作成日:2023年10月07日(土)
1.はじめに
2023年7月23日(日)のMicrosoftのBlog記事でOpenAIのWhisperがMicrosoft Azureでもうすぐ使えるようになるというアナウンスがありました。
首を長くして待っていたら、2023年9月15日(金)のAzure AI ServiceのBlog記事「OpenAI Whisper is Coming Soon to Azure OpenAI Service and Azure AI Speech - Microsoft Community Hub」で9月15日(金)から利用可能になると発表がありました。
そこで、さっそく人柱となってハマってみました。
2.Whisperとは
Whisperとは2023年3月1日(水)に米国OpenAI社が公開した汎用的な音声認識モデル(Speech recognition Model)のAPIです。
57の言語をマルチタスクで合計680,000時間もの機械学習を実施しており、音声認識に加えて音声識別、多言語音声認識にも対応したモデルです。
Whisperの音声認識モデルは以下の5つのサイズのモデルが存在し、それぞれ英語専用モデルと、マルチリンガルモデルが存在します。
音声認識モデルはサイズ、パラメタ数が大きくなればなるほど速度が遅く、音声認識制度が向上する特徴があります。
これらの音声認識モデルを動作させるには通常、NVIDIA製の高性能GPUとcuDNNドライバが必要です。
OpenAI Whisper記事参照(2023年6月3日(土))
以下に利用可能なモデルの名前とおおよそのメモリ要件、相対的な速度を示します。
| No | Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|---|
| 1 | tiny | 39M | tiny.en | tiny | ~1 GB | ~32x |
| 2 | base | 74M | base.en | base | ~1 GB | ~16x |
| 3 | small | 244M | small.en | small | ~2 GB | ~6x |
| 4 | medium | 769M | medium.en | medium | ~5 GB | ~2x |
| 5 | large | 1550M | N/A | large | ~10 GB | 1x |
※GitHUB openai/whisperページより引用
OpenAI Whisper記事の時には何とか動かしましたが、正直、Whisperをローカル環境で動かすのはハードルが高かったです。
3.利用可能なリージョン
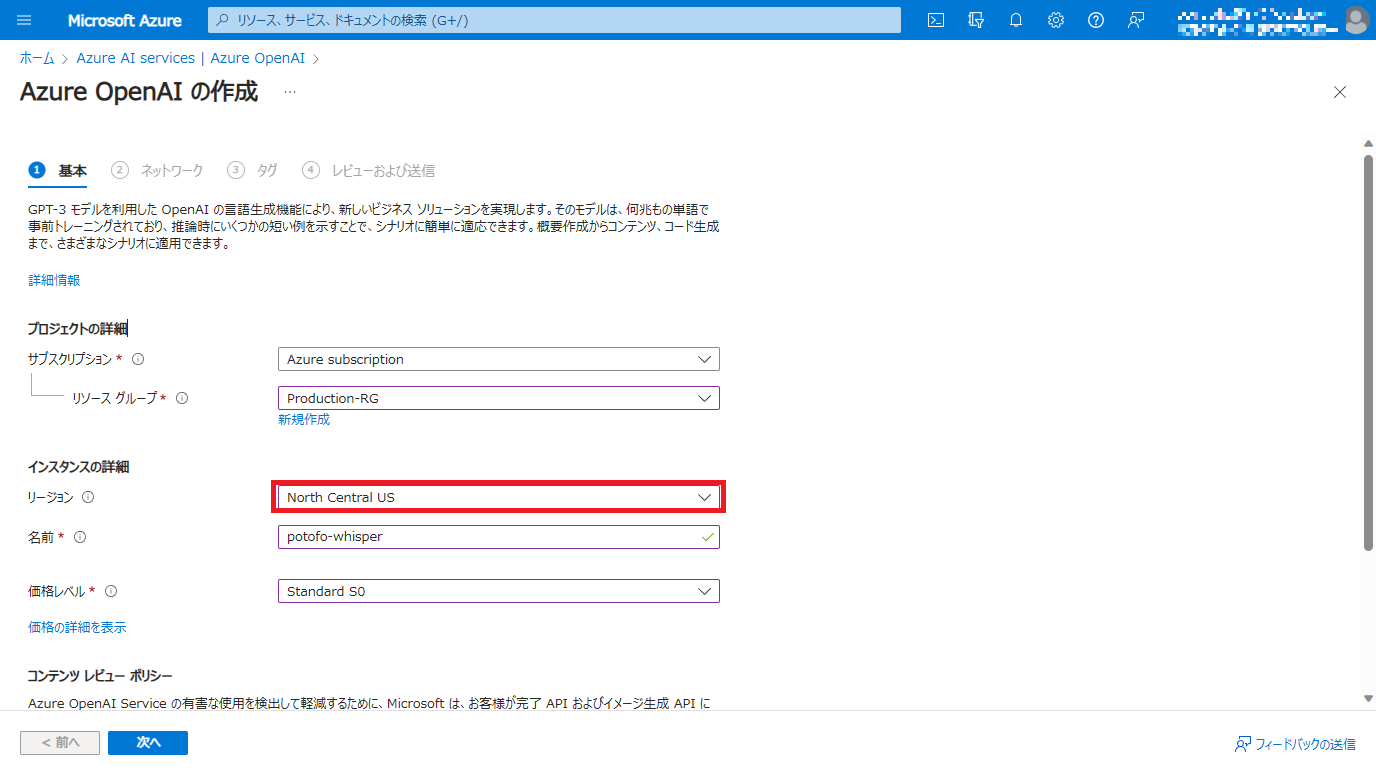
Quickstart: Speech to text with the Azure OpenAI Whisper modelページによると、Azure OpenAI Serviceを介したWhisperモデルの提供はNorth Central US(米国中北部)とWest Europe(西ヨーロッパ)のみです。また、Azure AI Speechを介したWhisperモデルの提供はEast US(米国東部)とEast South Asia(東南アジア)、West Europe(西ヨーロッパ)です。
それ以外のリージョンを指定した場合Azure OpenAI StudioでWhisperモデルがデプロイ一覧に表示されないので注意してください。
また、WhisperモデルはTPM(Token Per Minute)は現在1、RPM(Request Per Minute)は6に固定されています。
簡単に言うと1分当たり1000トークン、1分当たり6リクエストとなり、連続して利用できません。
また、クォータ上限も1000トークンとなるため、Whisperモデルはリージョンあたり1つしかデプロイできません。
| No | Azureのリージョン | 日本語リージョン名 | Azure OpenAI Service | Azure AI Speech |
|---|---|---|---|---|
| 1 | North Central US | 米国中北部 | ○ | |
| 2 | West Europe | 西ヨーロッパ | ○ | ○ |
| 3 | East US | 米国東部 | ○ | |
| 5 | East South Asia | 東南アジア | ○ |
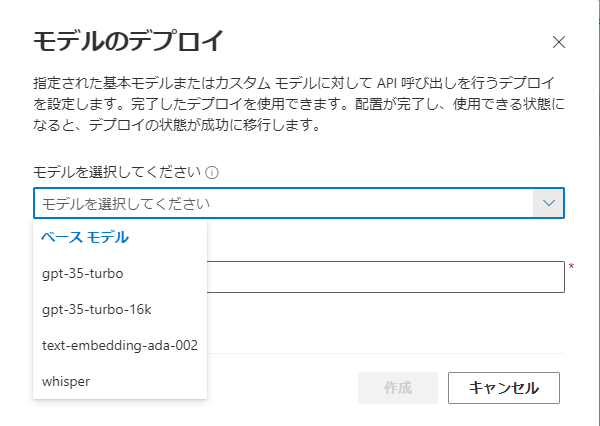
Azure OpenAI Studioでのモデルのデプロイ画面
- Whisper モデルとは? (Microsoft 2023/9/18)
- Quickstart: Speech to text with the Azure OpenAI Whisper model (Microsft 2023/9/16)
4.Azure OpenAI Service vs Azure AI Speech
Azure OpenAI Service vs Azure AI Speechそれぞれの特徴をまとめます。
今回公開されたAzure OpenAI ServiceのREST APIインタフェースではファイルサイズ上限25MBという制限があるため、無音箇所で切って、Chunk分割して処理する必要がありそうです。
4-1 Azure OpenAI Service
- ファイルサイズの上限は25MB(MP4動画で5分程度、MP3音声で10分程度)
- 音声ファイルを一度に一つずつすばやく文字起こしする
- 他の言語の音声を英語に翻訳する
- 出力をガイドするためのプロンプトをモデルに提供する
- サポートされているファイル形式: mp3、mp4、mpweg、mpga、m4a、wav、webm
4-2 Azure AI Speech
- 25 MB (最大 1 GB) を超えるファイルの文字起こし。 Azure OpenAI の Whisper モデルのファイル サイズの制限は 25 MB です。
- 音声ファイルの大きなバッチの文字起こし
- 会話に参加している異なる話者を区別するためのダイアライゼーション。 音声サービスは、文字起こしされた音声の特定の部分を話していた話者に関する情報を提供します。 Azure OpenAI を介した Whisper モデルでは、ダイアライゼーションはサポートされていません。
- ワードレベルのタイムスタンプ
- サポートされているファイル形式: mp3、wav、ogg
- シナリオの精度を向上させるための Whisper の基本モデルのカスタマイズ (近日公開予定)
5.利用可能なモデル
いろいろ探してみましたが、「What is the Whisper model?」ページによれば「The model is trained on a large dataset of English audio and text.」と記載があることからlargeのMultilingual modelではないかと思われます。
The Whisper model is a speech to text model from OpenAI that you can use to transcribe audio files. **The model is trained on a large dataset of English audio and text**. The model is optimized for transcribing audio files that contain speech in English. The model can also be used to transcribe audio files that contain speech in other languages. The output of the model is English text.
- Whisper モデルとは? (Microsoft 2023/9/18)
6.Pythonのサンプルコードは動きませんでした
Azureページ内のサンプルコードはcurlで記載されておりますが、うまく動きませんでした。
恐らくGPTモデルの時のようにapi-type、api-base、api-versionやdevelopment_idが必要なのに省略しているからだと思いました。
それからGPT
6-1 Azureページのサンプルコード
せっかく、openai.Audio.transcribe()というAPIがあるというのにcurlで書いたらrequestを使いたくなってしまいますよね。www
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/MyDeploymentName/audio/transcriptions?api-version=2023-09-01-preview \
-H "api-key: $AZURE_OPENAI_KEY" \
-H "Content-Type: multipart/form-data" \
-F file="@./wikipediaOcelot.wav"
6-2 OpenAI社のサンプルコード
OpenAIのサンプルコードも非常に惜しかったですが、結論から言うとそのままでは動きませんでした。
openai.api_keyの記載が無いことに気づきOpenAI APIサービス(本家)でAPIキーを発行して、以下のコードを追加したら動きました。
openai.Audio.transcribe()メソッドが動くことが確認できたので、ここから試行錯誤でパラメタを総当たりで試してみました。
import openai
**openai.api_key ='sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'**
file = open("/path/to/file/openai.mp3", "rb")
transcription = openai.Audio.transcribe("whisper-1", file)
print(transcription)
7.利用料金
「Azure OpenAI Service - 価格 | Microsoft Azure」、「Azure OpenAI Service - Pricing | Microsoft Azure」のNorth Central US(米国中北部)リージョンの価格表を確認しましたが、2023年10月7日(土)時点では価格が公開されていませんでした。
OpenAI系は本家と同じ価格かので参考までに2023年10月7日(土)時点の本家OpenAI社の価格情報を掲載しておきます。
| No | 料金 | 説明 |
|---|---|---|
| 1 | USD0.006/minute | 1分間の動画/音声ファイルあたりUSD0.006(約0.9円) |
- Introducing ChatGPT and Whisper APIs (Whisper API)
8.制限事項
- largeモデル以外が利用できません。
9.ソースコード
GitHubに作成したシンプルなサンプルコードをアップしていますので、ご自由にご利用ください。
Azureのopanai.api_versionは最新は「Azure OpenAI Serviceの新機能」をご覧ください。
https://github.com/potofo/whisper-azure
# Simple sample code to use the Azure OpenAI Service's Whisper API from Python
# LICENSE:MIT License
# requirements python packages
# openai==0.28.1
# python-dotenv==1.0.0
import openai
import os
from os.path import join, dirname # for establish path
from dotenv import load_dotenv # for Loading .env file
# Get Environment Variables
load_dotenv(verbose=True)
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
# Set parameter of Azure OpenAI Service whisper
# The actual parameters are read from those stored in the .env file
# openai.api_type = 'azure'
# openai.api_base = "https://xxxxxxxx.openai.azure.com/"
# openai.api_key ='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
# openai.api_version ='2023-09-01-preview'
# deployment_id = 'whisper'
# language = 'ja'
# OPENAI_API_TYPE : The API type provided in invalid. Please select one of the supported API types: 'azure', 'azure_ad', 'open_ai'
openai.api_type = os.getenv("OPENAI_API_TYPE")
# OPENAI_API_HOST : Access denied due to invalid subscription key or wrong API endpoint. Make sure to provide a valid key for an active subscription and use a correct regional API endpoint for your resource.
openai.api_base = os.getenv("OPENAI_API_HOST")
# OPENAI_API_KEY : The API deployment for this resource does not exist. If you created the deployment within the last 5 minutes, please wait a moment and try again.
# Access denied due to invalid subscription key or wrong API endpoint. Make sure to provide a valid key for an active subscription and use a correct regional API endpoint for your resource.
openai.api_key = os.getenv("OPENAI_API_KEY")
# OPENAI_API_VERSION : Resource not found error if you make a mistake
openai.api_version = os.getenv("OPENAI_API_VERSION")
# LANGUAGE : Invalid language 'japanese'. Language parameter must be specified in ISO-639-1 format.
language = os.getenv("LANGUAGE")
# AZURE_DEPLOYMENT_ID: The API deployment for this resource does not exist. If you created the deployment within the last 5 minutes, please wait a moment and try again.
deployment_id = os.getenv("AZURE_DEPLOYMENT_ID") # Deployment in Azure AI Studio
# Confirm Parameter of Azure openAI Service
print(f'api_type :{openai.api_type}')
print(f'api_base :{openai.api_base}')
print(f'api_key :{openai.api_key}')
print(f'api_version :{openai.api_version}')
print(f'language :{language}')
print(f'deployment_id :{deployment_id}')
# Specify model engine name
# This parameter necessary always be whisper-1.
model_engine = 'whisper-1'
# Music files are copyrighted by MaouDamashii
# Redistribution and modification are permitted under the following rules page.
# https://maou.audio/rule/
audio_file= open("./maou_14_shining_star.m4a", "rb")
# Executing the transcribe method
transcript = openai.Audio.transcribe(model=model_engine,
file=audio_file,
deployment_id=deployment_id,
language=language)
# Retrieve transcription results
print(str(transcript["text"]))
ソースコード中のlanguageはISO 639-1コード体系で設定する必要があります。
日本語にする場合は「ja」となります。

10.APIで発生したエラーと対策
| No | REST APIエラー | 対策 |
|---|---|---|
| 1 | The API type provided in invalid. Please select one of the supported API types: 'azure', 'azure_ad', 'open_ai' | openai.api_typeに「azure」、「azure_ad」、「open_ai」以外を設定した時に発生するエラーです。 |
| 2 | Access denied due to invalid subscription key or wrong API endpoint. Make sure to provide a valid key for an active subscription and use a correct regional API endpoint for your resource. | Whisperのエンドポイントアドレスに誤りがあるときに発生するエラーです。 内部で作成されるURLに含まれるWhisperモデルのデプロイ名を誤った場合もこのエラーが発生します。 |
| 3 | The API deployment for this resource does not exist. If you created the deployment within the last 5 minutes, please wait a moment and try again. | Azure OpenAI Serviceで作成したサービスインスタンスのAPIキーが誤っている時に発生するエラーです。 |
| 4 | Resource not found error if you make a mistake | WhisperモデルのAPIバージョンを誤った場合もこのエラーが発生します。 GPTモデルの時にも散々ハマりましたが、Whisperではさらにハマりました。GPTはPlaygroundでソースコードを表示すると、APIバージョン(例:2023-07-01-preview)が記載されていたのですが、WhisperではPlaygroundでソースコードが表示できません。 結局のところ、APIバージョンは「https://learn.microsoft.com/en-us/azure/ai-services/openai/whisper-quickstart?tabs=command-line」ページのcurlのサンプルが記載してあった「2023-09-01-preview」であることが分かりました。 |
| 5 | Deployment in Azure AI Studio | Azure OpenAI StudioでデプロイしたWhisperモデルのデプロイ名を誤った場合もこのエラーが発生します。 |
| 6 | Resource not found | Pythonコマンドを実行しているPowershellを再起動したらなおりました。原因不明ですがおそらく環境変数が取れなくなっていたのだと思います。 |
11.今後の目論見
シンプルなコードでAzure OpenAI ServiceのWhisperモデルの動作に成功しましたので、次はChunk分割とWebUIです。
Chunkは事例が結構あるので、そんなに難しくないのではと思っています。
WebUIについては最終的には会社の最長の会議3時間程度の文字起こしができることが目標ですので、mp4などはmp3に変換したのちChunk分割するべきと考えています。
12.参考URL
- **A**nnouncing the Preview of OpenAI Whisper in Azure OpenAI service and Azure AI Speech (Microsoft 2023/9/15)
- What is the Whisper model? (Microsoft 2023/9/16)
- OpenAIの文字起こしAI「Whisper」の使い方 (AIsmiley 2023/9/28)
- openai/whisper (GitHUB)
- potofo/whisper-azure (GitHUB)
- Whisper モデルとは? (Microsoft 2023/9/18)
- Quickstart: Speech to text with the Azure OpenAI Whisper model (Microsft 2023/9/16)