はじめに
Amazon Bedrock面白いですね、最近ずっと触ってます。
BedrockではChat-GPTのようなチャットでの会話だったり、音声認識・画像生成等様々な生成AIを使用する事ができますが、その中の一つであるRAG (Retrieval Augmented Generation) を構築する方法について、詳しくご紹介したいと思います。
RAG1 は、大規模言語モデルの回答精度を向上させる強力な手法ですが、その実装方法にはいくつかの選択肢があります。それぞれの特徴やコスト面での違いを見ていきましょう。
RAGとは?
構成を考える前にまずRAGについて、簡単に説明させていただきます。
RAGとは「Retrieval Augmented Generation」の略で、日本語では「検索拡張生成」と訳されます。
これは、大規模言語モデル(LLM)2の回答生成能力と、外部知識ベースからの情報検索を組み合わせた技術です。
RAGの魅力は、LLMの創造性と、正確な最新情報を組み合わせられる点にあります。例えば、「2024年の東京の人口は?」という質問に対して、LLM単体では古い情報を元に回答してしまう可能性(ハルシネーション)がありますが、RAGを使えば最新のデータベースから正確な情報を取得し、それを基に回答を生成します。
RAGを構成する部品について
一言でRAGとはいっても、様々なコンポーネントを用いて構成を行います。
以下はRAGアーキテクチャの実装例です。
ユーザー
↓
アプリケーション(入力)
↓
埋め込みモデル
↓
ベクトルDB
↓
LLM
↓
アプリケーション(出力)
↓
ユーザー
-
アプリケーション
その名の通りのアプリケーションです。
ユーザーからの入力を受け付け、後方の埋め込みモデル・ベクトルDB・LLMとのやり取りを中継します。
ECSやLambdaで構成を行い、PythonやTypeScript等色々な言語で作成を行います。 -
埋め込みモデル
ユーザーからの質問をベクトル変換します。
まず埋め込みモデルってなんやねん?というところからだと思うのですが、かなり端折った感じにいうと、・ 埋め込みモデルは、単語や文章を数値のベクトルに変換する技術 ・ ベクトルは、数値の並びであり、単語や文章の意味や関係性を数値で表現したものという事らしいです。
詳しくはEmbedding(エンベディング:埋め込み、埋め込み表現)とは? を参照して下さい。埋め込みモデルは多種多様にありますが、Bedrock上で使用できるモデルではCohereの「Embed Model - Multilingual」がよく耳にするかと思います。
-
ベクトルDB
埋め込みモデルで出力された値を格納するためのDBです。
AWSサービスでメジャーなところだと「Aurora」や「OpenSearch」がよく使用されます。
また、コストを下げるために外部DBとして「Pinecone3」を用いる方法もあります。
-
LLM
今までで出力してきた内容をもとにLLMで回答を生成します。
メジャーなモデルとしてはAnthropicの「Claude」が考えられます。
と言うように様々なコンポーネントを用いてRAGは作成されているのです。
RAGを構成する
ここからはRAGの構成例について様々なパターンで紹介させていただきます。
埋め込みモデルやLLMはほぼ決まっているような物だと思うので、ベクトルDBに焦点を当てて記載させていただきます。
- パターン1:Kendraを使った方法
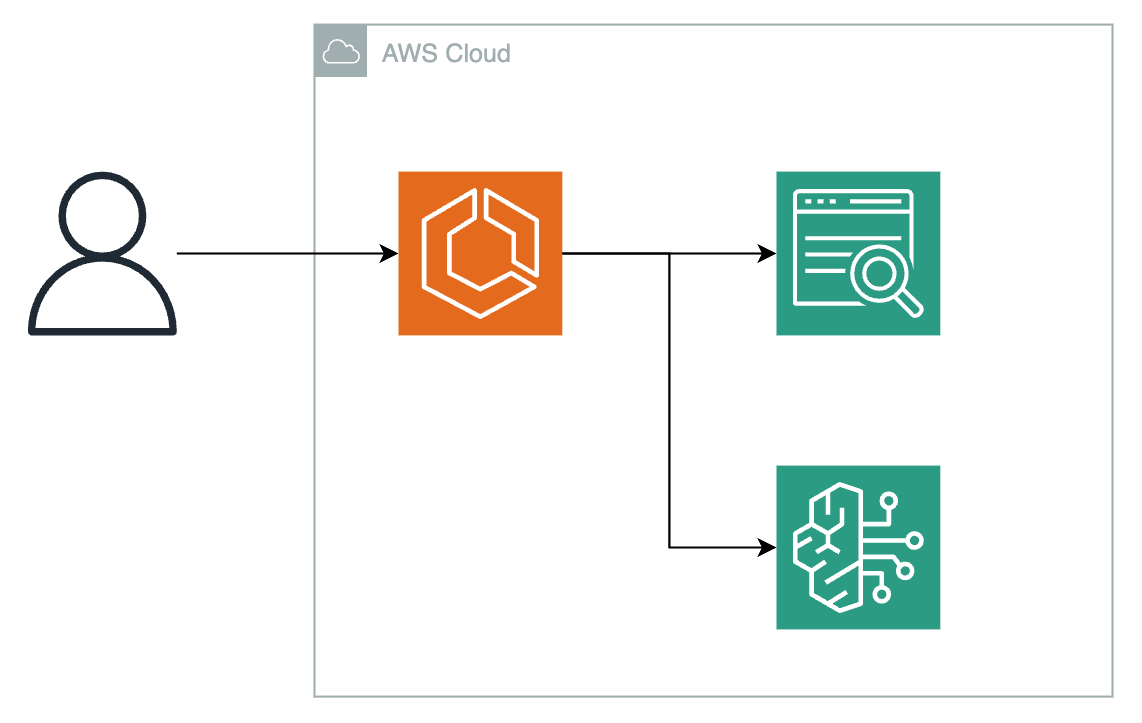
色々な意味で最強な構築方法です。
構築もKendraとBedrockを使用するだけで他の設定は特に必要としません。
Kendraを用いる方法としてのメリットとして
- AWSサービスやサードパーティ等の多数のデータソースを検索対象とできる
- 構築が簡潔。また、マネージドサービスなので管理をする必要がない
などのメリットが挙げられます。
ただし、かかるコスト4も最強です。
Bedrockはそこまでコストが発生しないので、Kendraのみで考えてみます。
Kendraには以下の通り2つのEditionが存在します。
- Developer Edition
- Enterprise Edition
そして、それぞれでかかるコストは以下の通りです。
- Developer Edition
1時間:1.125USD
1ヶ月:810USD - Enterprise Edition
1時間:1.4USD
1ヶ月:1008USD
ざっと考えるだけでも月10万を軽く超えてきます。
その為、よほどKendraでないとダメな事情がない限りおすすめはしない構成です。
- パターン2:OpenSearch Serverlessを使った方法
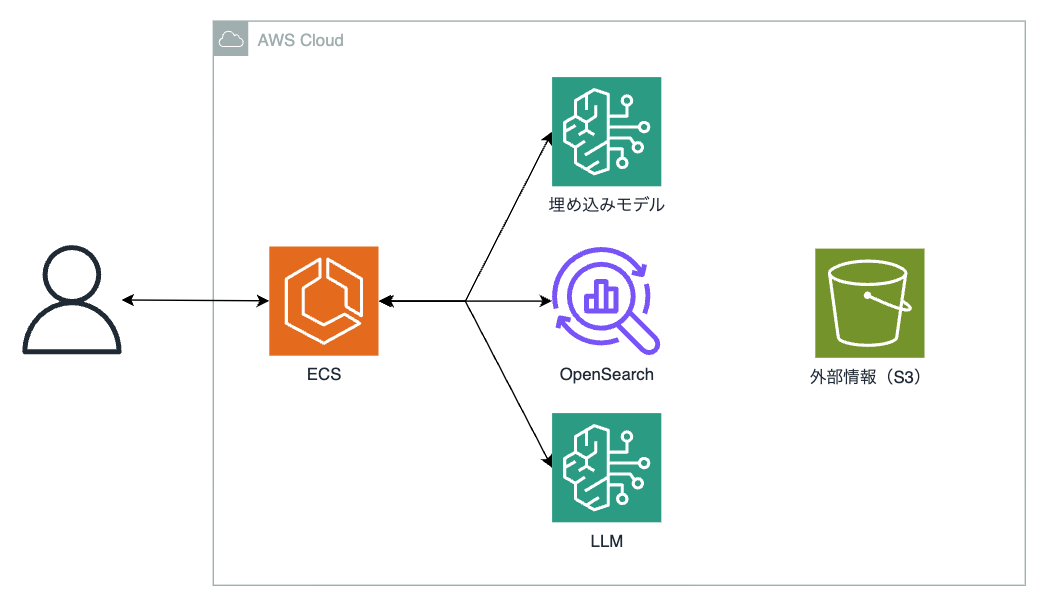
高額なコストを発生させるKendraを抜き、代わりのベクトルDBとしてOpenSearch Serverlessを取り入れた構築方法となっています。
OpenSearch Serverlessを取り入れた方法のメリットとして
- Knowledge basesを使用して作成する場合、クイック作成が対応している為、DBへ接続するための認証等をAWS側がやってくれる
- Serverlessモデルなので、リソースのプロビジョニングや管理をAWSに任せれる
などのメリットが挙げられます。
ただし、OpenSearchを使用した事がある方はすでに理解されているかと思いますが、KendraまでとはいかずともOpenSearch自体もコスト5は比較的高額です。
ですが、後述するAuroraやPineconeではDBの構築や接続方法の確立が必要となりますが、それらをする必要がないと言うメリットは結構大きいと思います。
- パターン3:Auroraを使った方法
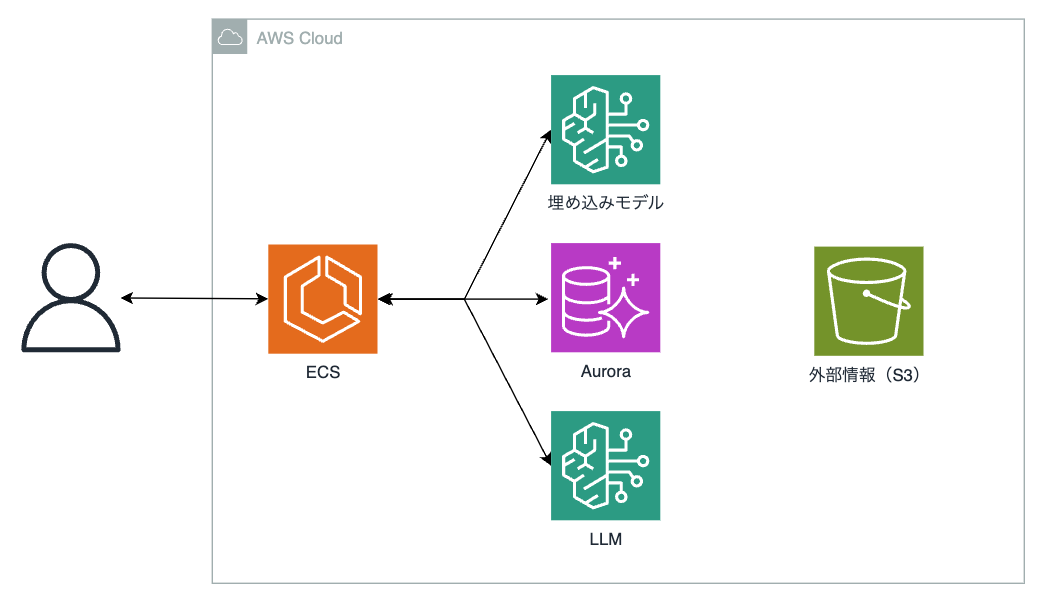
ここではAuroraと記載しましたが、RDSを用いた方法でも問題ないです。
RDBMSはPostgreSQLを用い、拡張機能である「pgvector」と言うベクトルデータを使用してベクトルDBとして昇格させます。
ちなみに、RDSやAuroraがpgvectorをサポートしたのは2023年のことなのでつい最近利用できるようになりました。
Auroraを用いる方法としてのメリットとして
- マネージドサービス
- 容量が枯渇した場合、自動的にスケールを行ってくれる
- 複数AZに跨ってインスタンスが構築される為、高可用性に優れている
- KendraやOpenSearhに比べてかなりコストがかからない
- Aurora Serverlessを選択した場合、より安価にすることも可能
などのメリットが挙げられます。
ただし、デメリットとしてKnownledge BasesではOpenSearchのようにクイック作成はできません。その為、Auroraを用いる場合は事前にAuroraクラスターを作成、pgvectorのセットアップ、スキーマやロール、テーブル等の作成は自分で行う必要があります。
- パターン4:Pineconeを使った方法
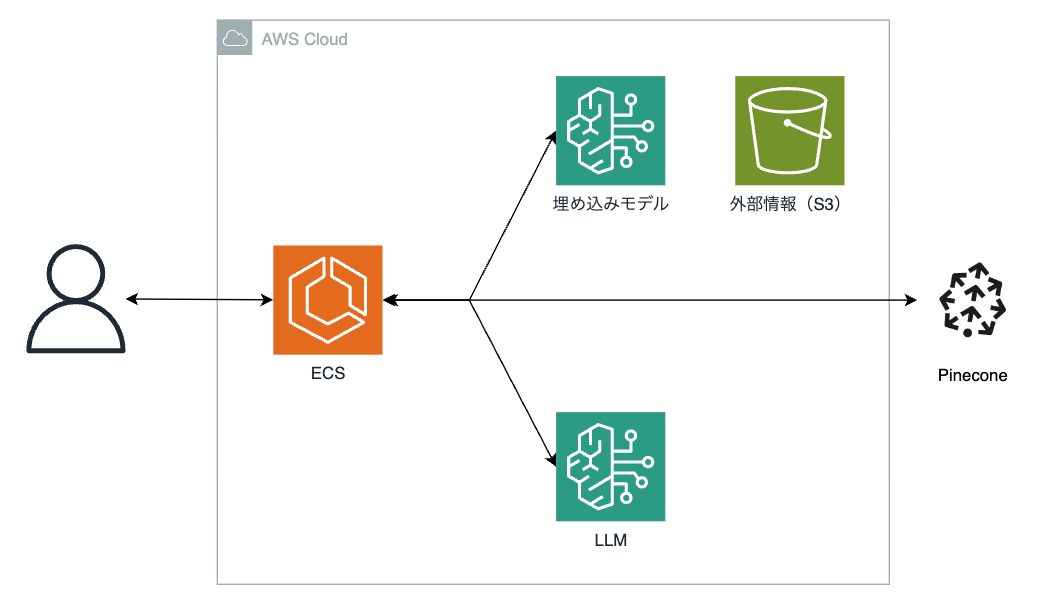
AWSのサービスではないですが、AWS Marketplaceで提供されているPineconeを用いた方法での構築方法となっています。
AWS MarketplaceとはAWS上で動作するサードパーティ製品を調達し、一元管理が可能となっているプラットフォームです。代表的なところで言うと、「CentOS」や「SUSE」、「WindowsServer」等もMarketplace上にあり、サブスクリプションとして契約を行うことが可能です。
Pineconeを用いる方法としてのメリットとして
- とにかく安価。無料プランも用意されている
- マネージドなベクトルDBとなっている
- Pinecone創業者がAWSの中の人なので、AWSをクラウドプロパイダーとして選択が可能 + AWS PrivateLinkでの閉鎖接続も限定的6に可能
などのメリットが挙げられます。
ただし、AWSサービスではないので環境構築が非常に大変です。
- Marketplaceでサブスク契約をする
- PineconeでIndexを作成
- Knownledge BasesでPineconeとの接続
- etc..
その為構築までが大変なのはちょっと・・・と言う方にとっては不便かもしれないです。
その分コストは非常に低額なので、ここは天秤にかけて考えていただけると幸いです。
ここまでの話を分かりやすいように表にまとめておきます。
| 比較 | Kendra | OpenSearch | Aurora | Pinecone |
|---|---|---|---|---|
| 料金 | 非常に高い | 高い | 普通 | 安い |
| データソース | S3やRDSの他複数のSaaS | S3 | S3 | S3 |
| 東京リージョンへの対応 | あり | あり | あり | 現状はなし |
| 構築の大変さ(個人差あり) | 非常に簡単 | 普通 | 少々大変 | 非常に大変 |
最後に
今回はRAGの構築方法についてご紹介させていただきました。ベクトルDBは他にも複数あり、DocumentDBやMemoryDBを使った方法、サードパーティであるRedisを使った方法等多種多様に存在します。
その為、使用する環境でハマるものを選択し、構築することをおすすめします。
また、アプリケーションも今回はECSとLambdaを例に挙げて記載しましたが、他にもStepFunctionsやAmplifyで構築する事も可能ですので、もし気になる方は試してみてはいかがでしょうか?
Bedrock、奥が深いです。
-
https://www.nri.com/jp/knowledge/glossary/lst/alphabet/rag#:~:t ↩
-
https://www.hitachi-solutions-create.co.jp/column/technology/llm.html ↩
-
現状Enterpriseプランでのみ使用可能。またプレビュー版なので今後変更になる可能性もある。 ↩