◆深層学習 day3
0. 復習
AlexNet
AlexNetとは2012年に開かれた画像認識コンペティション2位に大差をつけて優勝したモデルである。
AlexNetの登場で、ディープラーニングが大きく注目を集めた。
5層の畳み込み層およびプーリング層など、それに続く3層の全結合層から構成される。
確認テスト
サイズ5×5の入力画像を、サイズ3×3のフィルタで畳み込んだ時の出力画像のサイズを答えよ。なおストライドは2、パディングは1とする。
答:
縦(横)サイズ=(5+2-3)/2+1 = 3
よって 3×3
1. 再起型ニューラルネットワークの概念
<概要>
RNNとは?
時系列データに対応可能な、ニューラルネットワークである。
中間層が再帰構造を持ち、前後の時刻の中間層を繋ぐ。
時間に遡って逆伝播が行われる。
時系列データとは?
RNNの全体像図

RNNの数学的記述
$u^t = W_{(in)}x^t + W z^{t-1} + b$
$\ z^t = f(u^t)$
$v^t = W_{(out)}z^t + c$
$y^t = g(v^t)$
BPTTとは?
確認テスト
<確認テスト1>
RNNのネットワークには大きくわけて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
答:残る1つの重みは、前の中間層から現在の中間層を定義する際にかけられる重みである。
<確認テスト2>
連鎖律の原理を使い、dz/dxを求めよ。
答:
微分の連鎖率は
$\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}$
$\frac{dz}{dt}=2t$
$\frac{dt}{dx}=1$
より
$\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}=2t\times 1=2(x+y)$
<確認テスト3>
下図のy1をx1,s0,s1,win,w,woutを用いて数式で表わせ。また、中間層の出力にシグモイド関数を作用させよ。
答:
$z_1=sigmoid \left( s_0 W+x_1W_{in}+b \right)$
$y_1=sigmoid \left( z_1 W_{out}+c \right)$
演習
「3_1_simple_RNN.ipynb」を使用して演習
・weight_init_stdやlearning_rate, hidden_layer_sizeを変更してみよう
・重みの初期化方法を変更してみよう Xavier, He
・中間層の活性化関数を変更してみよう
■初期設定時
weight_init_std = 1、learning_rate = 0.1、hidden_layer_size = 16の場合
Loss:0.00036944179324640213
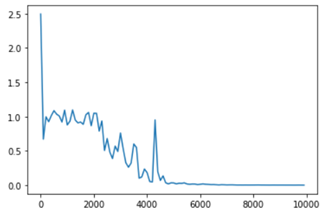
学習初期はまったく計算できていないが中盤以降正しく計算されている。
学習初期
iters:0
Loss:2.495287446169305
Pred:[1 1 1 1 1 1 1 1]
True:[0 1 1 0 0 0 0 0]
90 + 6 = 255
----------
iters:100
Loss:0.670924829282013
Pred:[1 1 1 0 0 0 0 0]
True:[1 1 1 0 0 0 0 0]
100 + 124 = 224
学習終盤
iters:9800
Loss:0.0009113598085292483
Pred:[0 1 1 1 0 1 0 1]
True:[0 1 1 1 0 1 0 1]
55 + 62 = 117
----------
iters:9900
Loss:0.00036944179324640213
Pred:[1 0 0 1 0 0 1 0]
True:[1 0 0 1 0 0 1 0]
77 + 69 = 146
----------
■ weight_init_std = 1、learning_rate = 0.5、hidden_layer_size = 16の場合
Loss:0.00011130339656977336

■ weight_init_std = 5、learning_rate = 0.1、hidden_layer_size = 16の場合
Loss:0.26565063715142545

■ weight_init_std = 1、learning_rate = 0.1、hidden_layer_size = 32の場合
Loss:0.0005047485425984668

■ 重みの重みの初期化方法をXavierに変更
# Xavier
W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size))
W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size))
W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size))
Loss:0.0019408171865118262

■ 重みの初期化方法をHeに変更
# He
W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size)) * np.sqrt(2)
W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
Loss:0.0016985682208860195

■ 中間層の活性化関数をReLUに変更してみる
以下の4か所を変更した。
z[:,t+1] = functions.relu(u[:,t+1])
y[:,t] = functions.relu(np.dot(z[:,t+1].reshape(1, -1), W_out))
delta_out[:,t] = functions.d_mean_squared_error(dd, y[:,t]) * functions.d_relu(y[:,t])
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_relu(u[:,t+1])
Loss:1.0
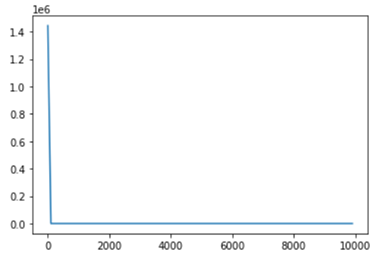
予測値がすべて0であり、学習が全く進んでいない。
プログラム修正誤りなのでしょうか?
2. LSTM
<概要>
RNNの課題として時系列を遡れば遡るほど勾配が消失していくため、長い時系列の学習が困難なことがあげられる。
解決策として構造自体を変えて解決したものがLSTMである。
LSTM(Long short-term memory)はRNNの一種であり、RNNの再帰構造を持つ隠れ層をLSTMブロックで置き換えている。
LSTMブロックには、CEC(Constant Error Carousel)と入力ゲート・出力ゲート・忘却ゲートの3つのゲートで構成されている。
CEC
答: 0.25
<確認テスト2>
以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測においてなくなっても影響を及ぼさないと考えられる。このような場合、どのゲートが作用すると考えられるか。
答: 忘却ゲート
3. GRU
<概要>
従来のLSTMでは、パラメータが多数存在していたため、計算負荷が大きいという課題があった。
GRU(Gated recurrent unit)はゲート付き回帰型ユニットと呼ばれ、LSTMをシンプルにしたモデルにあり、LSTMより高速に動作する。
GRUでは、そのパラメータを大幅に削減し、精度は同等またはそれ以上が望める様になった。
確認テスト
<確認テスト1>
LSTMとCECが抱える課題について、それぞれ簡潔に述べよ。
解答:
LSTM:パラメータ数が多く、計算負荷が高い
CEC:ニューラルネットワークの学習特性がない
<確認テスト2>
LSTMとGRUの違いを簡潔に述べよ。
答:
LSTMでは、パラメータが多数存在していたため、計算負荷が大きかったが、GRUでは、パラメータを大幅に削減し、精度は同等またはそれ以上が望める様になっており、計算負荷が低い。
4. 双方向RNN
<概要>
時間軸に対して未来方向と過去の方向のRNNを組み合わせたものを双方向RNNと呼ぶ。
過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデルである。
実用例:文章の推敲や、機械翻訳等
確認テスト
<確認テスト1>

答:4
5. Seq2Seq
<概要>
seq2seqはEncoder-Decoderモデルの一種であり、データを解くように変換するEncoderと、特徴を新しいデータに変換するDecoderを組み合わせたものである。自然言語用のモデルである。
seq2seqは英語を日本語に置き換えたり、質問を回答に置き換えるルールを学習することができる。
具体的な用途は機械対話や機械翻訳などである。
Encoder RNN
オートエンコーダ具体例:
MNISTの場合、28x28の数字の画像を入れて、同じ画像を出力するニューラルネットワークということになります
オートエンコーダの構造:
入力データから潜在変数zに変換するニューラルネットワークをEncoder
逆に潜在変数zをインプットとして元画像を復元するニューラルネットワークをDecoder。
メリット:次元削減が行えること
答:(2)
<確認テスト2>
VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
答:確率分布
<確認テスト3>
Seq2SeqとHRED、HREDとVHREDの違いを簡潔に述べよ。
答:
Seq2SeqとHREDの違い: Seq2Seqは一問一答しかできないが、HREDは過去n−1個の発話から文脈に応じた回答ができる。
HREDとVHREDの違い: HREDは発話に多様性がなく情報量に乏しいが、VHREDはそれらの課題を解決し、多様性ある発話ができる。
6. Word2vec
<概要>
・単語をベクトル表現する手法。単語間の関係性を捉えつつベクトル化するのが特徴。
・与えられた文章中の単語(文字列)をベクトルとして表現することで演算を可能にしている。
・ベクトル化した単語を単語ベクトルと呼び、この単語のベクトルの値を足したり引いたりすることで単語の意味関係を捉えることができる。
・大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能となった。
7. Attention Mechanism
<概要>
・seq2seq の問題は長い文章への対応が難しいことである。
→2単語でも、100単語でも、固定次元ベクトルの中に入力しなければならない。
・解決策として文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要となる。
・Attention Mechanismは「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組み。
確認テスト
<確認テスト1>
RNNとword2vec、seq2seqとAttentionの違いを簡潔に述べよ。
答:
RNNとWord2vecの違い:RNNは時系列データを処理するのに適したNNであり、Word2vecは単語の分散表現ベクトルを得る手法。
seq2seqとAttentionの違い:Seq2Seqは一つの時系列データから別の時系列データを得るネットワークであり、Attentionは時系列の中身に対して、関連性に重みをつける手法。
◆深層学習 day4
1. 強化学習
長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野
行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく

<強化学習の応用例>
マーケティングの場合
環境: 会社の販売促進部
エージェント: プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアである。
行動: 顧客ごとに送信、非送信のふたつの行動を選ぶことになる。
報酬: キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける。
・ある状態を入力として次の行動を出力する関数を方策関数と呼ぶ。
・エージェントが選択した行動の最終的な報酬の期待値をQ値(状態行動価値)と呼び、強化学習ではQ値が最大になるように学習する。
Q値を求める関数をQ関数(状態行動価値関数)と呼ぶ。
・Q学習は最初に設定されているQ値と、実際に行動して得られるQ値の期待値との差をQ値に反映させる手法。
価値関数
価値を表す関数としては「状態価値関数」と「行動価値関数」の2種類がある。
ある状態の価値に注目する場合は、状態価値関数
状態と価値を組み合わせた価値に注目する場合は、行動価値関数
方策関数
方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数
2. AlphaGo
・AlphaGoはコンピュータ囲碁プラグラムであり、教師あり学習と強化学習の併用により作られたモデルである。
・AlphaGoはモンテカルロ法を取り入れており、報酬を得たタイミングで今までに行った行動のQ値を一気に更新する。
AlphaGoの学習は以下のステップで行われる
- 教師あり学習によるRollOutPolicyとPolicyNetの学習
- 強化学習によるPolicyNetの学習
- 強化学習によるValueNetの学習

PolicyNetの教師あり学習
KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った。
具体的には、教師が着手した手を1とし残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。
この学習で作成したPolicyNetは57%ほどの精度である。
PolicyNetの強化学習
現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行った。
PolicyPoolとは、PolicyNetの強化学習の過程を500Iteraionごとに記録し保存しておいたものである。
現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ごうというのが主である。
この学習をminibatch size 128で1万回行った。
ValueNetの学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習した。
教師データ作成の手順は
1、まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。
2、N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。
3、S(N+1)からRLPolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
S(N+1)とRを教師データ対とし、損失関数を平均二乗誤差とし、回帰問題として学習した。
この学習をminibatch size 32で5000万回行った
N手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されている
モンテカルロ木探索
コンピュータ囲碁ソフトでは現在もっとも有効とされている探索法。
他のボードゲームではminmax探索やその派生形のαβ探索を使うことが多いが、盤面の価値や勝率予想値が必要となる。しかし囲碁では盤面の価値や勝率予想値を出すのが困難であるとされてきた。
そこで、盤面評価値に頼らず末端評価値、つまり勝敗のみを使って探索を行うことができないか、という発想で生まれた探索法である。囲碁の場合、他のボードゲームと違い最大手数はマスの数でほぼ限定されるため、末端局面に到達しやすい。
具体的には、現局面から末端局面までPlayOutと呼ばれるランダムシミュレーションを多数回行い、その勝敗を集計して着手の優劣を決定する。
また、該当手のシミュレーション回数が一定数を超えたら、その手を着手したあとの局面をシミュレーション開始局面とするよう、探索木を成長させる。
この探索木の成長を行うというのがモンテカルロ木探索の優れているところである。
モンテカルロ木探索はこの木の成長を行うことによって、一定条件下において探索結果は最善手を返すということが理論的に証明されている。
AlphaGoZero
AlphaGOZeroは教師あり学習を一切行わず、セルフプレイによる強化学習のみで作成されたモデル。
AlphaGo(Lee) とAlphaGoZeroの違い
1、教師あり学習を一切行わず、強化学習のみで作成
2、特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3、PolicyNetとValueNetを1つのネットワークに統合した
4、Residual Net(後述)を導入した
5、モンテカルロ木探索からRollOutシミュレーションをなくした
Alpha Go Zeroの学習法
Alpha Goの学習は自己対局による教師データの作成、学習、ネットワークの更新の3ステップで構成される
<自己対局による教師>
データの作成現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。
まず30手までランダムで打ち、そこから探索を行い勝敗を決定する。
自己対局中の各局面での着手選択確率分布と勝敗を記録する。
教師データの形は(局面、着手選択確率分布、勝敗)が1セットとなる。
<学習>
自己対局で作成した教師データを使い学習を行う。
NetworkのPolicy部分の教師に着手選択確率分布を用い、Value部分の教師に勝敗を用いる。
損失関数はPolicy部分はCrossEntropy、Value部分は平均二乗誤差。
<ネットワークの更新>
学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
3. 軽量化・高速化技術
データ並列化
親モデルを各ワーカーに子モデルとしてコピー、データを分割し、各ワーカーごとに計算させることをデータ並列化と呼ぶ。
データ並列化:同期型
データ並列化:非同期型
GPUによる高速化
GPGPU (General-purpose on GPU)
元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
CPU
高性能なコアが少数
複雑で連続的な処理が得意
GPU
比較的低性能なコアが多数
簡単な並列処理が得意
ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
軽量化
1.量子化
4. 応用モデル
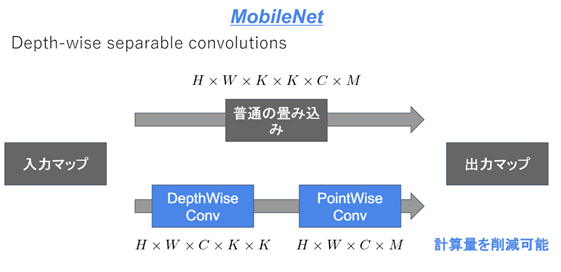
MobileNet
Depthwise Separable Convolution (Depthwise ConvolutionとPointwise Convolution)という仕組みを用いて画像認識において軽量化・高速化・高精度化したモデル。
通常の畳込みが空間方向とチャネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise ConvolutionとPointwise Convolutionと呼ばれる演算によって個別に行う。
DenseNet

正規化
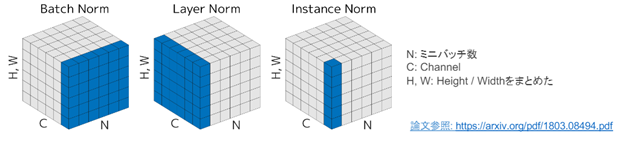
Batch Norm
ミニバッチに含まれるsampleの同一チャネルが同一分布に従うよう正規化
Layer Norm
それぞれのsampleの全てのpixelsが同一分布に従うよう正規化
Instance Nrom
さらにchannelも同一分布に従うよう正規化


WaveNet
生の音声波形を生成する深層学習モデル
Pixel CNNを音声に応用したもの
時系列データである音声に畳込みニューラルネットワーク(Dilated Convolution)を適用する

確認テスト
<確認テスト1>
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNet の大きな貢献の1 つである。提案された新しいConvolution 型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。
答:(あ)Dilated causal convolution
<確認テスト2>
(あ)を用いた際の大きな利点は、単純なConvolution layer と比べて(い)ことである。
答:(い)パラメータ数に対する受容野が広い
5. Transformer
TransfomerはEncoder-DecoderとAttention機構を組み合わせ、最後に全結合層を経て翻訳結果を返すモデルである。
RNNを一切使っておらず、並列化が容易であるため、訓練時間を大幅に短縮することが可能となった。
・2017年6月に登場 - RNNを使わない
・ 必要なのはAttentionだけ
・ 当時のSOTAをはるかに少ない計算量で実現
・ 英仏 (3600万文) の学習を8GPUで3.5日で完了

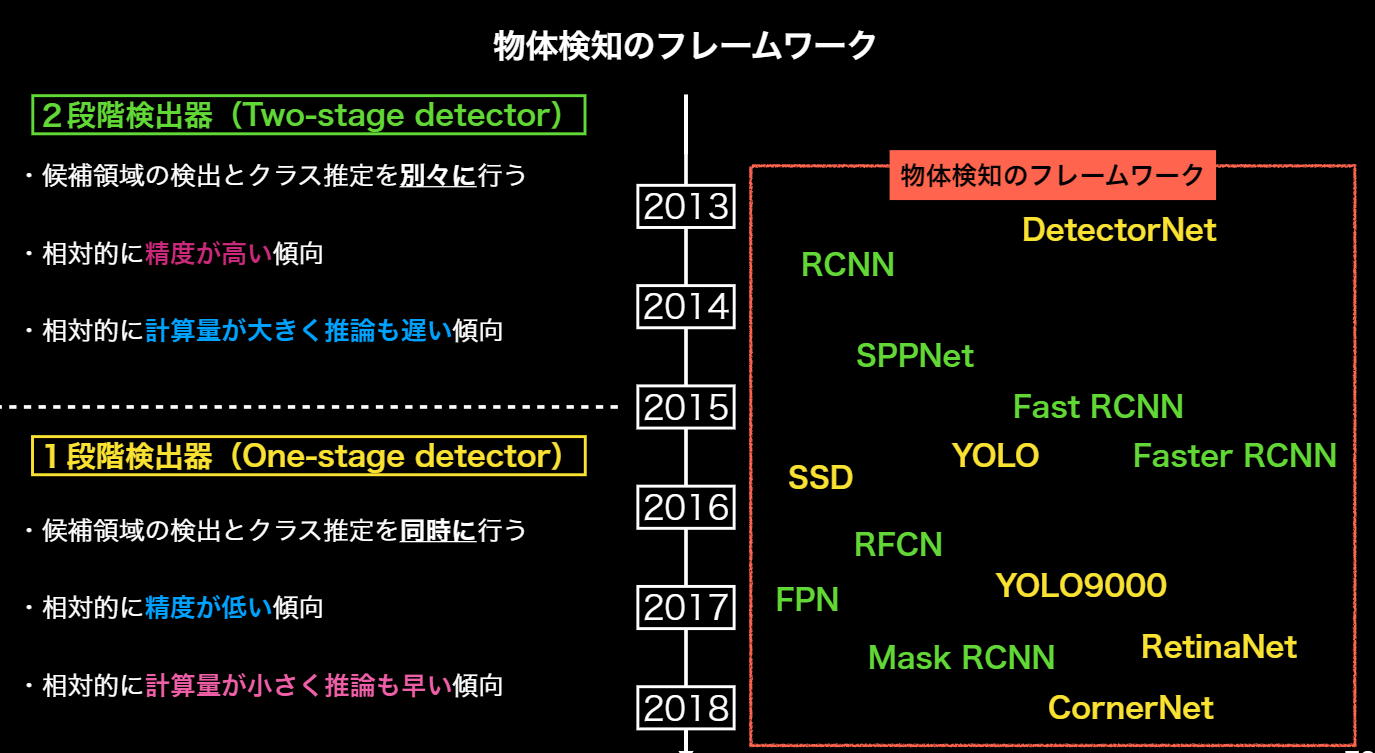
6. 物体検知・セグメンテーション
<概要>
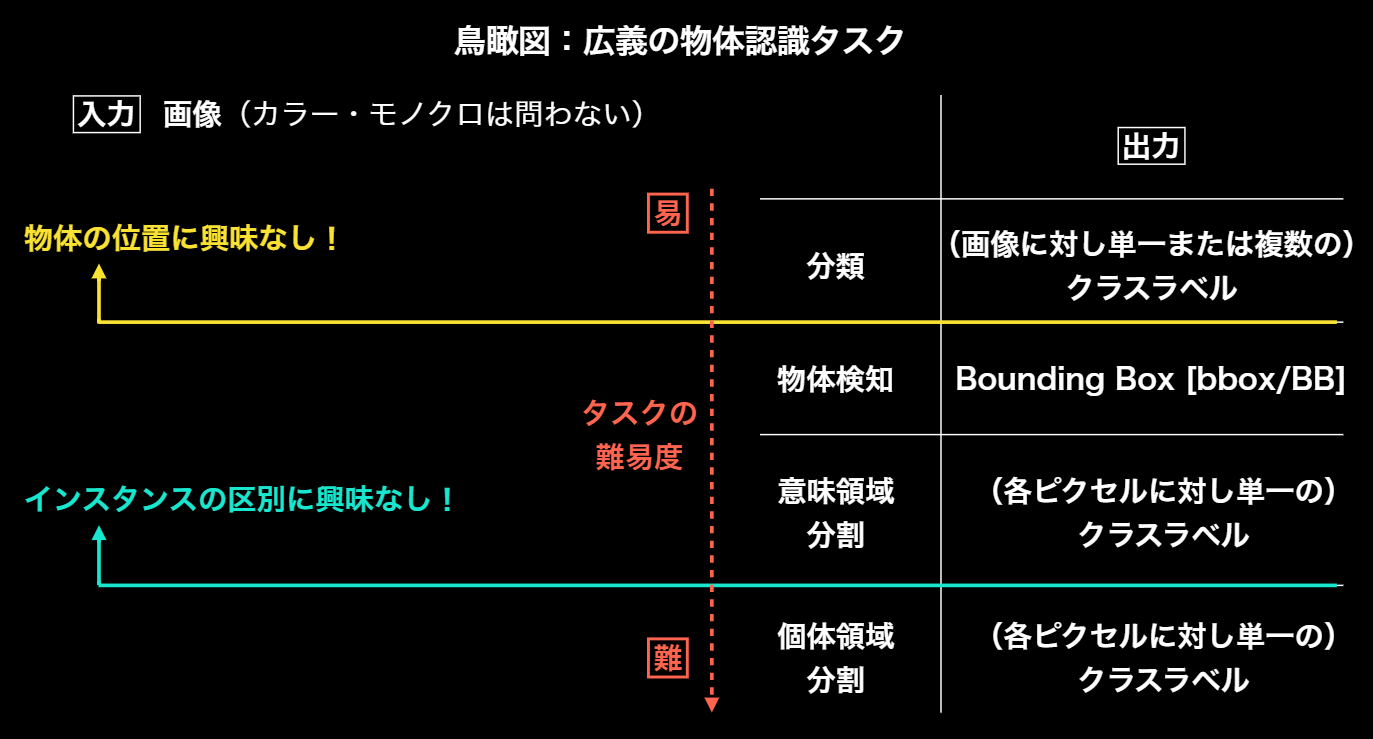
物体検知では入力画像に対して、物体検出位置であるBounding Box、ラベル、コンフィデンスの3つを併せて出力するのが一般的である。
広義の物体認識タスクとしては、分類・物体検知(バウンディングボックス)・意味領域分割・個体領域分割に分かれる
物体検知において代表的なデータセットにVOC12、ILSVRC17、MS COCO18、OICOD18などがある。
この中でILSVRC17以外は物体個々にラベルが与えられている。
分類問題の評価指標として混合行列がよく用いられるが、この概念を物体検出のクラスラベルだけでなく、物体位置の予測精度評価にも用いることができる。
すなわち、IoU(Intersection over Union 別名:Jaccard係数)を用いる。
定義式は
IoU=\frac{TP}{TP+FN+FP+TN}

物体検知のフレームワーク