環境
- Microsoft Windows 10.0.22000.613(21H2)
- Windows PowerShell 5.1.22000.613
- conda 4.12.0
- Python 3.8.12.final.0
- tweepy 4.8.0
- csv 1.0
- PyTorch 1.11
はじめに
1. モチベーション
- Twitter API を使ってみたい
- GPT-2 を試してみたい
2. 誰のツイートにするか
まず、真面目な雰囲気の文章よりも個性的で独特な文章の方が学習の成果がわかりやすいのではと考えた。そこでコウメ太夫氏が思い浮かんだが調べてみると既に行われていた。
今回はまだ誰も行っていないようだったので平沢進氏のツイートを学習することにした。(次回はツイートではないが夢野久作の作品で試したい。)
そこで、平沢氏のツイートを観察し特徴を探してみた。
特徴
- 改行・空行が多い
- だ・である調が多め
- 独特な言葉選び
- 偶に末尾に「またこんど!!」と書く
生成された文章
学習データ:4/18以前のツイート約1000件
字数制限なし
GPT-2 の精度には本当に驚く。特徴を捉えていて個人的には全然違和感がなかったが、実際のところはどうなのだろうか。もし平沢氏のフォロワーの方が読まれていたら、是非ご意見・ご感想を頂ければと思う。(評価はこちらから)
今はその時代に突入したが、私はこのように考察している。
「世界は私から私へと移行を始めた」
ある意味、ヒラサワ枠がハエトリグモの中に突入してから2時間ほど時間が過ぎた。
それぞれの環境で長いのか、短いのか。
========
ここにきて私の人生は半永久的に停止線に巻き戻されることになる。
世界は半永久的に停止線の中に巻き戻されることを知る。
それなのに、世界は半永久的に停止線の中に共存している。
ところが、世界は半永久的に進行する。そこに「時間」という概念がなければ、「止まった」世界はこんなにも簡単に存在しない。
世界は半永久的に止まっている。
========
私は小学生の時からダンゴムシは大嫌いだ。理由なく脱皮する脱皮Gの脱皮を見て「これはダンゴムシじゃない、ダンゴムシじゃない」と言いたくなる。脱皮しようがしまいが、ダンゴムシを食べても脱皮しなくてもいいと思う。私の嫌うのは、脱皮したものから着るものだ。脱皮は脱皮という方法でどこに投げても可能である。
ただし脱皮の逃げ方が悪いと脱皮の意味が抜けてしまう。
========
ステルス回転する人造人間に見えなくてもよかったものを。
それくらい私の身体は機械だらけだ。
========
貴方の心に生じた澱みに貴方の理を刻む日が来る日まで。
========
もう無理無理と絶望しながらもう無理と諦めようとした時、出会った。
とてもそうは見えない光景が見えた。
またこんど!!
========
ステルスQW・スタジオ・ライブに使用したPENONのスタッド・カーキーを2年間無駄使いした後に現在の東京のiモードに切り替えることにした。。。。
これであいつもステルスQW・スタジオ・ライブに出る。
またこんど!!
========
P-MODELの歌詞には「歌わなければどうぞ」という明確な境目がない。
その先に「あれこれやっていることを無駄に時間を費やす」などという表現があるかのようなタイトルと、「もう無理」と言っているかのようなタイトルの差が生じる。
それだけ短絡的思考回路が発達しているということ。
========
あ、騙されてる。騙されてるんだから仕方ないでしょう。とはいえ、そこは私の落ち度ゼロから来るものである。実際、この間はプロデューサーさんからアドバイスを受けたけど。もう少し落ち着いてくださいな。もう少し面白いキャラが居るんですよ。ああ、私を馬鹿にしないで。はい、もういい。
========
ある文化の日はその日にミュージカルが公演され、文化の日はその日に絵が投影される。
そのミュージカルは舞台上の舞台上からであり、舞台上の関係者から提供されるものではない。
私が創造したわけではない。
舞台の外に投影されているだけだ。
実際にツイートを投稿
アカウントを作って投稿してみた。
ここからは実装の説明をする。
準備
ここでは簡単に説明する。以下のサイトに詳しい手順が書かれている。
1. Twitterの開発者アカウントを作成
T予め Twitter にログインしておく。https://developer.twitter.com/ja にアクセスし、「申し込む」から開発者アカウントを作成する。

2. Bearer Token を取得
あとで使うのでコピーしておく。
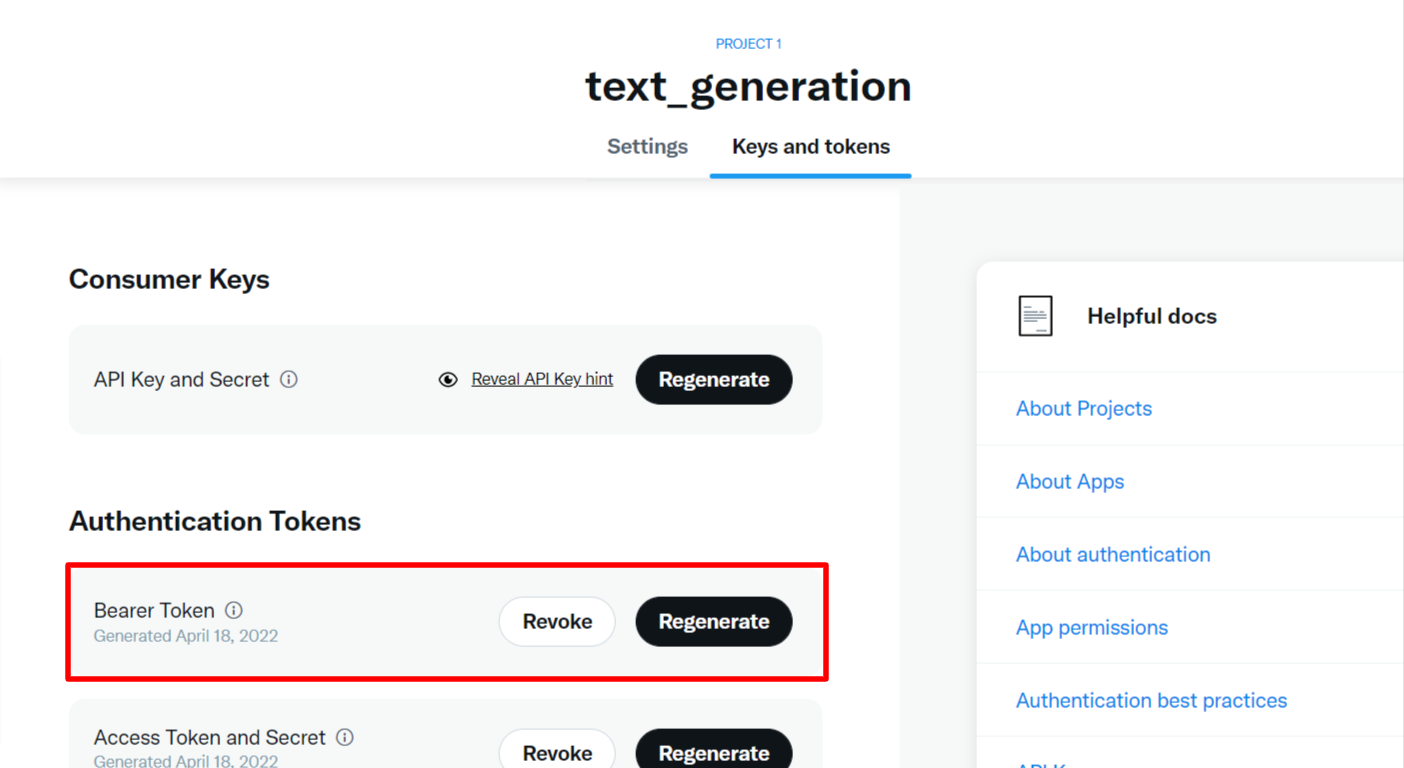
3. User authentication の設定
Developer Portal で App settings をクリックし、User authentication settings で OAuth 2.0 を有効にする。
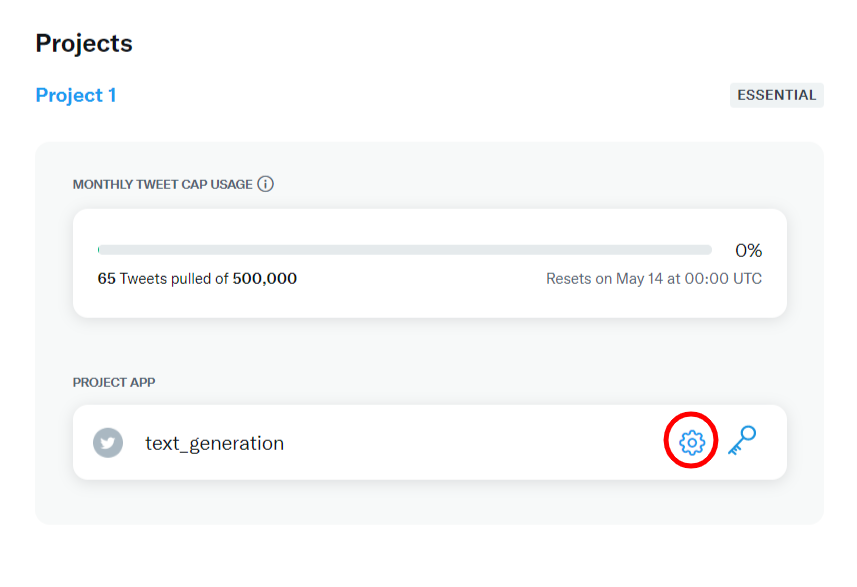
テスト用なので適当に設定した。
Type of App:Automated App or bot
Callback URI / Redirect URL:http://120.0.0.1/(ローカルホスト)
Website URL:自作サイトのURL
コード
環境変数の設定
BEARER_TOKEN = "Bearer Token"
環境変数を取得
import os
from dotenv import load_dotenv
# .envを読み込む
load_dotenv()
# 環境変数を取得
BT = os.getenv("BEARER_TOKEN")
認証
Anaconda で tweepy をインストールする
conda install -c conda-forge tweepy
import tweepy
# Authentication(Twitter API v2)
# OAuth 2.0 Bearer Token (App-Only)
client = tweepy.Client(BT)
ユーザIDの設定
以下のサイトで、ツイートを取得したいユーザのユーザネーム( @ を除く)を入力して Convert する。
user_id = "User ID"
ツイートの取得
csvファイルにTweet IDとツイート内容を記録した。空行ができるのを防ぐため、ツイート内の改行 \n は <n> に置換した。また、いくつか画像を含んでいるツイートがあったので手動で削除した。
tweet_data = []
with open(CSV_PATH, mode="a", encoding="utf-8") as f:
writer = csv.writer(f)
for tweet in tweepy.Paginator(client.get_users_tweets, id=USER_ID, max_results=100, exclude="retweets", until_id="ここで指定したTweet IDより古いツイートを取得できる").flatten(limit=取得したいツイート数を指定):
tweet_data.append([tweet.id, tweet.text.replace("\n", "<n>")])
writer.writerow([tweet.id, tweet.text.replace("\n", "<n>")])
# 確認
print("\n-------------------------------\n".join(["Tweet ID: "+str(x[0])+"\n"+x[1] for x in tweet_data]))
Tweet ID: 1508423085086883843
通常は一日1.5食のところライブの楽屋では二食以上食べてしまう。<n><n>出されるから食べてしまう。<n><n>しかし体重は減っている。<n><n>羨望の視線が注がれる身体。
-------------------------------
Tweet ID: 1508422048426905610
キーひとつひとつがピラミッド形をしており、打つと逆さまになります。<n><n>ピラミッドが逆さまにされてゆく日々。いいぞ、もっとやれ。
-------------------------------
Tweet ID: 1508421032159608841
サブのまたサブのマシンからのTwでありますからキーボードの形状に不慣れで誤字脱字がはびこっています。
1508423085086883843,通常は一日1.5食のところライブの楽屋では二食以上食べてしまう。<n><n>出されるから食べてしまう。<n><n>しかし体重は減っている。<n><n>羨望の視線が注がれる身体。
1508422048426905610,キーひとつひとつがピラミッド形をしており、打つと逆さまになります。<n><n>ピラミッドが逆さまにされてゆく日々。いいぞ、もっとやれ。
1508421032159608841,サブのまたサブのマシンからのTwでありますからキーボードの形状に不慣れで誤字脱字がはびこっています。
get_users_tweets() について
Client.get_users_tweets(id, *, end_time=None, exclude=None, expansions=None, max_results=None, media_fields=None, pagination_token=None, place_fields=None, poll_fields=None, since_id=None, start_time=None, tweet_fields=None, until_id=None, user_fields=None, user_auth=False)
取得できるツイート数
デフォルトでは、最新の10件のツイートがリクエストごとに返されるが、ページネーションを使用すると、最新の3,200件のツイートを取得できる。
レート制限
- App rate limit (OAuth 2.0 App Access Token): 1500 requests per 15-minute window shared among all users of your app
- User rate limit (OAuth 2.0 user Access Token): 900 requests per 15-minute window per each authenticated user
- User rate limit (OAuth 1.0a): 900 requests per 15-minute window per each authenticated user
ページネーションについて
学習データ作成
csvファイルからツイートを取り出し、末尾に <|endoftext|> をつけてテキストファイルに保存。
import csv
CSV_PATH = "tweets.csv"
TXT_PATH = "tweets.txt"
tweets = []
with open(CSV_PATH, mode="r", encoding="utf-8") as f:
reader = csv.reader(f)
for row in reader:
if(row == []):
continue
tweets.append([row[1] + "<|endoftext|>"])
with open(TXT_PATH, mode="w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(tweets)
通常は一日1.5食のところライブの楽屋では二食以上食べてしまう。<n><n>出されるから食べてしまう。<n><n>しかし体重は減っている。<n><n>羨望の視線が注がれる身体。<|endoftext|>
キーひとつひとつがピラミッド形をしており、打つと逆さまになります。<n><n>ピラミッドが逆さまにされてゆく日々。いいぞ、もっとやれ。<|endoftext|>
サブのまたサブのマシンからのTwでありますからキーボードの形状に不慣れで誤字脱字がはびこっています。<|endoftext|>
ツイート文の学習・生成
![]()
こちらでコードとともに説明している。
出力された文章の <n> を \n に置換すると見やすくなる。
参考