1.データクレンジングとは
データクレンジングとは、破損したデータ、不正確なデータ、無関係のデータを特定して解決する手法を指します。 データ処理におけるこの重要な段階は、データスクラビングと呼ばれます。
2.データクレンジングの必要性
1番でも説明した通り、無関係のデータなどがあった場合、正しい予測結果を得られなくなることや、回帰分析においては、強い相関がみられる2変数のデータなどがある場合、※多重共線性などが発生してしまったりと、とても都合がよろしくありません。
分析業務においてもデータクレンジングはほどんどの業務を占めており、実際企業が保有しているデータは汚れているデータがほとんどなどでとても欠かせない作業になります。
3.実際にデータを見てみよう
#必要なライブラリのインストール
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
%matplotlib inline
len(df)
# 637351
df.isnull().sum()
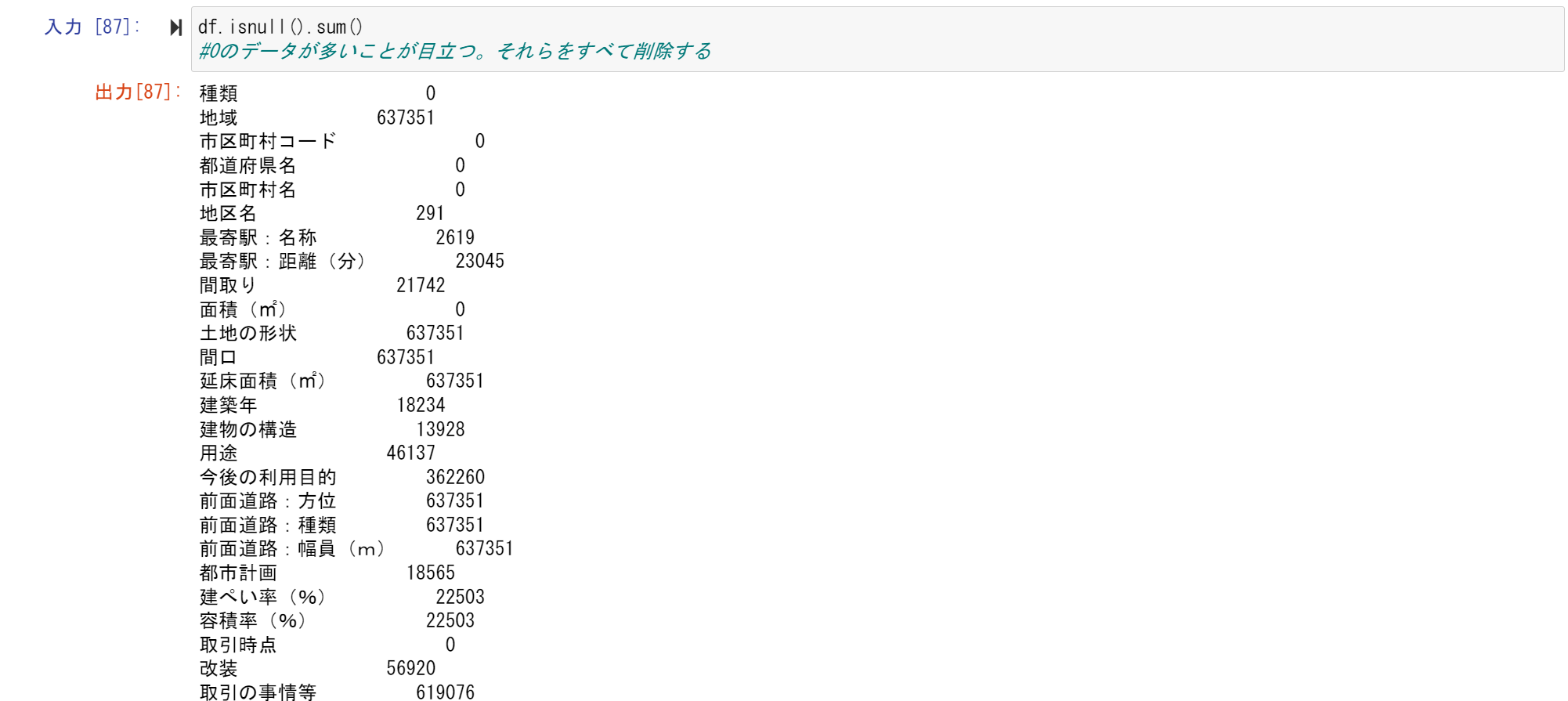
※修正:0のデータは欠損値がないということなので、消す必要がありません。
データフレームの行が63751個に対して、何個か欠損値が63751個あります
つまり、そのカラムにはなにもデータが入っていないことになります。
4.欠損値を削除しよう
カラムの中に完全にデータが入っていない場合、削除する必要があります。
ここでは欠損値をまとめて消す方法について説明していきます。
では実際にコードを書いていきます
non_null_list = []
for col in df.columns: #カラム名を順番に取り出す
non_null = df[col].count() #あるカラムのデータの個数をカウントします
if non_null == 0 : #もし、カウント数が0の場合
non_null_list.append(col) #そのカラム名を抽出し、空のリストに順に加える
non_null_list
['地域', '土地の形状', '間口', '延床面積(㎡)', '前面道路:方位', '前面道路:種類', '前面道路:幅員(m)']
完全に欠損しているカラム名が出ました
次に、作成したリストを活用し、欠損値データをまとめて消していくよ
df = df.drop(non_null_list , axis=1)
# データが入っていないカラムを一斉に削除する。axis=0の場合はすべて消えてしまう。
5.まとめ
これで無事に完全に欠損があるカラムを消すことができました。
今回行った処理はあくまでもデータクレンジングの一つに過ぎませんので、また別の手法を解説します。
それでは!