Adobe Illustratorの合成フォントのプリセットデータを覗いてみた。
生成ツール
jsonから生成できるツールを作った
詳しい構造はこれ見て
https://github.com/potistudio/composition-font-generator
ヘッダー
内部は4つのチャンクに分かれている。
- CFNA
- CID
- RLBL
- name
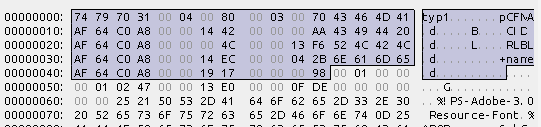
-
シグネチャ: 4byte (typ1)
-
padding: 8byte
-
ヘッダーたち (16byte x4)
シグネチャは typ1、このファイルがイラレの合成フォントであることを表している。
次の8byteは分からないのでスキップ
そっからはデータを構成する4つのチャンク情報がそれぞれ16byteずつ
この中でデータの核となりそうなのは CID と RLBLかな
CFNAとnameはメタデータっぽいし、あまり考えなくていいかも。
また、少し注意が必要なのは、CFNAとCIDは順番が逆だということ。
ヘッダーではCFNA → CIDの順で書かれているが、実際にはCID → CFNAの順でチャンクが置かれている。
CIDチャンク

ヘッダー部分 (16byte)
- tag: 4byte (CID )
- skip: 4byte
- offset: 4byte (0x4C)
- length: 4byte (0x13F6)
ファイル先頭から後の分
この例の場合、ファイル先頭から76byte先の5110byte分がCIDチャンクとなる

こっから
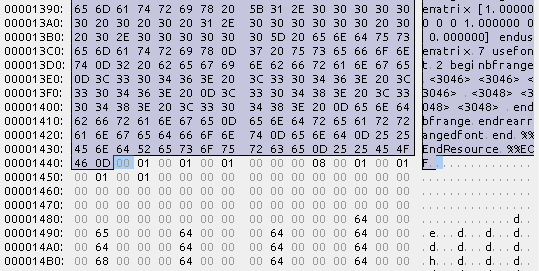
ここまで
この中に、フォント名だったりスケールだったりが入るらしい
長い
CFNAチャンク

ヘッダー部分 (16byte)
- tag: 4byte (CFNA)
- skip: 4byte
- offset: 4byte (0x1442)
- length: 4byte (0xAA)
ファイル先頭から後の分
この例の場合、ファイル先頭から5186byte進めたあとの170byte分がCFNAチャンクとなる
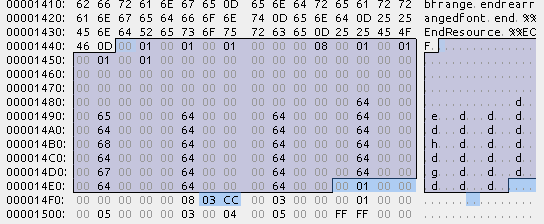
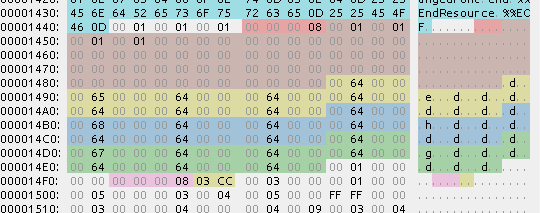
CFMAチャンクは以下のような構造になっている。
- 謎: 6byte
- 文字セット数: 8byte
- 拡大: 8byte * 文字セット数
- サイズ: 4byte * 文字セット数
- 水平比率: 4byte * 文字セット数
- 垂直比率: 4byte * 文字セット数
それぞれイラレの以下の設定値に対応している。
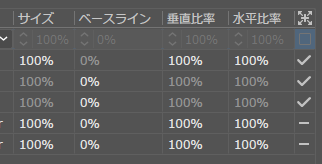
なお、ベースラインについては、CFMAに存在しないため、CIDのmatrix部分を見る必要がある。
文字セット数8byteには、設定されている文字セットの総数が書かれている。
値は最小で6、特例文字セットを2つ追加していれば、8となる。
RLBLチャンク

ヘッダー部分 (16byte)
- tag: 4byte (RLBL)
- skip: 4byte
- offset: 4byte (0x14EC)
- length: 4byte (0x042B)
ファイル先頭から後の分
この例の場合、ファイル先頭から5356byte進めたあとの1067byte分がRLBLチャンクとなる
こっから
ここまで
居ますね、ヤツが
まずは、L 0 9 0からKanjiまでの部分
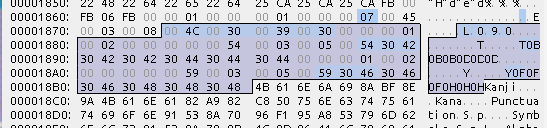
- 目印: 8byte ( L 0 9 0)
- 文字セットたち(個数分連なる)
- skip: 16byte
- offset: 2byte - Kanjiからのオフセット
- char: 2byte x3 (Unicode)
L 0 9 0はよくわからないが、なんか不変なので目印に使えそう
char 2byteには、特例文字セットで設定した文字がUnicodeで3つずつ ← ? 並んでる
「あ」と「い」だったら、U+3042とU+3044なので、
304230423042304430443044
↓↓↓
0B0B0B0D0D0D
となる
んで、Kanjiから先の部分
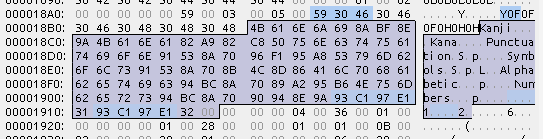
ここに文字セットの名前が、特に区切り記号などなく、詰めて連ねてある
まずはおきまりのやつら
Kanji漢字KaneかなPunctuation全角約物Symbols全角記号Alphabetic半角欧文Numbers半角数字
これの尻尾に特例文字セットが連なる
Kanjiから分進めた先に名前がある
(そして1つ目の文字セットのoffsetは必ず0x54(84byte)になる)
例えば、1つ目の「特例1」であれば、オフセットが0x54で84byte
よって、Kanjiから84byte進めた先に名前が存在する
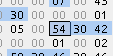
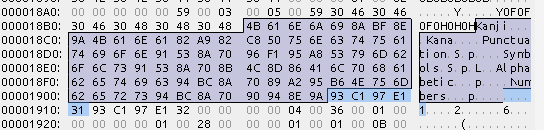
青い部分が文字セット名
そして2つ目の「特例2」であれば、オフセットが0x59で89byte
よって、Kanjiから89byte進めた先に名前がある
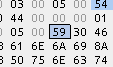
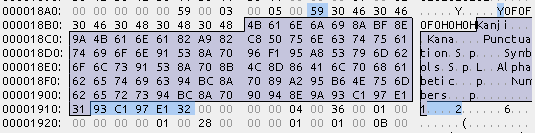
Shift-JIS表示できなくてゴメン;;
nameチャンク

ヘッダー部分
- tag: 4byte (name)
- skip: 4byte
- offset: 4byte (0x1917)
- length: 4byte (0x98)
ファイル先頭から後の分
この例の場合、ファイル先頭から6423byte進めたあとの152byte分がnameチャンクとなる
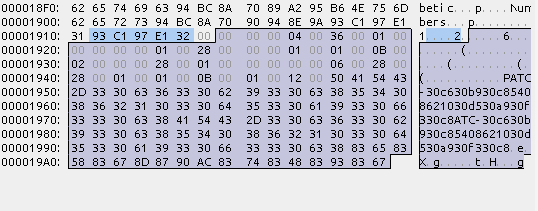
この部分
ATC-で始まる部分には、保存した合成フォントのプリセット名がUnicode表記とShift-JIS表記でそれぞれ書いてある。
また、それぞれのバイト数は、その直前に書いてある。
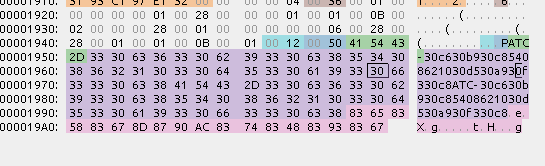
<Unicodeバイト数><Shift-JISバイト数>ATC-<Unicodeプリセット名><Shift-JISプリセット名>
のような型になっている。
また、その後ろにある部分については、ある時と無い時があるようだ。
(まだ判明していない)