概要
実験データを単純な直線ではなく、複雑な関数式でフィットしそのフィッティングパラメータを取得したいことがあります。(特に化学系は)
excelやその他さまざまなソフトウェアがありますが、今回はPythonのScipyを用いてプロットする方法を紹介します。
scipy.optimize.curve_fitは、非線形最小二乗法(Nonlinear Least Squares) を使ってデータに関数をフィッティング(近似)する関数となります。
フィッティング関数
化学系なら多くの方が知っている以下のArrheniusの式でフィッティングを行い、そのフィッティング結果から$A$および$E_a$を求めるという方針で行きます。Arrheniusの式は以下のような式です。
$$
k = A \exp\left(\frac{-E_a}{RT}\right)
$$
- $k$:反応速度定数
- $A$:頻度因子
- $E_a$:反応の活性化エネルギー
- $R$:気体定数
- $T$:温度
となっています。実験ではしばしはこちらを自然対数の形式で表します。自然対数をとると以下のようになります。
$$
\ln k = \ln A - \frac{E_a}{R} \cdot \frac{1}{T}
$$
$\frac{1}{T}$に対して$lnk$をプロットし、フィッティング直線の傾きおよび切片を調べることでパラメータ$E_a$および$A$を取得することができるというわけです。
ただし今回はこのような単純な直線フィッティングではなく、あえて$k = A \exp\left(\frac{-E_a}{RT}\right)$のまま、scipy.optimize.curve_fitを用いてフィットしてみたいと思います。
それではやっていきます。
Scipyの利用方法
Scipyがインストールされていない方は、以下のコマンドにより自身の環境にインストールしてください。pipでインストールは以下です。
pip install scipy
全体のコード
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
R = 8.314 # 気体定数 J/(mol*K)
def arrhenius_function(T, A, Ea):
"""Arrheniusの式: k = A * exp(-Ea / (R * T))"""
return A * np.exp(-Ea / (R * T))
def generate_data(T_range, A_real, Ea_real, noise_scale=0.05, seed=0):
np.random.seed(seed)
k_data = arrhenius_function(T_range, A_real, Ea_real) * (
1 + np.random.normal(scale=noise_scale, size=len(T_range))
)
return k_data
# --- フィッティング ---
def fit_arrhenius(T_data, k_data, initial_guess):
popt, pcov = curve_fit(arrhenius_function, T_data, k_data, p0=initial_guess)
return popt, pcov
def plot_arrhenius(T_data, k_data, popt, filename="arrhenius_fixed.png"):
A_fit, Ea_fit = popt
T_fine = np.linspace(min(T_data), max(T_data), 1000)
k_fit_fine = arrhenius_function(T_fine, *popt)
plt.figure(figsize=(8, 5))
plt.scatter(1 / T_data, np.log(k_data), label="data", color="blue", alpha=0.6)
plt.plot(
1 / T_fine, np.log(k_fit_fine), label="fitting curve", color="red", linewidth=2
)
plt.xlabel("1/T (1/K)")
plt.ylabel("ln(k)")
# 動的にテキスト位置を調整
x_text = np.mean(1 / T_data)
y_text = np.max(np.log(k_data)) - 0.5
plt.text(x_text, y_text, f"Estimated A = {A_fit:.3e}", fontsize=12, color="black")
plt.text(
x_text,
y_text - 0.5,
f"Estimated Ea = {Ea_fit:.3f} J/mol",
fontsize=12,
color="black",
)
plt.legend()
plt.savefig(filename, dpi=300)
plt.show()
def main():
# 温度データ生成
T_data = np.linspace(250, 400, 10)
# 真のパラメータ
A_real = 1e5
Ea_real = 50000 # J/mol
# シミュレーションデータ生成
k_data = generate_data(T_data, A_real, Ea_real)
# 初期推定値
initial_guess = [1e4, 40000]
# フィッティング
popt, pcov = fit_arrhenius(T_data, k_data, initial_guess)
A_fit, Ea_fit = popt
print(f"Estimated A = {A_fit:.3e}")
print(f"Estimated Ea = {Ea_fit:.3f} J/mol")
plot_arrhenius(T_data, k_data, popt)
if __name__ == "__main__":
main()
流れとしては以下のようになっています。
- ダミーデータをgenerate_dataにより生成
-
scipy.optimize.curve_fitを用いてフィッティング - フィッティングの様子を描画
それぞれ解説
main関数
def main():
# 温度データ生成
T_data = np.linspace(250, 400, 10)
# 真のパラメータ
A_real = 1e5
Ea_real = 50000 # J/mol
# シミュレーションデータ生成
k_data = generate_data(T_data, A_real, Ea_real)
# 初期推定値
initial_guess = [1e4, 40000]
# フィッティング
popt, pcov = fit_arrhenius(T_data, k_data, initial_guess)
A_fit, Ea_fit = popt
print(f"Estimated A = {A_fit:.3e}")
print(f"Estimated Ea = {Ea_fit:.3f} J/mol")
plot_arrhenius(T_data, k_data, popt)
まずはダミーデータ(温度$T$)を250 Kから400 Kに等間隔で生成します。
またその$T$に対応する反応速度$k$のデータをgenerate_data関数により生成します。
# 真のパラメータ
A_real = 1e5
Ea_real = 50000 # J/mol
今回、$k$のデータを上の値に従って生成するので、フィッティング結果がそれに近い値が得られるとよいです。
# フィッティング
popt, pcov = fit_arrhenius(T_data, k_data, initial_guess)
A_fit, Ea_fit = popt
print(f"Estimated A = {A_fit:.3e}")
print(f"Estimated Ea = {Ea_fit:.3f} J/mol")
fit_arrhenius関数内にてcurve_fitの1つ目の返り値として帰ってくるpoptにフィッティングパラメータが入っているので、それらを取得しています。
generate_data関数
def generate_data(T_range, A_real, Ea_real, noise_scale=0.05, seed=0):
np.random.seed(seed)
k_data = arrhenius_function(T_range, A_real, Ea_real) * (
1 + np.random.normal(scale=noise_scale, size=len(T_range))
)
return k_data
np.random.normalを用いて$k$の値に対して、正規分布に従うノイズを加えています。
- noise_scaleは標準偏差を指定します
- seedの値を指定することで乱数の値を変えることができます
fit_arrhenius関数
def fit_arrhenius(T_data, k_data, initial_guess):
popt, pcov = curve_fit(arrhenius_function, T_data, k_data, p0=initial_guess)
return popt, pcov
今回のコードの肝となるフィッティングを行っている部分になります。
ドキュメントにもあるようにcurve_fitは以下の形にする必要があります。
popt, pcov = curve_fit(func, xdata, ydata, p0=initial_guess)
今回フィッティングしたい式はarrhenius_function、xはT_data、yはk_dataとなっています。
p0には初期値をいれる必要があり、今回はinitial_guess = [1e4, 40000]を入れてみます。
デフォルトはNoneとなっています。
plot_arrhenius関数
def plot_arrhenius(T_data, k_data, popt, filename="arrhenius_fixed.png"):
A_fit, Ea_fit = popt
T_fine = np.linspace(min(T_data), max(T_data), 1000)
k_fit_fine = arrhenius_function(T_fine, *popt)
plt.figure(figsize=(8, 5))
plt.scatter(1 / T_data, np.log(k_data), label="data", color="blue", alpha=0.6)
plt.plot(
1 / T_fine, np.log(k_fit_fine), label="fitting curve", color="red", linewidth=2
)
plt.xlabel("1/T (1/K)")
plt.ylabel("ln(k)")
# 動的にテキスト位置を調整
x_text = np.mean(1 / T_data)
y_text = np.max(np.log(k_data)) - 0.5
plt.text(x_text, y_text, f"Estimated A = {A_fit:.3e}", fontsize=12, color="black")
plt.text(
x_text,
y_text - 0.5,
f"Estimated Ea = {Ea_fit:.3f} J/mol",
fontsize=12,
color="black",
)
plt.legend()
plt.savefig(filename, dpi=300)
plt.show()
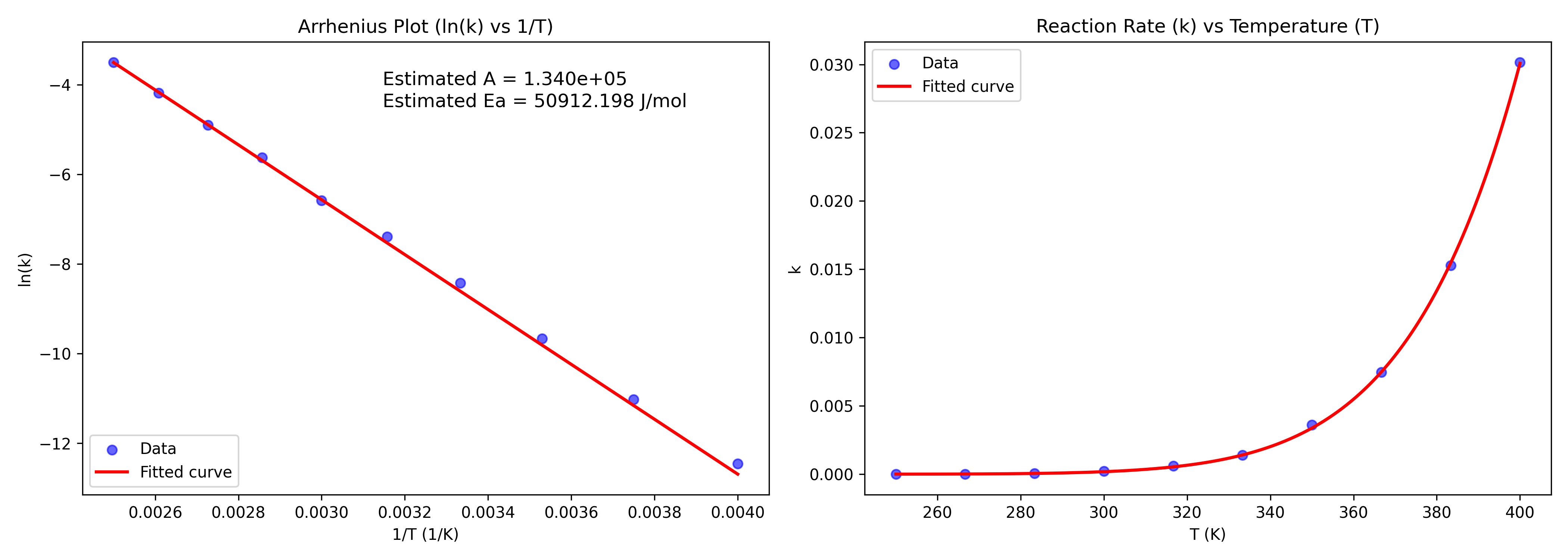
- フィッティング結果
#ダミーデータ生成に用いた値
A_real = 1e5
Ea_real = 50000 # J/mol
# フィッティング結果
Estimated A = 1.340e+05
Estimated Ea = 50912.198 J/mol
用意したA_realやEa_realと近い値が得られていることがわかります。
curve_fitではあえてexp関数でフィットしているので、指数形のフィッティングの様子と合わせて見てみます。右側の図がそれに対応しています。うまくフィッティングカーブがダミーデータを記述できています。
まとめ
scipy.optimize.curve_fitを用いて実験データをうまく非線形フィッティングすることができました。
アレニウスプロットのような直線フィッティングの式は単純ですが(コード内ではあえて非線形な関数の状態でフィットしましたが)、少し複雑な関数では有効な手段になります。