これはマイネット Advent Calendar 2016 24日目の記事です。
対象読者
以下、当てはまる人
- DBからはどうしても集計できない。ログから頑張れば集計できるけど、時間かかって辛い。
- Amazon S3を利用している
- Hiveをちょっとでも使ったことがある人
以前、@nohamaさんが投稿された記事と少々かぶってしまいましたが、
どうしてもこれやりたかったので、どうかご勘弁ください。m_m
やりたいこと
ログを分散処理で集計して、集計時間を短縮したい。
手順
準備するもの
今回集計対象とするのは私のプロジェクトで使ってるゲームの物理ログ。ログフォーマットは以下のようなもの
(実データはお見せできないので、中身はテキトーにしています。)
2016-09-09T00:00:02+09:00 analytics {"dt":"add_item","d":20160909,"h":aaa,"ut":11111111,"attrs":{"id":"add_item","name":"add_item","q":aaa,"c":aaa,"in_vc":aaaa,"l":1111,"gc":11111,"vc":11111,"f":111111,"fp":111,"pa":111,"ge":null,"be":null,"item_id":"999","item_count":999,"before_item_count":1111,"after_item_count":111,"from_present":0},"sl":111,"serial":"","a":"<proj-name>","av":"0","o":"android","ov":"0.0.0","dvc":"11111","ip":"000.000.000.000","cid"1234,"mkt":"google_play"}
2016-09-12T13:59:58+09:00 analytics {"dt":"battle_user","d":20160912,"h":bbb,"ut":22222222,"attrs":{"id":"battle_user","name":"battle_user","q":bbb,"c":bbb,"in_vc":bbb,"l":2222,"gc":2222,"vc":222,"f":22,"fp":2222,"pa":22,"ge":null,"be":null,"user_battle_id":"00000000000","opponent_user_id":"2222222","treasure_id":"222","result":"2"},"sl":222,"serial":"2222222-22222222","a":"<proj-name>","av":"0","o":"android","ov":"0.0.0","dvc":"222222","ip":"000.000.000.000","cid":22222,"mkt":"google_play"}
だいたいこんな感じのやつが、1日で1GB弱あり、イベント期間中で10GB弱。
例えば、ユーザー毎にこのアイテムの獲得数、消費数・・・・・・などの行動ログを出してくれと頼まれるとします。
DBから集計できればいいのですが、できないものはS3から物理ログをローカルに落としてきてごにょごにょしなきゃならない。
毎回この集計に時間取られる。そこで、痒いところに手が届きそうなのが、Athena。
今回は、簡単にイベント期間中のユーザーごとにアイテムごとの獲得数を集計してみます。
AWSコンソールからAthenaのサービス画面に行きます。
※現在, Athenaは東京リージョンでは使えないので、今使えるオレゴンリージョンで始めました。
集計用テーブルを作成する
クエリエディタが表示されるので、ここで今回の集計用のテーブルを作ります。
先ほどのログをテーブルにするために、以下のようなcreate文を発行します。
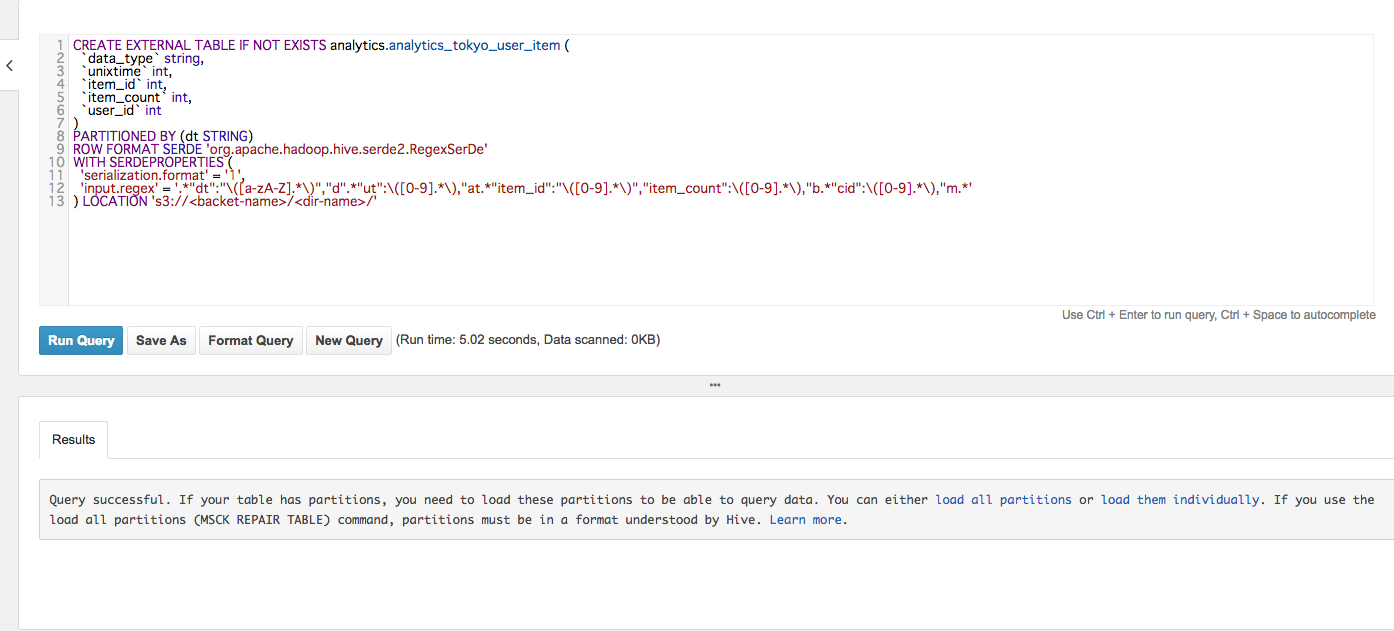
EXTERNALを付与することにより、テーブル定義はS3上に保持されます。
今回はログデータすべてをテーブルに入れるのではなく、イベント期間中のログデータだけ入れればいいので、パーティション機能を使って入れます。
WITH_SERDEPROPERTIESで正規表現を使って、ログからマッチした部分だけ取り出して、各カラムに入れます。
LOCATION設定は、集計対象とするデータが置いてあるS3上のディレクトリを指定します。
これでテーブルが作成されたので、パーティションを切って、クエリを実行すれば、集計結果がS3に保存されます。
まず以下をぼんぼん叩いて、パーティションを切ります
(うまいやり方があるのかもしれないですが、時間もそんなにかからないのでひとまず無心で叩く。)
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160909') location 's3://<backet-name>/<dir-name>/d=20160909';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160910') location 's3://<backet-name>/<dir-name>/d=20160910';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160911') location 's3://<backet-name>/<dir-name>/d=20160911';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160912') location 's3://<backet-name>/<dir-name>/d=20160912';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160913') location 's3://<backet-name>/<dir-name>/d=20160913';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160914') location 's3://<backet-name>/<dir-name>/d=20160914';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160915') location 's3://<backet-name>/<dir-name>/d=20160915';
ALTER TABLE analytics.analytics_tokyo_user_item ADD PARTITION (dt='d=20160916') location 's3://<backet-name>/<dir-name>/d=20160916';
ちゃんと読み込めていますね。
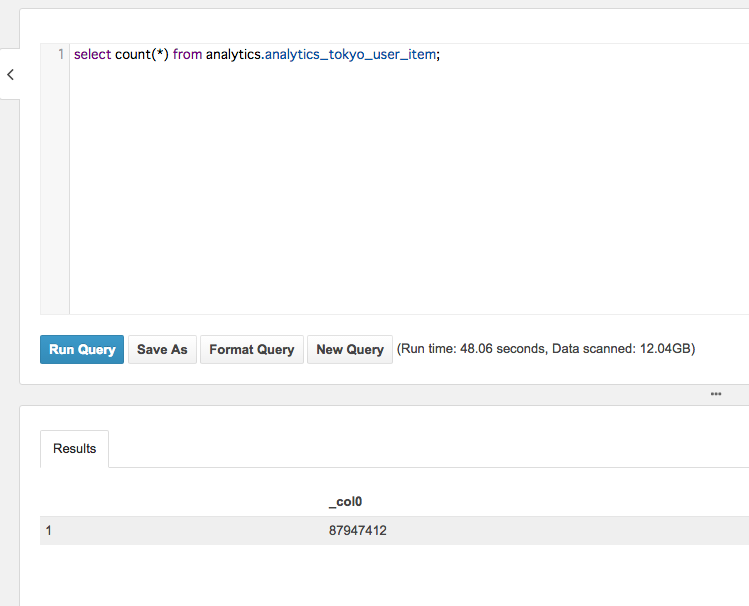
集計
では、イベント期間中のユーザーごとにアイテムごとの獲得数を集計してみます。
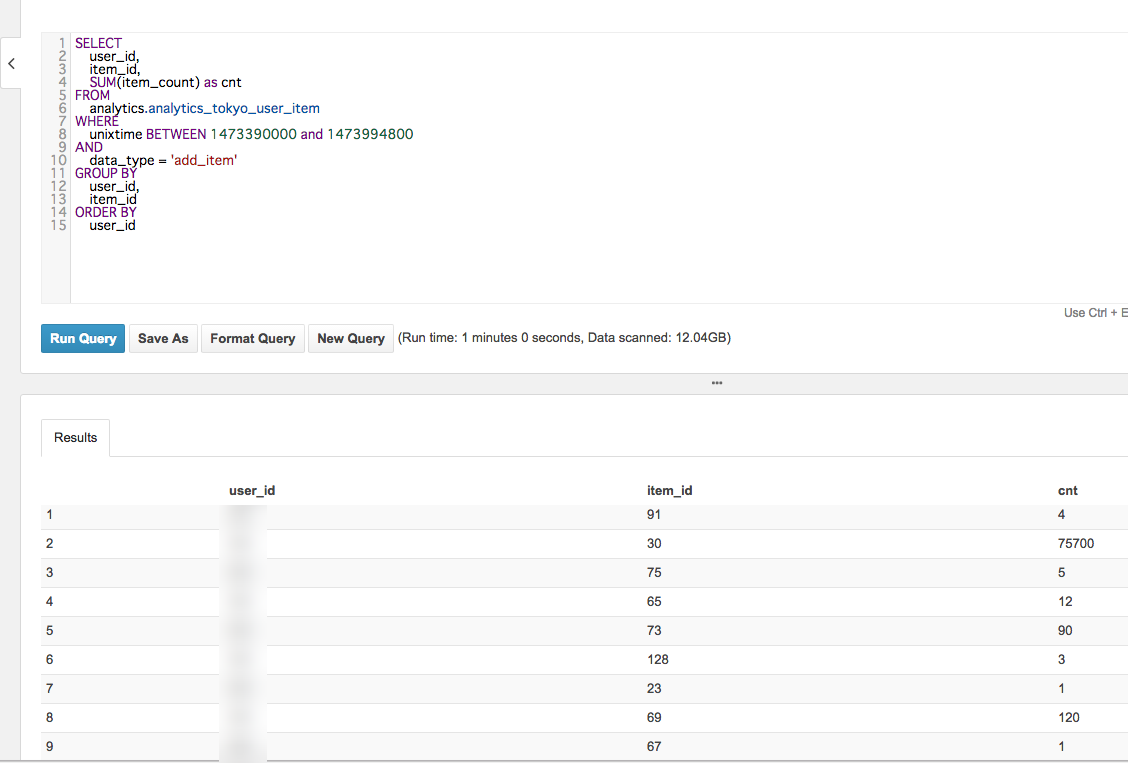
実行時間を見ると、1分でした。
今まで、1,2時間かかっていた集計処理がたった1分で終わりました。
やっぱり、prestoは早いですね。

集計結果はS3に上がっています。
料金
今回かかった費用はこんな感じ。
- クエリ発行
- S3からのデータ転送量に対する料金
AthenaはGoogle Big Queryのように、スキャンした容量によって課金される料金体系です。
レートは
$5 per TB(1000GB) of data scanned.
と公式に出ています。
今回の集計結果を見ると、データスキャン量は12GBなので、約0.06$。
また、Athenaは海外リージョンなので、リージョン間転送は料金がかかります。
今回、東京リージョンからオレゴンリージョンへ10GBほどデータ転送したので、そのときにかかった料金は
AWS料金見積もりサイト
で計算したところ、0.2$。
なので、合計で、0.26$しかかかりませんでした。
といっても、もっと馬鹿でかい量のログを集計するとなると、破産してしまいますが。
なので、ネックになるのが、データ転送の部分かと。
それでも、ちょっと小金を払って、半端なく時間がかかる集計をこれだけ短縮できたのは魅力的だと思いました。
早く東京リージョンで使えるようにならないかな・・・・・というかそもそも集計や調査で使うであろうログを東京リージョンに置いておくのが間違いであった。
料金も東京リージョンが最も高いらしいし。
まとめ
集計が爆速でした。
これで時間コストもだいぶ削減できるかと。
今まで、自前のインスタンスでhadoop環境構築して、hdfsにログ置いて、集計・・・・なんてことしてたけど、これらの必要性がなくなったのはすごく有難いです。まさにサーバーレス!
それと、集計するフォーマットがその時々によって変わっても、スキーマ定義を柔軟に変えられて、集計できるのは便利です。
データ分析界隈では、Schema on Readという言い方をするのかな?(間違っていたらすみません)
以前@nohamaさんも記事に書いていましたが、S3に結果ファイルが置かれたことを駆動にしてLambdaを動かして、ファイル圧縮したりなどLambdaとの組み合わせもうまく利用すると使い勝手もっと広がりそうですね。