目次
- 本記事の最終目標データ
- 実施手続一覧
- 実施手順
- 結論
- 感想
1. 本記事の最終目標
大量の文章データから有益な情報を抽出することをテキストマイニングと呼びますが、本記事の最終目標はPythonによる自然言語処理を活用し、とあるアプリゲームのレビューコメントをテキストマイニングすることで有益な情報、具体的には潜在的なユーザーのニーズやアプリの改善点等を抽出し、アプリゲーム提供会社の意思決定に役立つ情報を取得することとします。
2. 実施手続一覧
①スクレイピングを実施し、元データを作成する
②データの前処理
③レビューコメントの頻出単語に関するグラフの作成する
④コサイン類似度を用いて賛成数(グッド数)が一番多いコメントと類似しているコメントを集計する
3. 実施手順
①スクレイピングを実施し、元データを作成する。
1.データ(レビューコメント)の収集場所について
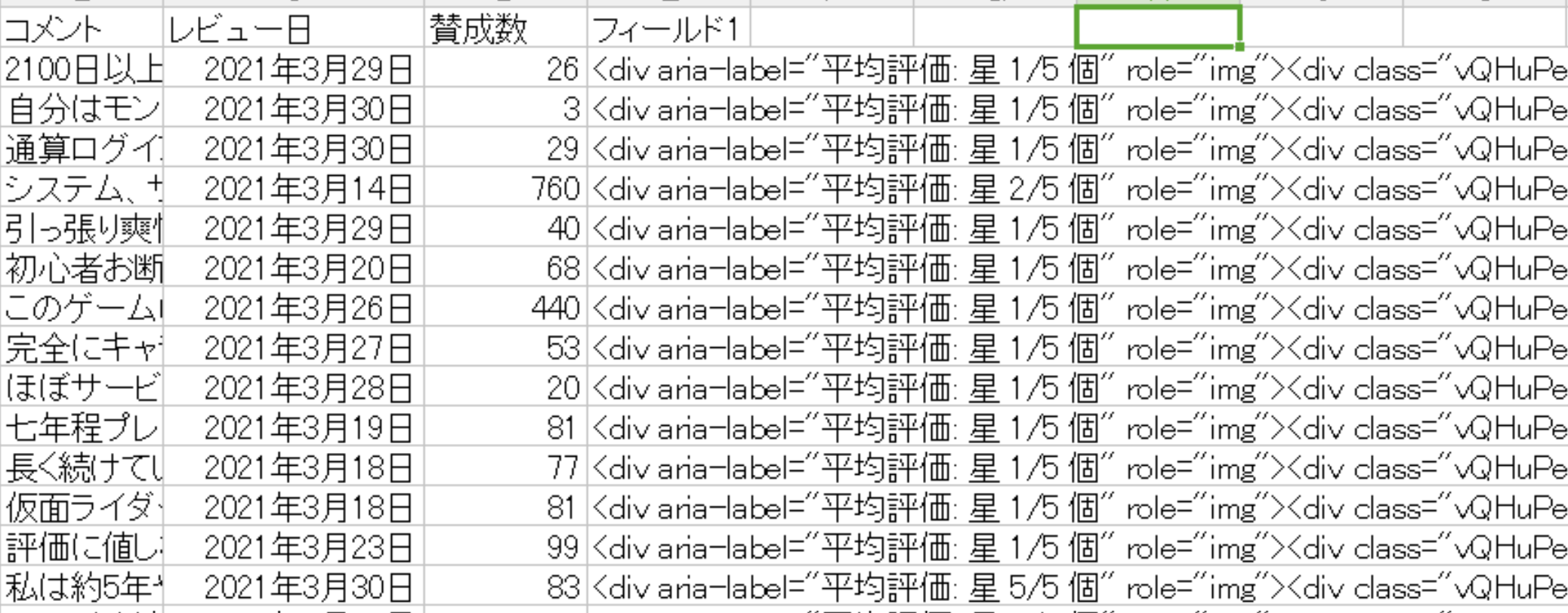
今回、元データを作成するに当たりデータを収集する場所としてはgoogle playストアを選びました。理由としては投稿コメントに加えて、そのコメントに対する賛成数(goodマーク数)及び星の数が収集でき、分析に有用だと判断したためです。

2.スクレイピングの方法について
スクレイピングの実施方法についてはBeautiful Soupを用いて自分で試行錯誤しながら実施しようと思いましたが、今回の最終目標的に分析の方に力を入れたかったためスクレイピングツールという文明の利器に頼ることにしました(`・ω・´)。
下記が今回使用したスクレイピングツールです。
■ScrapeStorm
無課金の場合、一日に収集できるデータやエクスポートできる数(1日100行まで)に制限があるものの、操作が分かりやすく簡単にスクレイピングを実施してくれました。
今回はこれによって収集した約200件のコメントデータを使ってテキストマイニングを実施していきます。
■スクレイピングの実施結果の一部抜粋(抽出期間は2021年2月~3月)
②データの前処理
1.使用ライブラリ一覧
Google Colaboratoryで下記をコピペして実行してもらえればColaboratory上でもMeCab等が使えます。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
import MeCab
!pip install japanize-matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
import numpy as np
from collections import defaultdict
!pip install janome
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import TfidfVectorizer
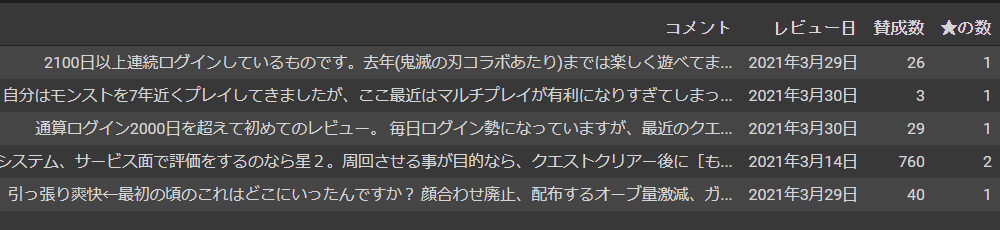
2.元データの加工
読み込んだデータだと星の数(フィールド1列)が情報として使いにくいので整形します。
df = pd.read_csv("Google Play のアプリ-ScrapeStorm.csv")
evaluation = []
for eva in df["フィールド1"]:
evaluation.append(eva[25])
df["★の数"] = evaluation
df = df.drop(columns="フィールド1")
フィールド1列の整形が完了しました。
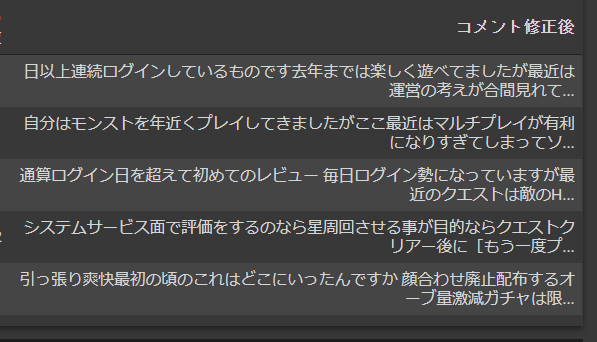
3.正規表現により不要な記号等の削除
・正規表現を用いて不要な数字・記号の削除
・()の中のコメントは補足的なコメントだったので不要と判断し削除
・その他分析の上で不要な記号を削除
df["コメント修正後"] = df["コメント"].str.replace("\(.+?\)|\(.+?\)|\d|[…★←!●...??。、,☆○�👍]+","",regex=True)
実行結果は以下の通り。まだ少し余計な記号([]とか)が入っていますがだいぶスッキリしましたね。
4.形態素解析の実施 & 頻出単語の集計
parses = []
m = MeCab.Tagger()
for comment in df["コメント修正後"]:
parses.append(m.parse(comment)[:-5])
results = []
for parse in parses:
parts = parse.split("\n")
for part in parts:
part = part.split(",")
results.append(part)
dic = []
for result in results:
# 表層形、品詞1の抽出
surface,hinshi1 = result[0].split("\t")
# 品詞2の抽出
hinshi2 = result[1]
# 基本形(又は原形)の抽出
base = result[-3]
dic.append(dict(表層形=surface,品詞1=hinshi1,品詞2=hinshi2,基本形=base))
dic変数の中身は下記のとおりです。自然言語処理っぽくなってきましたね。

5.分析に使えそうにない助詞と助動詞以外をdefaultdictを使って集計
コード上にも記載していますが1文字だけの頻出単語を集計しても分かりづらかったので
if文を使って2文字以上の単語のみを集計し、降順へ並び替えています。
count_dic = defaultdict(int)
# 単語の集計
for i in dic:
# 1文字だけだと集計しても分かりにくいので2文字以上を集計する
if len(i["基本形"]) >= 2:
if i["品詞1"] != "助詞" or i["品詞1"] != "助動詞":
count_dic[i["基本形"]] += 1
# 降順に並び替え
sort_count_dic = sorted(count_dic.items(),key=lambda x : x[1],reverse=True)
実行結果はこんな感じ。する・です・ます等の分析に使えなさそうな単語が入ってますが一旦このまま作業を進めましょう。

6.単語と数字に分割
グラフのx軸、y軸を作成するために上記で作成したcount_dicを単語と数字に分割します。
mozi = [i[0] for i in sort_count_dic]
num = [i[1] for i in sort_count_dic]
上記の変数をそれぞれ10件ずつ出力した結果は以下のとおりです。さて、前処理は一旦ここまでとなりますので、次はいよいよグラフの作成に入ります。

③-1 レビューコメントの頻出単語に関するグラフの作成
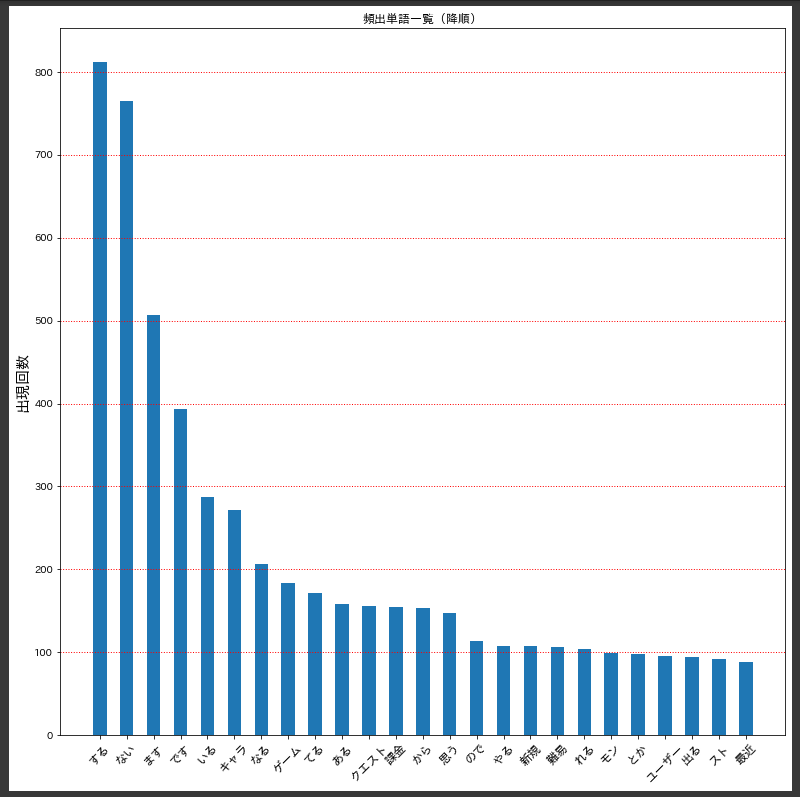
頻出単語の上位25件を使って棒グラフを作成します。デフォルトではx軸が見えにくかったため、plt.xticksの引数にrotationを入れて軸の文字を回転させました。
plt.figure(figsize=(14,14))
plt.bar(x=mozi[:25],height=num[:25],width=0.5)
plt.grid(linestyle='dotted', linewidth=1,axis='y',color="r")
plt.xticks(fontsize=12,rotation=45)
plt.title("頻出単語一覧(降順)")
plt.ylabel("出現回数",fontsize=15)
plt.show()
出力結果は下記のとおりです。降順に並び替えた時から何となく想像していた方もいるかも知れませんが、『です・ます』などの文章中に出現する可能性が非常に高い単語が上位を占めているのでイマイチなグラフとなっていますね。
分析に役立つグラフを作成するために、次は名詞のみの単語で集計したグラフを作成してみましょう。
③-2 レビューコメントの頻出単語に関するグラフの作成(名詞のみ)
dicに集めた単語の集計を行う時点からコードを変更していきます。
③-1との変更点は、まず『5.分析に使えそうにない助詞と助動詞以外をdefaultdictを使って集計』で作成したcount_dicのif文のところですね。
次に、スクレイピングで抽出したコメントが長すぎたために、元データの中のコメントが途中で切れて『…全文を表示』という言葉になっていました。そのため、『全文』、『表示』という単語が頻出単語に含まれる結果となってしまったためif文を追加して除外しています。なお、コード内の["全文","表示"]の中に外したい単語を入力することで追加で単語を除外できるので、他に除外したい単語があれば[]の中に入力してください。
最後の変更点として、グラフをx軸を上位25件ではなく上位30件へ変更。さらに、x軸を増やした結果、x軸の文字が見にくくなったためrotationを75に変更しています。
# 集計を名詞のみに変更
count_dic_meishi = defaultdict(int)
for i in dic:
if len(i["基本形"]) >= 2:
if i["品詞1"] == "名詞":
# 『全文』と『表示』は分析に不要なため除外する。
if i["基本形"] not in ["全文","表示"]:
count_dic_meishi[i["基本形"]] += 1
sort_count_dic_meishi = sorted(count_dic_meishi.items(),key=lambda x : x[1],reverse=True)
mozi_meishi = [i[0] for i in sort_count_dic_meishi]
num_meishi = [i[1] for i in sort_count_dic_meishi]
# 名詞のみの頻出単語をグラフ化
plt.figure(figsize=(14,14))
plt.bar(x=mozi_meishi[:30],height=num_meishi[:30],width=0.5)
plt.grid(linestyle='dotted', linewidth=1,axis='y',color="r")
plt.xticks(fontsize=12,rotation=75)
plt.title("頻出単語一覧(降順)")
plt.ylabel("出現回数",fontsize=15)
plt.show()
結果は以下の通り。モンストを実際にやっている人なら馴染み深い単語が集計される結果となりましたね。
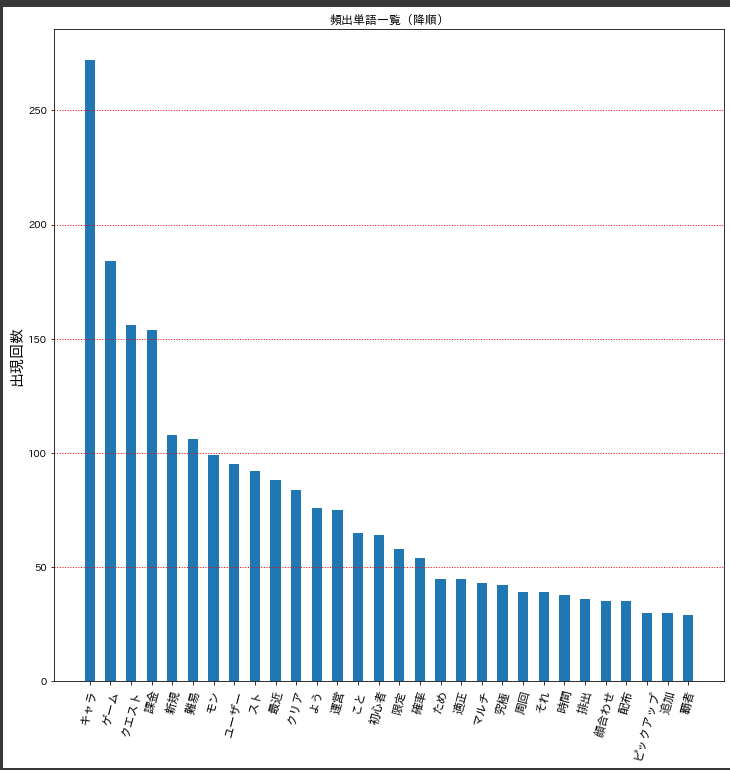
■グラフから読み取れるモンストの現状
①『キャラ・課金・難易・クリア・限定』から分かること。
モンストに限った話ではないですが、アプリゲームでは過去のガチャキャラよりどんどん強いキャラを出していかなければ皆がガチャを回してくれません(最近のキャラが過去のキャラより弱いならガチャなんて引かずに過去キャラ使えばええやんという話になってしまいますからね。)
つまり有名な大人気漫画であるワンピースやドラゴンボールに出てくる敵キャラがどんどんインフレしていくのに合わせて主人公側がどんどん強くなっていきパワーインフレが発生してしまうように、アプリゲームにおいても強い敵キャラを倒す(いわゆる高難易度クエストって奴ですね。)ために強いガチャキャラを作り続けていかなければならないんですね。
アプリゲームのパワーインフレを加速させた有名な事例としては、某パズルゲームの曲芸師事件が結構有名だと思います。
さて、では2021年3時点で7周年も続いているモンストの状況はというと……はい、残念ながらパワーインフレが顕著に目立つようになってしまっています。
つまり、課金すればするほど手に入りやすくなる(なお必ず出るわけでは無い。)ガチャキャラが強くなりすぎた結果、『課金して手に入れることができるガチャ限定キャラじゃなければ高難易度のクエストをクリアすることができないゲーム』、いわゆるキャラゲーと呼ばれる状態になっていることが頻出単語から読み取れますね。
②『新規・ユーザー・初心者・適正』から分かること。
こちらは上記のキャラゲーと深く関係しており、初心者(新規)ユーザーにとって非常にハードルの高いゲームになってしまっているということが頻出単語から読み取れます。
初心者(新規)ユーザーにとって非常にハードルの高いゲームがいったいどういうものなのかをざっくりと説明すると、
①新規のユーザーがゲームを始める
↓
②新規なので当然強いガチャキャラを持っていない
↓
③簡単なクエストはクリアできるが高難易度クエストはパワーインフレによりその高難易度クエストに特化したガチャキャラ(いわゆる適正キャラ)じゃないとクリアできないものが多いことに気づき絶望する。
↓
④じゃあ無課金でも手に入れることができる強いキャラを手に入れればええやんと希望を持つ。
↓
⑤しかしそもそも強い無課金キャラというのは強いガチャキャラによってクリアできるクエストからじゃないと入手できないことに気づき再度絶望する。
↓
⑥ \(^o^)/オワタ
っていう流れですね。もちろん簡単に入手できる強い無課金キャラもいますし他のユーザーから強いキャラを借りることで自分が弱いままでも何とかなるケースもあります。また、ガチャを回すためのアイテムは定期的にもらえるので時間さえかければ強くなることも可能です。
……まぁその時間をかけている間に他の面白そうなゲームに浮気されちゃうんですけどね。
他にも読み取れることは沢山ありますが、一旦頻出単語グラフに関することはここまでにして、次はコサイン類似度を用いて賛成数(グッド)数が多かったコメントに類似するコメントを確認してみましょう。
④コサイン類似度を用いて賛成数(グッド数)が一番多いコメントと類似しているコメントを集計する
1.元データの加工(ここまではデータの前処理で行った処理と同様)
df = pd.read_csv("Google Play のアプリ-ScrapeStorm.csv")
evaluation = []
for eva in df["フィールド1"]:
evaluation.append(eva[25])
df["★の数"] = evaluation
df = df.drop(columns="フィールド1")
df["コメント修正後"] = df["コメント"].str.replace("\(.+?\)|\(.+?\)|\d|[…★←!●...??。、,☆○�👍]+","",regex=True)
2.janomeを使って文章中の単語を表層形ごとに空白で分割
ここではMeCabに変わってjanomeを使用しています。MeCabでも特に問題ありません。
t = Tokenizer()
wakati = []
for comment in df["コメント修正後"]:
tmp1 = []
tmp2 = []
for token in t.tokenize(comment):
tmp1.append(token.surface)
tmp2 = ' '.join(tmp1)
wakati.append(tmp2)
wakati
wakati変数の中身はこんな感じに。きれいに表層形ごとに分けられてますね。

3.TF-IDFを用いたベクトル変換
先程表層形ごとに分割した文章をTF-IDFによって数字に変換します。
TF-IDFの詳細については割愛しますが、ざっくり説明すると複数の文章中に出てくる可能性が高い頻出単語(私・です・ます等)については重要性が低く、逆に複数の文章中には余り出ないが個々の文章の中では多く出てくる単語(ログイン・オーブ等)については重要性が高いされ、それを数値化したもの……だと思ってもらえれば大丈夫ですかね。
つまり、TF-IDFによって計算された値が大きい場合、その数値化された単語はその文章を特徴づける重要な(希少性が高い)単語であるという意味になり、逆に値が小さい場合にはその単語はその文章の特徴をそこまで表せない(希少性が低い)単語であるという意味になります。
# リスト形式からNumPy配列へ変換(arrayのほうが計算速度が速いため)
wakati_array = np.array(wakati)
# ベクトル表現化を行う変換器を生成
tfidf_wakati = TfidfVectorizer(use_idf=True)
# 単語をベクトル表現に変換
wakati_tfidf_vecs = tfidf_wakati.fit_transform(wakati_array)
# NumPy配列⇒リスト形式に戻す。
wakati_tfidf_array = wakati_tfidf_vecs.toarray()
# 結果を見やすくするためにDF形式にします。
tfidf_df = pd.DataFrame(wakati_tfidf_array, columns=tfidf_wakati.get_feature_names())
tfidf_df.head()
tfidf_dfの行が何番目の文章なのかを、列は表層形ごとに分割された単語となっています。『mixi』や『twitter』等の単語は全文章中の単語の中でも希少性が高いからか値が大きくなっていますね。
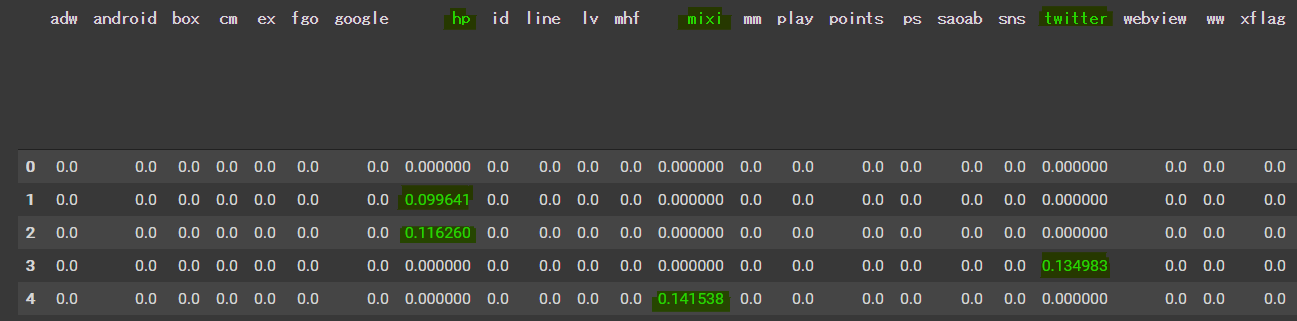
逆によくみかける単語である『〇〇ない』という単語は希少性が低いからか値が小さくなっています。

4.比較元となる賛成数が多い文章の行を抽出
元データが更新されたとしてもその都度賛成数が一番多いコメントを特定してくれるようなコードにしています。しかし今回のような処理は元データから直接取りに行ったほうが早いですね。
# コメントの中で賛成数が一番高いものを特定
good = max(df["賛成数"])
# 賛成数が一番高い行の確認+indexの抽出
max_text = df[df["賛成数"] == good]
target_text_index = max_text.index
# tf-idf_dfから比較元の行を抽出
target_text = tfidf_df.iloc[target_text_index]
target_text
max_text変数とtarget_text変数に格納されたのは17行目のコメントになりました。
賛成数が762もあることから、多くのユーザーがこのコメントに共感していることが分かります。
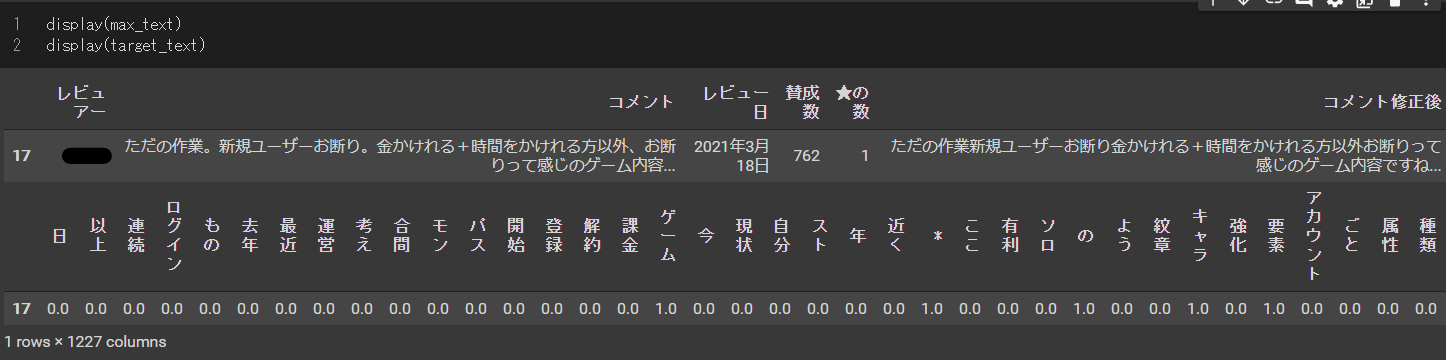
5.コサイン類似度の計算
numpyを使ってコサイン類似度を計算します。コサイン類似度について簡潔に説明すると、コサイン類似度は-1から1のまでの値を取り、数値が1に近いほどそれは比較元に近いような意味を持つコメントであること表し、逆に-1に近いほど比較元から遠い意味を持つコメントであることを表します。数式の意味は分からなくてもしっかり計算してくれるので、計算結果の意味さえわかっていれば問題ないです。
cos_sim = []
for i in range(len(tfidf_df)):
cos_text = tfidf_df.iloc[i]
cos = np.dot(target_text, cos_text) / (np.linalg.norm(target_text) * np.linalg.norm(cos_text))
cos_sim.append(cos)
tfidf_df["cos_sim"] = cos_sim
# float型に変換
tfidf_df["cos_sim"] = tfidf_df["cos_sim"].astype(float)
# 降順に並び替えて1に近いコメントを確認。
tfidf_df.sort_values("cos_sim",ascending=False)["cos_sim"].head(10)
tfidf_dfのcos_sim列を降順に並べるとこんな結果となりました。一番上の17行目は比較元と比較対象が一緒なので当然1になりますが、2番めの29行目を見ると0.32と一気に小さな値になりましたね。
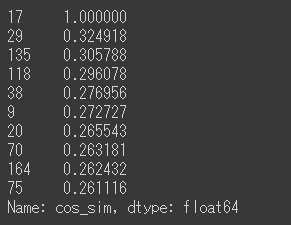
では、最後に上位10件のindexを使って元データのコメントをまとめましょう。
6.上位10件の類似コメントの確認
# 上位10件のindexを取得
target_index = tfidf_df.sort_values("cos_sim",ascending=False).head(10).index
# 元データから上位10件のコメント、賛成数、星の数を取得
target_comment = []
target_good = []
target_star_num = []
for index in target_index:
target_comment.append(df["コメント"].iloc[index])
target_good.append(df["賛成数"].iloc[index])
target_star_num.append(df["★の数"].iloc[index])
# DF型に変更
target_comment_df = pd.DataFrame({"コメント":target_comment,"賛成数":target_good,"星の数":target_star_num})
# target_comment_df
# csv化
target_comment_df.to_csv("賛成数が多いコメントの類似コメント一覧.csv",index=False)
さて、CSVを開いてコメントを確認した結果、下記画像のようになりました。上位10件のコメントの中身を見てみると、主に『新規ユーザーにとって厳しいゲームになっているぞ』という意味合いが強いコメントが集計されていますね。
特に1番目と2番めのコメントを比較すると、『新規ユーザーにとって厳しい』ということに加えて『ガチャの天井機能が無い』という点が共通しており、賛成数762を獲得したコメントに類似したコメントが集められていることがよく分かる結果となりました。

④結論
今までの分析で分かったことをまとめると、現状(2021年3月現在)のモンストは
・キャラゲーが進み課金して強いキャラを入手しなければクリアできないクエストが多くなっている。
・キャラゲーが進んだ結果、初心者に優しくないゲームになっている。
・ガチャに天井機能が無い。
というユーザーの声が多いことが分かりました。
モンストは有名どころ(鬼滅の刃や銀魂、仮面ライダー等)とコラボする機会が多く、そのおかげで新規勢の獲得は狙いやすいものの、キャラゲーが進んだ影響で新規勢が定着しないという問題点があるようですね。
現状は昔から遊んでいるプレイヤーの課金によって支えられているものの、時間が経てば立つほど既存ユーザーがキャラゲーに追いつけなくなったり、別の新しいゲーム(最近でいうとウマ娘や原神でしょうか?)に目移りしてしまうため、今回の分析から導き出せるモンストのこれからの課題としては、
①いかに新規勢を定着させるか
②獲得した新規勢を課金者へと引きずり込むか
③既存ユーザーが離れていかない工夫をしていくか
の3つだと考えられます。まぁ②について簡単に思いつくものとしてはユーザーの声というか注目度が高い天井機能を実装することでしょうか?
実装するとしてもどのような手段(完全無課金でも天井可能なのか、また天井するまでの課金額は最低いくらか等)でユーザーに天井機能を明け渡していくのか、今後のモンストに期待したいところですね。
⑤感想
2021年の1月からプログラミングについて勉強し始めて約3ヶ月が経過しましたが、Pythonは今回実施した自然言語処理等のデータ分析や業務の効率化・スクレイピング等、汎用的でやれることが多くて楽しいですね。
特に今回、楽しいというか嬉しいと感じたのは、一回コードを頑張ってかけさえすれば、後は入力するデータの形式が同じであれば瞬時に別のデータであっても分析できるところでしょうか。今回のデータとしてはモンストのレビューコメントを採用しましたが、例えば今流行りのウマ娘であったり原神のデータであっても、同じ形式でスクレイピングを実施して最初に読み込むデータを変えればあっという間に同じような分析結果が出力されることに感動しました。
今回はスクレイピングツールの都合上、200件程度のコメントしか分析できませんでしたが、もっと勉強してより多くのデータを使った分析や深層学習にも挑戦していきたいですね。
ではでは、最後までご閲覧いただきありがとうございました。