はじめに
概要
前回の続きです。
今回は、自分で使いたいニューラルネットワークを定義します。
どうでもいいけどQiitaでMATLABの記事って150件もないんですね(2017/7/1現在)。
あと用語の使い方間違えても大目に見てください……。
今回やること
色々模索した結果、feedforwardnetクラスのインスタンスを作って、層の数や活性化関数、学習アルゴリズムを変更することで自分好みのネットワークを作って学習させることにしました。
クラスって書いたけどこれクラスなのかな。
だいたいこのCreate Neural Network ObjectとCreate custom neural networkを参考にしています。
データ生成
前回と同じ。
%%データ生成
%5*250のデータ行列を生成
data = rand(5,250);
%2*250のラベル配列を生成。
label = [sum(data)<2.5 ; sum(data)>=2.5];
ニューラルネットワークを定義
もとになるネットワーク
feedforwardnetクラスからインスタンスをつくる。2層のフィードフォワードネットワークで、活性化関数は、隠れ層がtanh、出力層がlinear。
net = feedforwardnet();
view(net)
view(net)してやると画像でネットワークの構成が見られるが、この時点でこんなかんじになっている。
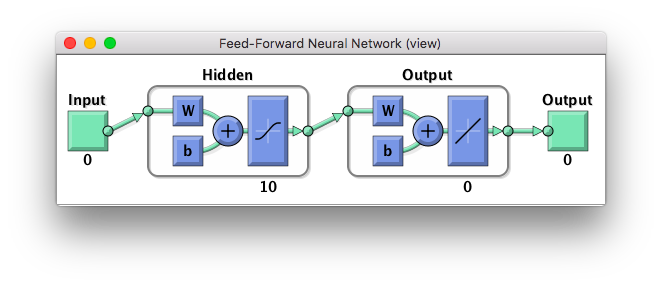
このままではクラス分類には適さない。
また、せっかくなので層の数を増やす操作とかをやってみたいと思う。
層を追加する。
層を追加する。これはnet.numLayersを変更してやればいい。デフォルトは2。
net.numLayers = 3;
view(net)
ところがこのままでは、次の図のような感じで、現状が変わってない。
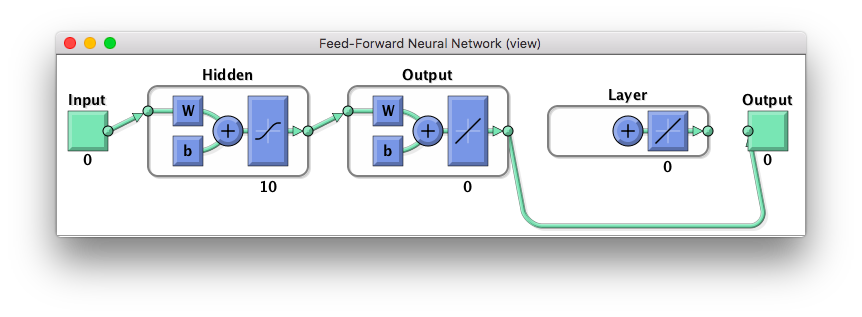
追加された層はどの層ともつながっていないし、バイアスもかかってない。
そこで、バイアスを追加して、層間を接続、さらに最後の層から出力につながるように変更してやる。
いじるのはhogeConnectというパラメータ群。バイナリの行列になっていて、接続があるところは1、ないところは0が入る。
% 各層にバイアスをかける。
net.biasConnect = [1;1;1];
% 層間の接続を変更
net.layerConnect = [0 0 0; 1 0 0; 0 1 0];
% 最後の層から出力するように変更
net.outputConnect = [0 0 1];
view(net)
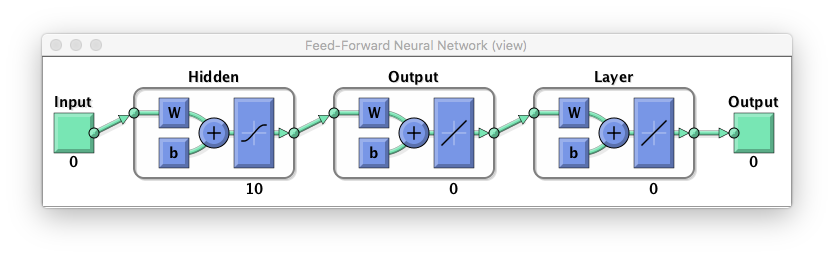
いい感じだ。名前なんて飾りであるから、Output層からOutputにつながっていなくても問題はない。
層の調整
層の名前と活性化関数を変更する。使える活性化関数は
help nntransfer
で一覧が見られる。
net.Layers{1}.name = 'Hidden1';
net.Layers{1}.dimensions = 20;
net.Layers{2}.name = 'Hidden2';
net.Layers{2}.dimensions = 10;
net.Layers{2}.transferFcn = 'tansig'
net.Layers{3}.name = 'Output';
net.Layers{3}.transferFcn = 'softmax';
view(net)
今回はしなかったが、訓練アルゴリズムを変更するには、次のようにすればいい。
使えるアルゴリズムは、
help nntrain
で一覧が見られる。
net.trainFcn = 'traingdx'
この時点で出来たネットワークは次の図のようになる。
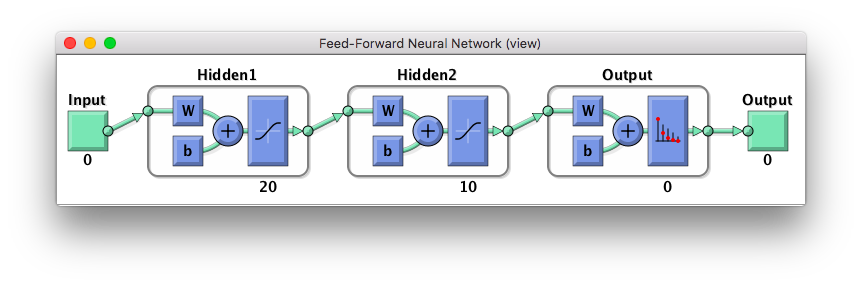
入出力のノード数は訓練時にtrainメソッドが勝手に決めてくれるはずである。
訓練とテスト
あとは前回と一緒なので割愛する。
%% 訓練
%訓練データから勝手に入出力を読んでくれる
[net,tr] = train(net,data,label);
nntraintool
plotperform(tr)
view(net)
%% テスト
test_data = data(:,tr.testInd);
test_label= label(:,tr.testInd);
test_result = net(test_data);
testIndices = vec2ind(test_result)
plotconfusion(test_label,test_result)
[c,cm] = confusion(test_label,test_result)
fprintf('Percentage Correct Classification : %f%%\n', 100*(1-c));
fprintf('Percentage Incorrect Classification : %f%%\n', 100*c);
結果
Percentage Correct Classification : 94.736842%
Percentage Incorrect Classification : 5.263158%
データ数250個だとこのくらい。
試しにデータ数を増やしてもう一度やってみる。
Percentage Correct Classification : 97.333333%
Percentage Incorrect Classification : 2.666667%
データ数は正義っぽい。
このtoolboxにはAutoEncorderが既定だったりするので、その辺利用して事前学習できるようにしてみたいところだ。
結果の出力を見てると、早期打ち切りを勝手にやってくれているみたい。
あとミニバッチ法とかやってくれてるんだろうか。そのあたりはまだよくわかってない。