はじめに
Azure Cognitive Servicesで提供されているSpeech serviceを使って音声テキスト変換機能を実装する機会があったので、簡単にご紹介したいと思います!
そもそもSpeech Service とは
Speech Serviceとは音声テキスト変換、テキスト読み上げ、音声翻訳を Azureが提供するSpeech CLI、Speech SDK、REST API などを使って簡単にWebアプリ、ツール、デバイスに実装することが出来る便利なサービスです。
音声テキスト変換が提供する機能
以下のような機能が提供されています。
・リアルタイムの音声テキスト変換
オーディオ ストリームまたはローカル ファイルからテキストへの文字起こしまたは翻訳をリアルタイムで行います。
・一括音声テキスト変換
Azure Blob Storage に格納された大量の音声データに対して、音声からテキストへの文字起こしを非同期で行うことができます。
・会話の文字起こし
リアルタイムの音声認識、話者識別、およびダイアライゼーションが有効になります。 話者を区別することができるため、対面会議の文字起こしに最適です。
また、他にも発音や評価する機能やカスタム音声モデルの作成機能などがあります。
音声テキスト変換機能を実装してみる。
音声ファイル(wav形式)をローカル上でテキストに変換してみる。
■実行環境
macOS
python3.8
■実行準備
①Azure sppechサービスの作成。
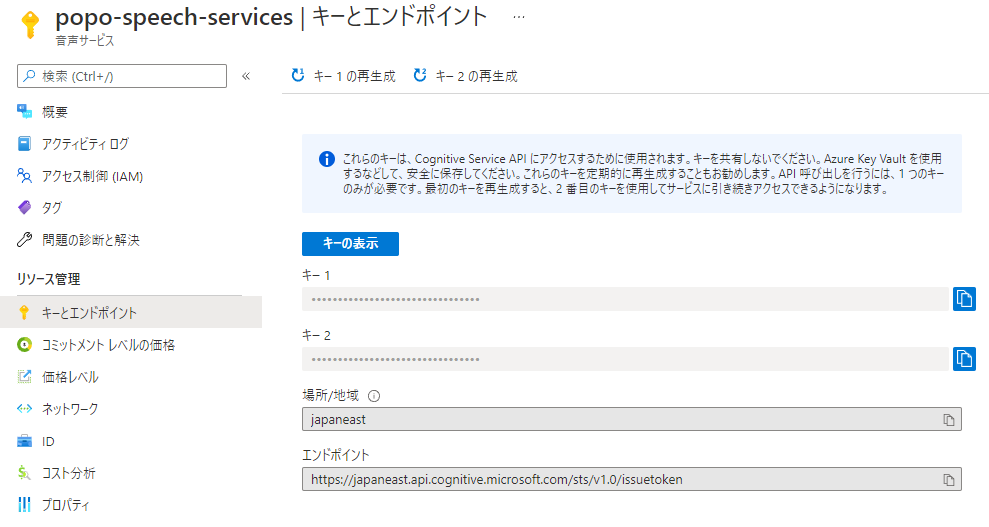
Azure portalへログインしてCognitive Servicesの音声サービスを立ち上げます。

音声サービスのデプロイが完了したら、サブスクリプションキーと地域(リージョン)を控えます。(コードを実行する際に利用するため)
②音声ファイルの準備
・wav形式の音声ファイルを用意します。
③音声変換コードの準備
・下記コードを実行環境に用意します。
import azure.cognitiveservices.speech as speechsdk
import os
# 音声サービスの接続情報
speech_subscription = "<サブスクリプションキーを格納>"
speech_region= "<サービスのリージョンを格納>"
language = "ja-JP"
# 音声ファイルのパス
voice_file = "<音声ファイルのパスを格納>"
def voice_to_text():
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription, region=speech_region,speech_recognition_language=language)
audio_input = speechsdk.AudioConfig(filename=voice_file)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
result = speech_recognizer.recognize_once_async().get()
return result.text
print("音声ファイルの変換を実行中")
text = voice_to_text()
print("音声ファイルの出力:",text)
print("処理終了")
■実行結果の確認
% python3.8 voice-to-text.py
音声ファイルの変換を実行中
音声ファイルの出力: 天気は晴れです。
%
問題なく、音声ファイルからテキストに起こされていることを確認できました!
今回は非同期の音声テキスト変換でしたので、次回はリアルタイムでの音声テキスト変換をやってみようと思います。