記事作成のきっかけ
ほぼ自分語りになるので興味がない人は飛ばしてください。
昨年にUnity6がリリースされ、それと同時にUnity Sentisというサービスが正式に対応することになりました。Unity Sentisを用いることで、ゲーム内にローカルで機械学種モデルによる推論を盛り込めるようになりました。
当時私も気になってはいたものの、それほど深くは立ち入りませんでしたが、新しい年度になり、なにか自分で記事でも書いてみようかと思いネタを考えてみたところ思い浮かんだのがUnity Sentisでした。
この記事の執筆時点では、検索窓に「Unity Sentis」と入れてもQiitaでは6件、Zennでは11件ほどしかヒットせず、まだあまり踏み込まれていない領域であるように感じたので勉強もかねてUnity Sentisを活用してなにか面白いものを作ってみたいと思ったのがきっかけです。
Unity Sentisの特徴
公式のページによると、Unity Sentisには以下のような特徴があると謡われています。
- ONNX規格を用いたモデルへのアクセス
- API不使用なのでコストがかからない
- マルチプラットフォーム対応
- ランタイム環境に合わせた最適化と高速な推論
- ハードウェアの最適化
- ローカル実行されるのでデータが抜かれることが無く安全
また、実際にモデルを用いたデモの紹介もされており、リポジトリも公開されています。
余談ですが、近々デモについての記事も公開予定です。
Whisper-tinyを用いた文字起こしとエフェクトの表示
先ほどのGitHubのリポジトリのほかに、HuggingFace上でもモデルを用いたデモが公開されています。
今回はこの中の sentis-whisper-tiny のプロジェクトを利用して音声認識を行い、文字起こしを行ってみようと思います。また、それだけではゲームっぽくないので認識された音声によってエフェクトが再生されるようもしようと思います。「ファイヤー!!」とか叫んで実際にゲーム上で炎の魔法が唱えられたら面白そうだと思った次第です。
実行環境
デバイス環境
- Windows11
- CPU : AMD Ryzen5 7600
- GPU : NVIDIA GeForce RTX4060 Ti
- メモリ : 32GB
Unity
- Unity6 (6000.0.23f1)
- Unity Hub 3.8.0
ライブラリ
- Unity Sentis 2.1.0
- Newtonsoft Json 3.2.1
ライブラリについては、すでにsentis-whisper-tinyのプロジェクトではすでにインストールされているため追加の必要はないと思います。
sentis-whisper-tinyの実行
リポジトリのクローン
リモートリポジトリをクローンします。
他のsentis向けに公開されているものの中にはモデルとソースコードのみのものもありますが、sentis-whisper-tinyではProjectが丸々公開されています。そのため、適当な場所にgit cloneしてからUnity Hubを開き、Add > Add project from diskとして先ほどcloneしたプロジェクトを選択すれば完了です。
このとき、エディタバージョン6000.0.23f1がインストールされていない場合はインストールするかどうか聞かれると思いますが、インストールしてから開いてあげる方が不都合ないかと思います。
なお、onnx形式のモデルファイルのサイズが大きいので, LFSをインストールする必要があります。
git lfs install
git clone https://huggingface.co/unity/sentis-whisper-tiny
試しに動かしてみる
実行前にSentisとNewtonsoft JsonがインストールされていることをPackage Managerから確認してください。もしインストールされていなければPackage Managerからインストールしてください。なお、Newtonsoft Jsonについては左上のAdd Package from git URL ...からcom.unity.nuget.newtonsoft-jsonを入力し追加をする必要があります。
インストールされていることが確認出来たらAssets/ScenesにあるSampleScenceを起動し、実行してみてください。Consoleに英語の文章が文字起こしされているのが確認できると思います。これは, Assets/Data以下にあらかじめ用意されているwav形式の音声ファイルを読みこんで実際に文字起こしを行った結果です。

マイクから音声入力を行い文字起こし
コード編集
wav形式のファイルを毎回アップロードして文字起こし、というのはゲームとしては使いにくいのでマイク音声から文字起こしを行うことを試みます。
調べたところ、先駆者がいらっしゃったのでコード等は主にこちらのものを参考にしています。
ただし、この記事が書かれた当時からsentis-whisper-tinyにアップデートが入っているなど少し勝手が変わった部分があったので修正していきます。
まず、
Assets/Scriptsに以下のスクリプトVoiceRecorder.csを作成します。
using System;
using UnityEngine;
using System.IO;
using UnityEngine.Serialization;
using UnityEngine.UI;
public class VoiceRecorder : MonoBehaviour
{
public AudioClip recordedClip;
[SerializeField] private RunWhisper runWhisper;
[SerializeField] private Button startRecordingButton;
[SerializeField] private Button stopRecordingButton;
private void Start()
{
startRecordingButton.onClick.AddListener(StartRecording);
stopRecordingButton.onClick.AddListener(StopRecording);
}
private void StartRecording()
{
recordedClip = Microphone.Start(null, false, 10, 16000);
Debug.Log("Recording started");
}
private void StopRecording()
{
Microphone.End(null);
Debug.Log("Recording stopped");
SaveRecordedClip();
}
private void SaveRecordedClip()
{
string fileName = "recorded_clip_" + System.DateTime.Now.ToString("yyyyMMdd_HHmmss") + ".wav";
string filePath = Path.Combine(Application.dataPath, fileName);
SavWav.Save(filePath, recordedClip);
Debug.Log("Recorded clip saved as " + filePath);
runWhisper.audioClip = recordedClip;
runWhisper.StartWhisper();
}
}
また、元々あったRunWhisper.csに以下のように変更を加えます。
- メンバ変数にpublic TextMeshProUGUI textMeshProUGUIを追加
- (ちょっと強引だが)関数名を変更 : public async void Start() → public async void StartWhisper()
- InferenceStep()の最後の部分を変更 : Debug.Log(outputString); → TranscriptionCompleted(outputString);
- 以下の新しい関数 TranscriptionCompleted()を追加
void TranscriptionCompleted(string transcription)
{
Debug.Log("Transcription: " + transcription);
textMeshProUGUI.text = "Output:"+transcription;
}
最終的には以下のようなコードになります。
修正後のRunWhisper.cs
using System.Collections.Generic;
using UnityEngine;
using Unity.Sentis;
using System.Text;
using Unity.Collections;
using TMPro;
public class RunWhisper : MonoBehaviour
{
Worker decoder1, decoder2, encoder, spectrogram;
Worker argmax;
public AudioClip audioClip;
public TextMeshProUGUI textMeshProUGUI;
// This is how many tokens you want. It can be adjusted.
const int maxTokens = 100;
// Special tokens see added tokens file for details
const int END_OF_TEXT = 50257;
const int START_OF_TRANSCRIPT = 50258;
const int ENGLISH = 50259;
const int GERMAN = 50261;
const int FRENCH = 50265;
const int TRANSCRIBE = 50359; //for speech-to-text in specified language
const int TRANSLATE = 50358; //for speech-to-text then translate to English
const int NO_TIME_STAMPS = 50363;
const int START_TIME = 50364;
int numSamples;
string[] tokens;
int tokenCount = 0;
NativeArray<int> outputTokens;
// Used for special character decoding
int[] whiteSpaceCharacters = new int[256];
Tensor<float> encodedAudio;
bool transcribe = false;
string outputString = "";
// Maximum size of audioClip (30s at 16kHz)
const int maxSamples = 30 * 16000;
public ModelAsset audioDecoder1, audioDecoder2;
public ModelAsset audioEncoder;
public ModelAsset logMelSpectro;
//public async void Start()
public async void StartWhisper()
{
SetupWhiteSpaceShifts();
GetTokens();
decoder1 = new Worker(ModelLoader.Load(audioDecoder1), BackendType.GPUCompute);
decoder2 = new Worker(ModelLoader.Load(audioDecoder2), BackendType.GPUCompute);
FunctionalGraph graph = new FunctionalGraph();
var input = graph.AddInput(DataType.Float, new DynamicTensorShape(1, 1, 51865));
var amax = Functional.ArgMax(input, -1, false);
var selectTokenModel = graph.Compile(amax);
argmax = new Worker(selectTokenModel, BackendType.GPUCompute);
encoder = new Worker(ModelLoader.Load(audioEncoder), BackendType.GPUCompute);
spectrogram = new Worker(ModelLoader.Load(logMelSpectro), BackendType.GPUCompute);
outputTokens = new NativeArray<int>(maxTokens, Allocator.Persistent);
outputTokens[0] = START_OF_TRANSCRIPT;
outputTokens[1] = ENGLISH;// GERMAN;//FRENCH;//
outputTokens[2] = TRANSCRIBE; //TRANSLATE;//
//outputTokens[3] = NO_TIME_STAMPS;// START_TIME;//
tokenCount = 3;
LoadAudio();
EncodeAudio();
transcribe = true;
tokensTensor = new Tensor<int>(new TensorShape(1, maxTokens));
ComputeTensorData.Pin(tokensTensor);
tokensTensor.Reshape(new TensorShape(1, tokenCount));
tokensTensor.dataOnBackend.Upload<int>(outputTokens, tokenCount);
lastToken = new NativeArray<int>(1, Allocator.Persistent); lastToken[0] = NO_TIME_STAMPS;
lastTokenTensor = new Tensor<int>(new TensorShape(1, 1), new[] { NO_TIME_STAMPS });
while (true)
{
if (!transcribe || tokenCount >= (outputTokens.Length - 1))
return;
m_Awaitable = InferenceStep();
await m_Awaitable;
}
}
Awaitable m_Awaitable;
NativeArray<int> lastToken;
Tensor<int> lastTokenTensor;
Tensor<int> tokensTensor;
Tensor<float> audioInput;
void LoadAudio()
{
numSamples = audioClip.samples;
var data = new float[maxSamples];
numSamples = maxSamples;
audioClip.GetData(data, 0);
audioInput = new Tensor<float>(new TensorShape(1, numSamples), data);
}
void EncodeAudio()
{
spectrogram.Schedule(audioInput);
var logmel = spectrogram.PeekOutput() as Tensor<float>;
encoder.Schedule(logmel);
encodedAudio = encoder.PeekOutput() as Tensor<float>;
}
async Awaitable InferenceStep()
{
decoder1.SetInput("input_ids", tokensTensor);
decoder1.SetInput("encoder_hidden_states", encodedAudio);
decoder1.Schedule();
var past_key_values_0_decoder_key = decoder1.PeekOutput("present.0.decoder.key") as Tensor<float>;
var past_key_values_0_decoder_value = decoder1.PeekOutput("present.0.decoder.value") as Tensor<float>;
var past_key_values_1_decoder_key = decoder1.PeekOutput("present.1.decoder.key") as Tensor<float>;
var past_key_values_1_decoder_value = decoder1.PeekOutput("present.1.decoder.value") as Tensor<float>;
var past_key_values_2_decoder_key = decoder1.PeekOutput("present.2.decoder.key") as Tensor<float>;
var past_key_values_2_decoder_value = decoder1.PeekOutput("present.2.decoder.value") as Tensor<float>;
var past_key_values_3_decoder_key = decoder1.PeekOutput("present.3.decoder.key") as Tensor<float>;
var past_key_values_3_decoder_value = decoder1.PeekOutput("present.3.decoder.value") as Tensor<float>;
var past_key_values_0_encoder_key = decoder1.PeekOutput("present.0.encoder.key") as Tensor<float>;
var past_key_values_0_encoder_value = decoder1.PeekOutput("present.0.encoder.value") as Tensor<float>;
var past_key_values_1_encoder_key = decoder1.PeekOutput("present.1.encoder.key") as Tensor<float>;
var past_key_values_1_encoder_value = decoder1.PeekOutput("present.1.encoder.value") as Tensor<float>;
var past_key_values_2_encoder_key = decoder1.PeekOutput("present.2.encoder.key") as Tensor<float>;
var past_key_values_2_encoder_value = decoder1.PeekOutput("present.2.encoder.value") as Tensor<float>;
var past_key_values_3_encoder_key = decoder1.PeekOutput("present.3.encoder.key") as Tensor<float>;
var past_key_values_3_encoder_value = decoder1.PeekOutput("present.3.encoder.value") as Tensor<float>;
decoder2.SetInput("input_ids", lastTokenTensor);
decoder2.SetInput("past_key_values.0.decoder.key", past_key_values_0_decoder_key);
decoder2.SetInput("past_key_values.0.decoder.value", past_key_values_0_decoder_value);
decoder2.SetInput("past_key_values.1.decoder.key", past_key_values_1_decoder_key);
decoder2.SetInput("past_key_values.1.decoder.value", past_key_values_1_decoder_value);
decoder2.SetInput("past_key_values.2.decoder.key", past_key_values_2_decoder_key);
decoder2.SetInput("past_key_values.2.decoder.value", past_key_values_2_decoder_value);
decoder2.SetInput("past_key_values.3.decoder.key", past_key_values_3_decoder_key);
decoder2.SetInput("past_key_values.3.decoder.value", past_key_values_3_decoder_value);
decoder2.SetInput("past_key_values.0.encoder.key", past_key_values_0_encoder_key);
decoder2.SetInput("past_key_values.0.encoder.value", past_key_values_0_encoder_value);
decoder2.SetInput("past_key_values.1.encoder.key", past_key_values_1_encoder_key);
decoder2.SetInput("past_key_values.1.encoder.value", past_key_values_1_encoder_value);
decoder2.SetInput("past_key_values.2.encoder.key", past_key_values_2_encoder_key);
decoder2.SetInput("past_key_values.2.encoder.value", past_key_values_2_encoder_value);
decoder2.SetInput("past_key_values.3.encoder.key", past_key_values_3_encoder_key);
decoder2.SetInput("past_key_values.3.encoder.value", past_key_values_3_encoder_value);
decoder2.Schedule();
var logits = decoder2.PeekOutput("logits") as Tensor<float>;
argmax.Schedule(logits);
using var t_Token = await argmax.PeekOutput().ReadbackAndCloneAsync() as Tensor<int>;
int index = t_Token[0];
outputTokens[tokenCount] = lastToken[0];
lastToken[0] = index;
tokenCount++;
tokensTensor.Reshape(new TensorShape(1, tokenCount));
tokensTensor.dataOnBackend.Upload<int>(outputTokens, tokenCount);
lastTokenTensor.dataOnBackend.Upload<int>(lastToken, 1);
if (index == END_OF_TEXT)
{
transcribe = false;
}
else if (index < tokens.Length)
{
outputString += GetUnicodeText(tokens[index]);
}
//Debug.Log(outputString);
TranscriptionCompleted(outputString);
}
// Tokenizer
public TextAsset jsonFile;
void GetTokens()
{
var vocab = Newtonsoft.Json.JsonConvert.DeserializeObject<Dictionary<string, int>>(jsonFile.text);
tokens = new string[vocab.Count];
foreach (var item in vocab)
{
tokens[item.Value] = item.Key;
}
}
string GetUnicodeText(string text)
{
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(ShiftCharacterDown(text));
return Encoding.UTF8.GetString(bytes);
}
string ShiftCharacterDown(string text)
{
string outText = "";
foreach (char letter in text)
{
outText += ((int)letter <= 256) ? letter :
(char)whiteSpaceCharacters[(int)(letter - 256)];
}
return outText;
}
void SetupWhiteSpaceShifts()
{
for (int i = 0, n = 0; i < 256; i++)
{
if (IsWhiteSpace((char)i)) whiteSpaceCharacters[n++] = i;
}
}
bool IsWhiteSpace(char c)
{
return !(('!' <= c && c <= '~') || ('�' <= c && c <= '�') || ('�' <= c && c <= '�'));
}
void TranscriptionCompleted(string transcription)
{
Debug.Log("Transcription: " + transcription);
textMeshProUGUI.text = "Output:"+transcription;
}
private void OnDestroy()
{
decoder1.Dispose();
decoder2.Dispose();
encoder.Dispose();
spectrogram.Dispose();
argmax.Dispose();
audioInput.Dispose();
lastTokenTensor.Dispose();
tokensTensor.Dispose();
}
}
whisper-tinyがwav形式のファイルを扱う以上、マイク音声を入力した後それを一度wav形式で出力し、whisper-tinyで処理します。この部分の処理については、公開されているスクリプトSavWav.csを流用させていただきました。
シーン編集
Assets/Scriptsに、VoiceRecorder.cs、RunWhisper.cs、SavWav.csが用意できたらエディタに戻り、シーンの編集に移ります。
操作に必要なボタンおよび出力結果を表示するText(TextMeshProUGUI)を作成します。
その後、VoiceRecorder.csおよびRunWhisper.csをMain Cameraにアタッチし、必要なコンポーネントをアタッチしていきます。RunWhisper.csではonnx形式のモデルのアタッチなど必要ですが、すべてAssets以下のModelsやDataといったフォルダ内に用意されています。最初にシーンに用意されていていたTranscriptionというGame Objectにはすでにコンボーネントが完備されたRunWhisper.csがアタッチされているのでそれを参考に埋めていけばよいと思います。なお、Transcriptionはもう使わないのでInspector上でチェックを外して無効化しておいてください。
私の場合は、以下の画像のように設定しました。

文字起こしの結果
Startボタンを押すとマイク入力を受け付け、Stopを押すと終了します。その際に(英語で)話した文章がOutputとして表示されると思います。
試してみた感じ、自分が思っていたよりも速度については申し分なく感じます。
精度についてもそれほど悪くないかな?というくらいにはちゃんと認識してくれるので単語や短文であればギリギリゲームにも使えそうな気がします。それでも「Fire」と言っているのに、「For you」と表示されることとかはありますが。私の英語スキルの問題かもしれない
今回はWhisperの中でも最もサイズの小さいtinyモデルだったのでこの結果は妥当かもしれません。どこかでbaseとかも使ってUnity上で試したときの精度とか速度とか比較してみたいです。
また、当然ですがwhisperでは一般的な言語にしか変換してくれません。つまり「メラ〇ーマ!」とか唱えてもそれに近しい音の単語に変換されるのでオリジナリティを出すのは難しいと思います。もしそうしたモデルが欲しいなら一から作るかFine Tuningを行うかといったところでしょうが、コストやリソースを考えるとどこまでが現実的なラインでしょうか...
音声に応じたエフェクトを表示させる
最後に、よりゲームっぽくするために、取得された音声の内容(単語)に応じて表示させるエフェクトを変えるようなものを作ってみました。
仕様としては、
- 「Fire!」というと赤いエフェクトが発生する
- 「Ice!」とぃうと青いエフェクトが発生する
- その他の言葉に対しては白いエフェクトが発生する
といったものを考えました。
コード編集
まずはRunWhisper.cs側の変更を説明します。
音声から文字起こしされたテキストはメンバ変数outputStringに格納されます。しかし、outputStringは入力された内容を末尾にどんどん追加していくのでそのままでは扱いづらいです。そのため、今回はpreviousoutputStringというstring型メンバ変数を追加し, 前回の入力内容を保存させ、入力内容の差分を取る形にすることで新しい入力内容のみを読み取るようにします。また、whisper側が文章を認識する際にスペースやピリオドなどを文字列に加える場合がありますが、今回は邪魔になるので取り除く処理も追加します。
ついでに、Eventを用いて文字起こしが完了した際にVoiceRecorder.csに通知を送るように変更しました。
まとめると、変更点としては
- メンバ変数 previousoutputString の追加
- public event Action OnTranscriptionCompleted; の追加
- TranscriptionCompleted()で、前の出力との差分をとり、必要に応じてイベントを発火
- 差分を取る処理、スペースやピリオドを無視する処理を追加
となります。
最終的には以下のようなコードになります。長いので折りたたんでいます。
編集後のRunWhisper.cs
using System.Collections.Generic;
using UnityEngine;
using Unity.Sentis;
using System.Text;
using Unity.Collections;
using TMPro;
using System;
public class RunWhisper : MonoBehaviour
{
Worker decoder1, decoder2, encoder, spectrogram;
Worker argmax;
public AudioClip audioClip;
public TextMeshProUGUI textMeshProUGUI;
// This is how many tokens you want. It can be adjusted.
const int maxTokens = 100;
// Special tokens see added tokens file for details
const int END_OF_TEXT = 50257;
const int START_OF_TRANSCRIPT = 50258;
const int ENGLISH = 50259;
const int GERMAN = 50261;
const int FRENCH = 50265;
const int TRANSCRIBE = 50359; //for speech-to-text in specified language
const int TRANSLATE = 50358; //for speech-to-text then translate to English
const int NO_TIME_STAMPS = 50363;
const int START_TIME = 50364;
int numSamples;
string[] tokens;
int tokenCount = 0;
NativeArray<int> outputTokens;
// Used for special character decoding
int[] whiteSpaceCharacters = new int[256];
Tensor<float> encodedAudio;
bool transcribe = false;
string outputString = "";
string previousOutputString = ""; // 前回の結果を保存する変数
// Maximum size of audioClip (30s at 16kHz)
const int maxSamples = 30 * 16000;
public ModelAsset audioDecoder1, audioDecoder2;
public ModelAsset audioEncoder;
public ModelAsset logMelSpectro;
//public async void Start()
public async void StartWhisper()
{
SetupWhiteSpaceShifts();
GetTokens();
decoder1 = new Worker(ModelLoader.Load(audioDecoder1), BackendType.GPUCompute);
decoder2 = new Worker(ModelLoader.Load(audioDecoder2), BackendType.GPUCompute);
FunctionalGraph graph = new FunctionalGraph();
var input = graph.AddInput(DataType.Float, new DynamicTensorShape(1, 1, 51865));
var amax = Functional.ArgMax(input, -1, false);
var selectTokenModel = graph.Compile(amax);
argmax = new Worker(selectTokenModel, BackendType.GPUCompute);
encoder = new Worker(ModelLoader.Load(audioEncoder), BackendType.GPUCompute);
spectrogram = new Worker(ModelLoader.Load(logMelSpectro), BackendType.GPUCompute);
outputTokens = new NativeArray<int>(maxTokens, Allocator.Persistent);
outputTokens[0] = START_OF_TRANSCRIPT;
outputTokens[1] = ENGLISH;// GERMAN;//FRENCH;//
outputTokens[2] = TRANSCRIBE; //TRANSLATE;//
//outputTokens[3] = NO_TIME_STAMPS;// START_TIME;//
tokenCount = 3;
LoadAudio();
EncodeAudio();
transcribe = true;
tokensTensor = new Tensor<int>(new TensorShape(1, maxTokens));
ComputeTensorData.Pin(tokensTensor);
tokensTensor.Reshape(new TensorShape(1, tokenCount));
tokensTensor.dataOnBackend.Upload<int>(outputTokens, tokenCount);
lastToken = new NativeArray<int>(1, Allocator.Persistent); lastToken[0] = NO_TIME_STAMPS;
lastTokenTensor = new Tensor<int>(new TensorShape(1, 1), new[] { NO_TIME_STAMPS });
while (true)
{
if (!transcribe || tokenCount >= (outputTokens.Length - 1))
return;
m_Awaitable = InferenceStep();
await m_Awaitable;
}
}
Awaitable m_Awaitable;
NativeArray<int> lastToken;
Tensor<int> lastTokenTensor;
Tensor<int> tokensTensor;
Tensor<float> audioInput;
public event Action<string> OnTranscriptionCompleted;
void LoadAudio()
{
numSamples = audioClip.samples;
var data = new float[maxSamples];
numSamples = maxSamples;
audioClip.GetData(data, 0);
audioInput = new Tensor<float>(new TensorShape(1, numSamples), data);
}
void EncodeAudio()
{
spectrogram.Schedule(audioInput);
var logmel = spectrogram.PeekOutput() as Tensor<float>;
encoder.Schedule(logmel);
encodedAudio = encoder.PeekOutput() as Tensor<float>;
}
async Awaitable InferenceStep()
{
decoder1.SetInput("input_ids", tokensTensor);
decoder1.SetInput("encoder_hidden_states", encodedAudio);
decoder1.Schedule();
var past_key_values_0_decoder_key = decoder1.PeekOutput("present.0.decoder.key") as Tensor<float>;
var past_key_values_0_decoder_value = decoder1.PeekOutput("present.0.decoder.value") as Tensor<float>;
var past_key_values_1_decoder_key = decoder1.PeekOutput("present.1.decoder.key") as Tensor<float>;
var past_key_values_1_decoder_value = decoder1.PeekOutput("present.1.decoder.value") as Tensor<float>;
var past_key_values_2_decoder_key = decoder1.PeekOutput("present.2.decoder.key") as Tensor<float>;
var past_key_values_2_decoder_value = decoder1.PeekOutput("present.2.decoder.value") as Tensor<float>;
var past_key_values_3_decoder_key = decoder1.PeekOutput("present.3.decoder.key") as Tensor<float>;
var past_key_values_3_decoder_value = decoder1.PeekOutput("present.3.decoder.value") as Tensor<float>;
var past_key_values_0_encoder_key = decoder1.PeekOutput("present.0.encoder.key") as Tensor<float>;
var past_key_values_0_encoder_value = decoder1.PeekOutput("present.0.encoder.value") as Tensor<float>;
var past_key_values_1_encoder_key = decoder1.PeekOutput("present.1.encoder.key") as Tensor<float>;
var past_key_values_1_encoder_value = decoder1.PeekOutput("present.1.encoder.value") as Tensor<float>;
var past_key_values_2_encoder_key = decoder1.PeekOutput("present.2.encoder.key") as Tensor<float>;
var past_key_values_2_encoder_value = decoder1.PeekOutput("present.2.encoder.value") as Tensor<float>;
var past_key_values_3_encoder_key = decoder1.PeekOutput("present.3.encoder.key") as Tensor<float>;
var past_key_values_3_encoder_value = decoder1.PeekOutput("present.3.encoder.value") as Tensor<float>;
decoder2.SetInput("input_ids", lastTokenTensor);
decoder2.SetInput("past_key_values.0.decoder.key", past_key_values_0_decoder_key);
decoder2.SetInput("past_key_values.0.decoder.value", past_key_values_0_decoder_value);
decoder2.SetInput("past_key_values.1.decoder.key", past_key_values_1_decoder_key);
decoder2.SetInput("past_key_values.1.decoder.value", past_key_values_1_decoder_value);
decoder2.SetInput("past_key_values.2.decoder.key", past_key_values_2_decoder_key);
decoder2.SetInput("past_key_values.2.decoder.value", past_key_values_2_decoder_value);
decoder2.SetInput("past_key_values.3.decoder.key", past_key_values_3_decoder_key);
decoder2.SetInput("past_key_values.3.decoder.value", past_key_values_3_decoder_value);
decoder2.SetInput("past_key_values.0.encoder.key", past_key_values_0_encoder_key);
decoder2.SetInput("past_key_values.0.encoder.value", past_key_values_0_encoder_value);
decoder2.SetInput("past_key_values.1.encoder.key", past_key_values_1_encoder_key);
decoder2.SetInput("past_key_values.1.encoder.value", past_key_values_1_encoder_value);
decoder2.SetInput("past_key_values.2.encoder.key", past_key_values_2_encoder_key);
decoder2.SetInput("past_key_values.2.encoder.value", past_key_values_2_encoder_value);
decoder2.SetInput("past_key_values.3.encoder.key", past_key_values_3_encoder_key);
decoder2.SetInput("past_key_values.3.encoder.value", past_key_values_3_encoder_value);
decoder2.Schedule();
var logits = decoder2.PeekOutput("logits") as Tensor<float>;
argmax.Schedule(logits);
using var t_Token = await argmax.PeekOutput().ReadbackAndCloneAsync() as Tensor<int>;
int index = t_Token[0];
outputTokens[tokenCount] = lastToken[0];
lastToken[0] = index;
tokenCount++;
tokensTensor.Reshape(new TensorShape(1, tokenCount));
tokensTensor.dataOnBackend.Upload<int>(outputTokens, tokenCount);
lastTokenTensor.dataOnBackend.Upload<int>(lastToken, 1);
if (index == END_OF_TEXT)
{
transcribe = false;
}
else if (index < tokens.Length)
{
outputString += GetUnicodeText(tokens[index]);
}
//Debug.Log(outputString);
TranscriptionCompleted(outputString);
}
// Tokenizer
public TextAsset jsonFile;
void GetTokens()
{
var vocab = Newtonsoft.Json.JsonConvert.DeserializeObject<Dictionary<string, int>>(jsonFile.text);
tokens = new string[vocab.Count];
foreach (var item in vocab)
{
tokens[item.Value] = item.Key;
}
}
string GetUnicodeText(string text)
{
var bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(ShiftCharacterDown(text));
return Encoding.UTF8.GetString(bytes);
}
string ShiftCharacterDown(string text)
{
string outText = "";
foreach (char letter in text)
{
outText += ((int)letter <= 256) ? letter :
(char)whiteSpaceCharacters[(int)(letter - 256)];
}
return outText;
}
void SetupWhiteSpaceShifts()
{
for (int i = 0, n = 0; i < 256; i++)
{
if (IsWhiteSpace((char)i)) whiteSpaceCharacters[n++] = i;
}
}
bool IsWhiteSpace(char c)
{
return !(('!' <= c && c <= '~') || ('�' <= c && c <= '�') || ('�' <= c && c <= '�'));
}
void TranscriptionCompleted(string transcription)
{
Debug.Log("Transcription: " + transcription);
// 差分を計算
string diff = GetDifference(previousOutputString, transcription);
// 差分が空でない場合のみイベントを発火
if (!string.IsNullOrWhiteSpace(diff))
{
textMeshProUGUI.text = "Output: " + diff;
OnTranscriptionCompleted?.Invoke(diff);
}
// 現在の結果を前回の結果として保存
previousOutputString = transcription;
}
private string GetDifference(string previous, string current)
{
// ピリオドやスペースを無視して比較
string normalizedPrevious = NormalizeText(previous);
string normalizedCurrent = NormalizeText(current);
if (normalizedCurrent.StartsWith(normalizedPrevious))
{
return normalizedCurrent.Substring(normalizedPrevious.Length);
}
return current; // 差分が見つからない場合は全体を返す
}
private string NormalizeText(string text)
{
// ピリオドやスペースを削除
return text.Replace(".", "").Replace(" ", "").ToLower();
}
private void OnDestroy()
{
decoder1?.Dispose();
decoder2?.Dispose();
encoder?.Dispose();
spectrogram?.Dispose();
argmax?.Dispose();
audioInput?.Dispose();
lastTokenTensor?.Dispose();
tokensTensor?.Dispose();
}
}
一方でVoiceRecorder.cs側ですが、イベントを購読できるようにし、結果に応じてエフェクトを再生してやればよいです。Start()に
runWhisper.OnTranscriptionCompleted += HandleTranscriptionCompleted;
という行を追加しておき、末尾に以下の三つの関数を追加します。
private void HandleTranscriptionCompleted(string transcription)
{
Debug.Log("Handling transcription: " + transcription);
// すべての ParticleSystem を停止
StopAllParticles();
// 再生時間(秒)
float effectDuration = 3.0f;
// 認識結果に応じて ParticleSystem を再生
if (transcription.Contains("Fire", StringComparison.OrdinalIgnoreCase))
{
StartCoroutine(PlayParticleForDuration(fireParticle, effectDuration));
}
else if (transcription.Contains("Ice", StringComparison.OrdinalIgnoreCase))
{
StartCoroutine(PlayParticleForDuration(iceParticle, effectDuration));
}
else
{
StartCoroutine(PlayParticleForDuration(defaultParticle, effectDuration));
}
}
private void StopAllParticles()
{
fireParticle.Stop();
iceParticle.Stop();
defaultParticle.Stop();
}
private IEnumerator PlayParticleForDuration(ParticleSystem particle, float duration)
{
particle.Play(); // ParticleSystem を再生
yield return new WaitForSeconds(duration); // 指定した時間待機
particle.Stop(); // ParticleSystem を停止
}
加えて、エフェクトを再生するためにParticleSystem型のメンバ変数を定義することを忘れないようにしてください。
最終的には以下のようになります。
編集後のVoiceRecorder.cs
using System;
using UnityEngine;
using System.IO;
using UnityEngine.Serialization;
using UnityEngine.UI;
using System.Collections;
public class VoiceRecorder : MonoBehaviour
{
public AudioClip recordedClip;
[SerializeField] private RunWhisper runWhisper;
[SerializeField] private Button startRecordingButton;
[SerializeField] private Button stopRecordingButton;
[Header("Particle Systems")]
[SerializeField] private ParticleSystem fireParticle;
[SerializeField] private ParticleSystem iceParticle;
[SerializeField] private ParticleSystem defaultParticle;
private void Start()
{
startRecordingButton.onClick.AddListener(StartRecording);
stopRecordingButton.onClick.AddListener(StopRecording);
// RunWhisper のイベントを購読
runWhisper.OnTranscriptionCompleted += HandleTranscriptionCompleted;
}
private void StartRecording()
{
recordedClip = Microphone.Start(null, false, 10, 16000);
Debug.Log("Recording started");
}
private void StopRecording()
{
Microphone.End(null);
Debug.Log("Recording stopped");
SaveRecordedClip();
}
private void SaveRecordedClip()
{
string fileName = "recorded_clip_" + System.DateTime.Now.ToString("yyyyMMdd_HHmmss") + ".wav";
string filePath = Path.Combine(Application.dataPath, fileName);
SavWav.Save(filePath, recordedClip);
Debug.Log("Recorded clip saved as " + filePath);
runWhisper.audioClip = recordedClip;
runWhisper.StartWhisper();
}
private void HandleTranscriptionCompleted(string transcription)
{
Debug.Log("Handling transcription: " + transcription);
// すべての ParticleSystem を停止
StopAllParticles();
// 再生時間(秒)
float effectDuration = 3.0f;
// 認識結果に応じて ParticleSystem を再生
if (transcription.Contains("Fire", StringComparison.OrdinalIgnoreCase))
{
StartCoroutine(PlayParticleForDuration(fireParticle, effectDuration));
}
else if (transcription.Contains("Ice", StringComparison.OrdinalIgnoreCase))
{
StartCoroutine(PlayParticleForDuration(iceParticle, effectDuration));
}
else
{
StartCoroutine(PlayParticleForDuration(defaultParticle, effectDuration));
}
}
private void StopAllParticles()
{
fireParticle.Stop();
iceParticle.Stop();
defaultParticle.Stop();
}
private IEnumerator PlayParticleForDuration(ParticleSystem particle, float duration)
{
particle.Play(); // ParticleSystem を再生
yield return new WaitForSeconds(duration); // 指定した時間待機
particle.Stop(); // ParticleSystem を停止
}
}
シーン編集
エディタに戻り、カメラに映る位置に何らかのGame Objectを配置します。そして、そのGame Objectと親子関係になるようにParticle Systemを3つ追加します。変化が分かるようにStart Colorの部分の色を定義変更しておいてください。また、開始時に再生されないようにするためにPlay On Awakeのチェックマークは外しておいてください。
Particle Systemの追加が終わったら、それらをVoiceRecorerのコンポーネントとして追加してください。
私の場合は、以下の画像のように設定しました。
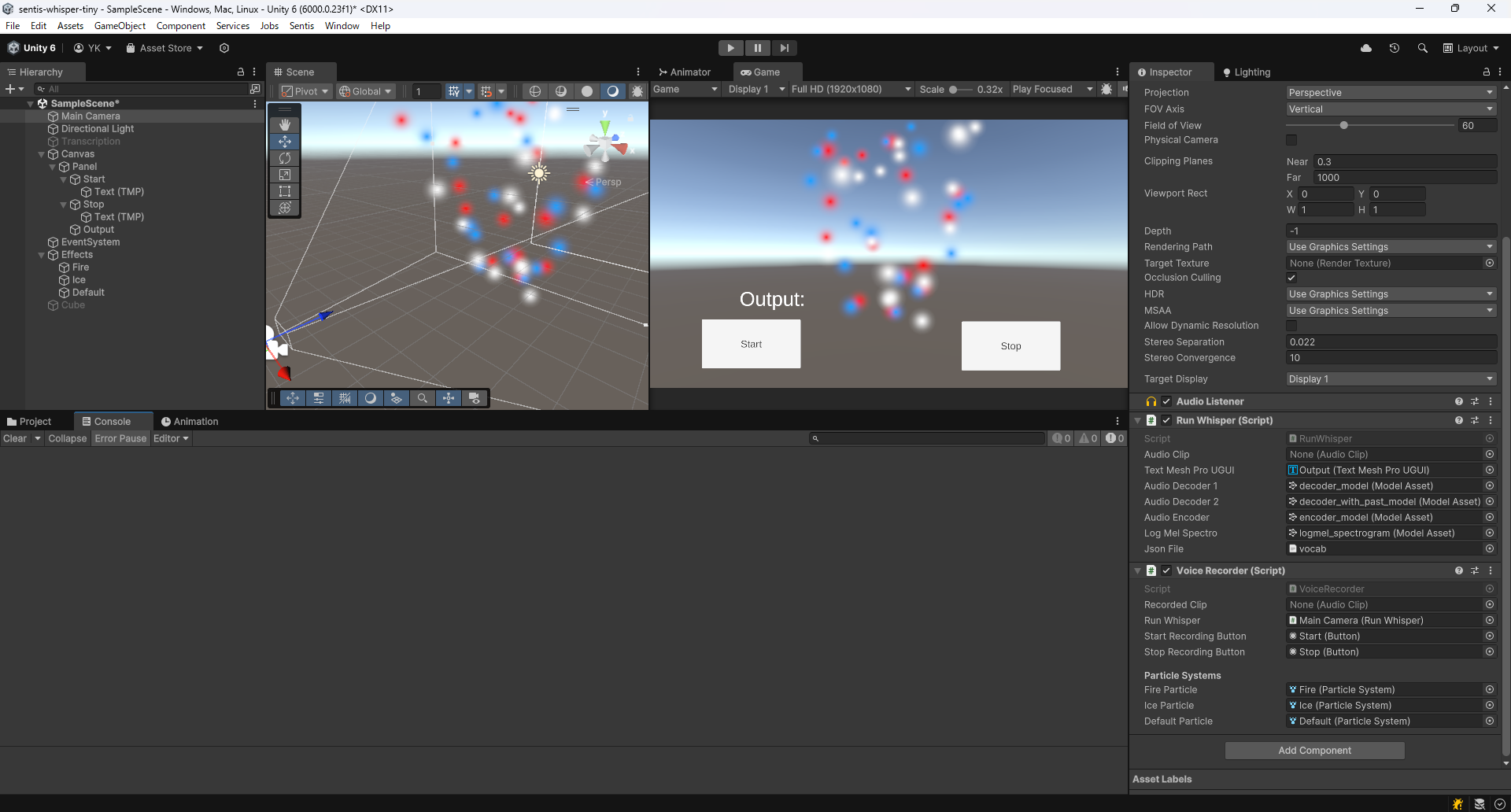
エフェクト再生の結果
先ほどと同じようにStartを押して「Fire」と入力しStopを押すと、(正確に認識されれば)赤いエフェクトが3秒間再生されることが確認できると思います。「Ice」というと青いエフェクトが、その他の言葉(例えば「Thunder」とか)を言うと白いエフェクトが発生することも確認してください。実際のゲームでは白いエフェクトに該当する部分を「スカ」のようなはずれっぽいエフェクトにすると面白いかもしれません。
夢が広がりますね!

まとめ
Unity Sentisを利用して、音声をもとにエフェクトを表示させてみました。今回は、Hugging Face上で公開されているプロジェクトをそのまま流用しましたが、onnx形式であれば別のモデルを流用することも可能です。もちろんPyTorchなどを使って自作したモデルであってもonnx形式にフォーマットすればUnity Sentisで利用できます。どこかのタイミングで実際に自作してみたいです。
次回は、よりロールプレイを楽しめるように、音声の感情分析を行うモデルを使った簡単なゲームを作ってみたいと考えています。怒気を込めて呪文を唱えるほど攻撃が強くなるとか、優しく呪文を唱えるほど回復量が増えるとかするとより没入感があって面白くなりそうだなぁと思っています。
今回初投稿でしたが、読んでくださった方々ありがとうございました。