みゅーもり Advent Calendar 2018 18日目の記事です。嘘です。
つらかった問題
ABC141-F Xor Sum 3(16敗)
正直今解けと言われても無理やが…
Bitの配列を定義し、Gauss–Jordan eliminationを行えば正答が得られる(らしい、ほとんど解説見て書いたのでよくわからん)のですが、なんかかなり苦労しました。最終的にかなり雑な枝刈りをして通ったのでヨシ!
ABC091-D Two Sequences(22敗)
正解するまでに5か月もかかったので、かなり辛かったイメージが強いです。
想定解の場合は各$a_{i}$に関して条件を満たす$b_{i}$を二分探索で求めればよいのですが、各$a_{i}$につき二分探索を4回行う必要があり、この部分がボトルネックとなりTLEとなりました。
本当に意味がわからなかったので、しまいには自分史上初めて他人のコードをコピペして通すという屈辱をやるに至りました。
この際に自分のコードとの比較を行った結果、二分探索のコード内で中央を求める箇所をdiv(l+r,2)としていたため、ここを右シフト(l+r)>>1とすることで計算時間の短縮をしているようでした。
というわけで、自分の二分探索のコードを修正して無事正解にたどり着きました。
辛い思い出ではありますが、この問題は
- 二分探索(二分法)に関する理解を深めた
- シフト計算に関して理解できた
という点で得るものは多かったと感じています。
苦労はしますが、まだまだJuliaで想定解を通せます。
ARC064-E Cosmic Rays(20敗)
はい。遂にJuliaでは想定解で通せなさそうな問題が出てしまった…
重みが小数になるDijkstraですが、愚直に実装するとTLEになりました。
苦労の詳細は省いて結論から言うと、この問題の場合は定められた始点と終点間の最短経路長を求めれば良いので、始点、終点双方からDijkstraを実行して両ノードから最短で到達可能なノードが出現した時点で止めるという方法(双方向Dijkstra)で計算時間を短縮できました。
しかし双方向Dijkstraだけでは解決しませんでした。強い人いわくFloatの加算にはクロックサイクルがかかるので、Intの加算より時間がかかるらしいです。自分の提出したコードを確認すると同じ重みを複数回計算している箇所があったため、ここを修正して加算の回数を減らし、正解することができました。
どちらかを怠ると間に合いません。こんなん本番で解けるようになれるんか…
http://ithare.com/infographics-operation-costs-in-cpu-clock-cycles/
ABC147-E Balanced Path(53敗)
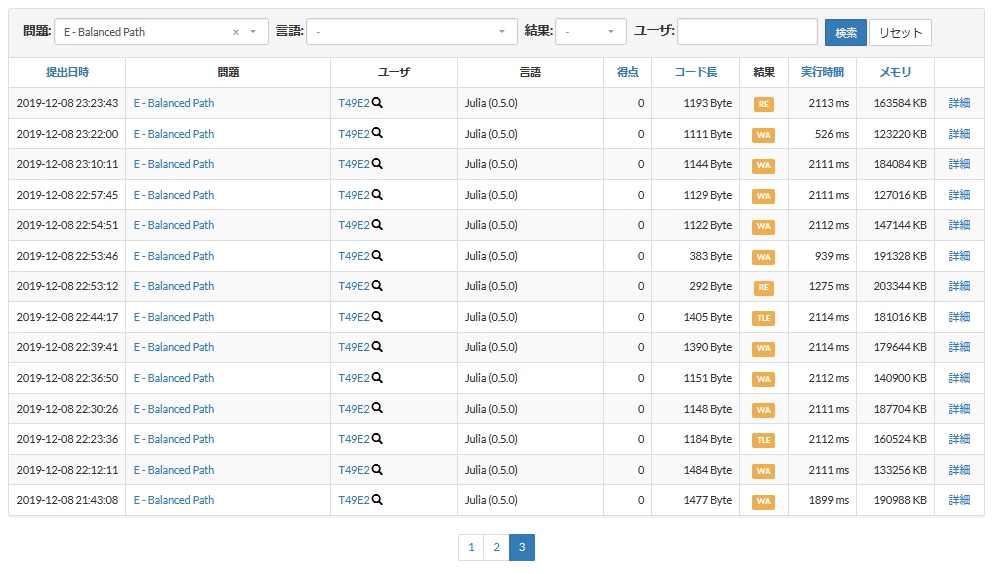
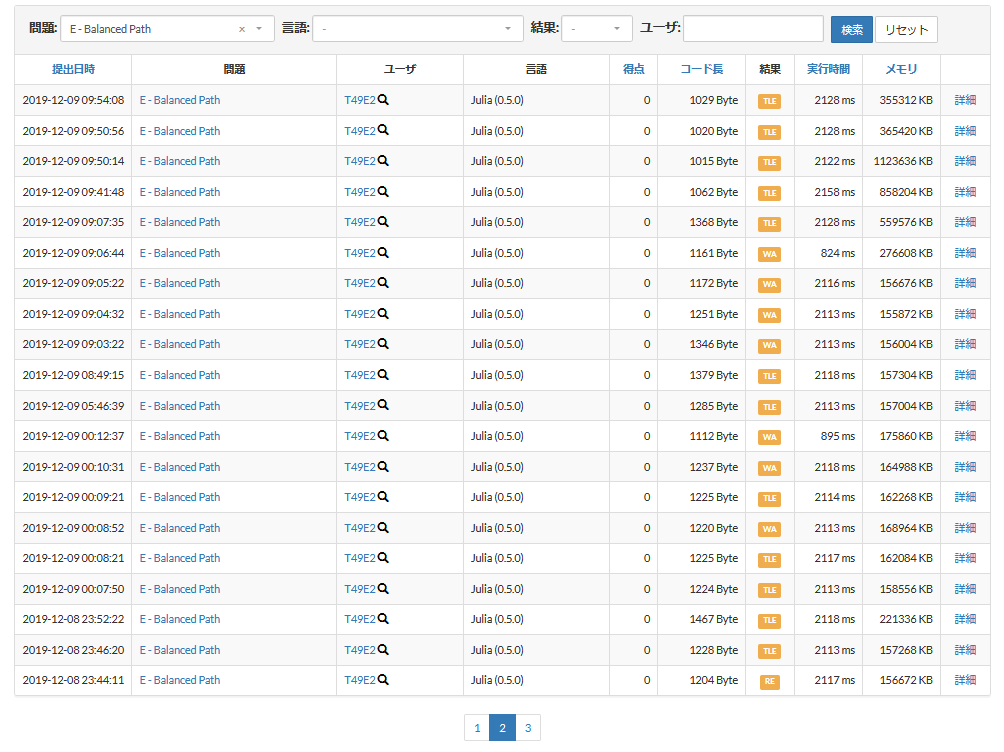
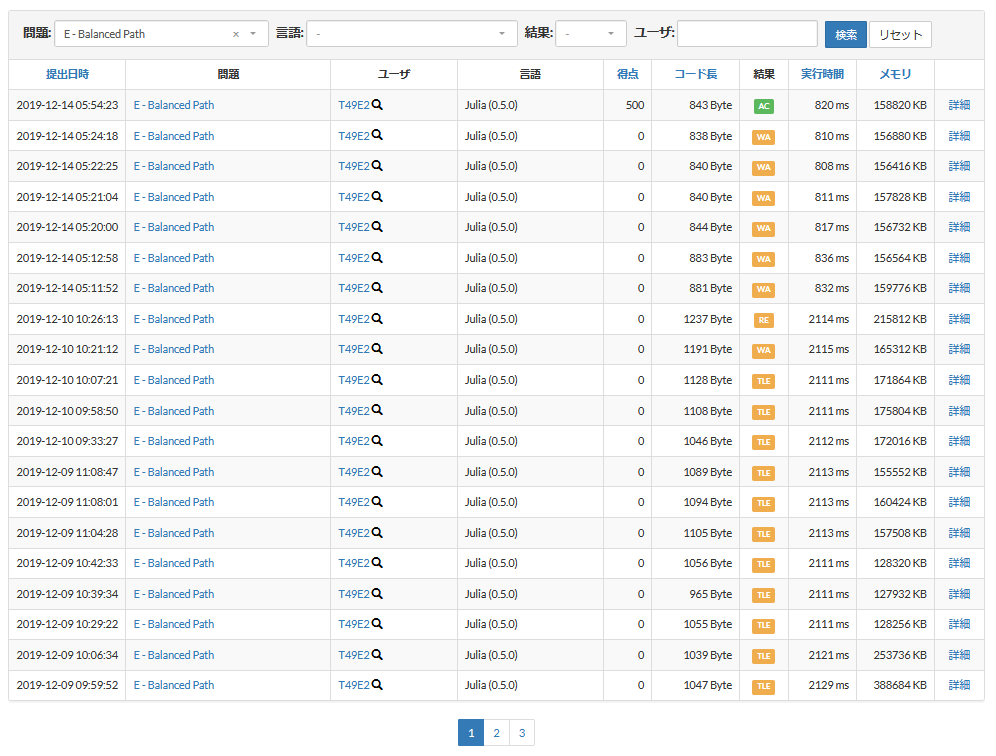
※53敗のうちいくつかはこれまで他の問題で試してうまく行かなかった高速化を片っ端から再検証していたためであって、体感的には30敗程度の印象です。だとしてもぶっちぎりで一番辛かった…
想定解で通せない問題、意外にポンポン出てくるかもしれない説
愚直に考えた場合、最大8080通りの数値に関してそのマスで実現可能か否かを最大8080のマスそれぞれについて計算すれば良い、というものですが、
- 三次元配列が異常に遅い
- 80^4は通らない
- Julia0.5.0にはBitSetがない
という3つの壁に阻まれ、かなり辛酸を嘗めさせられました。
顛末としては、BigInt型の数値の各bitを各数値の実現可能性と考えることで、実質的にBitSetによる高速化と同等のことを行って正答しました。BitSetがないならBigIntを使えばいいじゃない
結果的には割とすっきりした解法で、3つの壁を簡潔に破れたので概ね満足です。使い道もありそう。
たのしくするために
※AtCoderのコードテストページにて、各記述の「サンプルコード」を「ソースコード」欄に、「入力」を「標準入力」欄にコピペすることで、「出力」と同じ結果が「標準出力」欄に表示されると思います。
@Juliaユーザー
これはAtCoderの環境でこうなっているだけなので一般的な議論は無用
コードを高速化する上でまず最初に思いつく方法等に関しての見解
関数でくくれ
効果はある
少なくともmainの処理全体をくくることで目に見えて速度改善するし、くくらないと通らない問題とかあるかもしれない 外したことがないのでわからん
ただし倍速とかそういうことを期待していたなら思っているほどはないかもしれない(JITのオーバーヘッドが大きくて霞む)
引数の型を指定しろ
これ
だいたい全部これで解決するし、解決できない場合はおまえの解法かJuliaのどちらかがだめ
何度もやる処理は細かい関数に分割しろ
基本的に詰まった時にこれで改善したことはない
下のおまじないみたいに型の変換を伴う処理を何度も行う場合は分離したほうがいいと思われるが、DPの更新などIntからIntを返すような計算を分離しても恩恵は感じなかった
@inboundsマクロ
無駄いますぐ消せ
初級編
基本
整数の入力
# サンプルコード
parseInt(x) = parse(Int, x)
parseMap(x::Array{SubString{String},1}) = map(parseInt, x)
function main()
a = parseInt(readline())
b = parseMap(split(readline()))
println(a)
println(b)
end
main()
# 入力
1
2 3
# 出力
1
[2,3]
おまじない。
1行に数値一つならparseInt(readline())
1行に数値複数ならparseMap(split(readline()))を行数分。
※@Juliaユーザー dot syntaxで定義してもほとんど同じですが検証の結果mapの方が数ms速かったのでこちらを採用しています
文字列の入力
# サンプルコード
function main()
str1 = readline()
str2 = chomp(readline())
println(str1)
println(length(str1))
println(str2)
println(length(str2))
end
main()
# 入力
ihatejulia
ihatejulia
# 出力
ihatejulia
11
ihatejulia
10
chomp()は改行コードを消す関数。これをやらないと改行を含めた文字列として認識されるので注意。
やらなくても良い問題設定もありますが、やって損することはないので文字列を受け取る場合はやっておくのが吉です。
ちなみに、文字列を処理する問題で一文字ずつ見ていく必要がある場合ですが、JuliaはStringのi番目のみを参照することができる(書き換えは不可)ので、Stringのまま受け取って問題ありません。
ただしi番目を参照した場合の型はCharになるので注意。Stringは""でくくられ、Charは''でくくられます。
迷路問題
# サンプルコード
function main()
a = String["" for i in 1:3]
for i in 1:3
a[i] = chomp(readline())
end
println(a)
end
main()
# 入力
# .##
.##.
..##
# 出力
String["#.##",".##.","..##"]
上記の通りString自体は配列に変換する必要がないため、迷路を文字で表現した問題(頻出)の場合は予めStringの配列を確保しておいて、毎行読み取るという形で実装しています。
ちなみにこの手の問題はしばしば外周に壁(#)があることを仮定するとその後の処理が簡単になる場合が多いですが、Juliaの場合文字列を結合する時は+ではなく*なので注意。
理不尽な入力が来た場合
e.g. https://atcoder.jp/contests/abc128/tasks/abc128_b
# サンプルコード
parseInt(x) = parse(Int, x)
function main()
data = Tuple{String,Int}[("",0) for i in 1:3]
for i in 1:3
a,b = split(readline())
data[i] = (chomp(a),parseInt(b))
end
println(data)
end
main()
# 入力
idontlikejulia 1
ilikejulia 2
ilovejulia 3
# 出力
Tuple{String,Int64}[("idontlikejulia",1),("ilikejulia",2),("ilovejulia",3)]
初見ではB最難関だと思いました。
こういうふうに1行内にStringとIntegerが同居すると多分にめんどくさい。
私は予めTuple{String,Int}型でサイズnの配列aを持っておいて、各行でx,yにsplitしたあと a[i] = (chomp(x),parseInt(y))と格納することにしました。
ちなみにsortは型がなんだろうが可能なので、この問題ならば市の昇順かつ同点ならば点数の降順、というsortが一発で書けるメリットもあります
ちなみにTupleは初期化や要素の更新が面倒なので注意(Tupleの要素は不変のため一部分のみを変えることができず、Tuple全体を更新する必要がある)。
2進数
※BigIntで表現するほうが簡単な可能性があるが、試したことがないので興味があれば検証してほしい 私はやりたくない
めんどくさいので具体例を掘り出していませんが、時々数値が2進数で与えられることがあります。
parseは2進数からも整数に変換できますが、大きすぎるとだめ。
というかそもそも2進数で与えられる時点で2進数であることの利点に帰着しろということなので、なるべくそのまま入力したいです。
ということで私が取っているのは
n桁の2進数に対してサイズnのInt配列を用意し、各インデックスに各桁の数値(1 or 0)を格納する
という方法です。 split()は第2変数で区切り文字を指定(デフォルトの区切り文字はスペース)できますが、無も指定できる点に注目。
# サンプルコード
parseInt(x) = parse(Int, x)
parseMap(x::Array{SubString{String},1}) = map(parseInt, x)
function main()
a = parseMap(split(chomp(readline()),""))
println(a)
end
main()
# 入力
11111100000
# 出力
[1,1,1,1,1,1,0,0,0,0,0]
二値なので別にBool配列でもいいですが、そこをケチるケチらないで通る通らないが決まる問題に出会ったことはありません。出会ってしまった場合そのときに考えます
大事な点としてparseは改行コードを無視しますが、一文字ずつparseする場合splitの前にchompしておかないと改行コードのみの要素が生まれてエラーが発生します。
やばい処理
三次元以上の配列
三次元配列で持つ場合はそこまで遅くならないので問題ありませんが、配列の配列の配列みたいな実装をしてしまうとなんかアホみたいに挙動が遅くなったのでやらないほうが無難です。
ただしi行j列にそれぞれ可変長の配列を保持させたい場合など、配列の配列の配列を作りたくなる場合もありまして…(二次元の場合行列または配列の配列として実装可能だが、三次元を配列の行列と実装することはできない)
一般論としてi行j列は1行にn個要素があるとしてn*(i-1)+j番目にそれぞれ格納すればいいので、比較的脳のリソースを食わない処理で次元を一つ落とすのはそこまで難しくはないです。
二次元配列は(行列でなくても)普通に高速です。流石にね。
Set
あまり詳しくありませんがおそらくJuliaのSetはHashSetっぽいもののはずで、挿入や削除が高速に行えるはずですがなんかおそい。
重複チェックとしてSetを使おうとする局面のほとんどは既出かどうかを判定する配列を用意したほうが速くなります(出現する数値が極端に大きい場合は除く)。
e.g. https://atcoder.jp/contests/abc139/tasks/abc139_e
次に試合が行われる可能性のある人を書き出す部分で既出かどうかの判定が必要で、Setだと通らないが既出判定配列を毎回作った場合通る例。
既出判定をする必要のない書き方もあるかもしれません。読者の課題とする。
https://atcoder.jp/contests/arc033/submissions/8998691
一応こういう芸当(intersectやunion等集合っぽい方法を駆使)ができることもあるかもしれないし、ないかもしれない
M L E
無に145MBも使う謎仕様によりメモリではかなりディスアドバンテージがあると言っていいです。
当然最初期の64MB問題は一切の例外なく解けないし、256MB問題も時々MLEを起こします。
最近は1024MBまで許容されるため問題になりませんが、過去問で通らなくて困った場合、例えばIntを32bitにするとかで通ったり通らなかったりします。それでだめなら頑張って余計な計算を省く。
Holy S**t コーナー
Dictの謎挙動
# サンプルコード
d = Dict{Int,Int}(1=>1,2=>2,3=>3,4=>1)
println(indmax(d))
# 入力
# 出力
1
は?
上でやりたいのはDictの値が最大値をとるキーを知る方法ですが、この場合丁寧に一つずつ見ていって最大の時のキーを保持する、という原始的なやり方をとる必要があります。
xor
# サンプルコード
println(xor(3,5))
# 入力
# 出力
ERROR: LoadError: UndefVarError: xor not defined
in include_from_node1(::String) at ./loading.jl:488
in process_options(::Base.JLOptions) at ./client.jl:262
in _start() at ./client.jl:318
while loading /imojudge/Main.jl, in expression starting on line 1
は?
Julia0.5.0においてa xor b は a$b です。当然配列全体のxorを取りたい場合は丁寧に一つずつ見ていく必要があります。
(追記)'+'や'x'などの演算子を配列全体に適用する場合は、reduce(演算子, 配列) とするとすればよいです。Julia 0.5.0の場合は'$'がxorを返す演算子のため、これが利用可能です。 @goropikari さんありがとうございます。
struct
わかってんだよ!!!!!!!!!!!!!!!!!Julia0.5.0には!!!!!!!!!!!!!!!!!!!!!structなんてねーよ!!!!!!!!!!!!!!!!!!!!!キイィィーーーー!!!!!!!!!!!!!!!
(追記)Julia 0.5.0において(mutable) struct はtypeという名前らしいです。abap君ありがとうございます。
あとがたり
この記事は私の競プロデビュー1周年(9月上旬)かつ入青記念記事の一部となるべく夏頃から温められていたものですが、本人が12月になっても水色のままだったためこのタイミングでの公開となりました。
私は競プロ以外でJuliaを触ることはほぼない人間ですが、せっかくここまで使ってる言語だし、競プロでC++に勝つとかそういうのは無理なんで、せめてスクリプト言語最強ではあってほしくないですか?私はあってほしいです。というわけなので、やっぱり倒すべき敵はPythonのようです。