災害安否確認ちゃんを作って学ぶGoogle Cloud Run
社内10分勉強会 2025.3.6 たけじい

キャラクター:災害安否確認ちゃん
本日の内容
- なぜ「災害安否確認ちゃん」を「GCP」で作ろうと思ったのか
- システム全体像
- Google Cloud Runとは
- システム実装のポイント
- コンテナ化とデプロイ
- Cloud Schedulerによる定期実行
- 気象庁XMLフィードの活用
- Firestoreによるデータ管理
- SlackAPIによる通知機能
- 学んだこと・今後の展望
なぜ「災害安否確認ちゃん」を作ろうと思ったのか
- 災害時の安否確認システムが欲しいと会社の労務さんから相談を受けた
- 有料のサービスはいくつかあるが、簡易的なものでよく、コストがかからずにシンプルであることが重要
市販品はそこそこの値段がするわね・・・
なぜGCPなのか(アナタAWS認定試験受けてなかったっけ・・・?)
- 災害情報は大体RSSで配信されているようで、通知システムを作る際に「最新チェック日時」を保存する手軽なデータストアが欲しかった
- AWSでRDBを使うには重いしコストもかけたくないと考えた時Firestoreが思い浮かんだ
- 弊社SREさんが前職でGCPでSREやってた話を思い出して、AWSと同じようなことができるんじゃないかなと考えた
- 調べたらGCPもFirestoreも無料枠があり、うまく使えば無料枠で収まるなと思いチャレンジしてみた
実際どうだったか
めちゃめちゃ簡単にバックエンド環境をデプロイすることができて感動しました。
ぜひみんなにこのお手軽さを知ってほしいなと思い、今回筆を取りました。
ちなみにお値段(4日間)
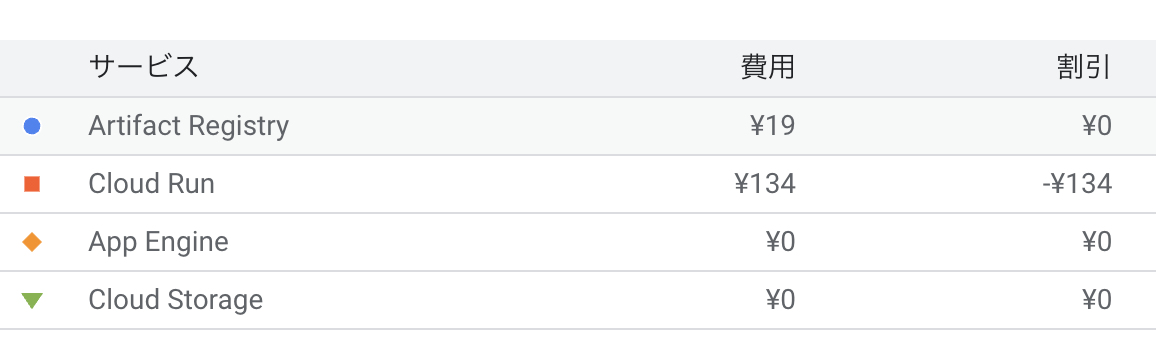
CloudRun自体は無料枠割引で0円。Artifact RegistoryはECRみたいなもので、デプロイしたコンテナを破棄せず全部とっておく設定になってたためと思われる。(最新だけ取っておくようなライフサイクル設定をしたので3月は1日1円くらいに抑えられると思う)
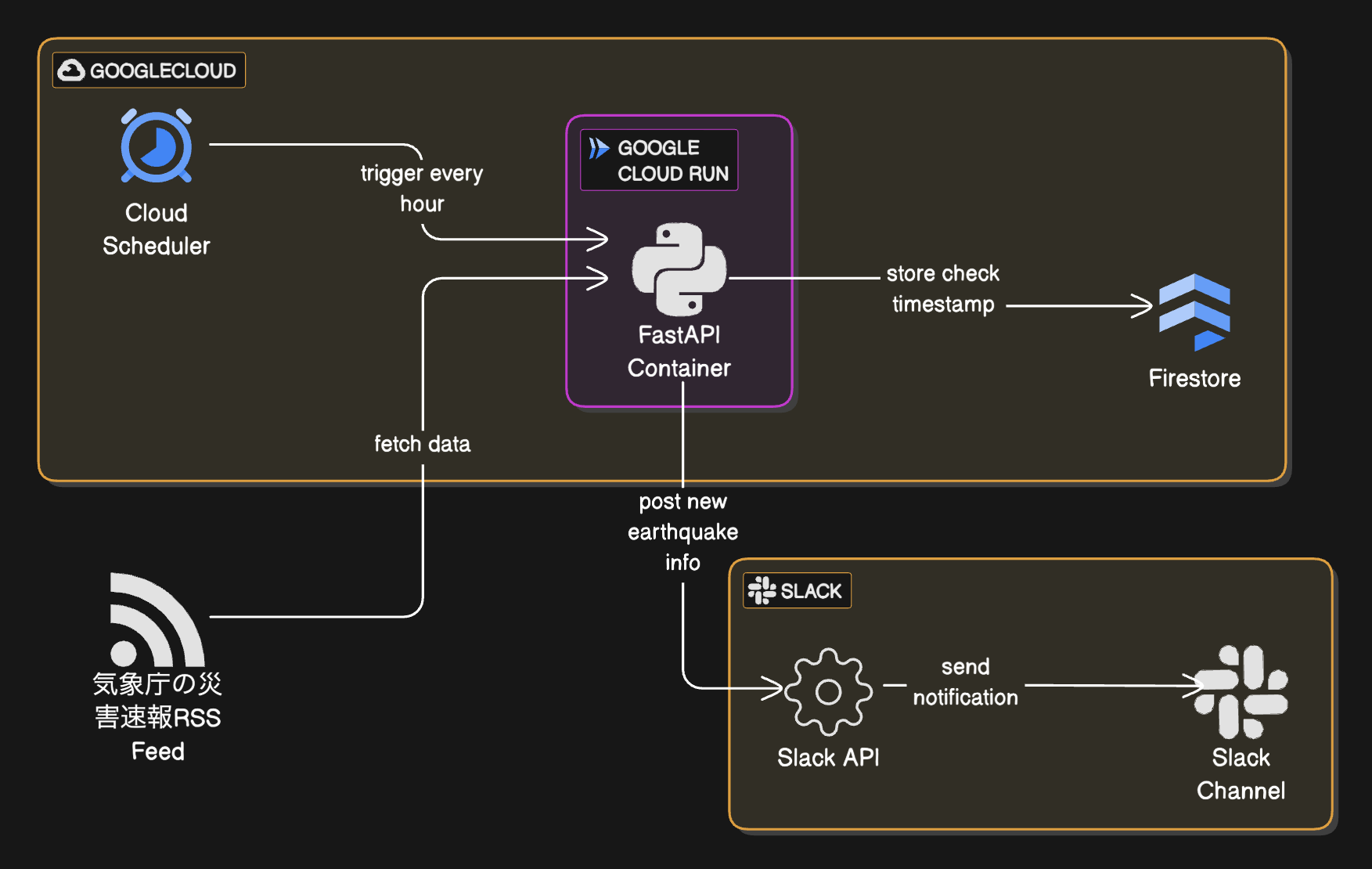
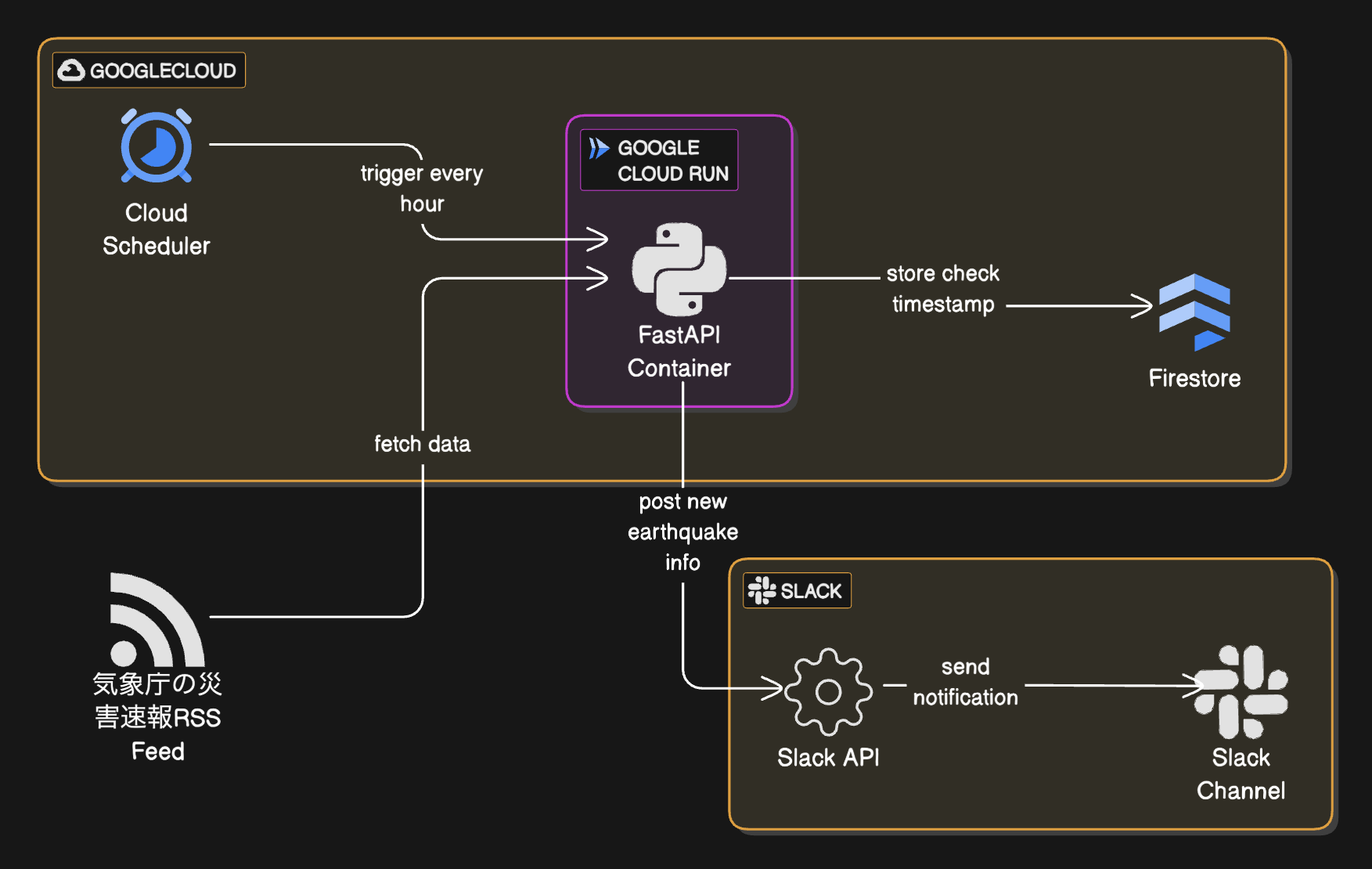
今回のシステム全体像(AI作図: https://www.eraser.io/ai)
- フロントエンド:SlackApp(安否スタンプつき地震通知)
- バックエンド:Python3.12 + FastAPI on Cloud Run, Firestore
Google Cloud Runとは
- Docker化されたアプリケーションや関数を簡単にデプロイできるサービス
- 使用したリソースに対してのみ課金
- 自動スケーリング機能
今回享受したGoogle Cloud Runの利点
- Dockerコンテナをそのままデプロイ
- CI/CDとの連携が容易(簡単Github mainブランチコミットDEデプロイ)
- トラフィックに応じた自動スケーリング(0スケール運用でコスト節約)
- フルマネージドでサーバー管理不要
システム実装:Dockerコンテナ化
Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
# コマンドを明示的に指定
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]
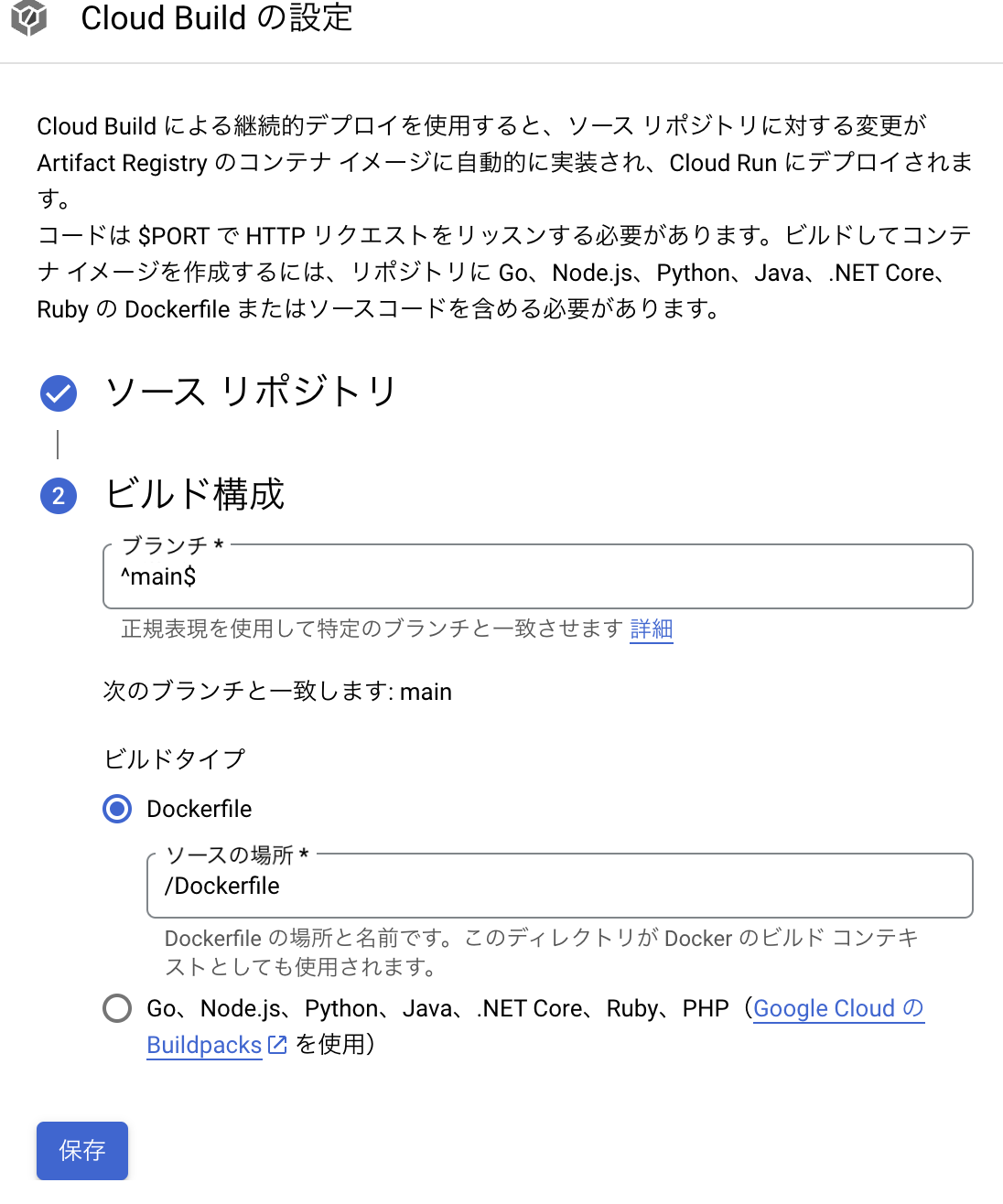
Google CloudBuildでの設定
GitHubのリポジトリと連携して、そのリポジトリのDockerfileを使ってコンテナイメージを作成することができる。mainブランチへのpushをトリガーに発動できる。
システム実装:利用ライブラリ
python3.12でfastapi,pydanticなどが使えるよ!
環境変数でfirebase用のアカウントjsonを読み込む必要があったのでpydantic-settingsも利用。(後述)
pyproject.toml
python = "^3.12"
fastapi = "^0.115.8"
uvicorn = "^0.34.0"
feedparser = "^6.0.11"
xmltodict = "^0.14.2"
pydantic-settings = "^2.8.0"
google-cloud-firestore = "^2.20.0"
めんどくさかったので poetry export -f requirements.txt --output requirements.txt で requirements.txtを生成。
システム実装:APIエンドポイント
app = FastAPI()
# 設定
RSS_URL = "https://www.data.jma.go.jp/developer/xml/feed/eqvol.xml" # 気象庁の地震・火山情報フィード
EMOJI_LIST = ["o", "x"]
CHECK_SINDO = 3 # この震度以上の地震を通知
@app.get("/")
def root():
fetch_rss()
return {"message": "RSS Monitoring Service is running"}
普通にFastAPI使えちゃう!
Cloud Schedulerによる定期実行(1時間おき)
誤報の可能性があったり、そもそも大地震でそこまでいち早く安否確認通知を出して反応できるか?ということもあるし、
何よりコストをかけないという制約があるので、今回は1時間に1回地震情報をとるようにする。
そのため、APIとしてコンテナを立ち上げっぱなしにすると言うより、スケジューラで定期的にリクエストを飛ばして実行するようにした。
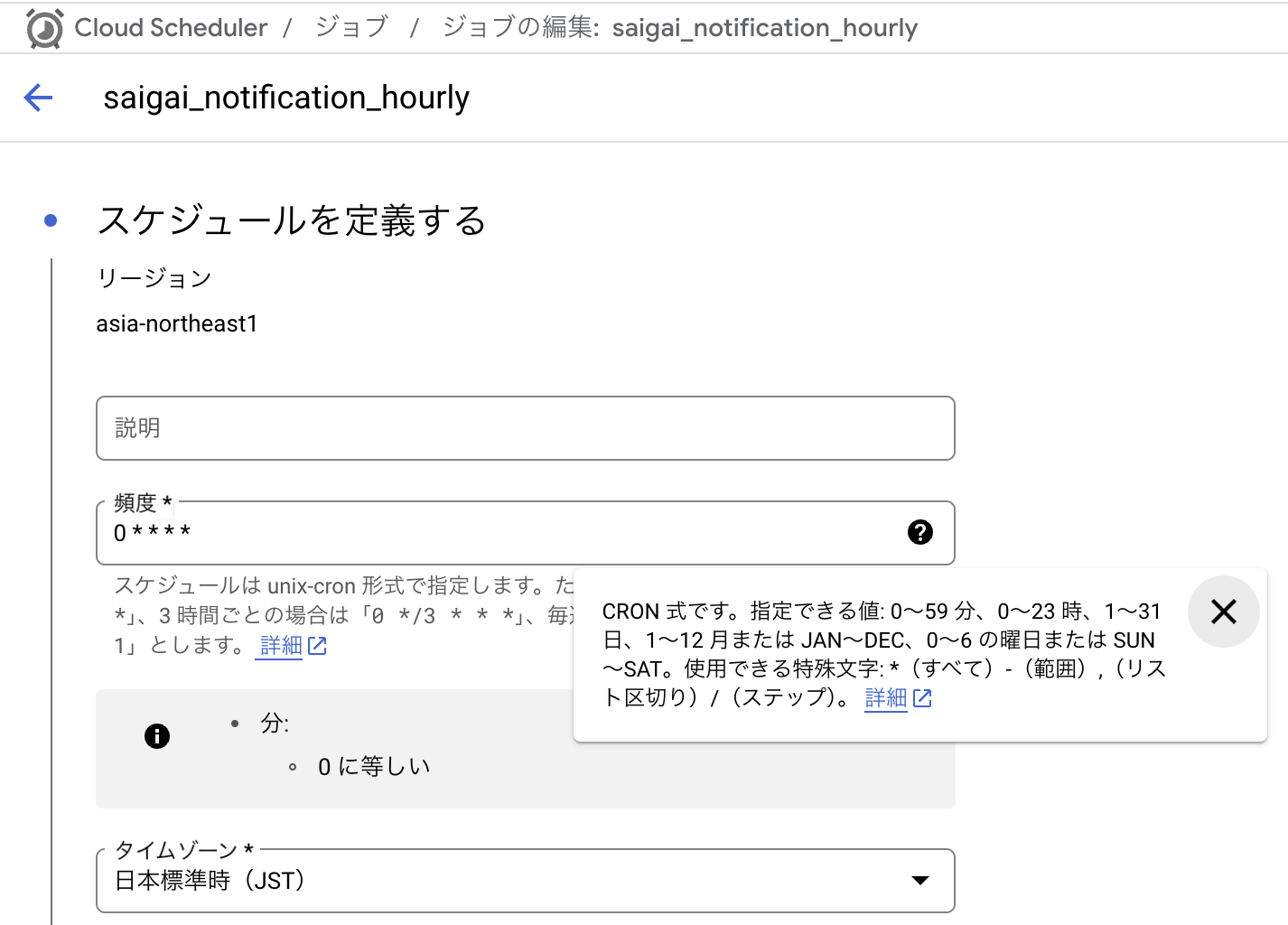
Cloud Schedulerはunix-cron形式で頻度を指定できる。
0 * * * *
このようにすれば1時間に一回という実行になる。
Cloud Runの指標を見ても、ちゃんと1時間に一回起動していることがわかる。
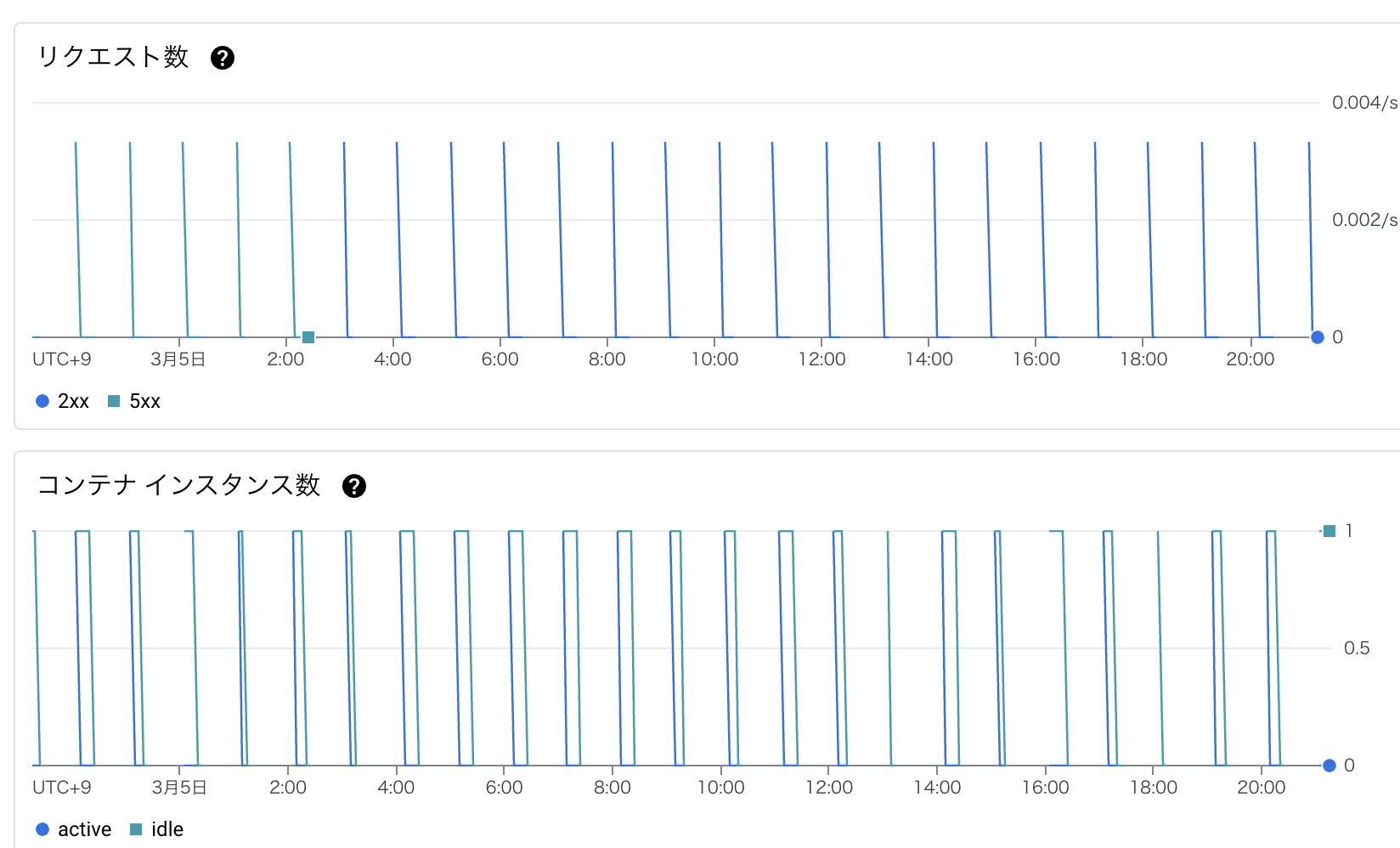
Cloud Schedulerによる定期実行(1時間おき)
実行はHTTPリクエストの他、Pub/SubやGoogleAppEngineへのリクエストも可能。

Cloud Schedulerによる定期実行の設定と実行の様子
定期実行の設定
地味にJST指定できるのが嬉しい。
実行の様子
1時間おきに実行されている。
システム実装:気象庁の地震火山情報Feed
https://www.data.jma.go.jp/developer/xml/feed/eqvol.xml
抜粋(火山の降灰予報がめっちゃ多い。震度速報は震度3以上じゃないと飛んでこないようで、今回は震度速報を拾うことにした。)
一応、ここ(https://xml.kishou.go.jp/tec_material.html)にドキュメントがあるがさっぱりわからんのでxmlみて雰囲気で作ることにした。
<feed xmlns="http://www.w3.org/2005/Atom" lang="ja">
<title>高頻度(地震火山)</title>
<updated>2025-03-02T14:01:10+09:00</updated>
<entry>
<title>降灰予報(定時)</title>
<id>https://www.data.jma.go.jp/developer/xml/data/20250302050050_0_VFVO53_010000.xml</id>
<updated>2025-03-02T05:00:00Z</updated>
<link type="application/xml" href="https://www.data.jma.go.jp/developer/xml/data/20250302050050_0_VFVO53_010000.xml"/>
<content type="text">【火山名 諏訪之瀬島 降灰予報(定時)】 現在、諏訪之瀬島は噴火警戒レベル2(火口周辺規制)です。諏訪之瀬島で噴火が発生した場合には、2日21時から24時までは火口から北東方向に降灰が予想されます。</content>
</entry>
<entry>
<title>震度速報</title>
<id>https://www.data.jma.go.jp/developer/xml/data/20250301192647_0_VXSE53_010000.xml</id>
<updated>2025-03-01T19:26:47Z</updated>
<link type="application/xml" href="https://www.data.jma.go.jp/developer/xml/data/20250301192647_0_VXSE53_010000.xml"/>
<content type="text">【震源・震度情報】 2日04時23分ころ、地震がありました。</content>
</entry>
</feed>
feed自体には震度の詳細はなくて、entryのlinkにあるxmlを見にいく必要がある。
システム実装:気象庁の地震火山情報Feed 詳細
https://www.data.jma.go.jp/developer/xml/data/20250301192647_0_VXSE53_010000.xml Body Intensity Observation Prefあたりに最大震度や地域名が出ている。
<Report>
<Head xmlns="http://xml.kishou.go.jp/jmaxml1/informationBasis1/">
<Title>震源・震度情報</Title>
<ReportDateTime>2025-03-02T04:26:00+09:00</ReportDateTime>
<Headline><Text> 2日04時23分ころ、地震がありました。</Text></Headline>
</Head>
<Body>
<Intensity>
<Observation>
<MaxInt>2</MaxInt>
<Pref>
<Name>岩手県</Name><Code>03</Code><MaxInt>2</MaxInt>
<Area>
<Name>岩手県内陸南部</Name><Code>213</Code><MaxInt>2</MaxInt>
<City><Name>一関市</Name><Code>0320900</Code><MaxInt>2</MaxInt></City>
</Area>
</Pref>
</Observation>
</Intensity>
</Body>
</Report>
システム実装:地震Feedをどこまで検知したかを保存する
地震速報はrss feedなので地震情報は一定期間最初のfeedに残り続ける。
システム側でどの情報まで調べたかを保存しておき、何回も通知が行かないようにする必要がある。
コンテナをずっと立ち上げっぱなしにすればメモリに保存する方法も取れたが、コスト対策のためその方法は使えない。(コンテナは破棄される) そのため、何かデータを保存する仕組みが必要だった。
そこでFirestoreの出番です
最後に検知した地震情報をFirestoreに保存。Key-Value形式で簡単にデータ管理。
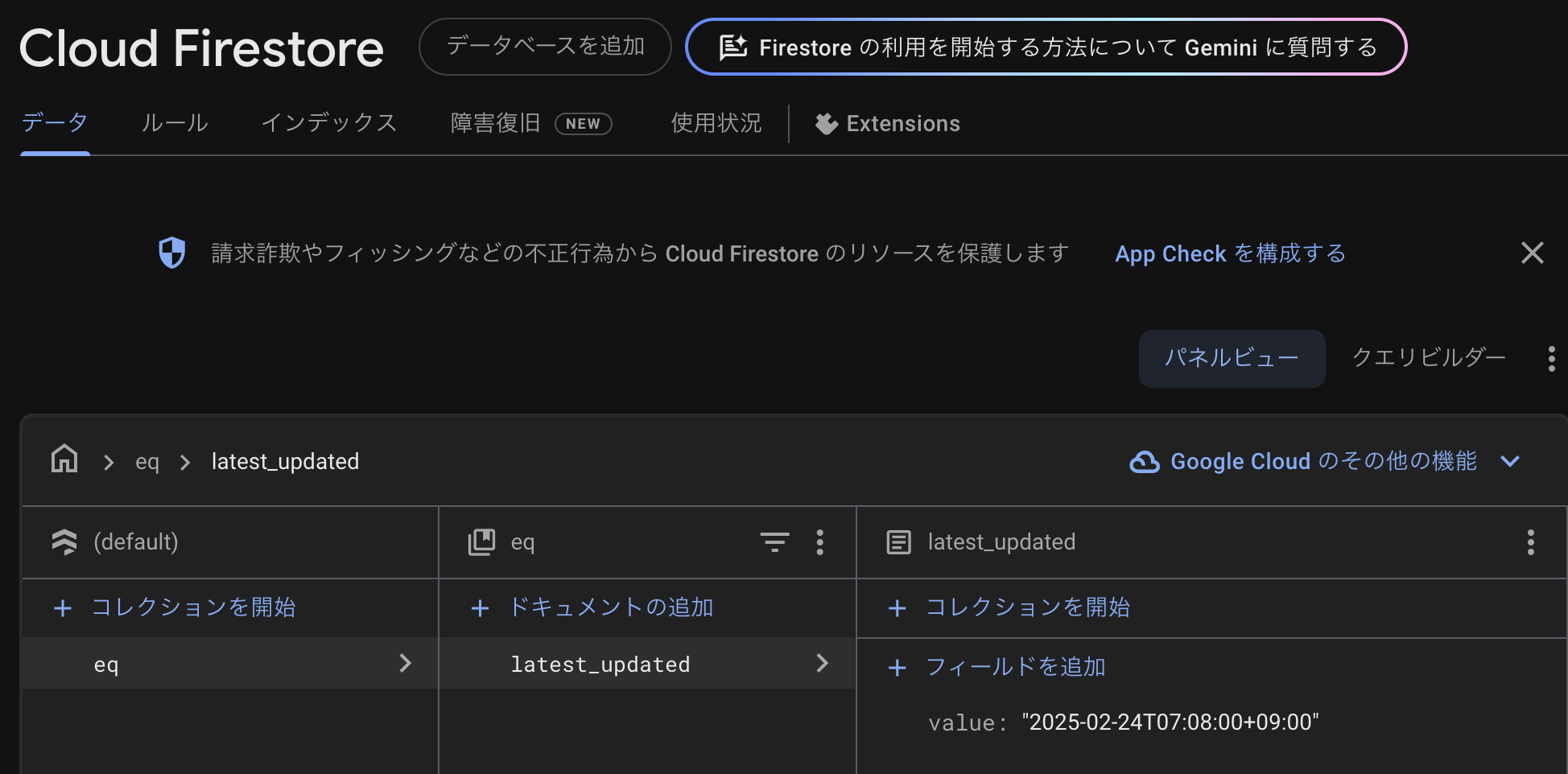
今回は単純に1つだけ値を保存・更新できれば良かったので、eq/latest_updated/value にデータを作りました。(eqはEarthQuakeの略。津波チェックも欲しくなるかもと。)
Firestoreを選択した理由とコスト利点(再掲)
従量課金制: 使った分だけ支払い
無料枠: 月間50,000回の読み取り、20,000回の書き込み、1GBのストレージが無料
読み取り/書き込み操作: 10万回あたり約$0.06
保存データ: 1GBあたり月$0.18
サーバーレス: インフラ管理コスト削減
自動スケーリング: トラフィック増加時も追加設定不要
高可用性: マルチリージョンレプリケーションによる災害時の信頼性確保
ちょっとしたデータの保存だったら、無料枠で済む。
https://firebase.google.com/docs/firestore/quotas?hl=ja#free-quota
バックエンドからのFirestoreアクセス実装
Firestoreユーティリティの実装
from google.cloud import firestore
class Firestore:
def __init__(self):
"""Firestoreクライアントを初期化"""
self.db = firestore.Client()
def get_document(self, collection_name: str, document_id: str):
doc_ref = self.db.collection(collection_name).document(document_id)
doc = doc_ref.get()
if doc.exists:
return doc.to_dict()
return None
def update_document(self, collection_name: str, document_id: str, data: dict):
doc_ref = self.db.collection(collection_name).document(document_id)
doc_ref.set(data, merge=True) # 既存データを保持しつつ更新
Firestoreユーティリティを利用する側の実装
def get_latest_updated_at():
firestore = Firestore()
data = firestore.get_document("eq", "latest_updated")
if data:
val = data.get("value")
if val == "":
return None
return val
else:
return None
def save_latest_updated_at(updated_at):
firestore = Firestore()
data = {
"value": updated_at
}
firestore.update_document("eq", "latest_updated", data)
Firebase関連を使うときの認証アカウント情報のセキュアな渡し方
Firebase関連サービスを利用する際、認証アカウント情報が入ったjsonファイルがある場所を、環境変数GOOGLE_APPLICATION_CREDENTIALSでファイルパスを指定してシステムを起動する必要がある。(認証基盤でもやった)
ローカルでは
GOOGLE_APPLICATION_CREDENTIALS=/Users/takehiroshi/~.json
このようにファイルを置いて渡せるが、CloudRunでこれを行うにはどうしたら良いか。
機密情報はSecret Managerを使おう1
GoogleのSecret Managerは環境変数に渡せるkey valueの値を保持できるほか、
今回のアカウントjsonをファイルとしてシークレット情報に保存し、コンテナからファイルをマウントして参照できる機能があります。
便利!!!
注意としては、コンテナから参照できるように、各シークレットに、権限でSecret Managerのシークレットアクセサーの指定が必要です。
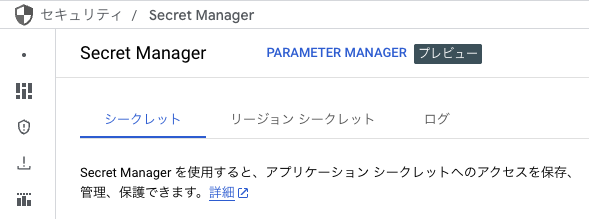
機密情報はSecret Managerを使おう2
画像のように、ファイル または 文字列 を与えることができます。
ファイルもあげれるし、値としても定義できる
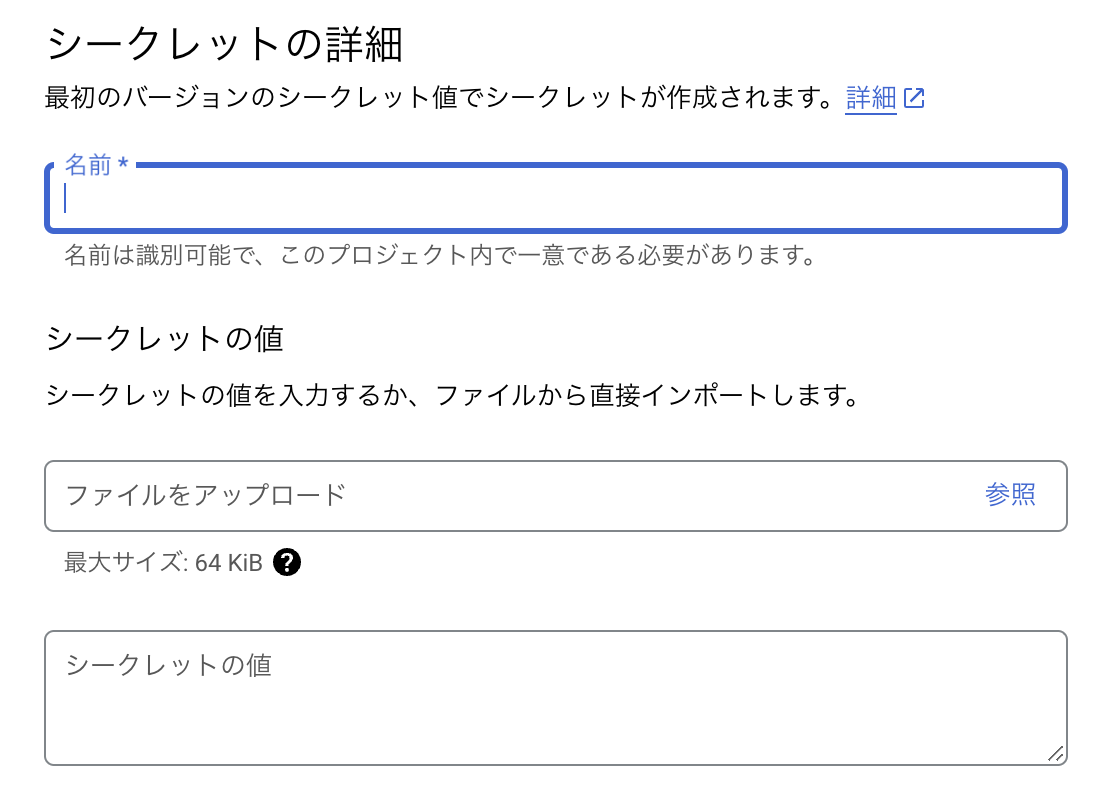
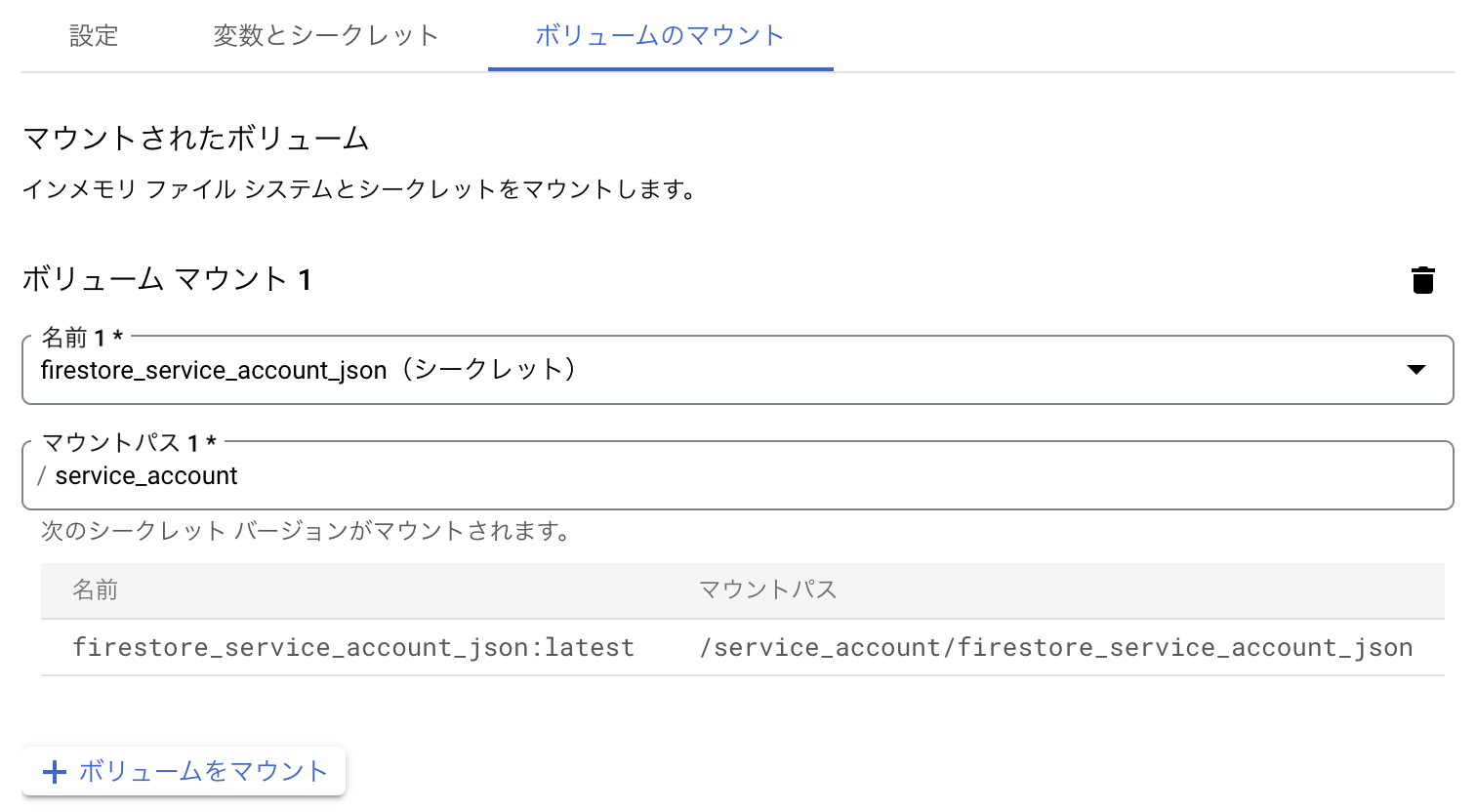
というわけで、firestore_service_account_jsonをファイルでアップロード
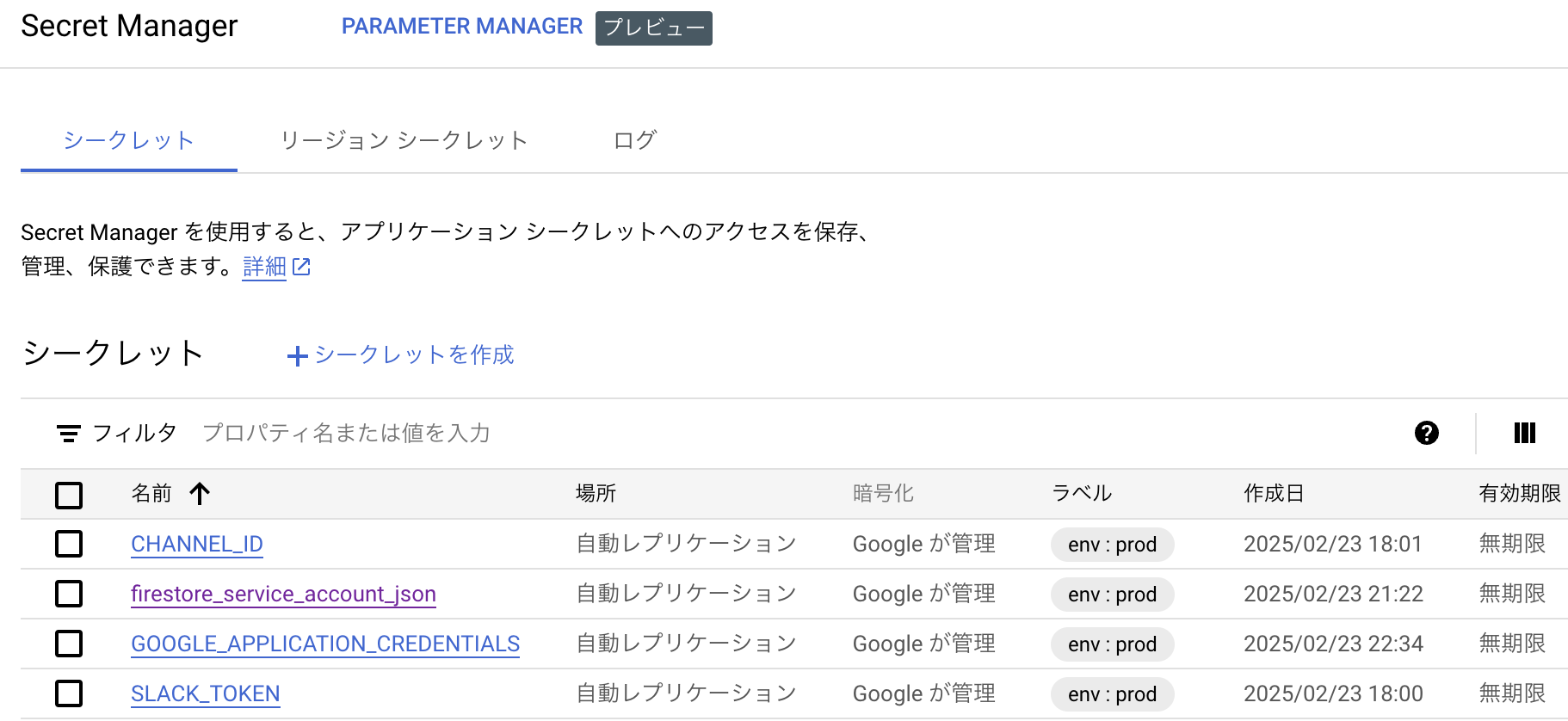
コンテナ側では、コンテナ定義の「変数とシークレット」の欄で、SecretManagerから取りたいシークレット名を指定し、環境変数としてコンテナ起動時に渡すことができます。
先ほどのSecretManagerにファイルとして定義したアカウントjsonは、「ボリュームのマウント」のタブから、
どこのファイルパスにファイルを置くかという感じで指定します。ここでは/service_account/firestore_service_account_json を指定しました。
なので、環境変数GOOGLE_APPLICATION_CREDENTIALSには値として、マウントしたパス /service_account/firestore_service_account_json を定義したというわけです。 ローカル環境でやっていた内容と同じことがCloudRun上でも再現できました。
機密情報はSecret Managerを使おう3
コンテナで利用するシークレットを指定して環境変数に設定
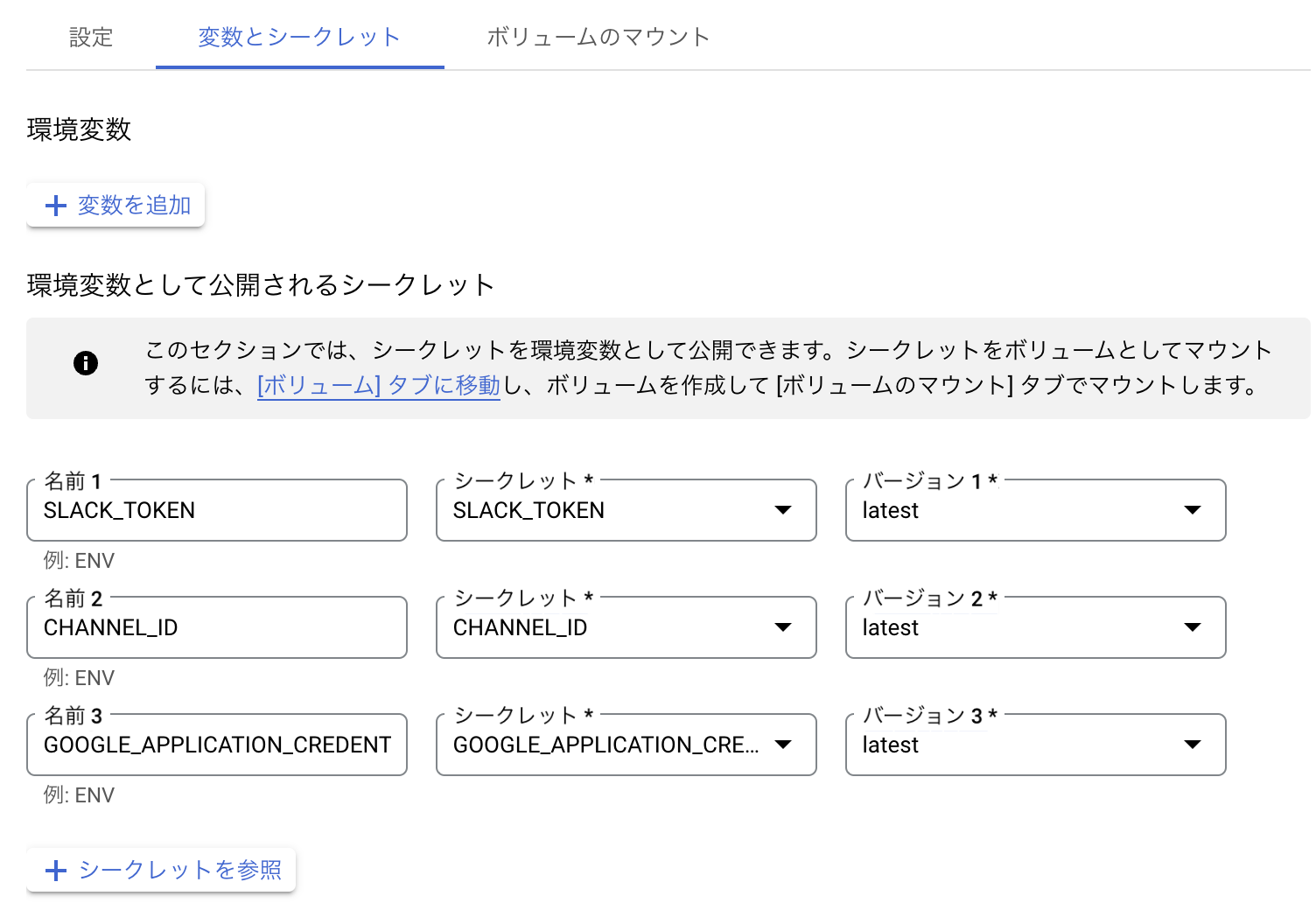
シークレットファイルはボリュームマウントして使う
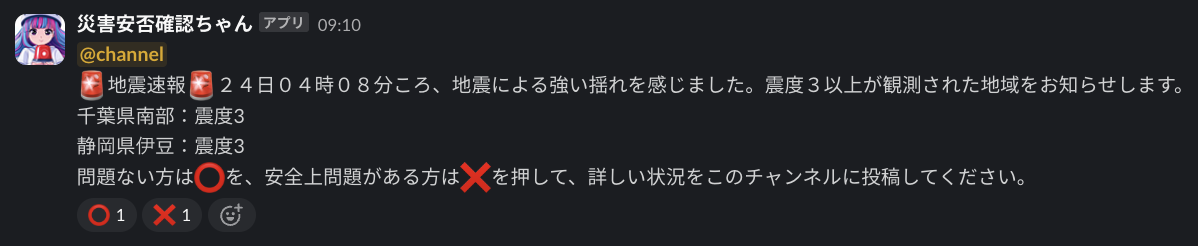
SlackAPIで、初期安否OK, NG スタンプ付きのメッセージを送る
SlackAppを作るのは手順が結構面倒なのですが、調べればわかるので割愛します。
ここではSlackAPIで、初期安否OK, NG スタンプ付きのメッセージを送る方法を紹介します。↓こういうの。選択肢のスタンプが1つずつ押されてるのがポイントですね。
SlackAPIで、初期安否OK, NG スタンプ付きのメッセージを送る(本文)
メインの投稿となる部分ではchannelメンション(<!channel>)をつけてチャンネル参加者にメンションします。(chat.postMessage)
EMOJI_LIST = ["o", "x"]
def post_message(title: str, text: str):
# メンションを付ける
text = "<!channel>\n" + text
text += "\n" + "問題ない方は:o:を、安全上問題がある方は:x:を押して、詳しい状況をこのチャンネルに投稿してください。"
# Slackに投稿
data = {
"channel": settings.CHANNEL_ID,
"username": title,
"text": text
}
headers = {"Authorization": "Bearer " + settings.SLACK_TOKEN}
r = requests.post("https://slack.com/api/chat.postMessage", headers=headers, data=data)
SlackAPIで、初期安否OK, NG スタンプ付きのメッセージを送る(スタンプ付ける)
続き。肝になるのが、◯と×の初期スタンプの付け方です。スタンプはつけるpostのtsをターゲットにreactions.addでつけることができます。oとxのスタンプをつけたいのでEMOJI_LISTをループで回して2回APIを呼び出しています。
EMOJI_LIST = ["o", "x"]
def post_message(title: str, text: str):
# 1. 前ページ
# 2. 投稿のtsを取得
ts = r.json()["ts"]
# 3. 2種類のスタンプを追加
for emoji in EMOJI_LIST:
data = {
"name": emoji,
"timestamp": ts,
}
url = "https://slack.com/api/reactions.add?" + "name=" + emoji + "×tamp=" + ts + "&channel=" + settings.CHANNEL_ID
r = requests.post(url, headers=headers, data=data)
デモ:災害安否確認ちゃんの動作
都合よく震度3以上の地震が起きれば良いのですが、多分起きないので(フラグ)
省略します。
こんな感じで通知がSlackに投稿されます。やったね!
今回のシステム全体像を再掲
- フロントエンド:SlackApp(安否スタンプつき地震通知)
- バックエンド:Python3.12 + FastAPI on Cloud Run, Firestore
ご理解いただけただろうか?
学んだこと1
Cloud Run活用
- CI/CDとの連携のお手軽さを実感(Github mainブランチコミットでデプロイ)
- トラフィックに応じた自動スケーリング(0スケール運用でコスト節約)
- APIキーなどのセキュア情報の安全な管理方法
- クラウドインフラでAWSとの共通点もたくさん知れた
アプリケーション設計
- Firestoreを活用したデータ保存の実現
- 環境変数を活用した設定管理
- SlackAPIの活用方法
学んだこと2
XML処理関連
- 気象庁XMLフィードの構造理解と効率的なパース処理
- 複雑なXMLスキーマに対する適切なデータ抽出方法
- 震度情報の階層構造を活用した地域別データの整理
まとめ
- Cloud Runは軽量サービスの迅速な展開に最適
- 無料枠を賢く使うことで社内向けの小さな便利ツールを作るような心理的ハードルがめちゃくちゃ下がる
- 開発環境からのスムーズなデプロイが可能
今後の展望
- 地震だけではなく、津波情報も拾えると嬉しいかも。
- 震度3以上がGCPにデプロイしてから起きてなくて、まだ本番稼働OKと言えないw 早くOK確認してお知らせしたい。
- このような小さい機能をサーバーレスでコストがかからないようにデプロイするのはAWS Lambdaに通じるものがある。実は同じような仕組みでPlaywrightによるPDF作成(脱wkhtmltopdf)も使えそうな目処がたったので、プロダクション環境へこのような仕組みを反映していきたい。
- 気軽にバックエンドインフラを構築できる方法を知れたので、次はフロントエンド構築もハードルが低い(コストかからない)やり方を調べたい。