Amazon Workspacesにどのユーザーが何時にログイン及びログアウトしたかの記録がCloudWatchメトリクスとしてしか分からなかったのでもう少し分かりやすくファイル形式で出力できたらいいなと思ったのでやってみました。
使うサービス
・Amazon WorkSpaces
・Lambda関数2つ
・Lambda用のIAMロール
・Dynamo DB
・S3
・CloudWatch
構成図
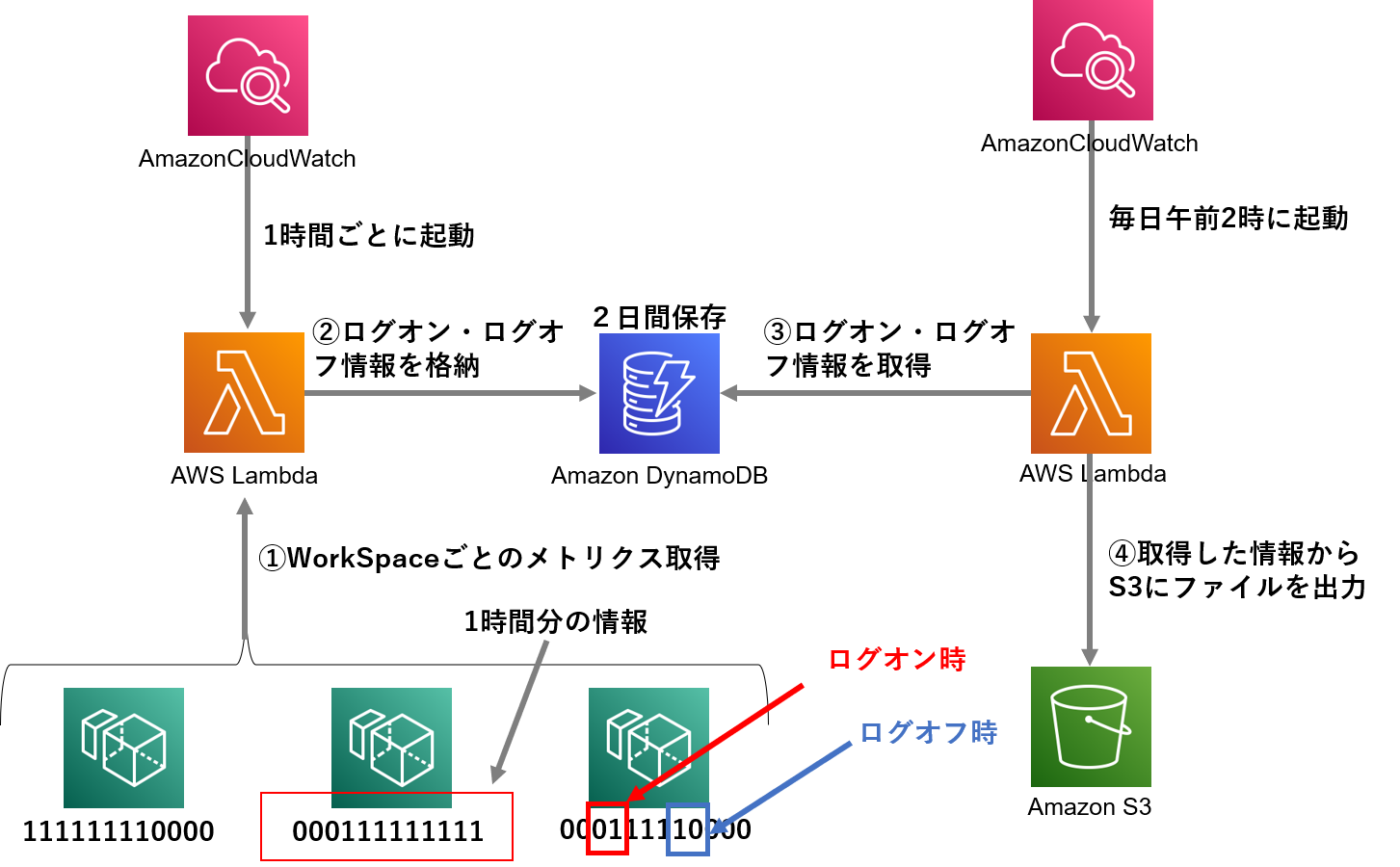
UserConnectedメトリクスがWorkSpacesにログイン・ログオフするときのデータを01で記録してくれるのでこの情報をLambdaで取得してDBに保存しておいて一日の終わりにCSVファイルとして出力する流れです。
※メトリクスが5分おきにしか出力されないため、実際のログイン・ログオフ時の時間と取得するときの時間が最大で5分程ずれる場合があります。これは仕様なので仕方ないですが。。。
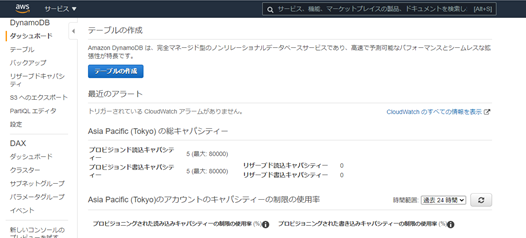
DynamoDBテーブルの作成
DynamoDBの管理画面を開き、「テーブルの作成」から作成します。
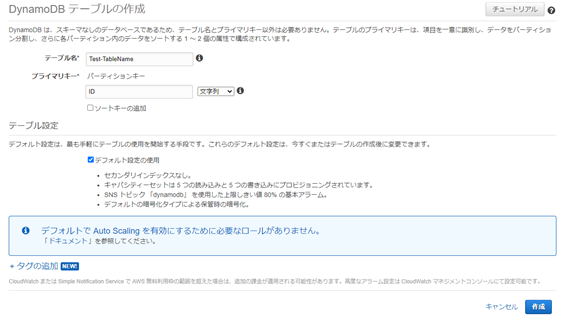
テーブル名を入力します。
プライマリキーには「ID」と入力しておきます。
テーブル設定はデフォルト設定の使用にチェックを入れ、「作成」をクリックします。
これでDynamoDBテーブルの作成は完了です。
S3バケットの作成
ファイルの出力先となるS3バケットの作成を行います。
S3管理画面からバケットの作成をクリックします。
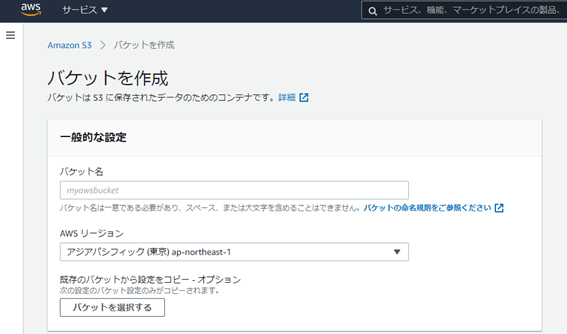
バケット名とリージョンの選択だけ設定して作成します。
Lambda用のIAMロール
IAMの管理画面を開き、左のメニューから「ロール」をクリックし、ロールの作成を行います。
信頼されたエンティティの種類を選択で「AWSサービス」を選択します。
ユースケースの選択では「Lambda」を選択し、次のステップへ進みます。
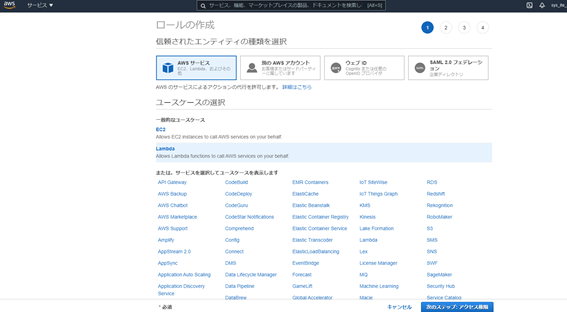
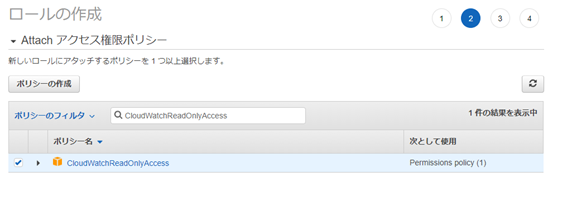
以下のポリシーを割り当てます。
・CloudWatchReadOnlyAccess
・AmazonS3FullAccess
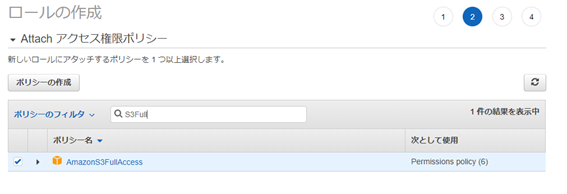
ポリシーを割り当てたら次のステップへ進みます。
ロール名を決定し、ロールを作成します。
作成したロールの管理画面を開き、「インラインポリシーの追加」をクリックします。
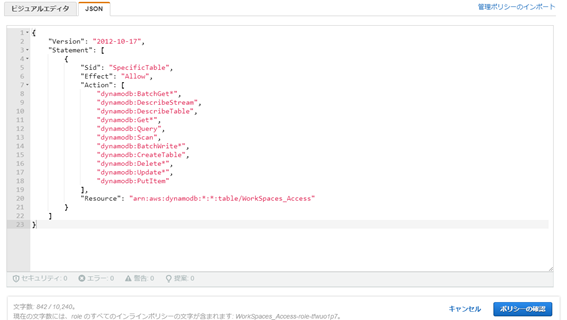
JSONタブを開き、以下ポリシーに書き換えます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SpecificTable",
"Effect": "Allow",
"Action": [
"dynamodb:BatchGet*",
"dynamodb:DescribeStream",
"dynamodb:DescribeTable",
"dynamodb:Get*",
"dynamodb:Query",
"dynamodb:Scan",
"dynamodb:BatchWrite*",
"dynamodb:CreateTable",
"dynamodb:Delete*",
"dynamodb:Update*",
"dynamodb:PutItem"
],
"Resource": "arn:aws:dynamodb:*:*:table/table-name"
}
]
}
※「table-name」には実際のDynamoDBテーブルの名前が入ります。
ポリシーの名前を入力し、ポリシーを作成します。
先程と同様の手順で以下ポリシーも作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"workspaces:*"
],
"Resource": "*"
}
]
}
ロールに合計4つのポリシーが当たっていることを確認します。
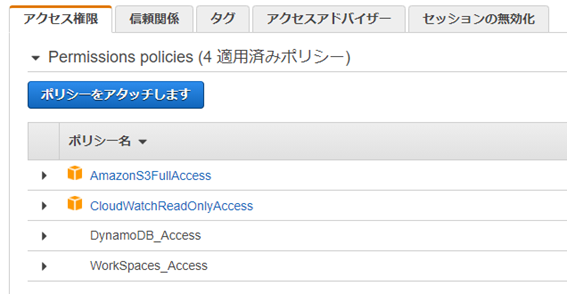
以上で、IAMロールの作成は完了です。
Lambda関数の作成(DynamoDBへの書き込み処理を行う関数)
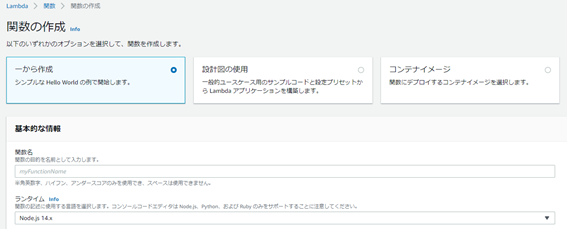
Lambdaの管理画面を開き「関数の作成」をクリックします。
「一から作成」を選択し、関数名を入力します。
ランタイムはPythonの最新バージョンのものを選択します(例:Python3.8)
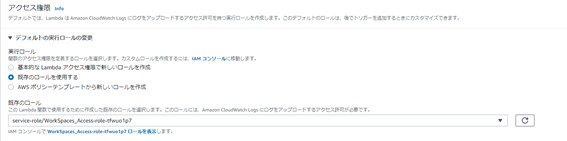
アクセス権限は「既存のロールを使用する」を選択し、先程作成したIAMロールをここで選択します。
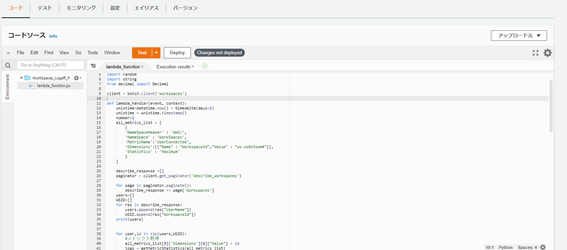
作成した関数の管理画面を開き、コードソースの欄に以下コードをコピーします。
import json
import boto3
from datetime import datetime, timedelta
from operator import itemgetter
import string
from decimal import Decimal
client = boto3.client('workspaces')
def lambda_handler(event, context):
unixtime=datetime.now() + timedelta(days=2)
unixtime = unixtime.timestamp()
number=1
all_metrics_list = [
{
'NameSpaceHeader' : 'AWS/',
'NameSpace' : 'WorkSpaces',
'MetricName':'UserConnected',
'Dimensions':[{"Name" : "WorkspaceId","Value" : "id"}],
'Statistics' : 'Maximum'
}
]
describe_response =[]
paginator = client.get_paginator('describe_workspaces')
for page in paginator.paginate():
describe_response += page['Workspaces']
users=[]
WSID=[]
for res in describe_response:
users.append(res["UserName"])
WSID.append(res["WorkspaceId"])
print(users)
for user,id in zip(users,WSID):
#メトリクス取得
all_metrics_list[0]['Dimensions'][0]["Value"] = id
logs = getMetricStatistics(all_metrics_list)
print("--------------------")
print("ユーザ名:%s" %user)
print("--------------------")
value=logs['Datapoints']
#メトリクスを時系列順にソート
SortList = []
for item in value:
SortList.append(item)
SortList = sorted(SortList, key=itemgetter('Timestamp'))
print(SortList)
metrics=[]
#値のみを抽出
for d in SortList:
#print(d)
metrics.append(d[all_metrics_list[0]["Statistics"]])
#ログオフしたタイミングを取得
for (point, num) in zip(metrics, range(12)):
LogoffTime = SortList[int(num)]['Timestamp']
#1ループ目はスルー
if num == 0:
before = point
#2ループ目から取得した値が「1から0」になる瞬間をとらえる
else:
if before==1 and point ==0:
print("User LogOff")
LogoffTime = SortList[int(num)]['Timestamp']
types="DisConnected"
#DynamoDBに書き込み
DBwrite(LogoffTime,user,id,types,number,unixtime)
number = number + 1
elif before==0 and point ==1:
print("User LogOn")
LogonTime = SortList[int(num)]['Timestamp']
types="Connected"
#DynamoDBに書き込み
DBwrite(LogonTime,user,id,types,number,unixtime)
number=number+1
before = point
def DBwrite(Time,user,wsid,types,num,unixtime):
id=datetime.now().strftime("%Y%m%d%H")
id += str(0)+str(num)
print("id:%s"%id)
table = "WorkSpaces_Access"# DynamoDBのテーブル名
Time=Time + timedelta(hours=9)
Time=Time.strftime("%Y/%m/%d %H:%M")
print(Time)
item = {
"ID": id,
"Time": Time,
"User": user,
"WorkSpacesID": wsid,
"Status": types,
"unixtime":unixtime
}
#jsonstr = json.dumps(item, default=dict)
#DynamoDBへのPut処理実行
#item = json.loads(item, parse_float=decimal.Decimal)
item=json.loads(json.dumps(item), parse_float=Decimal)
dynamo = boto3.resource('dynamodb')
dynamo_table = dynamo.Table(table)
dynamo_table.put_item(Item=item)
def getMetricStatistics(target_dict):
cloudwatch = boto3.client('cloudwatch', region_name='ap-northeast-1')
#endTime=datetime.datetime.now()
#startTime= endTime + datetime.timedelta(hours=-1)
#endTime="2021-06-23T17:00:00Z"
#startTime= "2021-06-23T15:00:00Z"
logs = cloudwatch.get_metric_statistics(
MetricName=target_dict[0]["MetricName"],
Namespace=target_dict[0]["NameSpaceHeader"] + target_dict[0]["NameSpace"],
Dimensions=target_dict[0]["Dimensions"],
StartTime=datetime.now() + timedelta(hours=-1),
EndTime=datetime.now(),
Period=300,
Statistics=[target_dict[0]["Statistics"]]
)
return logs
コピーしたら89行目のコードを作成したDynamoDBテーブルの名前に変更します。
table = "WorkSpaces_Access"
⇒ table=”[Table-Name]”
「Deploy」をクリックして設定を保存します。
以上でLambda関数(DynamoDBへの書き込み処理を行う関数)の作成は完了です。
Lambda関数の作成(S3へファイルを出力する関数)
先程と同様の手順で関数を作成します。
コードソースには以下コードをコピーします。
import json,csv
import boto3
from datetime import datetime, timedelta
csvdata=[]
def lambda_handler(event, context):
day=datetime.now() + timedelta(days=-1,hours=9)
daym=day.strftime("%Y%m%d")
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('WorkSpaces_Access')
get_data = table.scan()
data_list=get_data['Items']
num=0
for data in data_list:
id=data["ID"]
if daym in str(id).lower():
csvdata.append(data)
num+=1
print(daym in str(id).lower())
print(id)
print(csvdata)
with open("/tmp/test1.csv", 'w') as f:
writer = csv.writer(f, delimiter=',',quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
writer.writerow(["ID", "Username", "Timestamp","Status", "WorkSpacesID"])
#writer.writerow(csvdata)
#writer = csv.DictWriter(f, fieldnames=fieldnames)
#writer.writeheader()
for lis in csvdata:
id = lis['ID']
user = lis['User']
time = lis['Time']
status = lis['Status']
wsid = lis['WorkSpacesID']
writer.writerow([int(id),user,time,status,wsid])
with open ("/tmp/test1.csv", 'r') as f:
reader = csv.reader(f)
for row in reader:
print(row)
s3 = boto3.resource('s3')
s3.meta.client.upload_file('/tmp/test1.csv', 'workspaces-accesslist', 'AccessList'+daym+'.csv')
42行目の以下コードを作成したS3バケット名に編集します。
s3.meta.client.upload_file('/tmp/test1.csv','workspaces-accesslist','AccessList'+daym+'.csv')
⇒s3.meta.client.upload_file('/tmp/test1.csv','S3バケット名','AccessList'+daym+'.csv')
「Deploy」をクリックして設定を保存します。
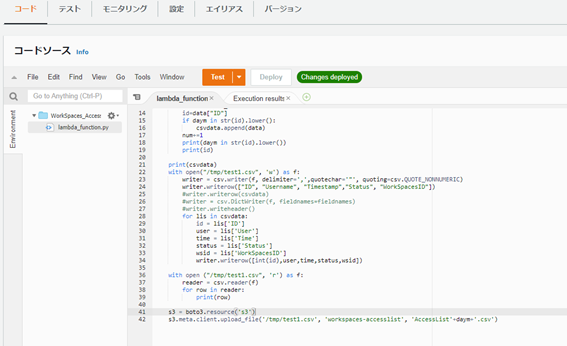
以上でLambda関数(S3へファイルを出力する関数)の作成は完了です。
CloudWatch イベントの作成
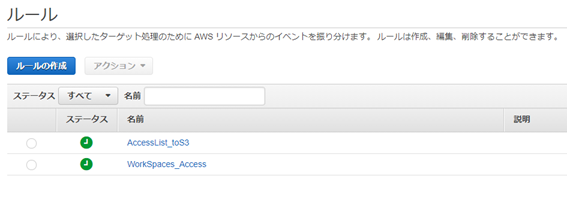
CloudWatchの管理画面を開き、左メニューからイベント>ルール をクリックします。
ルールの作成をクリックします。
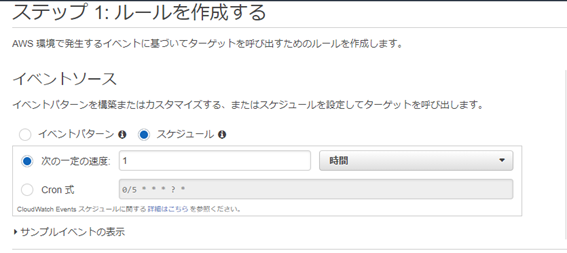
イベントソースで「スケジュール」を選択します。
「次の一定の速度」を1時間に設定します。
右側のターゲットの追加をクリックします。

ターゲットに作成したLamnda関数(DynamoDBへの書き込み処理を行う関数)を指定し、設定の詳細をクリックします。
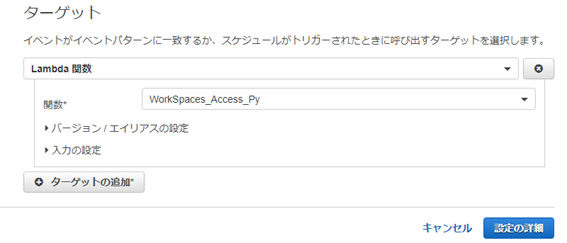
ルールの名前を入力し「有効化」にチェックを入れたまま「ルールの作成」をクリックします。
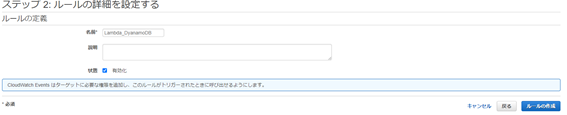
2つ目のルールの作成を行います。
先程と同様に「ルールの作成」をクリックします。
スケジュールで「Cron式」を選択し、以下の式をコピーします。
0 17 * * ? * (毎日日本時間午前2時に実行)
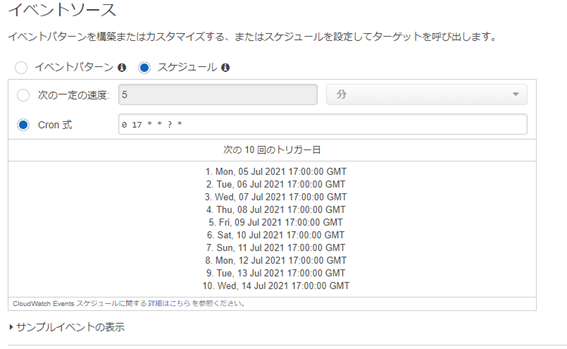
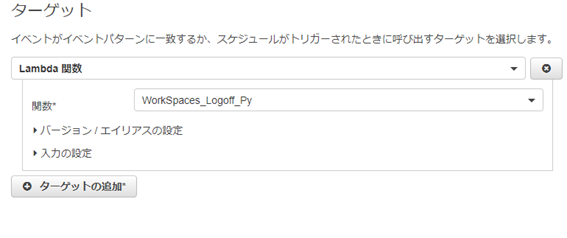
ターゲットにはLambda関数(S3へファイルを出力する関数)を指定し、設定の詳細に進みます。
名前を入力し、有効化にチェックを入れたままルールを作成します。
これで必要なものはすべてそろいました!
あとは指定の時間になればS3バケットにCSVファイルが保存されていくはず。。。
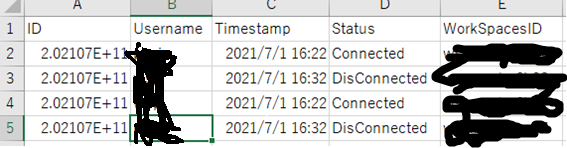
こんな感じ

CSVファイル
参考サイト:https://www.cloudsolution.tokai-com.co.jp/white-paper/2019/0614-97.html