e 'console.log(/D[oD]?(\[[^\[\]]*\]|\s+)+MMMM?/.test("D AA MMM"));'
false
■フォールバックあり
$ time node --enable-experimental-regexp_engine-on-excessive-backtracks -e '/D[oD]?(\[[^\[\]]*\]|\s+)+MMMM?/.test("D AA MMM");'
real 0m0.043s
user 0m0.044s
sys 0m0.000s
$ node --enable-experimental-regexp_engine-on-excessive-backtracks -e 'console.log(/D[oD]?(\[[^\[\]]*\]|\s+)+MMMM?/.test("D AA MMM"));'
false