はじめに
AWS re:Invent2024にてWorkshop「NTA401 | Improving the performance of your generative AI application on AWS」に参加してきました。
 |
|---|
※今回はちゃんとWorkshopでした。
Workshopの紹介文
Workshopの紹介文は下記のようになっています。
Topic : AI/ML, Architecture
Industry : Cross-Industry Solutions
Area of interest: Generative AI
Level: 400 – Expert
Role: Data Engineer, Data Scientist, Solution / Systems Architect
Services: Amazon Bedrock
In this workshop, learn to optimize the performance of your generative AI RAG applications using Amazon Bedrock with hands-on labs that guide you through best practices and optimization techniques. Assess performance and accuracy metrics of various foundational models on the Amazon Bedrock service. Explore techniques such as selecting the optimal model, implementing hybrid search, refining chunking strategies, re-ranking, and enhancing network configurations for improved response efficiency and quality. Walk away with insights and practical skills to evaluate your generative AI RAG workflow. You must bring your laptop to participate.
(翻訳)
このワークショップでは、Amazon Bedrockを使用した生成AI RAGアプリケーションのパフォーマンスを最適化する方法を、ベストプラクティスと最適化テクニックをガイドする実習を通して学びます。Amazon Bedrockサービス上の様々な基礎モデルのパフォーマンスと精度メトリクスを評価します。最適なモデルの選択、ハイブリッド検索の実装、チャンキング戦略の洗練、再順位付け、応答効率と品質を向上させるためのネットワーク構成の強化などのテクニックを探求します。ジェネレーティブAI RAGワークフローを評価するための洞察と実践的なスキルを身につけましょう。参加にはノートパソコンが必要です。
今回はBedrockを用いたRAG構築のスキルを身に付けたいと思い挑戦してきました!
Walk-upに長蛇の列
事前予約が埋まっている場合でも、その場で並べば参加できる可能性のある「Walk-up」という参加枠があります。本セッションはかなり早い時期から予約が埋まっていたため、Walk-upに並びました。
開始30分前に行ったところ既に20人ほど並んでおり、私が並んだ後も続々と人が並んできましたが、無事参加することができました。生成AI、RAGの注目度の高さが感じられました!
 |
|---|
※長蛇の列の写真はありません・・・
Workshopの流れ
まず最初にSolution Architect(SA)の方からBedrockやRAGについての説明があります。
その後は各自もくもくと手元のPCでWorkshopを進めます。
言語は英語のみのため、Webブラウザの翻訳機能を使いました。
何かあればSAさんに声をかけると丁寧に教えてくれます。
※私は英会話がほぼできませんが、「AWSという共通言語」と身振り等を駆使することで何とかなります!
SAさんからの説明スライド
 |
|---|
 |
|---|
 |
|---|
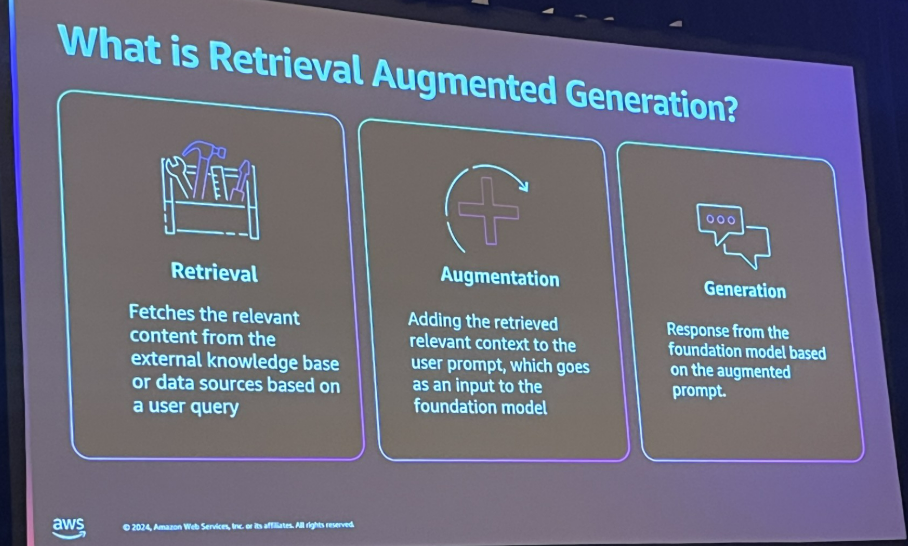 |
|---|
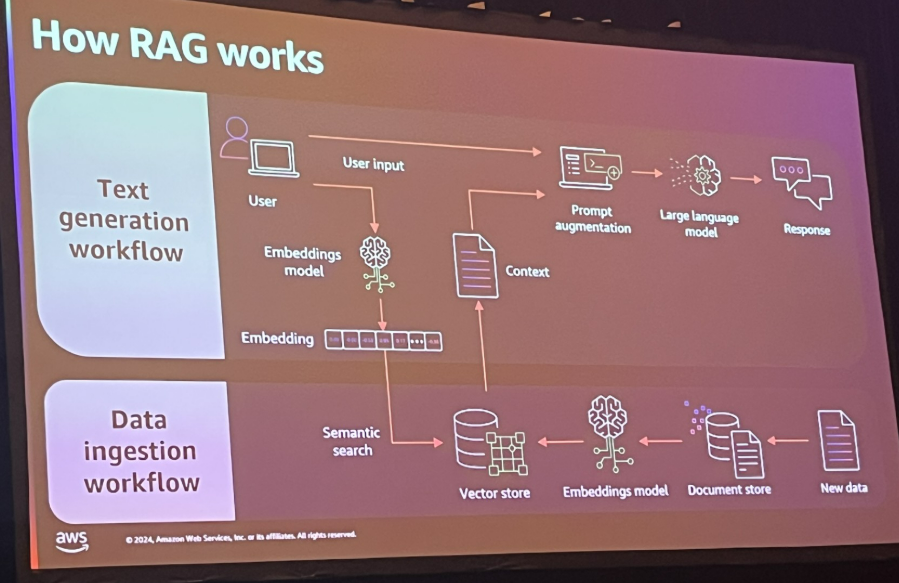 |
|---|
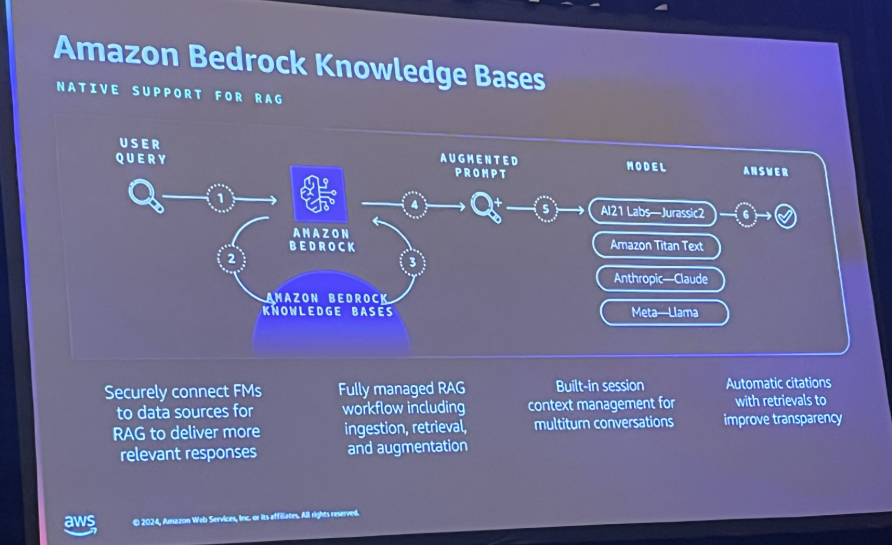 |
|---|
 |
|---|
 |
|---|
 |
|---|
Workshopの内容
章立ては下記のとおりです。
- RAGアプリケーションの構築
- RAGアプリケーションの構築
- RAGアプリケーションの実行
- モデルの選択
- モデル選択のためのRAGアプリケーションの構成
- チャンキング戦略
- 階層的チャンキング
- セマンティックチャンキング
- ハイブリッド検索
- ハイブリッド検索による精度の向上
- ストリーミング
- ストリーミングアプリケーションの設定
AWSサービスの構成は下図のようになっています。
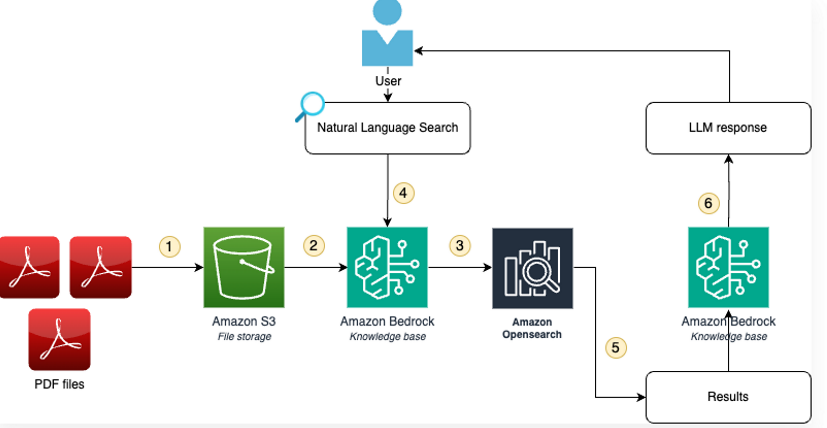
Workshopのポイント
RAGの精度に影響するポイントには様々なものがあると思われますが、本Workshopでは特に下記のポイントを経験できる作りになっていました。
- チャンキング戦略
- ベクターDBの検索方法
チャンキング戦略とは
チャンク(chunk)とは単語の意味のとおり「かたまり」のことです。LLMが参照するドキュメントをベクターDBへ取り込む前にある程度の大きさに分割して取り込みます。分割された個々のかたまりがチャンクです。チャンクの作り方には様々なものがあり、チャンクを作る方式を決めることをチャンキング戦略(下記資料の場合はチャンク戦略)と言います。

※AWSセミナー RAG on AWS dive deep より引用
Bedrock KnowledgeBaseで選択できる方法には下記の3種類があり、本Workshopではこれらをひととおり実践してみることができます。
- 固定チャンク(デフォルト)
- セマンティックチャンク
- 階層チャンク
※各種方式の詳細については上記AWSセミナー資料が分かりやすいです。
LLMが如何にそれっぽい回答の文章を生成したとしても、ユーザの質問へ回答するために必要な情報をベクターDBから取得できていなければ、ユーザに正確な回答を返すことはできません。
ハイブリッド検索とは
キーワード検索とベクトル検索の両方を使う検索方式です。
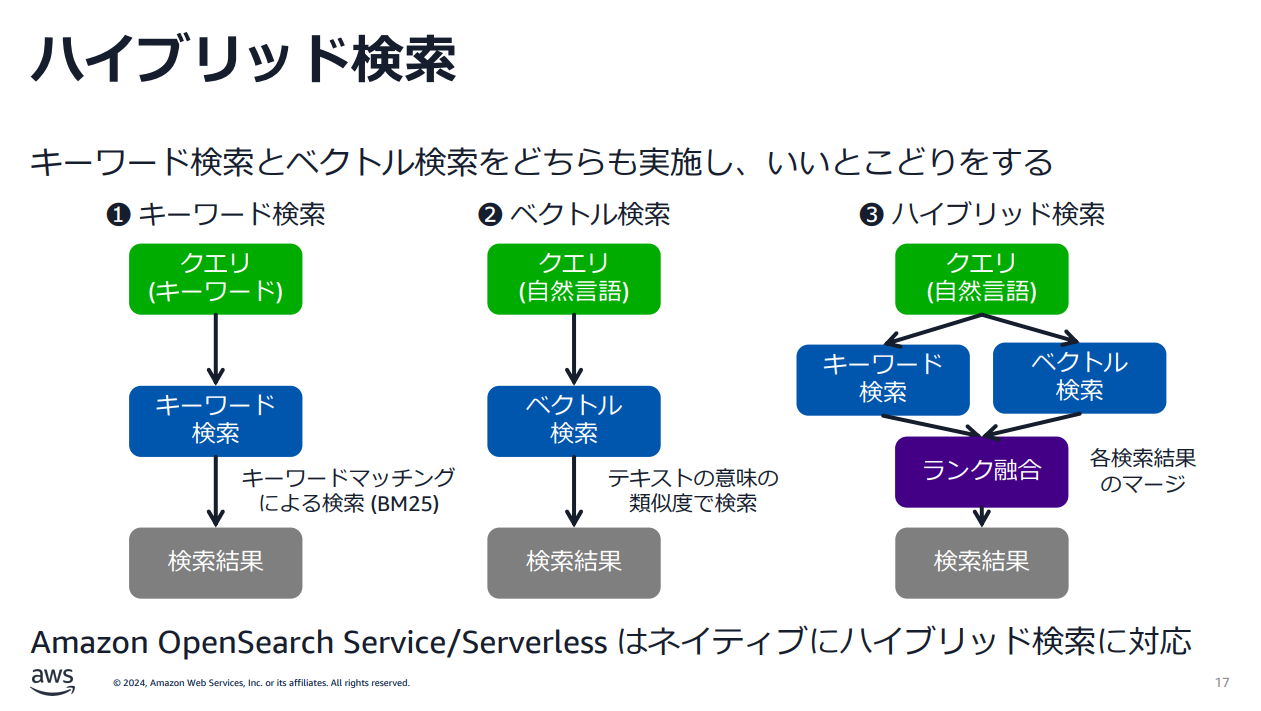
※AWSセミナー「あなたの RAG の精度を改善!Advanced RAG on AWS のすヽめ」より引用
本Workshopではこれら検索方式を実践してみることができます。
なお、下記のとおり、どの検索方式の精度が最も良いかは場合によるそうです。
ユーザーのクエリに十分な情報が含まれているのであれば、キーワード検索とベクトル検索のハイブリッドを採用することで、今回のクエリ拡張のような幅広いドキュメントを取得するという目的は達成できるかもしれません。一方で、ユーザーのクエリは単一の単語のみで構成されていたり、多様な分布を持つこともあり得ます。
さいごに
今回のWorkshopに対する所感です。
2時間で、回答精度に関わる各種チャンキング戦略を試して結果を比較することができ、最後のストリーミングのところではPythonのstreamlitパッケージを利用して簡易なWebアプリの動作も試すことができ、とりあえずとにかく体験してみるには良いWorkshopだと感じました。
各方式ごとの回答の比較に関しては英語であったことと時間もかぎられていたことから、このWorkshop内ではあまり差異を感じることはできませんでした。
もし今後このWorkshopが一般公開されたらまた試してみたいと思います。
その際は下記のようなことができると、より理解が深まるかもしれないと感じました。
- 日本語の質問文と回答を比較する
- 回答だけではなくベクトルDBの検索結果の違いも比較する
弊社では一緒に働く仲間を募集中です
現在、様々な職種を募集しております。
カジュアル面談も可能ですので、ご興味のある方は是非ご連絡ください!
募集内容等詳細は、是非採用サイトをご確認ください。
https://engineer.po-holdings.co.jp/