はじめに
この記事は、重回帰分析を行なっていく過程を書き記している。重回帰分析で行う必要のあるステップは次のとおり。
- データの読み込みと確認
- 入力データ/目標データの切り分け
- モデル構築と検証
- 訓練データと検証データを用いたモデルの構築と検証
- 予測値の計算とモデルの保存・読み込み
これを行うためには、事前に物理学実験で観測・計測したデータやビジネスで利用されているデータをCSV形式で情報を準備しておく必要がある。
例えば、重力加速度を学習モデルから求めたい場合は、実験した場所の経度、緯度、その時の気温や気圧、地上からの高さや質量、初速度などを$x_{i}$変数とし、実験結果として得られた重力加速度の結果を$y$変数として、それらを学習元データとして準備する必要がある。また、家賃の相場を学習モデルから求めたい場合は、駅からの距離、その土地の相場、マンションであれば部屋の階数や部屋の広さなどを$x_{i}$変数とし、その結果としての実際の家賃を$y$変数として、それらを学習元データとして準備する必要がある。
つまり、学習するための生データが必然的に必要となってくる。ここでいう生データというのは、現実世界で実際に観測し得た、または得られたデータを指す。
なおここでは学習するための生データと説明しているが、実際には学習のみに用いられるわけではなく、学習済モデルがどれほどの精度を持つかを評価するためにも、生データが使用される。
データの読み込みと確認
ここから先は、あらかじめデータがCSVファイルとして準備されていることを想定している。あらかじめ準備しているCSVファイルを読み込み、正しくデータが読み込みできているかを確認する。CSVファイルには複数の$x_{i}$列と一つの$y$列が存在するものとして、準備が必要となる。

import pandas as pd
df = pd.read_csv('/content/housing.csv')
df.shape #行数と列数を確認できる
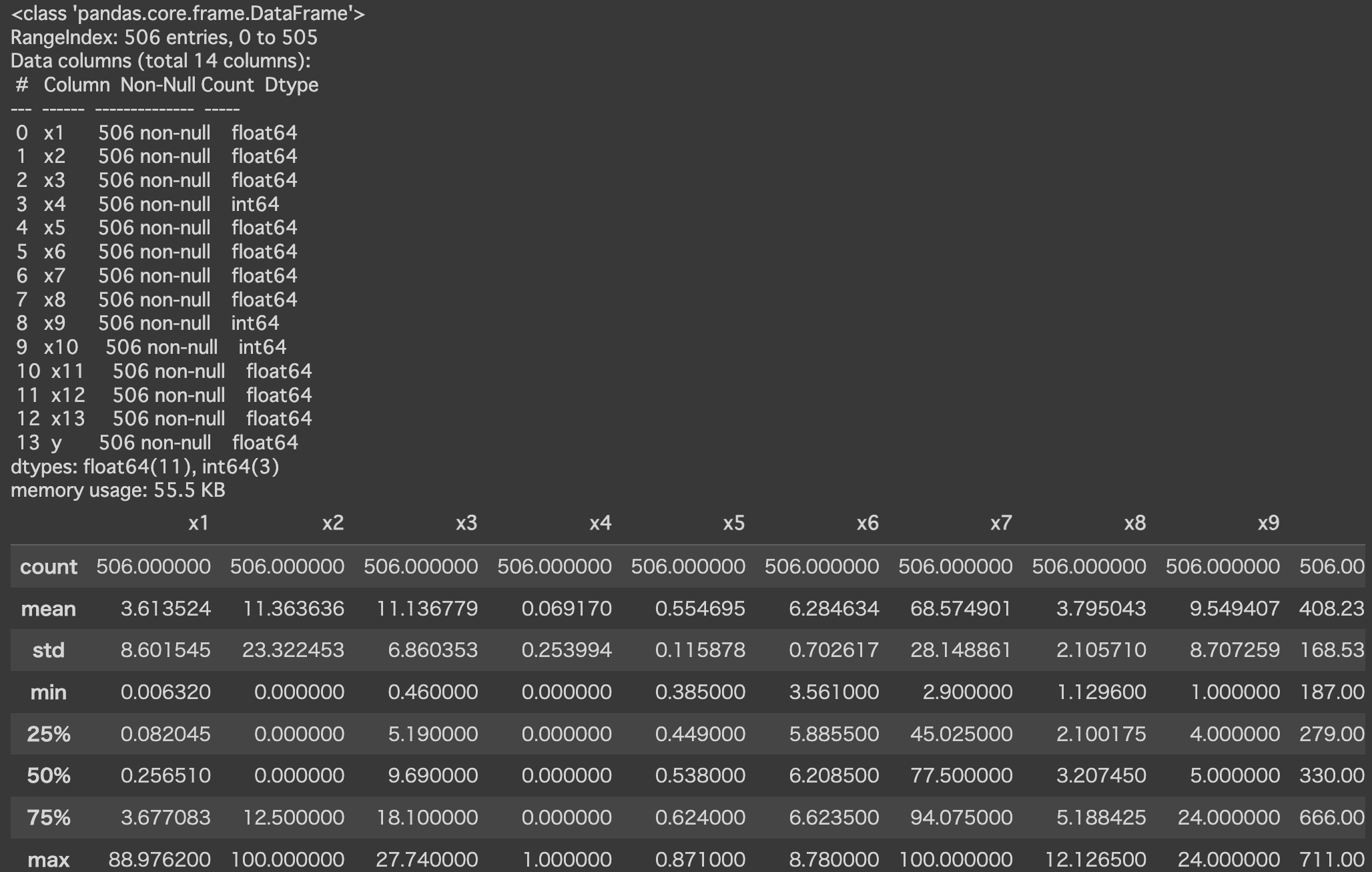
df.info() #行数列数non-nullデータを確認できる
df.describe() #統計量の算出
以下のような出力結果が出ており、行数列数に対して、nullのデータが入っていなければ、問題はない。ただし、nullのデータが入っていれば、別途、そのnullのデータに値を入れる or そのデータ自体を学習させないように削除するなど、工夫が必要となる。
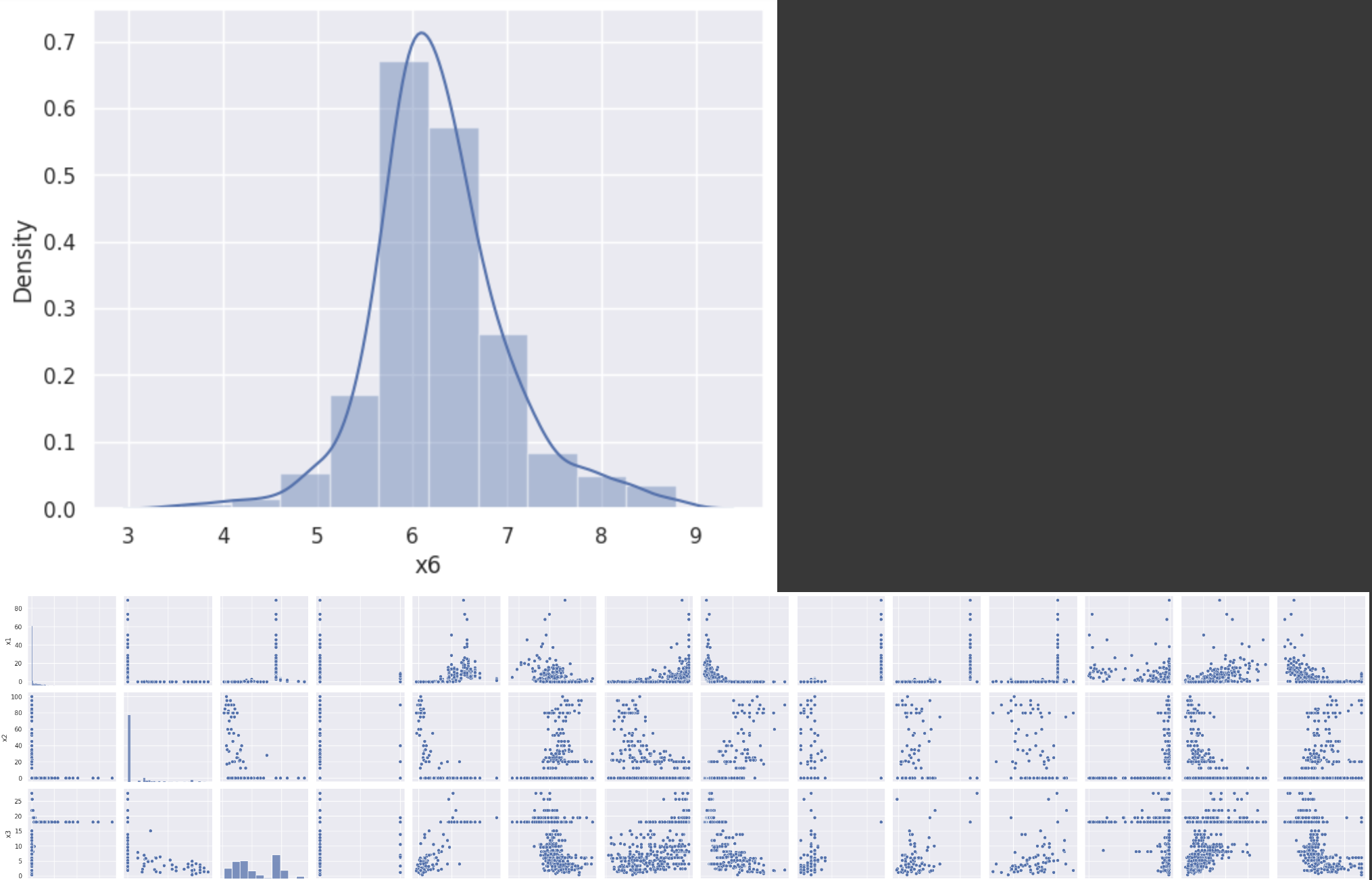
import seaborn as sns #seabornはpythonのデータ可視化用ライブラリ。
sns.set()
sns.distplot(df['x6'], bins = 10) #グラフの可視化
df.corr() #dfのそれぞれの相関係数
sns.pairplot(df) #dfのそれぞれの値をプロットしたグラフを表示
sns.distplot(df['x6']) #x6に含まれるデータを取り出して、ヒストグラムで表示
以下のように、グラフが出力されていれば、問題はない。
入力データ/目標データの切り分け
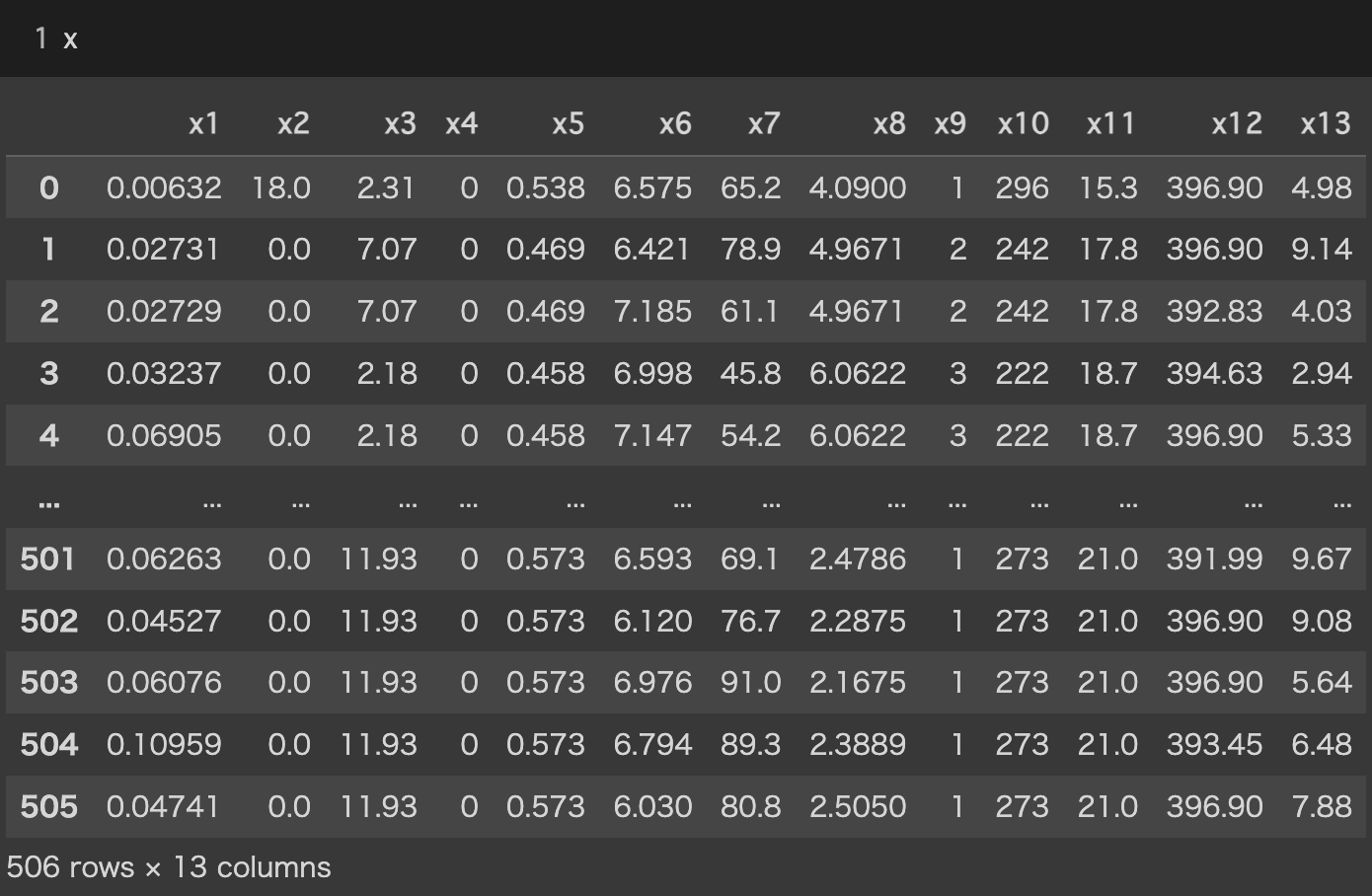
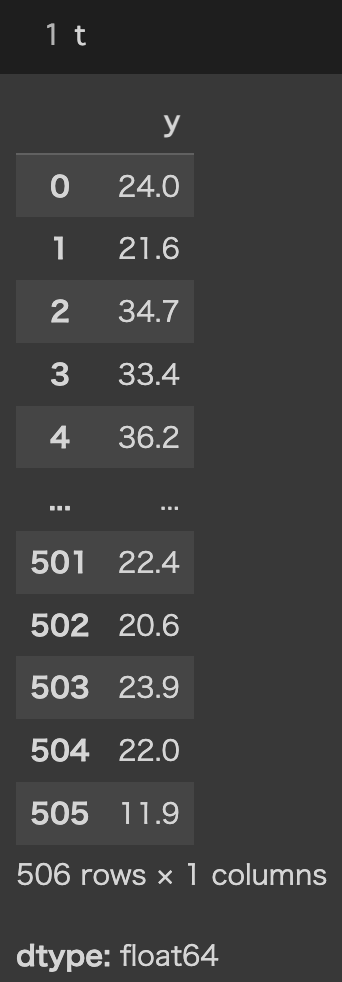
CSVファイルの$x_{i}列$と$y$列を、学習元になる入力データ$x$と目標データ$t$に分ける必要がある。なお以降、$x$は入力値をまとめたデータであり、$t$は目標値をまとめたデータを意味する。簡単に言うと、$x_{i}$と$t$が$df$(同じCSVファイル)に入っているので、$x$と$t$のそれぞれの変数へ格納しよう、と言うことです。
x = df.drop('y', axis = 1) #'y'列をドロップして、それをxに入力
t = df['y'] #'y'列のみを抽出し、それをtに入力
各種変数が以下のように格納されていれば良い。
モデルの構築と検証
ここでは、すべてのデータを用いて、学習モデルを作成している。
- 線形回帰モデルを呼び出し、
- $x$と$t$を用いて学習させたモデルを、
- 学習元として使用した$x$と$t$を用いて、性能を評価している
ただし、同じデータをもとに学習&評価したものは、評価の精度が低いため、これが十分な精度を持つモデルということは評価しずらい。
from sklearn.linear_model import LinearRegression
model = LinearRegression() #モデルのインスタンス化
model.fit(x, t) #学習
model.score(x, t) #検証し、決定係数を決定(データの分布に対して、どのくらい当てはまりのいいモデルができたかの指標)

訓練データと検証データを用いたモデルの構築と検証
ここでは、学習に使用するデータを訓練データ(train)と検証データ(test)に分けて、検証を行なっている。訓練データは学習元となるデータを分割したものであり、検証データも学習元となるデータを分割したものである。つまり、$x$と$t$という実際の生データの一部を訓練用データとして使用し、残りを検証用データとして使用することである。これによって、実際の生データに基づいて、学習と評価を行うことができるため、ある一定程度の精度を担保した評価ができる。
from sklearn.model_selection import train_test_split
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size = 0.4, random_state = 1) # 分割(用意したデータから学習用と検証用に分ける) random_state は乱数のシードの固定値(再現性の確保)
len(t_train), len(t_test) #xとtで数が同じでなければならないため、確認が必要
model.fit(x_train, t_train) #モデルの学習
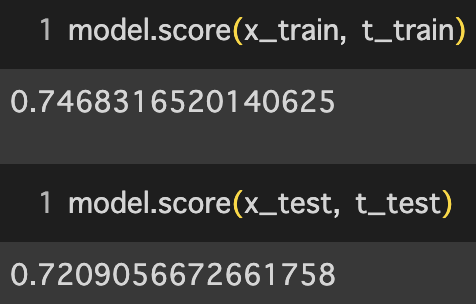
model.score(x_train, t_train) #検証(訓練データ)
model.score(x_test, t_test) #検証(検証データ)
予測値の計算とモデルの保存・読み込み
最終的に、学習させたモデルは保存する必要がある。ここではGoogle Colabへ保存する方法を示している。
import joblib
from google.colab import drive
drive.mount('/content/drive')
joblib.dump(model, 'model.pkl')
保存したモデルは利用すると仮定し、それを読み込み、予測してもらう必要がある。ここでは先ほど保存した学習モデルを読み込み、CSVの1行目のデータをsampleに入れ、それを予測した結果である。予測結果は29.4に対し、実際のデータは24.0と予測と実際のデータはほぼ一致していて、予測できていると言える。
model_new = joblib.load('/content/model.pkl')
sample = x.iloc[0, :]
model_new.predict([sample])
学習モデルから予測した結果

実際の$x$のデータと$y$のデータ

おまけ(重みの確認)
重み$w$の確認は次のとおりに指定すれば、確認ができ、各特徴量が予測にどの程度影響を与えているかを評価できます。例えば、$x_{6}$の場合、「+3.636」であり、他に比べ大きいことがわかる。これは、予測結果に対して、増加に働くことを意味する。逆に$x_{5}$の場合、「-17.205」であり、他に比べ小さいことがわかる。これは、予測結果に対して、減少に働くことを意味する。逆に「0」に近い値は、予測結果に対して、ほとんど影響しないことを意味する。
import numpy as np
model.coef_ #重みの確認
np.set_printoptions(precision = 3) #有効桁数の設定・小数点以下
model.coef_ #重みの確認
np.set_printoptions(precision = 3, suppress=True) # 指数関数の表示禁止
model.coef_ #重みの確認
