どうも、掘る前のじゃがいもです
今回はQiitaの初投稿ということで、数日前に開発したツールの話をします
ざっくり言えばタイトルの通り、SNSの投稿を感情分析してみようというものです
公開はこちらでしました
開発のきっかけ
普段はMisskeyという分散型SNSを使っていて、すしすき-というサーバーによくいるのですが、そのときくちばし(サーバー管理者)のこのような投稿を目にしました
このアイディアに影響を受け、開発を行うことにしました
くちばしありがとう
設計
環境とかは
- Pythonで開発する
- Windows上で動く
- GUIにはTkinterを使う
目的は
- SNSの投稿を感情分析する
- 分析結果をメンタルヘルスに役立てる
ということです
それぞれの目的ごとに細かく見ていきます
SNSの投稿を感情分析する
まずSNSの投稿を持ってくる必要があります
前提として、対象のSNSはMisskey、分析対象は利用者本人とします
投稿は
- JSON形式でエクスポートされたノートを読み込む
- Misskey APIで動的にノートを取得する
この2つに対応させます(Misskeyにはノート(=投稿)をエクスポートしてダウンロードできる機能があります)
感情分析についてはこの時点ではブラックボックス的な関数として詳細には設計しないことにしました(ここら辺はあまり詳しくないので)
投稿からネガポジ判定するということだけは決めています(WRIMEというデータセットを使えばもっと詳細な感情を分析できるのですが、ライセンスが研究目的だけ許可なので今回は断念しました、データセットは貴重...)
ただ、ネガポジだけだと少し物足りないので、ルールベース的な思考でより詳細な判定を補助的に行うようにしました
分析結果をメンタルヘルスに役立てる
メンタルヘルスには詳しくないので、分析結果の整理だけを行います
グラフ化して、その先そのデータをどう役立てるかは利用者次第です(それ以上をしようとなると、この部分にもAIを持ち込む必要が出てくると思います...)
分析結果は
- ノート全体に対するネガポジの割合
- 時間帯ごとにまとめたノート群に対するそれぞれのネガポジの割合
- 曜日ごとでも1と同じことを行う
- 日ごとでまとめてネガポジの時系列変化を見る
- ネガティブなノートの中での詳細な感情の割合
でデータを整理してグラフ化します
クラス図
最近UMLを勉強したので練習がてらクラス図で設計図を書きます
Tkinterを使う性質上ウィジェットを保存したりボタン用の処理を用意したりしています

(PlantUMLを使ったのは初めてだけどこれは便利そう...開発してたときはDraw.ioを使ってた)
分析クラスと画面表示クラスについてはフローチャートでより細かい設計を行ってますが、大きくて画像そのまま貼っても拡大しないと見えないのでGitHubに上げたリンクを貼っておきます
実装
コード全体はこちらにもあります
画面表示クラス(mainUi)
mainUI.pyとしてメイン画面を実装します
設計上の名前はコメントに書いておきました
コード(長いです)
import tkinter as tk
from tkinter import messagebox
from tkinter import filedialog
import requests
import json
import analizer
import subUI
import os
import pathlib
import random
import threading
TOKENFILE="./token.txt"
SETTINGFILE="./setting.json"
class Ui:
"""
設計名:画面表示クラス
_token : APIトークン str
_noteFile : ノートファイル str
_manualUi : 説明画面 subUI.ManualUi
_resultUi : 分析結果画面 subUI.ResultUi
_analizer : 分析 analizer.Analizer
_window : 画面 tkinter.Tk
_widget : ウィジェット dict
_isAnalyzing : 分析中 bool
"""
def __init__(self):
print("program start")
#ウィンドウ・ウィジェットの作成
self._window = tk.Tk()
self._window.title("Misskey Analizer for Mental Health")
self._window.geometry("800x600")
self._window.resizable(False,False)
self._window.configure(bg="#ffffff")
self._widget = {
"manualButton" : tk.Button(text="使い方",command=self.manualButtonFunc,width=15,height=1,font=('Times New Roman',12)),
"tokenLabel" : tk.Label(text="APIトークンの入力",bg="#ffffff",font=('Times New Roman',12)),
"tokenEntry" : tk.Entry(show="*"),
"tokenButton" : tk.Button(text="確定",command=self.tokenButtonFunc,width=15,height=1,font=('Times New Roman',12)),
"fileButton" : tk.Button(text="ファイル入力",command=self.fileButtonFunc,width=15,height=1,font=('Times New Roman',12)),
"rangeEntry" : tk.Entry(font=('Times New Roman',12)),
"rangeLabel" : tk.Label(text="日間を分析",bg="#ffffff",font=('Times New Roman',12)),
"analyzeButton" : tk.Button(text="分析開始",command=self.analyzeButtonFunc,width=15,height=1,font=('Times New Roman',12)),
"resultButton" : tk.Button(text="分析結果",command=self.resultButtonFunc,width=15,height=1,font=('Times New Roman',12))
}
self._widget["rangeEntry"].insert(0, "42")
#インスタンスの作成
self._analizer = analizer.Analizer()
self._manualUi = subUI.ManualUi(self._window,self)
self._resultUi = subUI.ResultUi(self._window,self)
#トークンの読み込み
print("reading token now...")
self._token = self._tokenRead()
if(self._token!=""):
print("token OK")
self._widget["tokenEntry"].insert(0,self._token)
else:
print("no token")
#フィールドの初期化
self._isAnalyzing = False
self._noteFile = ""
def show(self) -> None:
"""
設計名: 表示
ウィジェットを配置する
"""
self._widget["manualButton"].place(x=10,y=10)
self._widget["tokenLabel"].place(x=10,y=70)
self._widget["tokenEntry"].place(x=10,y=100,width=480)
self._widget["tokenButton"].place(x=500,y=95)
self._widget["fileButton"].place(x=10,y=160)
self._widget["rangeEntry"].place(x=10,y=220,width=90)
self._widget["rangeLabel"].place(x=110,y=220)
self._widget["analyzeButton"].place(x=10,y=270)
self._widget["resultButton"].place(x=10,y=310)
def run(self) -> None:
"""
設計名:実行
"""
print("running GUI")
self._window.mainloop()
def _clearUi(self) -> None:
"""
設計名: 表示削除
ウィジェットの配置を消す(ウィジェット自体は消さない)
"""
for k in self._widget.keys():
self._widget[k].place_forget()
def _tokenSave(self,token: str) -> None:
"""
設計名:トークン保存
トークンを外部ファイルに保存する
"""
if(self._tokenCheck(token)):
self._token = token
tokenFile = open(TOKENFILE,"w")
tokenFile.write(token)
tokenFile.close()
else:
messagebox.showerror("エラー","APIトークンの認証に失敗しました\n以下を確認してください\n・トークンに誤字脱字がないか\n・トークンに権限を設定したか\n・設定されたサーバーURLが正しいか\n・ネットワーク接続がされているか")
def _tokenRead(self) -> str:
"""
設計名:トークン読み込み
外部ファイルからトークンを読み込んで返す
読み込めない場合は空の文字列を返す
"""
#ファイル読み込み
fileText = ""
try:
tokenFile = open(TOKENFILE,"r")
fileText = tokenFile.read()
tokenFile.close()
except:
return ""
#トークン確認
if(self._tokenCheck(fileText)):
return fileText
else:
messagebox.showerror("エラー","保存されたAPIトークンの確認に失敗しました")
return ""
def _tokenCheck(self,token: str) -> bool:
"""
設計名:トークン確認
トークンの正当性を確認し、正しいかを返す
"""
print("checking token...")
#形式のチェック
if(len(token)<1 or len(token)>100):
return False
for c in token:
if( not (ord("a")<=ord(c)<=ord("z") or ord("A")<=ord(c)<=ord("Z") or ord("0")<=ord(c)<=ord("9"))):
return False
#設定の読み込み
setting = {}
try:
settingFile = open(SETTINGFILE,"r",encoding="utf-8")
setting = json.load(settingFile)
settingFile.close()
except:
try:
settingFile = open(SETTINGFILE,"r",encoding="cp932")
setting = json.load(settingFile)
settingFile.close()
except:
setting["server"] = "https://sushi.ski"
if("server" not in setting.keys()):
setting["server"] = "https://sushi.ski"
print(f"set server as {setting['server']}")
#接続の確認
print("sending API(i)...")
api_url = f"{setting['server']}/api/i"
param = json.dumps({"i": token})
try:
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
except:
return False
print("API error")
print("token check OK")
return True
def _fileCheck(self,filePath: str) -> bool:
"""
設計名:ファイル確認
ファイルが読み込めるか・形式が正しいか確認し、正しいかを返す
"""
#存在・拡張子確認
if(not os.path.isfile(filePath) or os.path.splitext(filePath)[1]!=".json"):
messagebox.showerror("エラー","パスの指定が間違っています")
return False
notes = []
#開けるか
try:
print("opening note file as utf-8...")
noteFile = open(filePath,"r",encoding="utf-8")
print("file open OK")
notes = json.load(noteFile)
print("file read OK")
noteFile.close()
except:
try:
print("open failure\nopening note file as cp932...")
noteFile = open(filePath,"r",encoding="cp932")
print("file open OK")
notes = json.load(noteFile)
print("file read OK")
noteFile.close()
except:
print("file error")
messagebox.showerror("エラー","ファイルが開けません\n以下を確認してください\n・選択したファイルが正しいか\n・UTF-8もしくはSHIFT-JISでエンコードされているか")
return False
#必要なデータがあるか
if("text" not in notes[random.randint(0,len(notes)-1)].keys() or "createdAt" not in notes[random.randint(0,len(notes)-1)].keys()):
messagebox.showerror("エラー","データの形式が異なります")
return False
return True
def _analizeWait(self):
"""
アナライザーが重すぎて固まるので、別スレッドで実行させるための関数
"""
if(not self._analizer.analize()):
self._isAnalyzing = False
messagebox.showerror("エラー","分析中にエラーが起きました")
self._widget["analyzeButton"]["text"]="分析開始"
return False
self._widget["analyzeButton"]["text"]="分析開始"
self._isAnalyzing = False
def _analyzeByAPI(self,token: str) -> bool:
"""
設計名:読み込んで分析
ノートをAPIで読んで分析させる
"""
#フラグのセット(回収を忘れずに)
self._isAnalyzing = True
self._widget["analyzeButton"]["text"]="分析中..."
#分析日数の取得・設定
rangeText = self._widget["rangeEntry"].get()
if(not all(map(lambda x:ord("0")<=ord(x)<=ord("9"),rangeText))):
self._isAnalyzing = False
messagebox.showerror("エラー","分析日数を整数にしてください")
self._widget["analyzeButton"]["text"]="分析開始"
return False
rangeInt = int(rangeText)
if(rangeInt<1):
self._isAnalyzing = False
messagebox.showerror("エラー","分析日数が0以下です")
self._widget["analyzeButton"]["text"]="分析開始"
return False
self._analizer.rangeSet(rangeInt)
#ノート呼び出し
if(not self._analizer.callNote(token)):
self._isAnalyzing = False
messagebox.showerror("エラー","APIの呼び出し中にエラーが起きました")
self._widget["analyzeButton"]["text"]="分析開始"
return False
#分析
thread1 = threading.Thread(target=self._analizeWait)
thread1.start()
return True
def _analyzeByFile(self,file: str) -> bool:
"""
設計名:分析
ノートをファイルから読んで分析させる
"""
#フラグのセット(回収を忘れずに)
self._isAnalyzing = True
self._widget["analyzeButton"]["text"]="分析中..."
#分析日数の取得・設定
rangeText = self._widget["rangeEntry"].get()
if(not all(map(lambda x:ord("0")<=ord(x)<=ord("9"),rangeText))):
self._isAnalyzing = False
messagebox.showerror("エラー","分析日数を整数にしてください")
self._widget["analyzeButton"]["text"]="分析開始"
return False
rangeInt = int(rangeText)
if(rangeInt<1):
self._isAnalyzing = False
messagebox.showerror("エラー","分析日数が0以下です")
self._widget["analyzeButton"]["text"]="分析開始"
return False
self._analizer.rangeSet(rangeInt)
#ノート読み込み
if(not self._analizer.readNote(file)):
self._isAnalyzing = False
messagebox.showerror("エラー","ノートファイルの読み込み中にエラーが起きました")
self._widget["analyzeButton"]["text"]="分析開始"
return False
#分析
thread1 = threading.Thread(target=self._analizeWait)
thread1.start()
return True
def resultButtonFunc(self):
"""
設計名:分析結果ボタン処理
"""
#分析中・分析前・分析失敗は表示しない
if(self._isAnalyzing):
messagebox.showerror("エラー","分析中です")
return
if(self._analizer.result=={}):
messagebox.showerror("エラー","先に分析をしてください")
return
if(self._analizer.result["status"]=="failure"):
messagebox.showerror("エラー","直前の分析が失敗しています")
return
#初期化・表示
self._resultUi.initialize()
self._resultUi.resultSet(self._analizer.result)
self._clearUi()
self._resultUi.show()
def tokenButtonFunc(self):
"""
設計名:トークン入力確定ボタン処理
"""
self._tokenSave(self._widget["tokenEntry"].get())
def manualButtonFunc(self):
"""
設計名:説明ボタン処理
"""
self._manualUi.initialize()
self._clearUi()
self._manualUi.show()
def analyzeButtonFunc(self):
"""
設計名:分析ボタン処理
"""
if(self._isAnalyzing):
return
if(self._token!=""):
self._analyzeByAPI(self._token)
return
if(self._noteFile!=""):
self._analyzeByFile(self._noteFile)
return
messagebox.showwarning("エラー","APIトークンかファイルを設定してください")
return
def fileButtonFunc(self):
"""
設計名:ファイル入力ボタン処理
"""
fileName = filedialog.askopenfilename(filetypes=[("","*.json")])
if(len(fileName)<1):
return
if(not self._fileCheck(fileName)):
return
self._noteFile = fileName
main=Ui()
main.show()
main.run()
(プライベート属性として名前の先頭にアンダーバーを1個書いてるのですが、これで合ってますかね?)
感情分析やデータの整理は分析クラスに行わせるのでここでは画面表示とファイル・APIトークンの受付などを行います
エラーはできるだけ例外処理してポップアップを出すようにしています
SETTINGFILEとしてsetting.jsonを指定しています
これのデフォルトは
{
"server" : "https://sushi.ski",
"negativeFilter" : {
"activate" : false,
"value" : {
"public" : 2.0,
"home" : 1.0,
"followers" : 0.0
},
"$comment" : [
"ネガティブでないノートをネガティブとして多く判定してしまう場合に使います",
"activateにtrueを書けば有効化されます(falseで無効化されます)",
"valueはノートの公開範囲毎に設定できます",
"valueの値が高いほど、ネガティブと判定されにくくなります",
"valueはおおよそ2±1程度にするとよいと思います",
"valueは正の値です(0以下は無効)",
"ネガティブにネタノートを拾いすぎる!(開発者の例)という人は特定の公開範囲の値を10.0とかにして拾わないようにしてもいいかもしれません"
]
},
"sampleSize" : 10,
"$comment" : [
"設定の変更後はソフトを再起動してください",
"sampleSizeは分析中に表示するサンプルのサイズを指定します"
]
}
$commentのところはコメントなので動作中には使いません
mainUI.py中では、APIトークンを確認するときにserver属性に設定された文字列を使います
トークン確認の部分のコード
def _tokenCheck(self,token: str) -> bool:
"""
設計名:トークン確認
トークンの正当性を確認し、正しいかを返す
"""
print("checking token...")
#形式のチェック
if(len(token)<1 or len(token)>100):
return False
for c in token:
if( not (ord("a")<=ord(c)<=ord("z") or ord("A")<=ord(c)<=ord("Z") or ord("0")<=ord(c)<=ord("9"))):
return False
#設定の読み込み
setting = {}
try:
settingFile = open(SETTINGFILE,"r",encoding="utf-8")
setting = json.load(settingFile)
settingFile.close()
except:
try:
settingFile = open(SETTINGFILE,"r",encoding="cp932")
setting = json.load(settingFile)
settingFile.close()
except:
setting["server"] = "https://sushi.ski"
if("server" not in setting.keys()):
setting["server"] = "https://sushi.ski"
print(f"set server as {setting['server']}")
#接続の確認
print("sending API(i)...")
api_url = f"{setting['server']}/api/i"
param = json.dumps({"i": token})
try:
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
except:
return False
print("API error")
print("token check OK")
return True
MisskeyAPIでは
Misskeyサーバー/api/i
に、jsonデータ
{
"i" : "APIトークン"
}
をPOSTすることによって、そのトークンの所有者の情報を取得することができます
これを使って、APIトークンが正しいことを確認します(必要な権限はアカウントの読み取りなので実際に投稿を取得しなくてもこれで十分)
APIの送信にはrequestsライブラリを使っています
MisskeyAPIの情報はサーバーごとに公開されています(それぞれのサーバーのMisskeyバージョンによって仕様が異なることがあります)
すしすき-の場合は https://sushi.ski/api-doc です
Misskeyのアップデートはサーバーごとに行うので、最近追加されたAPIを使うといった場合ではサーバーによっては動かないこともあります(今回使っているAPIはおそらくほとんど変わらないと思いますが)
また、エクスポートしたノートファイルの受付も行っているのでこの形式も書いておきます
エクスポートしたノートは、古い順に
{
"id":"ノートID",
"text":"投稿文",
"createdAt":"投稿を作成した時刻",
"fileIds":[],
"files":[],
"replyId":null,
"renoteId":null,
"poll":null,
"cw":"CW(投稿内容を隠すときの注釈文、なければnull)",
"visibility":"公開範囲",
"visibleUserIds":[],
"localOnly":false,
"reactionAcceptance":"nonSensitiveOnly"
}
というデータがリストになって入っています、これはAPIでノートを取得したときも似たような形になっています
今回使うのは、text,cwは投稿文なのでもちろん、分析にcreatedAtとvisibilityを使います
createdAtに関しては
"2023-07-23T00:13:05.032Z"
のように、ISO 8601のフォーマットで協定世界時が書いてあります
この形式は、タイムゾーンを考慮した時刻の表記形式です
上の例なら、協定世界時(どこか知らないけど)が2023年7月23日の0時13分5.032秒ということになります
これを
2023-07-23T00:13:05.032+09:00
とすれば、日本標準時で2023年7月23日の0時13分5.032秒ということになります
+09:00の部分がタイムゾーンで、9時0分ずれていることを示しています(これが日本標準時と協定世界時のずれです)
それでファイル確認の部分が
ファイル確認の部分のコード
def _fileCheck(self,filePath: str) -> bool:
"""
設計名:ファイル確認
ファイルが読み込めるか・形式が正しいか確認し、正しいかを返す
"""
#存在・拡張子確認
if(not os.path.isfile(filePath) or os.path.splitext(filePath)[1]!=".json"):
messagebox.showerror("エラー","パスの指定が間違っています")
return False
notes = []
#開けるか
try:
print("opening note file as utf-8...")
noteFile = open(filePath,"r",encoding="utf-8")
print("file open OK")
notes = json.load(noteFile)
print("file read OK")
noteFile.close()
except:
try:
print("open failure\nopening note file as cp932...")
noteFile = open(filePath,"r",encoding="cp932")
print("file open OK")
notes = json.load(noteFile)
print("file read OK")
noteFile.close()
except:
print("file error")
messagebox.showerror("エラー","ファイルが開けません\n以下を確認してください\n・選択したファイルが正しいか\n・UTF-8もしくはSHIFT-JISでエンコードされているか")
return False
#必要なデータがあるか
if("text" not in notes[random.randint(0,len(notes)-1)].keys() or "createdAt" not in notes[random.randint(0,len(notes)-1)].keys()):
messagebox.showerror("エラー","データの形式が異なります")
return False
return True
なんですが、textとcreatedAtしか確認してませんでしたね(設計ミス)
この記事書いてて気づきました
テスト後に、分析をTkinterのスレッドでそのまま行うとフリーズすることが分かった(分析にめちゃくちゃ時間がかかる)ので、_analizeWait関数を急遽追加してこれを別スレッドで起動し、そこで分析を行わせるようにしました(スレッド作成にはthreadingライブラリを使いました)
_analyzeByAPIと_analyzeByFileの
thread1 = threading.Thread(target=self._analizeWait)
thread1.start()
という部分で別スレッドを立てています、この時点では分析中のフラグは立てたままにしておき
def _analizeWait(self):
"""
アナライザーが重すぎて固まるので、別スレッドで実行させるための関数
"""
if(not self._analizer.analize()):
self._isAnalyzing = False
messagebox.showerror("エラー","分析中にエラーが起きました")
self._widget["analyzeButton"]["text"]="分析開始"
return False
self._widget["analyzeButton"]["text"]="分析開始"
self._isAnalyzing = False
のように_analizeWaitの終わりにフラグを回収します
分析クラス(analizer.py)
スペルミスで所々analizeになっちゃってます
コード(長いです)
import json
import requests
import re
import datetime
import pytz
import time
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import numpy as np
import torch
import gensim
from janome.tokenizer import Tokenizer
import copy
import random
BERTMODELPATH = "./model/bert"
WORD2VECMODELPATH = "./model/word2vec/model.vec"
SETTINGFILE="./setting.json"
class Analizer:
"""
設計名:分析クラス
_note : ノート list<dict>
result : 分析結果 dict
_emoji : 絵文字 dict
_removePattern : 削除パターン list<re.Pattern>
_dayRange : 日数 int
"""
def __init__(self):
self.result = {}
self._dayRange = 42
self._note = []
self._removePattern = [
re.compile(r"https?://[\w!\?/\+\-_~=;\.,\*&@#\$%\(\)'\[\]]+"),
re.compile(r"\*\*"),
re.compile(r"<[/\w]+>"),
re.compile(r"\$\[\S+(\s.*?)\]"),
re.compile(r"@[\w\.]+")
]
#設定の読み込み
self._setting = {}
try:
settingFile = open(SETTINGFILE,"r",encoding="utf-8")
self._setting = json.load(settingFile)
settingFile.close()
except:
try:
settingFile = open(SETTINGFILE,"r",encoding="cp932")
self._setting = json.load(settingFile)
settingFile.close()
except:
print("setting file open Failure")
self._setting["server"] = "https://sushi.ski"
self._setting["negativeFilter"] = {"activate":False}
self._setting["sampleSize"] = 10
if("server" not in self._setting.keys()):
self._setting["server"] = "https://sushi.ski"
if("negativeFilter" not in self._setting.keys()):
self._setting["negativeFilter"] = {"activate":False}
if("sampleSize" not in self._setting.keys()):
self._setting["sampleSize"] = 10
print(f"set server as {self._setting['server']}")
print(f"negative filter : {self._setting['negativeFilter']['activate']}")
#絵文字の取得
api_url = f"{self._setting['server']}/api/emojis"
param = json.dumps({})
response = []
try:
print("sending API(emojis)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
response = response.json()["emojis"]
except:
try:
print("sending API(emojis)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
response = response.json()["emojis"]
except:
print("reading emojis Failure")
response = []
#絵文字のデータ形式を整形
self._emoji = {}
for i in response:
if(len(i["aliases"])<=0):
continue
self._emoji[i["name"]] = i["aliases"][0]
if(self._setting["server"] in ["https://sushi.ski","https://misskey.io"]):
self._emoji["blank"] = ""
#感情分析用
print("reading model now...(please wait)")
self._device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self._tokenizer = AutoTokenizer.from_pretrained(BERTMODELPATH)
self._model = (AutoModelForSequenceClassification.from_pretrained(BERTMODELPATH).to(self._device))
self._w2vModel = gensim.models.word2vec.KeyedVectors.load_word2vec_format(WORD2VECMODELPATH)
self._janomeTokenizer = Tokenizer()
print("read model OK")
def rangeSet(self,day: int):
"""
設計名:分析範囲セット
"""
if(type(day)!=int):
return
if(day<=0):
return
self._dayRange = day
def callNote(self,token: str) -> bool:
"""
設計名:ノート呼び出し
APIでノートを呼んで保存する
成功したかどうかを返す
"""
self._note = []
#ユーザーIDの取得
api_url = f"{self._setting['server']}/api/i"
param = json.dumps({"i": token})
user_id = ""
try:
print("sending API(i)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
user_id = response.json()["id"]
except:
try:
print("sending API(i)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
user_id = response.json()["id"]
except:
print("API error(i)")
False
#ノートの取得
api_url="https://sushi.ski/api/users/notes"
nowDate = datetime.datetime.now(pytz.timezone("Asia/Tokyo"))
untilDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo"))
sinceDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo")) - datetime.timedelta(days=self._dayRange)
while True:
param = json.dumps({"i": token,"userId" : user_id,"withRenotes" : False,"limit" : 100 , "untilDate" : int(untilDate.timestamp())*1000 , "sinceDate" : int(sinceDate.timestamp())*1000})
response = {}
print(f"reading note from {int(sinceDate.timestamp())*1000} to {int(untilDate.timestamp())*1000}")
try:
print("sending API(users/notes)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
response = response.json()
except:
try:
print("sending API(users/notes)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
response = response.json()
except:
print("reading note Failure")
return False
noteCount = len(response)
print(f"read {noteCount}note")
if noteCount<=0:
break
self._note+=response
untilDate = datetime.datetime.fromisoformat(response[-1]["createdAt"].replace("Z","+00:00")) - datetime.timedelta(milliseconds=1)
if untilDate<sinceDate:
break
time.sleep(1)
#ノートの整形
for i in range(len(self._note)-1,-1,-1):
if(self._note[i]["text"]==None or self._note[i]["text"]==""):
del self._note[i]
continue
if(self._note[i]["cw"]!=None):
self._note[i]["text"]=self._note[i]["cw"]+"\n"+self._note[i]["text"]
self._note[i]["text"] = self._noteFormatter(self._note[i]["text"])
if(self._note[i]["text"]==None or self._note[i]["text"]==""):
del self._note[i]
return True
def readNote(self,filename: str) -> bool:
"""
設計名:ノート読み込み
ファイルからノートを読み込んで保存する
成功したかどうかを返す
"""
self._note = []
#ファイルを開ける
file = None
notes = []
try:
print("opening file as utf-8...")
file = open(filename,"r",encoding="utf-8")
print("open OK")
notes = json.load(file)
print("read OK")
file.close()
except:
try:
print("opening file as cp932...")
file = open(filename,"r",encoding="cp932")
print("open OK")
notes = json.load(file)
print("read OK")
file.close()
except:
print("file Error")
return False
#分析範囲内だけ取り出して保存
nowDate = datetime.datetime.now(pytz.timezone("Asia/Tokyo"))
untilDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo"))
sinceDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo")) - datetime.timedelta(days=self._dayRange)
print(f"read {len(notes)}note")
for i in notes:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00"))
if(not (untilDate>=createdDate>=sinceDate)):
continue
i["text"]=self._noteFormatter(i["text"])
if(i["cw"]!=None):
i["text"]=i["cw"]+"\n"+i["text"]
if(i["text"]==""):
continue
self._note.append(i)
print(f"found {len(self._note)}note in analizing range")
return True
def _noteFormatter(self,note: str) -> str:
"""
設計名:ノート整形
"""
if(note==None or note==""):
return ""
#削除パターンを削除
for pattern in self._removePattern:
searched = pattern.search(note)
while(searched!=None):
inner = ""
try:
inner = searched.group(1)
except:
inner = ""
note = note[:searched.span(0)[0]]+inner+note[searched.span(0)[1]:]
searched = pattern.search(note)
#絵文字とそれ以外をカウント
emojiPattern = re.compile(r":(\w+?):")
noEmoji = note
searched = emojiPattern.search(noEmoji)
while(searched!=None):
noEmoji = noEmoji[:searched.span(0)[0]]+noEmoji[searched.span(0)[1]:]
searched = emojiPattern.search(noEmoji)
noEmoji = noEmoji.replace(" ","")
noEmoji = noEmoji.replace("\n","")
emojiCount = len(emojiPattern.findall(note))
mojiCount = len(noEmoji)
if(mojiCount<=10 and emojiCount>=10 or mojiCount==0 and emojiCount>=4):
return ""
#絵文字をエイリアスに置き換え
searched = emojiPattern.search(note)
while(searched!=None):
alias = ""
if(searched.group(1) in self._emoji.keys() and self._emoji[searched.group(1)]!=""):
alias = "["+self._emoji[searched.group(1)]+"]"
note = note[:searched.span(0)[0]]+alias+note[searched.span(0)[1]:]
searched = emojiPattern.search(note)
#空白文字のみなら弾く
blankPattern = re.compile(r"^\s\s*$")
if(blankPattern.match(note)!=None):
return ""
return note
def analize(self):
"""
設計名:分析
"""
if(len(self._note)<=0):
self.result={
"status":"failure",
"reason":"分析できるノートがない"
}
return False
print("analize start")
# 全体にネガポジ判定
note = {
"negative":[],
"neutral":[],
"positive":[]
}
print("phase 1...")
for i in self._note:
i["negaposi"] = self._negaposi(i["text"],i["visibility"])
note[i["negaposi"]].append(i)
self.result["range"] = self._dayRange
self.result["noteCount"] = len(self._note)
self.result["posiCount"] = len(note["positive"])
self.result["neutCount"] = len(note["neutral"])
self.result["negaCount"] = len(note["negative"])
print("phase 1 OK")
print("positive note sample")
for i in random.sample(note["positive"],min(self._setting["sampleSize"],len(note["positive"]))):
print(i["text"])
print("\nneutral note sample")
for i in random.sample(note["neutral"],min(self._setting["sampleSize"],len(note["neutral"]))):
print(i["text"])
print("\nnegative note sample")
for i in random.sample(note["negative"],min(self._setting["sampleSize"],len(note["negative"]))):
print(i["text"])
#各時間帯でネガポジの割合を出す
print("\nphase 2...")
self.result["timeBase"] = {
"posiCount":[0]*24,
"neutCount":[0]*24,
"negaCount":[0]*24,
"noteCount":[0]*24,
"posiPerNote":[0]*24,
"neutPerNote":[0]*24,
"negaPerNote":[0]*24,
"maxNega":None
}
for i in note["negative"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["timeBase"]["negaCount"][createdDate.hour]+=1
self.result["timeBase"]["noteCount"][createdDate.hour]+=1
for i in note["neutral"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["timeBase"]["neutCount"][createdDate.hour]+=1
self.result["timeBase"]["noteCount"][createdDate.hour]+=1
for i in note["positive"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["timeBase"]["posiCount"][createdDate.hour]+=1
self.result["timeBase"]["noteCount"][createdDate.hour]+=1
for i in range(24):
if(self.result["timeBase"]["noteCount"][i]<=0 and i==0):
self.result["timeBase"]["negaPerNote"][i] = 0
self.result["timeBase"]["neutPerNote"][i] = 0
self.result["timeBase"]["posiPerNote"][i] = 0
continue
elif(self.result["timeBase"]["noteCount"][i]<=0):
self.result["timeBase"]["negaPerNote"][i] = self.result["timeBase"]["negaPerNote"][i-1]
self.result["timeBase"]["neutPerNote"][i] = self.result["timeBase"]["negaPerNote"][i-1]
self.result["timeBase"]["posiPerNote"][i] = self.result["timeBase"]["negaPerNote"][i-1]
continue
self.result["timeBase"]["negaPerNote"][i] = self.result["timeBase"]["negaCount"][i]/self.result["timeBase"]["noteCount"][i]
self.result["timeBase"]["neutPerNote"][i] = self.result["timeBase"]["neutCount"][i]/self.result["timeBase"]["noteCount"][i]
self.result["timeBase"]["posiPerNote"][i] = self.result["timeBase"]["posiCount"][i]/self.result["timeBase"]["noteCount"][i]
self.result["timeBase"]["maxNega"] = self.result["timeBase"]["negaPerNote"].index(max(self.result["timeBase"]["negaPerNote"]))
print("phase 2 OK")
#各曜日でネガポジの割合を出す
print("phase 3...")
self.result["weekBase"] = {
"posiCount":[0]*7,
"neutCount":[0]*7,
"negaCount":[0]*7,
"noteCount":[0]*7,
"posiPerNote":[0]*7,
"neutPerNote":[0]*7,
"negaPerNote":[0]*7,
"maxNega":None
}
for i in note["negative"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["weekBase"]["negaCount"][createdDate.weekday()]+=1
self.result["weekBase"]["noteCount"][createdDate.weekday()]+=1
for i in note["neutral"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["weekBase"]["neutCount"][createdDate.weekday()]+=1
self.result["weekBase"]["noteCount"][createdDate.weekday()]+=1
for i in note["positive"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["weekBase"]["posiCount"][createdDate.weekday()]+=1
self.result["weekBase"]["noteCount"][createdDate.weekday()]+=1
for i in range(7):
if(self.result["weekBase"]["noteCount"][i]<=0 and i==0):
self.result["weekBase"]["negaPerNote"][i] = 0
self.result["weekBase"]["neutPerNote"][i] = 0
self.result["weekBase"]["posiPerNote"][i] = 0
continue
elif(self.result["weekBase"]["noteCount"][i]<=0):
self.result["weekBase"]["negaPerNote"][i] = self.result["weekBase"]["negaPerNote"][i-1]
self.result["weekBase"]["neutPerNote"][i] = self.result["weekBase"]["negaPerNote"][i-1]
self.result["weekBase"]["posiPerNote"][i] = self.result["weekBase"]["negaPerNote"][i-1]
continue
self.result["weekBase"]["negaPerNote"][i] = self.result["weekBase"]["negaCount"][i]/self.result["weekBase"]["noteCount"][i]
self.result["weekBase"]["neutPerNote"][i] = self.result["weekBase"]["neutCount"][i]/self.result["weekBase"]["noteCount"][i]
self.result["weekBase"]["posiPerNote"][i] = self.result["weekBase"]["posiCount"][i]/self.result["weekBase"]["noteCount"][i]
self.result["weekBase"]["maxNega"] = self.result["weekBase"]["negaPerNote"].index(max(self.result["weekBase"]["negaPerNote"]))
print("phase 3 OK")
#時系列で日毎のネガポジの割合を出す
print("phase 4...")
nowDate = datetime.datetime.now(pytz.timezone("Asia/Tokyo"))
startDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo"))
self.result["timeSeries"] = {
"posiCount":[0]*self._dayRange,
"neutCount":[0]*self._dayRange,
"negaCount":[0]*self._dayRange,
"noteCount":[0]*self._dayRange,
"posiPerNote":[0]*self._dayRange,
"neutPerNote":[0]*self._dayRange,
"negaPerNote":[0]*self._dayRange,
"maxNega":None
}
for i in note["negative"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["timeSeries"]["negaCount"][self._dayRange-1-((startDate-createdDate).days)]+=1
self.result["timeSeries"]["noteCount"][self._dayRange-1-((startDate-createdDate).days)]+=1
for i in note["neutral"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["timeSeries"]["neutCount"][self._dayRange-1-((startDate-createdDate).days)]+=1
self.result["timeSeries"]["noteCount"][self._dayRange-1-((startDate-createdDate).days)]+=1
for i in note["positive"]:
createdDate = datetime.datetime.fromisoformat(i["createdAt"].replace("Z","+00:00")).astimezone(pytz.timezone("Asia/Tokyo"))
self.result["timeSeries"]["posiCount"][self._dayRange-1-((startDate-createdDate).days)]+=1
self.result["timeSeries"]["noteCount"][self._dayRange-1-((startDate-createdDate).days)]+=1
for i in range(self._dayRange):
if(self.result["timeSeries"]["noteCount"][i]<=0 and i==0):
self.result["timeSeries"]["negaPerNote"][i] = 0
self.result["timeSeries"]["neutPerNote"][i] = 0
self.result["timeSeries"]["posiPerNote"][i] = 0
continue
elif(self.result["timeSeries"]["noteCount"][i]<=0):
self.result["timeSeries"]["negaPerNote"][i] = self.result["timeSeries"]["negaPerNote"][i-1]
self.result["timeSeries"]["neutPerNote"][i] = self.result["timeSeries"]["negaPerNote"][i-1]
self.result["timeSeries"]["posiPerNote"][i] = self.result["timeSeries"]["negaPerNote"][i-1]
continue
self.result["timeSeries"]["negaPerNote"][i] = self.result["timeSeries"]["negaCount"][i]/self.result["timeSeries"]["noteCount"][i]
self.result["timeSeries"]["neutPerNote"][i] = self.result["timeSeries"]["neutCount"][i]/self.result["timeSeries"]["noteCount"][i]
self.result["timeSeries"]["posiPerNote"][i] = self.result["timeSeries"]["posiCount"][i]/self.result["timeSeries"]["noteCount"][i]
print("phase 4 OK")
#ネガティブノートの詳細な感情を見る
print("phase 5...")
offensiveCount = 0
downerCount = 0
for i in note["negative"]:
detail = self._detailAnalize(i["text"])
if(detail=="offensive"):
offensiveCount+=1
else:
downerCount+=1
if(len(note["negative"])<=0):
self.result["detail"] = {
"offensive" : 0,
"downer" : 0
}
else:
self.result["detail"] = {
"offensive" : offensiveCount/len(note["negative"]),
"downer" : downerCount/len(note["negative"])
}
print("phase 5 OK")
self.result["status"] = "success"
return True
def _negaposi(self,note: str,visibility: str) -> str:
"""
設計名:感情分析
negative or neutral or positiveを返す
"""
inputs = self._tokenizer(note, return_tensors="pt")
try:
with torch.no_grad():
outputs = self._model(
inputs["input_ids"].to(self._device),
inputs["attention_mask"].to(self._device)
)
except:
return "neutral"
strength = outputs.logits.to('cpu').detach().numpy().copy()
if(self._setting["negativeFilter"]["activate"] and visibility in self._setting["negativeFilter"]["value"].keys()):
if(self._setting["negativeFilter"]["value"][visibility]>=strength[0][2]):
strength[0][2]-=5
y_preds = np.argmax(strength, axis=1)
return [self._model.config.id2label[x] for x in y_preds][0]
def _detailAnalize(self,note: str) -> str:
"""
設計名:詳細分析
offensive or downerを返す
"""
#形態素分析
words = []
for word in self._janomeTokenizer.tokenize(note):
if(word.part_of_speech.split(',')[0]=="名詞" and (word.part_of_speech.split(',')[1] not in ["非自立","接尾","数"]) and (word.surface[0] not in ["…","."])):
words.append(word.surface)
if(word.part_of_speech.split(',')[0]=="動詞" and (word.part_of_speech.split(",")[1] not in ["非自立"]) and word.base_form!="する"):
words.append(word.surface)
if(word.part_of_speech.split(',')[0] in ["形容詞","副詞"] and word.part_of_speech.split(',')[1]=="自立"):
words.append(word.surface)
#スコア化
score = [0,0]
offensiveEmotion = ["怒り","嫌悪","苛立ち","憤り","軽蔑"]
downerEmotion = ["悲しい","鬱","寂しい","絶望","憂鬱"]
for word in words:
before = copy.deepcopy(score)
try:
for emotion in offensiveEmotion:
score[0] += self._w2vModel.similarity(word,emotion)
for emotion in downerEmotion:
score[1] += self._w2vModel.similarity(word,emotion)
except:
score = before
if "!" in note or "!" in note:
score[0]*=1.1
if "..." in note or "..." in note:
score[0]*=1.1
return ["offensive","downer"][score.index(max(score))]
ノートを分析するにはまず、ノートから余計な部分を除く必要があります
Misskeyにはカスタム絵文字という機能があり、これが解析上では扱いづらいのでこれの対応をします
カスタム絵文字とは、ノート中に
:絵文字名:
と書くと、テキスト表示時にこの部分をサーバーごとに持つ独自の絵文字に置き換える機能です
コンストラクタでは、この絵文字をサーバーから取得します
#絵文字の取得
api_url = f"{self._setting['server']}/api/emojis"
param = json.dumps({})
response = []
try:
print("sending API(emojis)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
response = response.json()["emojis"]
except:
try:
print("sending API(emojis)...")
response = requests.post(api_url,data=param,headers={"Content-Type": "application/json"})
response.raise_for_status()
print("API OK")
response = response.json()["emojis"]
except:
print("reading emojis Failure")
response = []
絵文字はサーバードメイン/api/emojisを叩くと得られます(POSTにしてますがGETでも動くと思います)
レスポンスの形式は
{
"emojis": [
{
"aliases": [
"…"
],
"name": "…",
"category": null,
"url": "…",
"localOnly": true,
"isSensitive": true,
"roleIdsThatCanBeUsedThisEmojiAsReaction": []
}
]
}
です、emojisの部分にリストになって各絵文字のデータが入っています
このうち、nameが絵文字名であり、aliasesは検索用の別名が入っています
絵文字名はコードですが、別名は分かりやすいように日本語になっていたりするのでこれを使います
#絵文字のデータ形式を整形
self._emoji = {}
for i in response:
if(len(i["aliases"])<=0):
continue
self._emoji[i["name"]] = i["aliases"][0]
if(self._setting["server"] in ["https://sushi.ski","https://misskey.io"]):
self._emoji["blank"] = ""
このように、{絵文字名:1つ目の別名}の形で登録しておきます
:blank:は(すしすき-やioでは)空白を表す文字なので空文字を指定しておきます、空文字じゃなくても登録を消すのでもいいですが、どのみちないものとして無視できればいいです
ノートの整形時に絵文字をこの別名に置き換えます
また、絵文字の他に正規表現で削除パターンを考えておきます
self._removePattern = [
re.compile(r"https?://[\w!\?/\+\-_~=;\.,\*&@#\$%\(\)'\[\]]+"),
re.compile(r"\*\*"),
re.compile(r"<[/\w]+>"),
re.compile(r"\$\[\S+(\s.*?)\]"),
re.compile(r"@[\w\.]+")
]
これは、上から順に、URI、強調構文、<~>のタグ、MFM、メンションを消すための削除パターンです
MFMとはMisskeyの機能で、例えば$[position.x=3 文字]とすると文字のx座標がずれたりするような装飾用の構文です、感情分析には使わないので消しておきます
まとめて、以下のノート整形関数を作りました
def _noteFormatter(self,note: str) -> str:
"""
設計名:ノート整形
"""
if(note==None or note==""):
return ""
#削除パターンを削除
for pattern in self._removePattern:
searched = pattern.search(note)
while(searched!=None):
inner = ""
try:
inner = searched.group(1)
except:
inner = ""
note = note[:searched.span(0)[0]]+inner+note[searched.span(0)[1]:]
searched = pattern.search(note)
#絵文字とそれ以外をカウント
emojiPattern = re.compile(r":(\w+?):")
noEmoji = note
searched = emojiPattern.search(noEmoji)
while(searched!=None):
noEmoji = noEmoji[:searched.span(0)[0]]+noEmoji[searched.span(0)[1]:]
searched = emojiPattern.search(noEmoji)
noEmoji = noEmoji.replace(" ","")
noEmoji = noEmoji.replace("\n","")
emojiCount = len(emojiPattern.findall(note))
mojiCount = len(noEmoji)
if(mojiCount<=10 and emojiCount>=10 or mojiCount==0 and emojiCount>=4):
return ""
#絵文字をエイリアスに置き換え
searched = emojiPattern.search(note)
while(searched!=None):
alias = ""
if(searched.group(1) in self._emoji.keys() and self._emoji[searched.group(1)]!=""):
alias = "["+self._emoji[searched.group(1)]+"]"
note = note[:searched.span(0)[0]]+alias+note[searched.span(0)[1]:]
searched = emojiPattern.search(note)
#空白文字のみなら弾く
blankPattern = re.compile(r"^\s\s*$")
if(blankPattern.match(note)!=None):
return ""
return note
絵文字の数を数えてるのは、内容がほとんど絵文字で書かれた投稿はうまく感情分析できないと思うので先に消しておくためです
特に僕はネタ投稿としてほとんどが絵文字の投稿をすることがあります
これとかね
ノート取得のこともいくつか書いておきます(callNote関数やreadNote関数)
日付を扱うためにdatetimeライブラリとpytzライブラリを使います
日本の時間を前提に、読み込む範囲を定めています
nowDate = datetime.datetime.now(pytz.timezone("Asia/Tokyo"))
untilDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo"))
sinceDate = datetime.datetime(nowDate.year,nowDate.month,nowDate.day,0,0,0,tzinfo=pytz.timezone("Asia/Tokyo")) - datetime.timedelta(days=self._dayRange)
日単位で考えるので中途半端な今日の投稿は無視し、範囲分の日数引いた日付の始まりから1日前の終わりまでとします
ノートを取得するAPIは
サーバードメイン/api/users/notes
で、POSTする情報のパラメータは沢山あるので詳しくはドキュメントを見てほしいですが
{
"i": トークン,
"userId" : ユーザID,
"withRenotes" : False,
"limit" : 100 ,
"untilDate" : 読み込み終了の時刻,
"sinceDate" : 読み込み開始の時刻
ここで、untilDateとsinceDateはUNIX時間ですが、マイクロ秒単位で指定する必要があります(普通UNIX時間は秒単位なのでこれを考慮する必要があります)
なので
"untilDate" : int(untilDate.timestamp())*1000
というように1000掛けた形になります
また、datetimeではdatetime.datetime.fromisoformatでISO形式の時刻を読み込めますが、世界標準時のZの表記には対応していません
なので
datetime.datetime.fromisoformat(response[-1]["createdAt"].replace("Z","+00:00"))
というように"Z"を"+00:00"(ずれなし)に置き換えて対応します
感情分析については、ファインチューニング済みのモデルを./model/dert/に保存して読み込んでいます
ファインチューニングとそのモデルの使い方についてはほぼこれの通りです、あまり詳しくないのでこちらを参考にしてください
参考記事のものよりも、データセットを縮小させた(1/5だけサンプリングしました)ので精度は低くなってると思います
モデルはコンストラクタの
self._device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self._tokenizer = AutoTokenizer.from_pretrained(BERTMODELPATH)
self._model = (AutoModelForSequenceClassification.from_pretrained(BERTMODELPATH).to(self._device))
この部分で読み込んでいます(BERTMODELPATHはグローバルに"./model/bert"で宣言してます)
ブラックボックスにしていた感情分析の部分は
def _negaposi(self,note: str,visibility: str) -> str:
"""
設計名:感情分析
negative or neutral or positiveを返す
"""
inputs = self._tokenizer(note, return_tensors="pt")
try:
with torch.no_grad():
outputs = self._model(
inputs["input_ids"].to(self._device),
inputs["attention_mask"].to(self._device)
)
except:
return "neutral"
strength = outputs.logits.to('cpu').detach().numpy().copy()
if(self._setting["negativeFilter"]["activate"] and visibility in self._setting["negativeFilter"]["value"].keys()):
if(self._setting["negativeFilter"]["value"][visibility]>=strength[0][2]):
strength[0][2]-=5
y_preds = np.argmax(strength, axis=1)
return [self._model.config.id2label[x] for x in y_preds][0]
上記のリンクの記事に則って結果を出しているだけです
少しだけいじっている部分は
if(self._setting["negativeFilter"]["activate"] and visibility in self._setting["negativeFilter"]["value"].keys()):
if(self._setting["negativeFilter"]["value"][visibility]>=strength[0][2]):
strength[0][2]-=5
この部分です
strength変数は
strength = outputs.logits.to('cpu').detach().numpy().copy()
で宣言していて、どうやらどれだけpositive/neutral/negativeが強いかが書いてあるようです(確率ではないので0未満や1を超えたりもします)
_negaposi関数の引数のvisibilityはノートの公開範囲を渡す部分であり、公開範囲には"public"/"home"/"followers"があり、順に狭くなっています
おそらくですが「広い公開範囲ではネガティブなことは言いづらい(狭い公開範囲ではネガティブなことを言いやすい)」とか「ネタ投稿は広い公開範囲でされやすい」(ネタをネタとして捉える能力はこの感情分析モデルにはありません)といった性質があるので、公開範囲ごとにネガティブ判定の閾値を付けることにしました
誤検知のネタ投稿ではネガティブの値(strength[0][2])は2程度なのですが、本当にネガティブな投稿になると4ぐらいになります
デフォルトではこの閾値機能はオフにしています
if文条件のself._setting["negativeFilter"]["activate"]はsetting.jsonを読み込んだものであり、対応する部分をfalseからtrueに置き換えることで作動します
デフォルトではfalseを書き、利用者がこれを書き換えることでこの機能が動くようになります、なので、使われないことの方が多いかもしれません(一応使い方の説明画面には書いていますが)
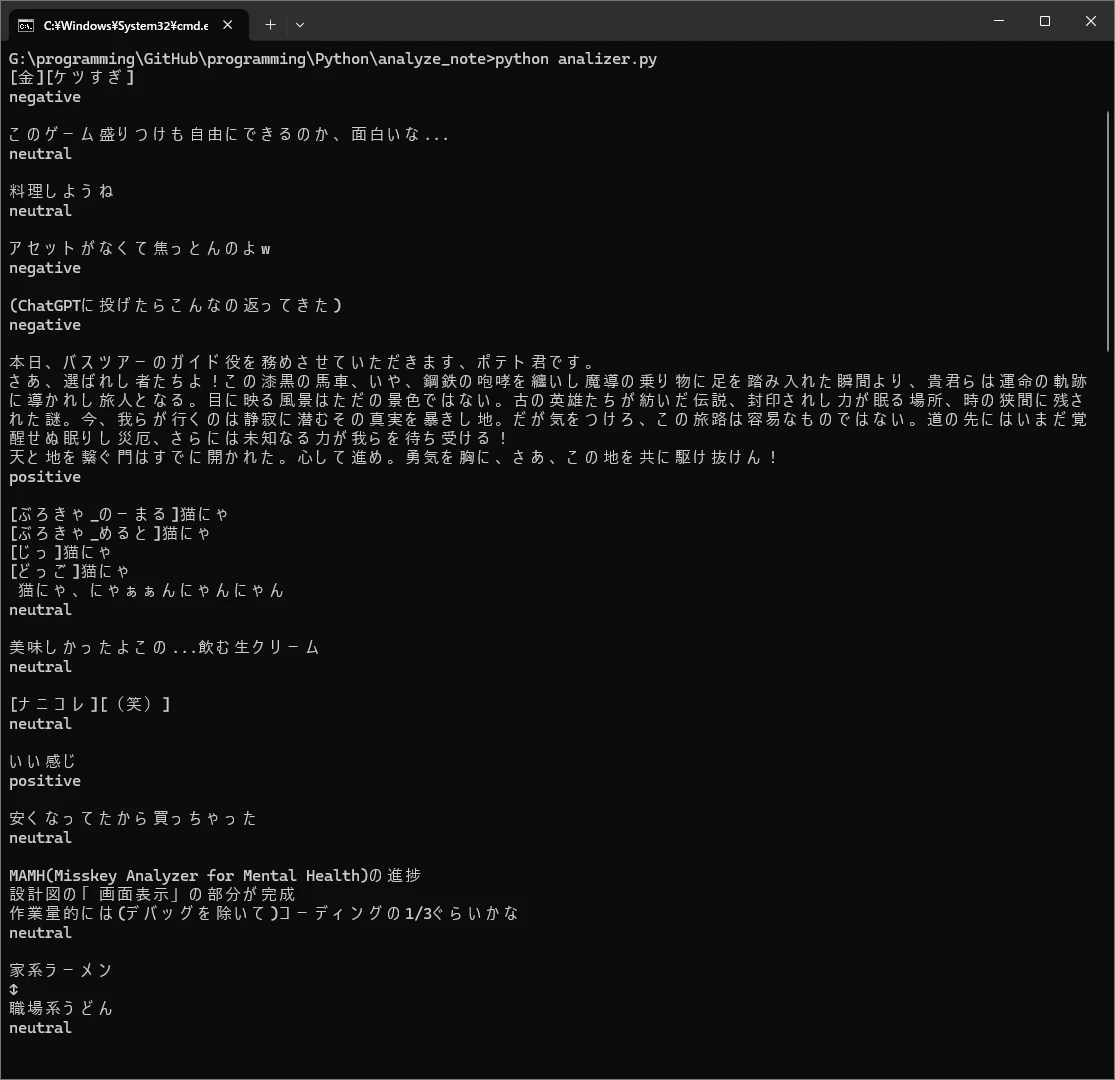
試したときの結果です(おそらく、閾値機能はなし)
これはほんとの僕の開発時点の投稿で、あんまりネガティブなものもないので例が悪いですがネタ投稿がネガティブとして拾われてしまっているのは少し分かると思います、今回はポジティブの判定の精度はあまり考えないこととします
また、詳細な感情分析としてネガティブなノートが"offensive"(攻撃的)か"downer"(ダウナー)かを判定することにしました
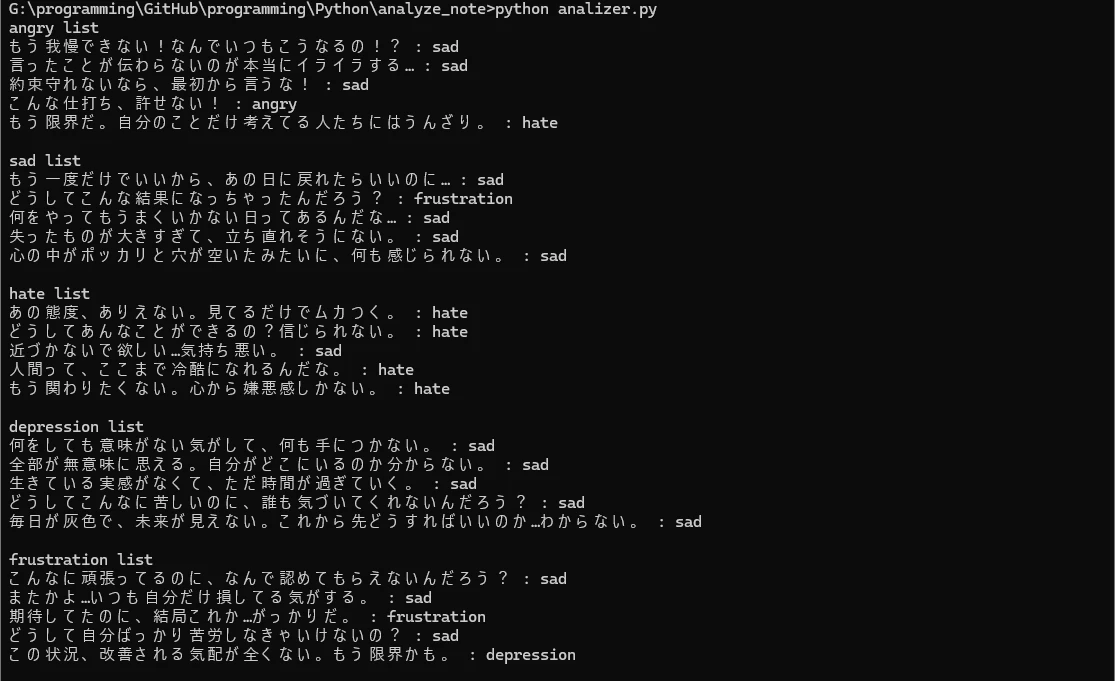
本当はもっと詳細に調べたかったのですが、この通り精度が悪いので諦めました
手順としては、
Janomeのトークナイザーで形態素分析して単語ごとに分ける
→word2vecで単語ベクトルとして各単語の感情との類似度を点数として加算する
→offensiveな感情とdownerな感情で点数を合計し、高い方を選ぶ
という流れです
word2vecのモデルとしてこちらを使わせていただきました
モデルはコンストラクタで読み込んでおきます
self._w2vModel = gensim.models.word2vec.KeyedVectors.load_word2vec_format(WORD2VECMODELPATH)
self._janomeTokenizer = Tokenizer()
詳細分析は以下のようになりました
def _detailAnalize(self,note: str) -> str:
"""
設計名:詳細分析
offensive or downerを返す
"""
#形態素分析
words = []
for word in self._janomeTokenizer.tokenize(note):
if(word.part_of_speech.split(',')[0]=="名詞" and (word.part_of_speech.split(',')[1] not in ["非自立","接尾","数"]) and (word.surface[0] not in ["…","."])):
words.append(word.surface)
if(word.part_of_speech.split(',')[0]=="動詞" and (word.part_of_speech.split(",")[1] not in ["非自立"]) and word.base_form!="する"):
words.append(word.surface)
if(word.part_of_speech.split(',')[0] in ["形容詞","副詞"] and word.part_of_speech.split(',')[1]=="自立"):
words.append(word.surface)
#スコア化
score = [0,0]
offensiveEmotion = ["怒り","嫌悪","苛立ち","憤り","軽蔑"]
downerEmotion = ["悲しい","鬱","寂しい","絶望","憂鬱"]
for word in words:
before = copy.deepcopy(score)
try:
for emotion in offensiveEmotion:
score[0] += self._w2vModel.similarity(word,emotion)
for emotion in downerEmotion:
score[1] += self._w2vModel.similarity(word,emotion)
except:
score = before
if "!" in note or "!" in note:
score[0]*=1.1
if "..." in note or "..." in note:
score[0]*=1.1
return ["offensive","downer"][score.index(max(score))]
Janomeでトークナイズされたデータには、.part_of_speech.split(',')[0]で品詞を見ることができます(splitで分割してるのは、並んで他にも補足情報があるからです)
名詞、動詞、形容詞、副詞だけを取り出すようにします(助詞や助動詞にはそれ自体にあまり情報がないので)
offensiveな感情として["怒り","嫌悪","苛立ち","憤り","軽蔑"]、downerな感情として["悲しい","鬱","寂しい","絶望","憂鬱"]を選びました
単に加算するだけなのでoffensiveとdownerの感情の項目数は揃えるようにしています
あとSNSの傾向として、「!」があるとoffensive寄りで「...」があるとdowner寄り(安直だけど、多分ある程度正しい)な傾向はあると思うので、それをスコアに重みづけしました
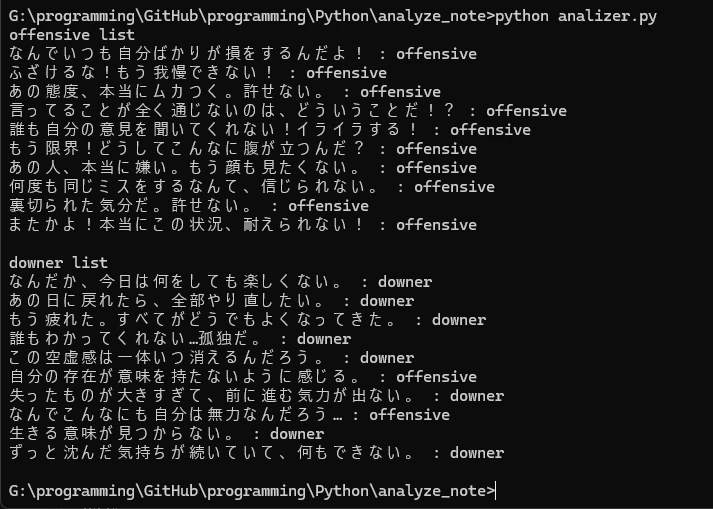
結構精度よさそうですね
サブ画面(subUI.py)
最後はサブ画面です、ほとんど画面表示なので細かい説明はしません
コード(長いです)
import abc
import tkinter as tk
import matplotlib.pyplot as plt
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
class SubUi(metaclass=abc.ABCMeta):
"""
設計名:サブ画面クラス
"""
@abc.abstractmethod
def __init__(self,window,referrer):
raise NotImplementedError()
@abc.abstractmethod
def initialize(self):
raise NotImplementedError()
@abc.abstractmethod
def show(self):
raise NotImplementedError()
@abc.abstractmethod
def _returnMenu(self):
raise NotImplementedError()
@abc.abstractmethod
def returnMenuButton(self):
raise NotImplementedError()
class ManualUi(SubUi):
"""
設計名:説明画面クラス
_page : 現在ページ int
_window : 画面 tkinter.Tk
_referrer : 遷移元 Ui
_widget : ウィジェット dict
_title : タイトル list<str>
_explane : 説明文 list<str>
_image : 説明画像 list<tk.PhotoImage|None>
"""
def __init__(self,window : tk.Tk,referrer):
self._window = window
self._referrer = referrer
self._title = [
"ようこそ",
"サーバー設定",
"分析の方法",
"APIトークンの設定",
"APIトークンの設定",
"APIトークンの設定",
"ノートファイルの設定",
"ノートファイルの設定",
"分析",
"分析",
"その他"
]
self._explane = [
"Misskey Analizer for Mental Health(MAMH)へようこそ\nこれは、ポテト(タイム)君(https://potatotimekun.github.io/web/)によって開発された、メンタルヘルスを目的としたMisskeyアカウントの分析ツールです",
"まず分析したい自分のアカウントが存在するMisskeyサーバーをソフトがあるディレクトリ直下のsetting.jsonに書き込んでください\nデフォルトはすしすき-(https://sushi.ski)になっています\n例えば、misskey.ioを使っているのであればここをhttps://misskey.ioに置き換えます\n設定後はソフトを再起動してください(起動時に反映されるので)\nAPIを使わない場合でも、カスタム絵文字のエイリアス取得のためにサーバーと通信します",
"分析には、MisskeyAPIを使う方法とノートファイルを持ってくる方法があります\nMisskeyAPIを使う場合、Misskeyアカウントと連携してリアルタイムにノートを取得します\nノートファイルを使う場合、自身のMisskeyアカウントから事前にノートをエクスポートして保存しておく必要があります\nどちらかお好きな方を選んでください\nAPIトークンを設定するとAPIが優先さえられるので、トークン設定後にファイルを使いたいときはこのソフトのディレクトリ直下のtoken.txtを消してソフトを再起動してください",
"APIを使用する場合、トークンを生成して設定する必要があります\n分析したいアカウントでMisskeyサーバーのページを開き、設定→その他の設定の「API」という項目を開きます\n「アクセストークンの発行」を選びます\n「アカウントの情報を見る」をONにします\n表示された「確認コード」の中身をメモしておきます",
"今メモした「確認コード」がいわゆるAPIトークンであり、アカウントにアクセスする許可証の役割を果たします\nこれが漏れると、アカウントを乗っ取られるなどの危険があります\n他人に教えたり、不特定多数の目に触れることのないよう管理してください\nまた、このソフトに設定したトークンはこのソフトのディレクトリ直下のtoken.txtに保存しています(このファイルを公開しないように注意してください)",
"APIトークンは、このソフトのメインメニューにある「APIトークンの入力」欄に入れ、「確定」ボタンを押すことで使用できるようになります",
"ノートファイルを使用する場合、事前に準備をします\n分析したいアカウントでMisskeyサーバーのページを開き、設定→その他の設定の「インポートとエクスポート」という項目を開きます\n「全てのノート」から「エクスポート」を選択します\nドライブを開きます\nnote-(日付).jsonと書かれたファイルが生成されるので、選択してダウンロードします(ファイルが生成されるまで時間がかかることもあります)",
"ダウンロードしたノートファイルを、このソフトのメインメニューの「ファイル入力」ボタンで選択します",
"トークンかファイルのどちらかが設定できたら、~日間を分析のところから分析したい日数を設定します(APIを使用する場合、あまりに長いとサーバーへの負荷になる可能性があります)\n現在の日付から指定した日数分だけ前の日付までを分析対象とします\nその後、分析開始を押します、分析には数分かかったりします\n分析中、長すぎるノートがあるとエラーメッセージが出ますが続行して構いません(該当ノートはニュートラルとしてカウントされます)\n分析が終わった後、分析結果からその内容が確認できます",
"分析中は結果をいくつかサンプリングしてログを表示しています\nネガティブの判定について、精度が悪いと思った場合はsetting.jsonを開いてnegativeFilter>activateをいじることでフィルターを有効化することができます(細かくはsetting.jsonのコメントに書いてあります)\nそれ以上は分析モデルを自作するか諦めてください、開発者はネタノートをよくするので誤検知されまくります",
"指定したサーバーのMisskeyAPIを使用する以外に、このソフトで収集した情報が外部に送信されることはありません\nこのソフトのコードはMITライセンスとして開発者のGitHubリポジトリ(https://github.com/PotatoTimeKun/programming)に公開します\nエラー報告などは開発者のすしすき-アカウント(https://sushi.ski/@potatokun)に連絡ください"
]
self._image = [
tk.PhotoImage(file="./asset/MAMH_logo.png"),
tk.PhotoImage(file="./asset/server.png"),
None,
tk.PhotoImage(file="./asset/gen_token.png"),
None,
None,
tk.PhotoImage(file="./asset/export_note.png"),
None,
None,
None,
None
]
self._widget = {
"titleLabel" : tk.Label(text="",bg="#ffffff",font=('Times New Roman',20)),
"explaneLabel" : tk.Label(text="",bg="#ffffff",wraplength=780,anchor='e',justify='left',font=('Times New Roman',16)),
"imageCanvas" : tk.Canvas(window,width=780,height=180,bg="#ffffff"),
"backButton" : tk.Button(text="戻る",command=self.returnMenuButton,width=15,height=1,font=('Times New Roman',12)),
"pageLabel" : tk.Label(text="",bg="#ffffff",font=('Times New Roman',16)),
"previousButton" : tk.Button(text="前のページ",command=self.previousButtonFunc,width=15,height=1,font=('Times New Roman',12)),
"nextButton" : tk.Button(text="次のページ",command=self.nextButtonFunc,width=15,height=1,font=('Times New Roman',12))
}
def initialize(self):
"""
設計名:初期化
ページを0に設定
"""
self._page = 0
def show(self):
"""
設計名:表示
画面の消去と指定したページ内容の表示
"""
#画面をクリア
self._widget["imageCanvas"].delete("image")
for k in self._widget.keys():
self._widget[k].place_forget()
#ページ内容を設定
self._widget["pageLabel"]["text"]=f"{self._page+1}/{len(self._title)}"
self._widget["titleLabel"]["text"]=self._title[self._page]
self._widget["explaneLabel"]["text"]=self._explane[self._page]
self._widget["imageCanvas"].create_image(780/2,180/2,image=self._image[self._page],tag="image")
#ウィジェットを配置
self._widget["titleLabel"].place(x=10,y=10)
self._widget["imageCanvas"].place(x=10,y=50)
self._widget["explaneLabel"].place(x=10,y=260)
self._widget["backButton"].place(x=10,y=560)
self._widget["previousButton"].place(x=300,y=560)
self._widget["nextButton"].place(x=600,y=560)
self._widget["pageLabel"].place(x=500,y=565)
def _returnMenu(self):
"""
設計名:戻る
画面の消去と遷移元の表示
"""
self._widget["imageCanvas"].delete("image")
for k in self._widget.keys():
self._widget[k].place_forget()
self._referrer.show()
def returnMenuButton(self):
"""
設計名:戻るボタン処理
"""
self._returnMenu()
def _previousPage(self):
"""
設計名:前のページ
"""
self._page-=1
if(self._page<0):
self._page = len(self._title)-1
def _nextPage(self):
"""
設計名:次のページ
"""
self._page+=1
if(self._page>len(self._title)-1):
self._page = 0
def previousButtonFunc(self):
"""
設計名:前のページボタン処理
"""
self._previousPage()
self.show()
def nextButtonFunc(self):
"""
設計名:次のページボタン処理
"""
self._nextPage()
self.show()
class ResultUi(SubUi):
def __init__(self,window,referrer):
self._window = window
self._referrer = referrer
self._title = [
"ノート全体",
"時間帯",
"曜日",
"時系列",
"詳細",
"その他"
]
self._explane = [
"読み込んだすべてのノートのポジティブ/ニュートラル/ネガティブの割合を示します",
"",
"",
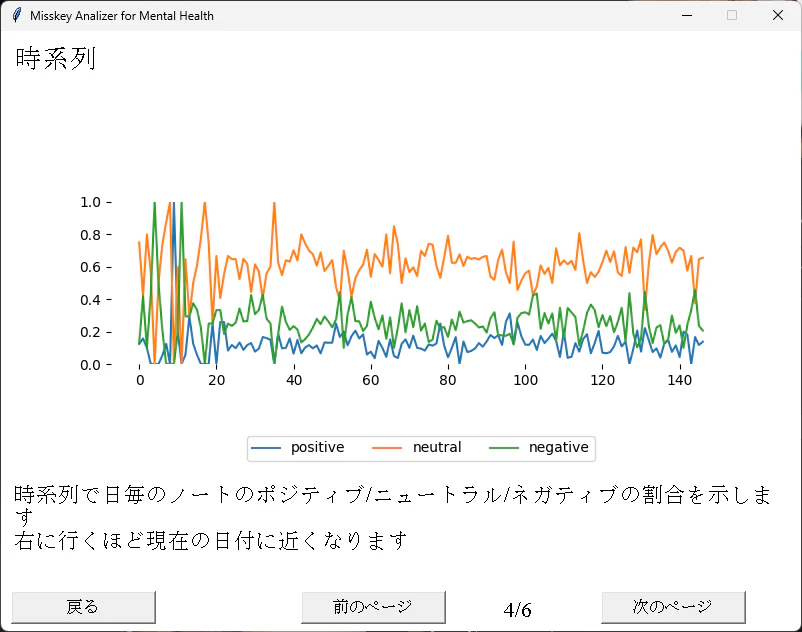
"時系列で日毎のノートのポジティブ/ニュートラル/ネガティブの割合を示します\n右に行くほど現在の日付に近くなります",
"ネガティブなノートがoffensive(攻撃的)かdowner(ダウナー)かを示します",
""
]
self._graph = plt.Figure(figsize=(8, 4))
self._ax = self._graph.add_subplot()
self._widget = {
"titleLabel" : tk.Label(text="",bg="#ffffff",font=('Times New Roman',20)),
"explaneLabel" : tk.Label(text="",bg="#ffffff",wraplength=780,anchor='e',justify='left',font=('Times New Roman',16)),
"frame" : tk.Frame(width=780,height=380),
"canvas" : None,
"backButton" : tk.Button(text="戻る",command=self.returnMenuButton,width=15,height=1,font=('Times New Roman',12)),
"pageLabel" : tk.Label(text="",bg="#ffffff",font=('Times New Roman',16)),
"previousButton" : tk.Button(text="前のページ",command=self.previousButtonFunc,width=15,height=1,font=('Times New Roman',12)),
"nextButton" : tk.Button(text="次のページ",command=self.nextButtonFunc,width=15,height=1,font=('Times New Roman',12))
}
self._widget["canvas"] = FigureCanvasTkAgg(self._graph, master=self._widget["frame"])
self._widget["canvas"].get_tk_widget().pack()
def initialize(self):
"""
設計名:初期化
ページを0に設定
"""
self._page = 0
def resultSet(self,result: dict):
"""
設計名:分析結果セット
"""
self._result = result
def show(self):
"""
設計名:表示
画面の消去と指定したページ内容の表示
"""
#画面をクリア
if(self._widget["canvas"]!=None):
self._ax.clear()
for k in self._widget.keys():
if(k=="canvas"):
continue
self._widget[k].place_forget()
#ページ内容を設定
self._widget["pageLabel"]["text"]=f"{self._page+1}/{len(self._title)}"
self._widget["titleLabel"]["text"]=self._title[self._page]
if(self._page==0):
self._ax.pie([self._result["posiCount"],self._result["neutCount"],self._result["negaCount"]],labels=["positive","neutral","negative"])
elif(self._page==1):
self._ax.bar(list(range(0,24)),self._result["timeBase"]["posiPerNote"],label="positive")
self._ax.bar(list(range(0,24)),self._result["timeBase"]["neutPerNote"],bottom=self._result["timeBase"]["posiPerNote"],label="neutral")
self._ax.bar(list(range(0,24)),self._result["timeBase"]["negaPerNote"],bottom=[i+j for i, j in zip(self._result["timeBase"]["posiPerNote"], self._result["timeBase"]["neutPerNote"])],label="negative")
self._ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.1), ncol=3,borderaxespad=4)
self._explane[self._page] = f"時間帯毎のノートに対するポジティブ/ニュートラル/ネガティブの割合を示します\n{self._result['timeBase']['maxNega']}~{self._result['timeBase']['maxNega']+1}時にネガティブが多いです"
self._ax.set_ylim([0, 1])
self._ax.set_aspect(2*24/7)
elif(self._page==2):
weekday = ["Mon","Tue","Wed","Thu","Fri","Sat","Sun"]
japaneaseWeekday = "月火水木金土日"
self._ax.bar(weekday,self._result["weekBase"]["posiPerNote"],label="positive")
self._ax.bar(weekday,self._result["weekBase"]["neutPerNote"],bottom=self._result["weekBase"]["posiPerNote"],label="neutral")
self._ax.bar(weekday,self._result["weekBase"]["negaPerNote"],bottom=[i+j for i, j in zip(self._result["weekBase"]["posiPerNote"], self._result["weekBase"]["neutPerNote"])],label="negative")
self._ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.1), ncol=3,borderaxespad=4)
self._explane[self._page] = f"曜日毎のノートに対するポジティブ/ニュートラル/ネガティブの割合を示します\n{japaneaseWeekday[self._result['weekBase']['maxNega']]}曜日にネガティブが多いです"
self._ax.set_ylim([0, 1])
self._ax.set_aspect(2)
elif(self._page==3):
self._ax.plot(list(range(0,self._result["range"])),self._result["timeSeries"]["posiPerNote"],label="positive")
self._ax.plot(list(range(0,self._result["range"])),self._result["timeSeries"]["neutPerNote"],label="neutral")
self._ax.plot(list(range(0,self._result["range"])),self._result["timeSeries"]["negaPerNote"],label="negative")
self._ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.1), ncol=3,borderaxespad=4)
self._ax.set_ylim([0, 1])
self._ax.set_aspect(2*self._result["range"]/7)
elif(self._page==4):
self._ax.pie([self._result["detail"]["offensive"],self._result["detail"]["downer"]],labels=["offensive","downer"])
self._widget["explaneLabel"]["text"]=self._explane[self._page]
#ウィジェットを配置
self._widget["titleLabel"].place(x=10,y=10)
if(self._page!=5):
self._widget["frame"].place(x=10,y=50)
self._widget["explaneLabel"].place(x=10,y=450)
self._widget["canvas"].draw()
else:
minTime=self._result['timeBase']['negaPerNote'].index(min(self._result['timeBase']['negaPerNote']))
minTimePer=round(100*self._result["timeBase"]["negaPerNote"][minTime])
maxTime=self._result['timeBase']['maxNega']
maxTimePer=round(100*self._result["timeBase"]["negaPerNote"][maxTime])
minWeek=self._result['weekBase']['negaPerNote'].index(min(self._result['weekBase']['negaPerNote']))
minWeekPer=round(100*self._result["weekBase"]["negaPerNote"][minWeek])
maxWeek=self._result['weekBase']['maxNega']
maxWeekPer=round(100*self._result["weekBase"]["negaPerNote"][maxWeek])
japaneaseWeekday = "月火水木金土日"
self._widget["explaneLabel"]["text"]=f"""分析したノート:{self._result['noteCount']}ノート\n一番ネガティブの少ない時間帯:{minTime}~{minTime+1}({minTimePer}%)\n一番ネガティブの多い時間帯:{maxTime}~{maxTime+1}({maxTimePer}%)\n一番ネガティブの少ない曜日:{japaneaseWeekday[minWeek]}({minWeekPer}%)\n一番ネガティブの多い時間帯:{japaneaseWeekday[maxWeek]}({maxWeekPer}%)"""
self._widget["explaneLabel"].place(x=10,y=50)
self._widget["backButton"].place(x=10,y=560)
self._widget["previousButton"].place(x=300,y=560)
self._widget["nextButton"].place(x=600,y=560)
self._widget["pageLabel"].place(x=500,y=565)
def _returnMenu(self):
"""
設計名:戻る
画面の消去と遷移元の表示
"""
for k in self._widget.keys():
if(k=="canvas"):
continue
self._widget[k].place_forget()
self._referrer.show()
def returnMenuButton(self):
"""
設計名:戻るボタン処理
"""
self._returnMenu()
def _previousPage(self):
"""
設計名:前のページ
"""
self._page-=1
if(self._page<0):
self._page = len(self._title)-1
def _nextPage(self):
"""
設計名:次のページ
"""
self._page+=1
if(self._page>len(self._title)-1):
self._page = 0
def previousButtonFunc(self):
"""
設計名:前のページボタン処理
"""
self._previousPage()
self.show()
def nextButtonFunc(self):
"""
設計名:次のページボタン処理
"""
self._nextPage()
self.show()
分析結果の表示には、matplotlibで作ったグラフをtkinterに埋め込んでいます
これはあまり詳しくないのでChatGPTの力を借りたりしました
グラフの画面を生成してる部分はコンストラクタの
self._graph = plt.Figure(figsize=(8, 4))
self._ax = self._graph.add_subplot()
...(略)
self._widget["canvas"] = FigureCanvasTkAgg(self._graph, master=self._widget["frame"])
self._widget["canvas"].get_tk_widget().pack()
の所です、このself._axをいじることでグラフの描画ができるらしいです
流れはグラフ生成前にself._ax.clear()で一度グラフをクリアして、self._ax.barやself._ax.pie、self._ax.plotをいじってグラフを生成し、self._widget["canvas"].draw()で再描画するといったところです
棒グラフの場合self._ax.set_aspect(数値)は横1単位に対する縦1単位の大きさの比らしいです(参考にした情報とは違う処理を起こした気がします...)
matplotlibはよく分からないのでトライアンドエラーで何とか書きました
インターフェースとしてサブ画面クラスを作りました、Pythonのオブジェクト指向はあまり強くないのでインターフェースが最初から用意されていたわけではないですが、abcライブラリを使って実装しました
@から始まる修飾子にも正直あまり詳しくないです、昔見たPythonの参考書にちょこっと書いてあった気はしますが...
最後に
というわけでMAMHが完成しました、全部で1000行ぐらいです
こんな感じで動きました、MisskeyAPI以外全部ユーザー側にインストールしてるのでモデル読み込んだり分析したりはやっぱり重いですね
このソースコードはMITライセンスとして公開しているので、自由に改変など行ってください(ネガポジ判定や分析はまだ改良の余地があると思います、別のSNSに移すこともできるかもしれません)
くちばし(アイディアくれて)ありがとう